【Mysql知识补充】
一、子查询
1.定义
子查询是将一个查询语句嵌套在另一个查询语句中。内层查询语句的查询结果,可以为外层查询语句提供查询条件。子查询中可以包含:IN、NOT IN、ANY、ALL、EXISTS 和 NOT EXISTS等关键字,还可以包含比较运算符:= 、 !=、> 、<等。
2.举例
- 带IN关键字的子查询
#查看技术部员工姓名
select name from employee
where dep_id in
(select id from department where name='技术');
- 带比较运算符的子查询
#比较运算符:=、!=、>、>=、<、<=、<>
#查询大于所有人平均年龄的员工名与年龄 select name,age from emp where age > (select avg(age) from emp);
- 带EXISTS关键字的子查询
EXISTS关字键字表示存在。在使用EXISTS关键字时,内层查询语句不返回查询的记录,而是返回一个真假值:True或False;
当返回True时,外层查询语句将进行查询;当返回值为False时,外层查询语句不进行查询。
#department表中存在dept_id=205,False
mysql> select * from employee
-> where exists
-> (select id from department where id=204);
查询每个部门最新入职的那位员工
company.employee
员工id id int
姓名 emp_name varchar
性别 sex enum
年龄 age int
入职日期 hire_date date
岗位 post varchar
职位描述 post_comment varchar
薪水 salary double
办公室 office int
部门编号 depart_id int #创建表
create table employee(
id int not null unique auto_increment,
name varchar(20) not null,
sex enum('male','female') not null default 'male', #大部分是男的
age int(3) unsigned not null default 28,
hire_date date not null,
post varchar(50),
post_comment varchar(100),
salary double(15,2),
office int, #一个部门一个屋子
depart_id int
); #查看表结构
mysql> desc employee;
+--------------+-----------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------------+-----------------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(20) | NO | | NULL | |
| sex | enum('male','female') | NO | | male | |
| age | int(3) unsigned | NO | | 28 | |
| hire_date | date | NO | | NULL | |
| post | varchar(50) | YES | | NULL | |
| post_comment | varchar(100) | YES | | NULL | |
| salary | double(15,2) | YES | | NULL | |
| office | int(11) | YES | | NULL | |
| depart_id | int(11) | YES | | NULL | |
+--------------+-----------------------+------+-----+---------+----------------+ #插入记录
#三个部门:教学,销售,运营
insert into employee(name,sex,age,hire_date,post,salary,office,depart_id) values
('egon','male',18,'','老男孩驻沙河办事处外交大使',7300.33,401,1), #以下是教学部
('alex','male',78,'','teacher',1000000.31,401,1),
('wupeiqi','male',81,'','teacher',8300,401,1),
('yuanhao','male',73,'','teacher',3500,401,1),
('liwenzhou','male',28,'','teacher',2100,401,1),
('jingliyang','female',18,'','teacher',9000,401,1),
('jinxin','male',18,'','teacher',30000,401,1),
('成龙','male',48,'','teacher',10000,401,1), ('歪歪','female',48,'','sale',3000.13,402,2),#以下是销售部门
('丫丫','female',38,'','sale',2000.35,402,2),
('丁丁','female',18,'','sale',1000.37,402,2),
('星星','female',18,'','sale',3000.29,402,2),
('格格','female',28,'','sale',4000.33,402,2), ('张野','male',28,'','operation',10000.13,403,3), #以下是运营部门
('程咬金','male',18,'','operation',20000,403,3),
('程咬银','female',18,'','operation',19000,403,3),
('程咬铜','male',18,'','operation',18000,403,3),
('程咬铁','female',18,'','operation',17000,403,3)
;
创建表
alter table employee rename emp;#修改表名 SELECT
*
FROM
emp AS t1
INNER JOIN (
SELECT
post,
max(hire_date) max_date
FROM
emp
GROUP BY
post
) AS t2 ON t1.post = t2.post
WHERE
t1.hire_date = t2.max_date;
联表查询
补充:
SELECT语句关键字的执行顺序
(7) SELECT
(8) DISTINCT <select_list>
(1) FROM <left_table>
(3) <join_type> JOIN <right_table>
(2) ON <join_condition>
(4) WHERE <where_condition>
(5) GROUP BY <group_by_list>
(6) HAVING <having_condition>
(9) ORDER BY <order_by_condition>
(10) LIMIT <limit_number>
二、索引
1.定义
索引在MySQL中也叫做“键”,是存储引擎用于快速找到记录的一种数据结构。
索引相当于字典的音序表,如果要查某个字,如果不使用音序表,则需要从几百页中逐页去查。索引优化应该是对查询性能优化最有效的手段了。索引能够轻易将查询性能提高好几个数量级。
2.原理
索引的目的在于提高查询效率,与我们查阅图书所用的目录是一个道理:先定位到章,然后定位到该章下的一个小节,然后找到页数。相似的例子还有:查字典,查火车车次,飞机航班等。
本质都是:通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。
3.索引的数据结构
- B+树
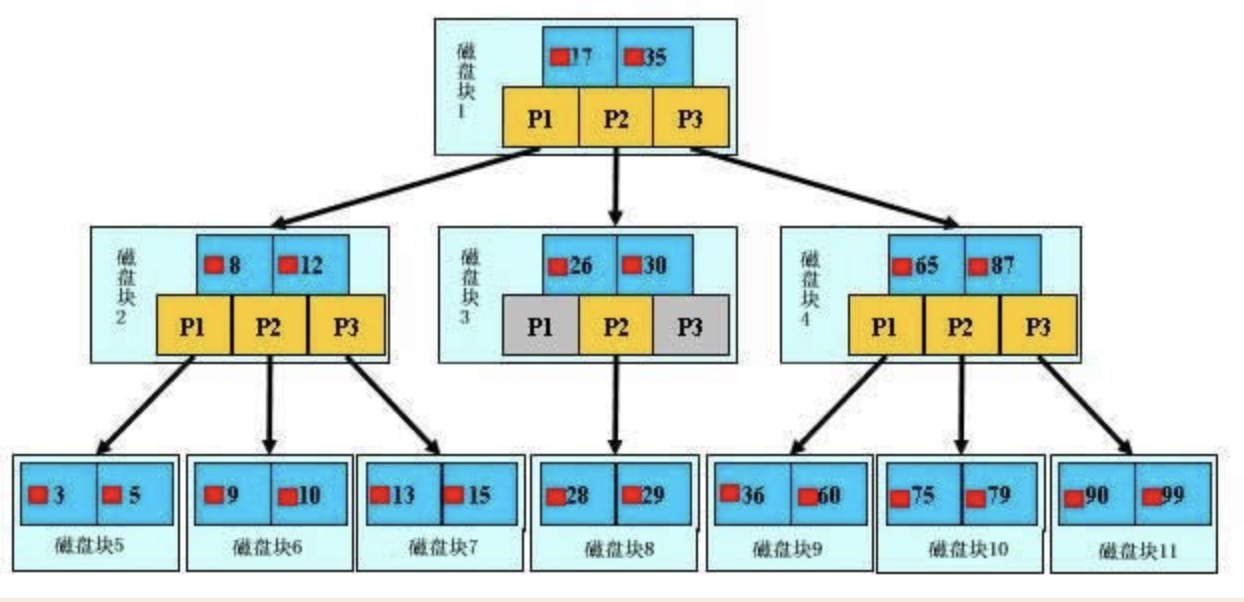
如上图,是一颗b+树,关于b+树的定义可以参见B+树,这里只说一些重点,浅蓝色的块我们称之为一个磁盘块,可以看到每个磁盘块包含几个数据项(深蓝色所示)和指针(黄色所示),如磁盘块1包含数据项17和35,包含指针P1、P2、P3,P1表示小于17的磁盘块,P2表示在17和35之间的磁盘块,P3表示大于35的磁盘块。真实的数据存在于叶子节点即3、5、9、10、13、15、28、29、36、60、75、79、90、99。非叶子节点不存储真实的数据,只存储指引搜索方向的数据项,如17、35并不真实存在于数据表中。
- b+树的查找过程
如图所示,如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。
三、视图
1、定义
视图是一个虚拟表(非真实存在),其本质是【根据SQL语句获取动态的数据集,并为其命名】,用户使用时只需使用【名称】即可获取结果集,可以将该结果集当做表来使用。
使用视图我们可以把查询过程中的临时表摘出来,用视图去实现,这样以后再想操作该临时表的数据时就无需重写复杂的sql了,直接去视图中查找即可,但视图有明显地效率问题,并且视图是存放在数据库中的,如果我们程序中使用的sql过分依赖数据库中的视图,即强耦合,那就意味着扩展sql极为不便,因此并不推荐使用
2、创建视图
#语法:CREATE VIEW 视图名称 AS SQL语句
create view teacher_view as select tid from teacher where tname='李平老师'; #于是查询李平老师教授的课程名的sql可以改写为
mysql> select cname from course where teacher_id = (select tid from teacher_view);
+--------+
| cname |
+--------+
| 物理 |
| 美术 |
+--------+
rows in set (0.00 sec) 注意:
#1. 使用视图以后就无需每次都重写子查询的sql,但是这么效率并不高,还不如我们写子查询的效率高 #2. 而且有一个致命的问题:视图是存放到数据库里的,如果我们程序中的sql过分依赖于数据库中存放的视图,那么意味着,一旦sql需要修改且涉及到视图的部分,则必须去数据库中进行修改,而通常在公司中数据库有专门的DBA负责,你要想完成修改,必须付出大量的沟通成本DBA可能才会帮你完成修改,极其地不方便
3、修改视图
语法:ALTER VIEW 视图名称 AS SQL语句
mysql> alter view teacher_view as select * from course where cid>3;
4、删除视图
语法:DROP VIEW 视图名称 DROP VIEW teacher_view
四、触发器
使用触发器可以定制用户对表进行【增、删、改】操作时前后的行为,注意:没有查询
1、创建触发器
# 插入前
CREATE TRIGGER tri_before_insert_tb1 BEFORE INSERT ON tb1 FOR EACH ROW
BEGIN
...
END # 插入后
CREATE TRIGGER tri_after_insert_tb1 AFTER INSERT ON tb1 FOR EACH ROW
BEGIN
...
END # 删除前
CREATE TRIGGER tri_before_delete_tb1 BEFORE DELETE ON tb1 FOR EACH ROW
BEGIN
...
END # 删除后
CREATE TRIGGER tri_after_delete_tb1 AFTER DELETE ON tb1 FOR EACH ROW
BEGIN
...
END # 更新前
CREATE TRIGGER tri_before_update_tb1 BEFORE UPDATE ON tb1 FOR EACH ROW
BEGIN
...
END # 更新后
CREATE TRIGGER tri_after_update_tb1 AFTER UPDATE ON tb1 FOR EACH ROW
BEGIN
...
END
创建触发器
例
NEW表示即将插入的数据行,OLD表示即将删除的数据行。
#准备表
CREATE TABLE cmd (
id INT PRIMARY KEY auto_increment,
USER CHAR (32),
priv CHAR (10),
cmd CHAR (64),
sub_time datetime, #提交时间
success enum ('yes', 'no') #0代表执行失败
); CREATE TABLE errlog (
id INT PRIMARY KEY auto_increment,
err_cmd CHAR (64),
err_time datetime
); #创建触发器
delimiter //
CREATE TRIGGER tri_after_insert_cmd AFTER INSERT ON cmd FOR EACH ROW
BEGIN
IF NEW.success = 'no' THEN #等值判断只有一个等号
INSERT INTO errlog(err_cmd, err_time) VALUES(NEW.cmd, NEW.sub_time) ; #必须加分号
END IF ; #必须加分号
END//
delimiter ; #往表cmd中插入记录,触发触发器,根据IF的条件决定是否插入错误日志
INSERT INTO cmd (
USER,
priv,
cmd,
sub_time,
success
)
VALUES
('egon','','ls -l /etc',NOW(),'yes'),
('egon','','cat /etc/passwd',NOW(),'no'),
('egon','','useradd xxx',NOW(),'no'),
('egon','','ps aux',NOW(),'yes'); #查询错误日志,发现有两条
mysql> select * from errlog;
+----+-----------------+---------------------+
| id | err_cmd | err_time |
+----+-----------------+---------------------+
| 1 | cat /etc/passwd | 2017-09-14 22:18:48 |
| 2 | useradd xxx | 2017-09-14 22:18:48 |
+----+-----------------+---------------------+
rows in set (0.00 sec)
2、删除触发器
drop trigger tri_after_insert_cmd;
五、事务
事务用于将某些操作的多个SQL作为原子性操作,一旦有某一个出现错误,即可回滚到原来的状态,从而保证数据库数据完整性。
START TRANSACTION或BEGIN语句可以开始一项新的事务。
COMMIT可以提交当前事务,是变更成为永久变更。
ROLLBACK可以 回滚当前事务,取消其变更。
SET AUTOCOMMIT语句可以禁用或启用默认的autocommit模式,用于当前连接。
create table user(
id int primary key auto_increment,
name char(32),
balance int
); insert into user(name,balance)
values
('wsb',1000),
('egon',1000),
('ysb',1000); #原子操作
start transaction;
update user set balance=900 where name='wsb'; #买支付100元
update user set balance=1010 where name='egon'; #中介拿走10元
update user set balance=1090 where name='ysb'; #卖家拿到90元
commit; #出现异常,回滚到初始状态
start transaction;
update user set balance=900 where name='wsb'; #买支付100元
update user set balance=1010 where name='egon'; #中介拿走10元
uppdate user set balance=1090 where name='ysb'; #卖家拿到90元,出现异常没有拿到
rollback;
commit;
mysql> select * from user;
+----+------+---------+
| id | name | balance |
+----+------+---------+
| 1 | wsb | 1000 |
| 2 | egon | 1000 |
| 3 | ysb | 1000 |
+----+------+---------+
rows in set (0.00 sec)
六、存储过程
存储过程包含了一系列可执行的sql语句,存储过程存放于MySQL中,通过调用它的名字可以执行其内部的一堆sql
使用存储过程的优点:
#1. 用于替代程序写的SQL语句,实现程序与sql解耦 #2. 基于网络传输,传别名的数据量小,而直接传sql数据量大
使用存储过程的缺点:
#1. 程序员扩展功能不方便
- 创建存储过程
delimiter //
create procedure p1()
BEGIN
select * from blog;
INSERT into blog(name,sub_time) values("xxx",now());
END //
delimiter ; #在mysql中调用
call p1() #在python中基于pymysql调用
cursor.callproc('p1')
print(cursor.fetchall())
七、自定义函数
函数中不要写sql语句(否则会报错),函数仅仅只是一个功能,是一个在sql中被应用的功能。若要想在begin...end...中写sql,请用存储过程
- 创建函数
delimiter //
create function f1(
i1 int,
i2 int)
returns int
BEGIN
declare num int;
set num = i1 + i2;
return(num);
END //
delimiter ;
- 执行函数
# 获取返回值
select UPPER('egon') into @res;
SELECT @res; # 在查询中使用
select f1(11,nid) ,name from tb2;
八、流程控制
1、条件语句
delimiter //
CREATE PROCEDURE proc_if ()
BEGIN declare i int default 0;
if i = 1 THEN
SELECT 1;
ELSEIF i = 2 THEN
SELECT 2;
ELSE
SELECT 7;
END IF; END //
delimiter ;
2、循环语句
delimiter //
CREATE PROCEDURE proc_while ()
BEGIN DECLARE num INT ;
SET num = 0 ;
WHILE num < 10 DO
SELECT
num ;
SET num = num + 1 ;
END WHILE ; END //
delimiter ;
【Mysql知识补充】的更多相关文章
- [mysql]知识补充
知识概况 视图 函数 存储过程 事务 索引 触发器 [视图] 视图是一个虚拟表,可以实现查询功能,不能进行增删改 本质:根据sql语句获取动态的数据集,并为其命名 1.创建视图 --create vi ...
- MySQL知识补充(表字段操作、视图、触发器、事物、存储过程、内置函数、流程控制、索引、慢查询)
今日内容概要 表字段操作补充(掌握) 视图(了解) 触发器(了解) 事务(掌握) 存储过程(了解) 内置函数(了解) 流程控制(了解) 索引(熟悉) 内容详细 1.表字段操作补充 # 1.添加表字段 ...
- Redis基础知识补充及持久化、备份介绍(二)--技术流ken
Redis知识补充 在上一篇博客<Redis基础认识及常用命令使用(一)--技术流ken>中已经介绍了redis的一些基础知识,以及常用命令的使用,本篇博客将补充一些基础知识以及redis ...
- SQL语句之 知识补充
SQL语句之 知识补充 一.存储过程 运用SQL语句,写出一个像函数的模块,这就是存储过程. 需求: 编写存储过程,查询所有员工 -- 创建存储过程(必须要指定结束符号) -- 定义结束符号 DELI ...
- Redis基础知识补充及持久化、备份介绍
Redis知识补充 在上一篇博客<Redis基础认识及常用命令使用(一)–技术流ken>中已经介绍了redis的一些基础知识,以及常用命令的使用,本篇博客将补充一些基础知识以及redis持 ...
- 大数据学习day23-----spark06--------1. Spark执行流程(知识补充:RDD的依赖关系)2. Repartition和coalesce算子的区别 3.触发多次actions时,速度不一样 4. RDD的深入理解(错误例子,RDD数据是如何获取的)5 购物的相关计算
1. Spark执行流程 知识补充:RDD的依赖关系 RDD的依赖关系分为两类:窄依赖(Narrow Dependency)和宽依赖(Shuffle Dependency) (1)窄依赖 窄依赖指的是 ...
- MySQL知识树-查询语句
在日常的web应用开发过程中,一般会涉及到数据库方面的操作,其中查询又是占绝大部分的.我们不仅要会写查询,最好能系统的学习下与查询相关的知识点,这篇随笔我们就来一起看看MySQL查询知识相关的树是什么 ...
- 两个容易被忽略的mysql知识
原文:两个容易被忽略的mysql知识 为什么标题要起这个名字呢?commen sence指的是那些大家都应该知道的事情,但往往大家又会会略这些东西,或者对这些东西一知半解,今天我总结下自己在mysql ...
- CRM中QueryDict和模型表知识补充
CRM中QueryDict和模型表知识补充 1.QueryDict的用法 request.GET的用法:1.在页面上输入:http://127.0.0.1:8000/index/print(reque ...
随机推荐
- Django(二)
QuerySet与惰性机制: 所谓惰性机制:Publisher.objects.all()或者所谓惰性机制:Publisher.objects.all()或者.filter()等都只是返回了一个Que ...
- Java 获取SQL查询语句结果
step1:构造连接Class.forName("com.mysql.jdbc.Driver"); Connection con = DriverManager.getConnec ...
- 浏览器缓存相关HTTP头部字段
1.Cache-Control/Pragma 2.Expires 3.Last-Modified/Etag
- ip完整验证详情
不想跳坑就看一下 之前一直不太会写正则表达式,很多要用到正则表达式的都直接百度,像上次要用正则表达式验证是否是合法的ip地址,然后就上网找,结果就是没找到一个对的,今天就为大家贡献一下,写个对的,并做 ...
- LeetCode 283. Move Zeroes (移动零)
Given an array nums, write a function to move all 0's to the end of it while maintaining the relativ ...
- maven 集成tomcat6,tomcat7
1. maven 集成 tomcat6的配置 maven自带的是tomcat6插件,所以不配置的话也可以,默认tomcat6,8080端口,需要更改端口或者编码方式等,也可以自己再配置一次: < ...
- oracle赋值问题(将同一表中某一字段赋值给另外一个字段的语句)
将同一表中某一字段赋值给另外一个字段的语句update jxc_ckmx ckmx1 set ckmx1.ddsl = (select ckmx2.sl from jxc_ckmx ckmx2 whe ...
- JS框架设计读书笔记之-选择器引擎01
选择符 选择符是指CSS样式规则最左边的部分,例如 p{},#id{},.class{},p.class{} 等等 总共可以分为四大类: 并联选择器 => 逗号 => $('div,spa ...
- 1041: [HAOI2008]圆上的整点
1041: [HAOI2008]圆上的整点 Time Limit: 10 Sec Memory Limit: 162 MBSubmit: 4298 Solved: 1944[Submit][Sta ...
- 关于Spring在多线程下的个人疑问
在Web开发中,不可避免的是需要遇到并发操作的,并发操作就有可能会引发我们的多线程安全问题.比如说,我们多线程下访问同一个变量并且有一个线程做出修改那么就会使得我们另外的线程在不知情的情况下被修改自己 ...