OpenTSDB介绍
OpenTSDB 2.0, the scalable, distributed time series database可扩展、分布式时间序列数据库
1、背景
一些老的监控系统,它常常会出现这样的问题:
1)中心化数据存储进而导致单点故障。
2)有限的存储空间。
3)数据会因为时间问题而变得不准确。
4)不易于定制图形。
5)不能扩展采集数据点到100亿级别。
6)不能扩展metrics到K级别。
7)不支持秒级别的数据。
OpenTSDB解决上面的问题:
1、它用hbase存储所有的时序(无须采样)来构建一个分布式、可伸缩的时间序列数据库。
2、它支持秒级数据采集所有metrics,支持永久存储,可以做容量规划,并很容易的接入到现有的报警系统里。
3、OpenTSDB可以从大规模的集群(包括集群中的网络设备、操作系统、应用程序)中获取相应的metrics并进行存储、索引以及服务
从而使得这些数据更容易让人理解,如web化,图形化等。
对于运维工程师而言,OpenTSDB可以获取基础设施和服务的实时状态信息,展示集群的各种软硬件错误,性能变化以及性能瓶颈。
对于管理者而言,OpenTSDB可以衡量系统的SLA,理解复杂系统间的相互作用,展示资源消耗情况。集群的整体作业情况,可以用以辅助预算和集群资源协调。
对于开发者而言,OpenTSDB可以展示集群的主要性能瓶颈,经常出现的错误,从而可以着力重点解决重要问题。
2、架构Review
openTSDB使用hbase作为存储中心,它无须采样,可以完整的收集和存储上亿的数据点,支持秒级别的数据监控,得益于hbase的分布式列式存储,hbase可以灵活的支持metrics的增加,可以支持上万机器和上亿数据点的采集。
在openTSDB中,TSD是hbase对外通信的daemon程序,没有master/slave之分,也没有共享状态,因此利用这点和hbase集群的特点就可以消除单点。用户可以通过telnet或者http协议直接访问TSD接口,也可以通过rpc访问TSD。每一个需要获取metrics的Servers都需要设置一个Collector用来收集时间序列数据。这个Collector就是你收集数据的脚本。
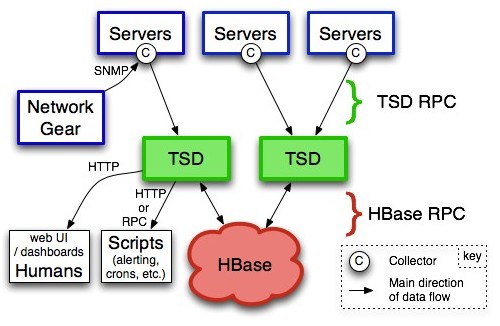 图1、openTSDB的数据流图
图1、openTSDB的数据流图
如果想快速地展示mysql中在一段时间内执行delete子句的数量,慢查询的数量,创建的临时文件数量以及99%的延迟数量等等。OpenTSDB则可以非常容易存储和处理百万级别以上的数据点,并能实时动态的生成对应的图,如图2.
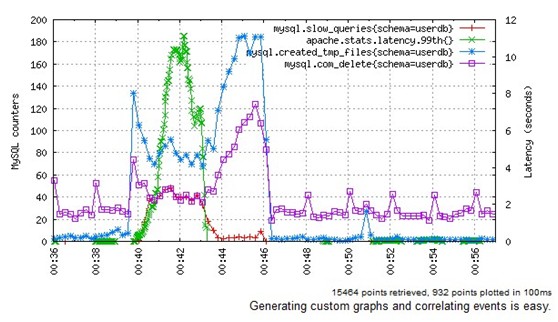
图2、OpenTSDB用例图
3、在hbase中存储时间序列
OpenTSDB使用async hbase ,这是个完全异步、非阻塞、线程安全、HBase api,使用更少的线程、锁以及内存可以提供更高的吞吐量,特别对于大量的写操作。
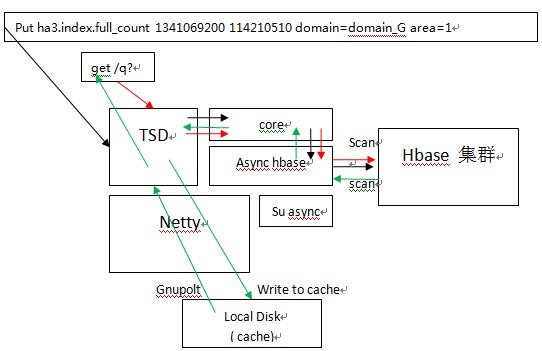
图3为读写流程
黑色的线表示写入,红色的线表示读取,通过get请求,绿色的呢,Gnuplot是画图吗??
在hbase中,表结构的设计对性能具有很大的影响,其中tsdb-uid表和tsdb表见表一和表二
tsdb-uid表
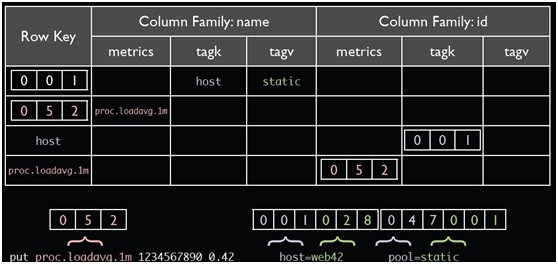
tsdb表
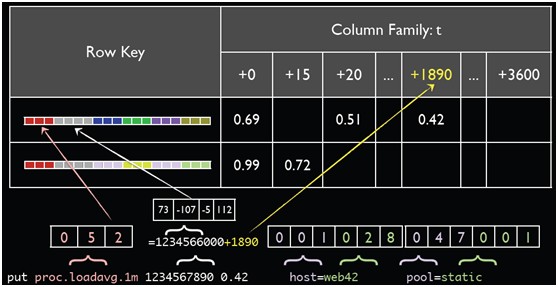
4、一淘的实例
OpenTSDB,一个数据点可以表示为:1)一个指标名称。2)UNIX时间戳。3)一个值(64位整数或双精度浮点值)。4)标识这个数据点的一组标记tags(键-值对)。
如tcollector中的dfstat.py脚本的输出:
df.bytes.total 1413306095 4159016960 mount=/ fstype=ext3
一淘的例子:
下面四个数据点都是采集的metrics为index.full_count,代表引擎索引doc数;标记tags为来自哪个domain(代表机房),area和app代表应用,cluster代表索引表,partition代表列。Metrics和tags加起来就是一个时间序列。
index.full_count 1341069600 156866750 domain=domain_E area=1 app=jqb cluster=epid partition=partition_16384_32767 index.full_count 1341069600 155819640 domain=domain_E area=1 app=jqb cluster=epid partition=partition_32768_49151 index.full_size 1341069000 18561 domain=domain_D area=1 app=jqb cluster=b2c partition=partition_0_16383 index.full_size 1341069000 18554 domain=domain_D area=1 app=jqb cluster=b2c partition=partition_16384_32767 index.full_count 1341069200 11421051 domain=domain_G area=1 app=jqb cluster=b2c partition=partition_16384_32767
那如何收集这些数据呢,Etao在tcollector开源收集器的基础上,做第二次开发,见图5。
tcollector可以完成:
1)可以任意添加你的收集脚本程序,并收集所有数据。
2)完成发送数据到TSD的所有连接管理。
3)初始化一些状态,执行一些公共的部分,比如定时管理执行1min文件夹下面的脚本。
4)删除重复的数据。
5)支持很多种数据交换协议,提供良好的扩展性。
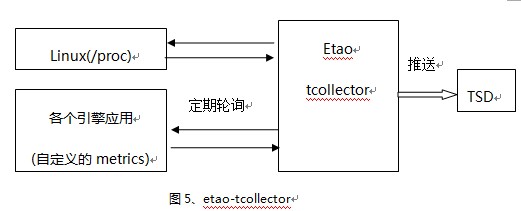
将etao-tcollector部署在所有机器上(可采用集中运维脚本进行远程部署,并可通过该系统远程控制收集器的启停)。etao-tcollector会将带时间和metrics的时间序列数据发送到tsd,之后的处理见第三节的图3,最后我们在Opentsdb提供的web UI上通过指定查询条件进行查询获取相应的图形用来对应用进行监控。
该etao-tcollector在一淘引擎中用来收集索引相关信息,引擎服务状态如延迟,日志等。
openTSDB采用hbase作为时序数据的存储中心,具有高扩展性,metrics添加相当灵活,且对数据可以无损的存储。可以很灵活的支持数据分析,图形显示以及一系列定制化操作,非常方便运维人员做运维监控。
5、参考资料
1、http://www.searchtb.com/2012/07/opentsdb-monitoring-system.html
2、http://opentsdb.net/docs/build/html/index.html
3、https://github.com/stumbleupon/asynchbase
4、https://github.com/stumbleupon/tcollector
OpenTSDB介绍的更多相关文章
- OpenTSDB介绍——基于Hbase的分布式的,可伸缩的时间序列数据库,而Hbase本质是列存储
原文链接:http://www.jianshu.com/p/0bafd0168647 OpenTSDB介绍 1.1.OpenTSDB是什么?主要用途是什么? 官方文档这样描述:OpenTSDB is ...
- OpenTSDB安装
时序数据库 时序数据库全称为时间序列数据库.主要用于处理带时间标签(按照时间的顺序变化,即时间序列化)的数据,带时间标签的数据也称为时间序列数据.时间序列数据主要由电力行业.化工行业.物联网行业等各类 ...
- openTSDB(转)
1.OpenTSDB介绍 1.1.OpenTSDB是什么?主要用途是什么? 官方文档这样描述:OpenTSDB is a distributed, scalable Time Series Datab ...
- Opentsdb简介(一)
原文:http://www.jianshu.com/p/0bafd0168647 1.OpenTSDB介绍 1.1.OpenTSDB是什么?主要用途是什么? 官方文档这样描述:OpenTSDB is ...
- Opentsdb简介
1.OpenTSDB介绍 1.1.OpenTSDB是什么?主要用途是什么? 官方文档这样描述:OpenTSDB is a distributed, scalable Time Series Datab ...
- #研发解决方案介绍#基于StatsD+Graphite的智能监控解决方案
郑昀 基于李丹和刘奎的文档 创建于2014/12/5 关键词:监控.dashboard.PHP.graphite.statsd.whisper.carbon.grafana.influxdb.Pyth ...
- 时序列数据库武斗大会之 OpenTSDB 篇
[编者按] 刘斌,OneAPM后端研发工程师,拥有10多年编程经验,参与过大型金融.通信以及Android手机操作系的开发,熟悉Linux及后台开发技术.曾参与翻译过<第一本Docker书> ...
- kubernetes之监控Prometheus实战--prometheus介绍--获取监控(一)
Prometheus介绍 Prometheus是一个最初在SoundCloud上构建的开源监控系统 .它现在是一个独立的开源项目,为了强调这一点,并说明项目的治理结构,Prometheus 于2016 ...
- Telegraf安装与介绍
Telegraf 是什么? Telegraf 是一个用 Go 编写的代理程序,是收集和报告指标和数据的代理.可收集系统和服务的统计数据,并写入到 InfluxDB 数据库.Telegraf 具有内存占 ...
随机推荐
- HDU 5934 强联通分量
Bomb Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Submis ...
- netconf选用秘钥登录
#! /usr/bin/python2.7import ncclientfrom ncclient import managerwith manager.connect(\ host="19 ...
- Hadoop(七)HDFS容错机制详解
前言 HDFS(Hadoop Distributed File System)是一个分布式文件系统.它具有高容错性并提供了高吞吐量的数据访问,非常适合大规模数据集上的应用,它提供了一个高度容错性和高吞 ...
- JAVA中子类会不会继承父类的构造方法
声明:刚刚接触java不久,如果理解有错误或偏差望各位大佬强势批判 java中子类能继承父类的构造方法吗? 父类代码: class Father { String name ; //就不set/get ...
- win10 uwp 自定义控件初始化
我遇到一个问题,我在 xaml 用了我的自定义控件,但是我给他设置了一个值,但是什么时候我才可以获得这个值? 本文告诉大家,从构造函数.loaded.Initialized 的调用过程. 用最简单的方 ...
- BZOJ-3040-最短路(road)
Description N个点,M条边的有向图,求点1到点N的最短路(保证存在).1<=N<=1000000,1<=M<=10000000 Input 第一行两个整数N.M,表 ...
- mongdb单节点安装方法
mongo单节点环境安装(linux) 安装包 下载地址: (https://www.mongodb.com/download-center) 用户权限/目录 创建 dbuser用户 groupadd ...
- gcd,最大公约数,lcm,最小公倍数
int gcd(int a,int b){ ?a:gcd(b,a%b); } 关于lcm,若写成a*b/gcd(a,b) ,a*b可能会溢出! int lcm(int a,int b){ return ...
- [Python] 文科生零基础学编程系列三——数据运算符的基本类别
上一篇:[Python] 文科生零基础学编程系列二--数据类型.变量.常量的基础概念 下一篇: ※ 程序的执行过程,就是对数据进行运算的过程. 不同的数据类型,可以进行不同的运算, 按照数据运算类型的 ...
- 使用prettytable美化python的print输出
经常碰到需要将一些数据用表格形式输出来.自己手动写太麻烦. 用prettytable能很好解决这个问题. ...(未完)