ida和idr机制分析(盘符分配机制)
内核ida和idr机制分析(盘符分配机制)
ida和idr的机制在我个人看来,是内核管理整数资源的一种方法。在内核中,许多地方都用到了该结构(例如class的id,disk的id),更直观的说,硬盘的sda到sdz的自动排序也是依靠该机制。使用该结构的好处是可以管理大量的整数资源并且检索的时候非常高效。但是,使用该机制的另一个弊端就是:同一个槽位的硬盘进行拔插的时候,如果之前申请的整数资源没有来得及释放,那么可能会产生盘符漂移现象。这给上层软件对盘符的管理带来了困难。在本篇博文中,对具体如何解决盘符漂移不做说明。
在根据代码说明之前,我想先介绍一下该机制对整型数的灵活应用。int数值一般来说,为4个字节。那么将一个int数分为4部分的结果就是每部分8bit。在idr的机制中,采用树来管理资源,int数值的一个字节,被抽象成了树中的一层。即:对某个int值从又向左数,分别是第一层、第二层、第三层、第四层。第一层必须要有,第一层一般是树叶层。该idr树的生长方式也是从树叶开始,随着不断的生长,最开始,树根就是树叶,到最后,树根处于第四层,树叶还是第一层。特别注意说明的是,idr还有一个第0层的概念。在第0层上,可以比喻成树叶上水珠。
之前的文字描述可能比较抽象,而且也可能不太准确。下面用一个图来表示这种关系。
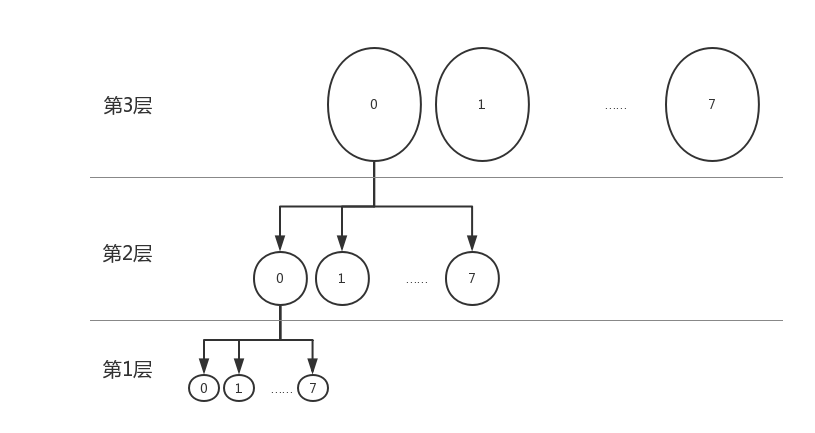
假设我们现在有个a=0x0001,那么a在图中对应第一层中的1。如果有个b=0x0011,那么就必须从第二层的1上生长出一个和第一层一样的结构,再在这上面找到1.如图所示:
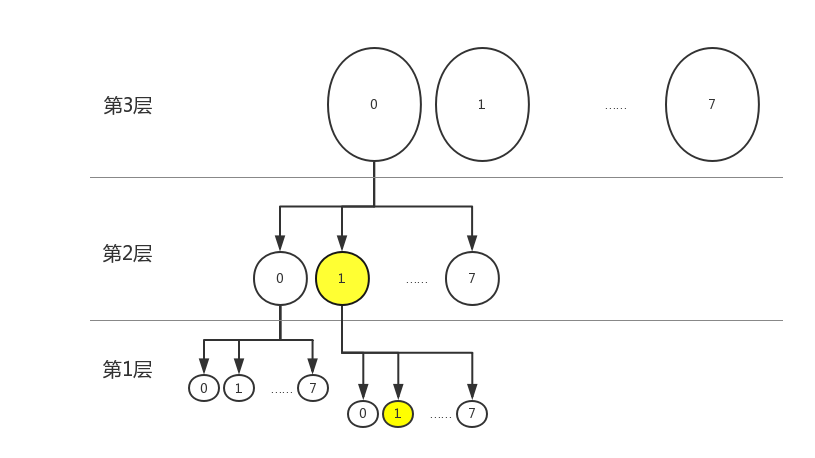
当然,如果该树管理的最大资源,还没有涉及到第三层,即最大的数第三个字节都是0,那么其实是没有必要维护第三层的。
此外,该图只是形象的说明了idr的思想,但与实际的代码并不完全一样,具体细节还需要接下来慢慢结合代码分析。在分析代码之前,再介绍一下常用运算符抑或。请观察下面的运算式:((m >> 8) & (0xF) ^ (m >> 8) ^ (0x5)) << 8 该运算的作用是将m的第二个字节置为5,第三个第四个字节不变,第一个字节清零。
下面开始结合代码分析,先分别给出ida和idr的结构说明:
168 struct ida {
169 struct idr idr;
170 struct ida_bitmap *free_bitmap;
171 };
163 struct ida_bitmap {
164 long nr_busy;
165 unsigned long bitmap[IDA_BITMAP_LONGS];
166 };
idr代表着上面介绍的那一棵树,因此可见,ida只是对这棵树的封装,在idr树的基础上,统一了管理办法。
42 struct idr {
43 struct idr_layer __rcu *hint; /* the last layer allocated from */
44 struct idr_layer __rcu *top;
45 int layers; /* only valid w/o concurrent changes */
46 int cur; /* current pos for cyclic allocation */
47 spinlock_t lock;
48 int id_free_cnt;
49 struct idr_layer *id_free;
50 };
30 struct idr_layer {
31 int prefix; /* the ID prefix of this idr_layer */
32 int layer; /* distance from leaf */
33 struct idr_layer __rcu *ary[1<<IDR_BITS];
34 int count; /* When zero, we can release it */
35 union {
36 /* A zero bit means "space here" */
37 DECLARE_BITMAP(bitmap, IDR_SIZE);
38 struct rcu_head rcu_head;
39 };
40 };
idr代表图中的那棵树,idr_layer代表着图上的每个圆球,而其中的ary数组代表着每个圆球下的箭头,bitmap位图用来记录该位置下的子layer是否还有空位,如果没有将置1.
获取idr资源主要由两个api来管理。ida_pre_get和ida_get_new_above。前者负责按照该树可承载的最多layer数量申请layer资源,并存放到资源池中。后者可以指定从某个id开始,寻找下一个未被使用的id。
896 int ida_pre_get(struct ida *ida, gfp_t gfp_mask)
897 {
898 /* allocate idr_layers */
899 if (!__idr_pre_get(&ida->idr, gfp_mask))
900 return 0;
901
902 /* allocate free_bitmap */
903 if (!ida->free_bitmap) {
904 struct ida_bitmap *bitmap;
905
906 bitmap = kmalloc(sizeof(struct ida_bitmap), gfp_mask);
907 if (!bitmap)
908 return 0;
909
910 free_bitmap(ida, bitmap);
911 }
912
913 return 1;
914 }
192 static int __idr_pre_get(struct idr *idp, gfp_t gfp_mask)
193 {
194 while (idp->id_free_cnt < MAX_IDR_FREE) {
195 struct idr_layer *new;
196 new = kmem_cache_zalloc(idr_layer_cache, gfp_mask);
197 if (new == NULL)
198 return (0);
199 move_to_free_list(idp, new);
200 }
201 return 1;
202 }
160 static void move_to_free_list(struct idr *idp, struct idr_layer *p)
161 {
162 unsigned long flags;
163
164 /*
165 * Depends on the return element being zeroed.
166 */
167 spin_lock_irqsave(&idp->lock, flags);
168 __move_to_free_list(idp, p);
169 spin_unlock_irqrestore(&idp->lock, flags);
170 }
153 static void __move_to_free_list(struct idr *idp, struct idr_layer *p)
154 {
155 p->ary[0] = idp->id_free;
156 idp->id_free = p;
157 idp->id_free_cnt++;
158 }
868 static void free_bitmap(struct ida *ida, struct ida_bitmap *bitmap)
869 {
870 unsigned long flags;
871
872 if (!ida->free_bitmap) {
873 spin_lock_irqsave(&ida->idr.lock, flags);
874 if (!ida->free_bitmap) {
875 ida->free_bitmap = bitmap;
876 bitmap = NULL;
877 }
878 spin_unlock_irqrestore(&ida->idr.lock, flags);
879 }
880
881 kfree(bitmap);
882 }
899行调用__idr_pre_get分配layer。在该函数内,分配MAX_IDR_FREE个layer,之后使用move_to_free_list函数进行保存。153行可以看出,所有的未使用layer都通过idr里的id_free连接起来,layer之间通过ary[0]连接。这样,创建的资源,在之后需要使用的时候,直接取就可以了,可以节省运行时间,提高性能。
ida内还有个free_bitmap域,由于该域的操作涉及到竞争,因此,放到自旋锁中处理。881行的free是因为,防止某个线程申请好了资源,但是有一个线程比他还快,已经进入了874行。那么等之后他获取到锁后,直接不需要进入if分支,释放之前申请的资源即可。
932 int ida_get_new_above(struct ida *ida, int starting_id, int *p_id)
933 {
934 struct idr_layer *pa[MAX_IDR_LEVEL + 1];
935 struct ida_bitmap *bitmap;
936 unsigned long flags;
937 int idr_id = starting_id / IDA_BITMAP_BITS;
938 int offset = starting_id % IDA_BITMAP_BITS;
939 int t, id;
940
941 restart:
942 /* get vacant slot */
943 t = idr_get_empty_slot(&ida->idr, idr_id, pa, 0, &ida->idr);
944 if (t < 0)
945 return t == -ENOMEM ? -EAGAIN : t;
946
947 if (t * IDA_BITMAP_BITS >= MAX_IDR_BIT)
948 return -ENOSPC;
949
950 if (t != idr_id)
951 offset = 0;
952 idr_id = t;
953
954 /* if bitmap isn't there, create a new one */
955 bitmap = (void *)pa[0]->ary[idr_id & IDR_MASK];
956 if (!bitmap) {
957 spin_lock_irqsave(&ida->idr.lock, flags);
958 bitmap = ida->free_bitmap;
959 ida->free_bitmap = NULL;
960 spin_unlock_irqrestore(&ida->idr.lock, flags);
961
962 if (!bitmap)
963 return -EAGAIN;
964
965 memset(bitmap, 0, sizeof(struct ida_bitmap));
966 rcu_assign_pointer(pa[0]->ary[idr_id & IDR_MASK],
967 (void *)bitmap);
968 pa[0]->count++;
969 }
970
971 /* lookup for empty slot */
972 t = find_next_zero_bit(bitmap->bitmap, IDA_BITMAP_BITS, offset);
973 if (t == IDA_BITMAP_BITS) {
974 /* no empty slot after offset, continue to the next chunk */
975 idr_id++;
976 offset = 0;
977 goto restart;
978 }
979
980 id = idr_id * IDA_BITMAP_BITS + t;
981 if (id >= MAX_IDR_BIT)
982 return -ENOSPC;
983
984 __set_bit(t, bitmap->bitmap);
985 if (++bitmap->nr_busy == IDA_BITMAP_BITS)
986 idr_mark_full(pa, idr_id);
987
988 *p_id = id;
989
990 /* Each leaf node can handle nearly a thousand slots and the
991 * whole idea of ida is to have small memory foot print.
992 * Throw away extra resources one by one after each successful
993 * allocation.
994 */
995 if (ida->idr.id_free_cnt || ida->free_bitmap) {
996 struct idr_layer *p = get_from_free_list(&ida->idr);
997 if (p)
998 kmem_cache_free(idr_layer_cache, p);
999 }
1000
1001 return 0;
1002 }
289 static int idr_get_empty_slot(struct idr *idp, int starting_id,
290 struct idr_layer **pa, gfp_t gfp_mask,
291 struct idr *layer_idr)
292 {
293 struct idr_layer *p, *new;
294 int layers, v, id;
295 unsigned long flags;
296
297 id = starting_id;
298 build_up:
299 p = idp->top;
300 layers = idp->layers;
301 if (unlikely(!p)) {
302 if (!(p = idr_layer_alloc(gfp_mask, layer_idr)))
303 return -ENOMEM;
304 p->layer = 0;
305 layers = 1;
306 }
307 /*
308 * Add a new layer to the top of the tree if the requested
309 * id is larger than the currently allocated space.
310 */
311 while (id > idr_max(layers)) {
312 layers++;
313 if (!p->count) {
314 /* special case: if the tree is currently empty,
315 * then we grow the tree by moving the top node
316 * upwards.
317 */
318 p->layer++;
319 WARN_ON_ONCE(p->prefix);
320 continue;
321 }
322 if (!(new = idr_layer_alloc(gfp_mask, layer_idr))) {
323 /*
324 * The allocation failed. If we built part of
325 * the structure tear it down.
326 */
327 spin_lock_irqsave(&idp->lock, flags);
328 for (new = p; p && p != idp->top; new = p) {
329 p = p->ary[0];
330 new->ary[0] = NULL;
331 new->count = 0;
332 bitmap_clear(new->bitmap, 0, IDR_SIZE);
333 __move_to_free_list(idp, new);
334 }
335 spin_unlock_irqrestore(&idp->lock, flags);
336 return -ENOMEM;
337 }
338 new->ary[0] = p;
339 new->count = 1;
340 new->layer = layers-1;
341 new->prefix = id & idr_layer_prefix_mask(new->layer);
342 if (bitmap_full(p->bitmap, IDR_SIZE))
343 __set_bit(0, new->bitmap);
344 p = new;
345 }
346 rcu_assign_pointer(idp->top, p);
347 idp->layers = layers;
348 v = sub_alloc(idp, &id, pa, gfp_mask, layer_idr);
349 if (v == -EAGAIN)
350 goto build_up;
351 return(v);
352 }
220 static int sub_alloc(struct idr *idp, int *starting_id, struct idr_layer **pa,
221 gfp_t gfp_mask, struct idr *layer_idr)
222 {
223 int n, m, sh;
224 struct idr_layer *p, *new;
225 int l, id, oid;
226
227 id = *starting_id;
228 restart:
229 p = idp->top;
230 l = idp->layers;
231 pa[l--] = NULL;
232 while (1) {
233 /*
234 * We run around this while until we reach the leaf node...
235 */
236 n = (id >> (IDR_BITS*l)) & IDR_MASK;
237 m = find_next_zero_bit(p->bitmap, IDR_SIZE, n);
238 if (m == IDR_SIZE) {
239 /* no space available go back to previous layer. */
240 l++;
241 oid = id;
242 id = (id | ((1 << (IDR_BITS * l)) - 1)) + 1;
243
244 /* if already at the top layer, we need to grow */
245 if (id > idr_max(idp->layers)) {
246 *starting_id = id;
247 return -EAGAIN;
248 }
249 p = pa[l];
250 BUG_ON(!p);
251
252 /* If we need to go up one layer, continue the
253 * loop; otherwise, restart from the top.
254 */
255 sh = IDR_BITS * (l + 1);
256 if (oid >> sh == id >> sh)
257 continue;
258 else
259 goto restart;
260 }
261 if (m != n) {
262 sh = IDR_BITS*l;
263 id = ((id >> sh) ^ n ^ m) << sh;
264 }
265 if ((id >= MAX_IDR_BIT) || (id < 0))
266 return -ENOSPC;
267 if (l == 0)
268 break;
269 /*
270 * Create the layer below if it is missing.
271 */
272 if (!p->ary[m]) {
273 new = idr_layer_alloc(gfp_mask, layer_idr);
274 if (!new)
275 return -ENOMEM;
276 new->layer = l-1;
277 new->prefix = id & idr_layer_prefix_mask(new->layer);
278 rcu_assign_pointer(p->ary[m], new);
279 p->count++;
280 }
281 pa[l--] = p;
282 p = p->ary[m];
283 }
284
285 pa[l] = p;
286 return id;
287 }
由于代码较长。为了方便叙述,假设当前idr树中没有被使用的id。现在调用ida_get_new_above从0开始找下一个可用的id。由于我们给出了假设,因此可以预期到得到的结果是0.我们带着这样的假设去分析代码。
943行进入idr_get_empty_slot。301行由于是第一次申请id,因此将进入该分支,分配一个top,即根节点。此时,304行看出根节点层数为第0层。305行layers表示总层数,为1层。由于是从0开始分配,因此311行循环不进入,直接跳过。346行通过rcu方式配置了top域。348行开始真正分配。
该函数工作开始,保存了几个量,如227~230所示。考虑到我们从0开始,则id=0,p为刚刚分配的根节点,l=1。232行的循环是为了使l>1时,能不断遍历到第0层。237行得到m=0.if分支显然不会进入,跳过。由于231行l--,所以267行的时候,跳出循环。285行保存了根节点,之后返回0.
回到943行,t取到0.pa[0]内保存的一定是叶子节点的地址。我们这里因为只有1层,根节点就是叶子节点。955行显然取到一个NULL,那么将ida中的free_bitmap转交给它,并在966行转交给根节点的ary[0]。972行检测当前层数是否还有剩余空位,这里需要说明的是,一般情况下,一个节点(layer)管理8*128个id,这种管理就是直接通过数组进行管理的。这个数组就是ida申请的数组,在该函数内通过强转保存到了ary[0]内。那么此时,肯定返回0. 980行id=0.984行配置相应位为1. 985~986行判断该节点是否已满,如果之后没有空闲了,将设置为该位置已满。这是通过根节点下的bitmap去设置的。988行将id值赋给p_id,之后返回。
在这里,将对之前的假设做出一个纠正。我们开始假设是从0开始寻找,是假设ida_get_new_above里的参数staring_id是从哪个数开始查找的意思。实际上,通过走读分析,我们可以看到,该starting_id其实代表某个layer。
通过这样的分析,相信对于整个流程已经有了简单的认知。代码其他部分主要涉及到stating_id指定的layer不存在,分配新的layer。或者starting_id超过了当前层数所能提供的最大id,则idr必须开始生长的过程。对于这些部分,相信经过前面的分析,这些都已经变的很简单,本文不再详细说明。留给读者自行分析。
ida和idr机制分析(盘符分配机制)的更多相关文章
- Linux 线程实现机制分析 Linux 线程实现机制分析 Linux 线程模型的比较:LinuxThreads 和 NPTL
Linux 线程实现机制分析 Linux 线程实现机制分析 Linux 线程模型的比较:LinuxThreads 和 NPTL http://www.ibm.com/developerworks/c ...
- [转]Linux 线程实现机制分析 Linux 线程实现机制分析 Linux 线程模型的比较:LinuxThreads 和 NPTL
转载地址:https://www.cnblogs.com/MYSQLZOUQI/p/4233630.html 自从多线程编程的概念出现在 Linux 中以来,Linux 多线应用的发展总是与两个问题脱 ...
- [置顶] NGINX原理分析之SLAB分配机制
一.基础概述 如果使用伙伴系统分配和释放算法,不仅会造成大量的内存碎片,同时处理效率也比较低.SLAB是一种内存管理机制,其核心思想是预分配.SLAB是将空间按照SIZE对内存进行分类管理的,当申请一 ...
- NGINX原理分析 之 SLAB分配机制
1 引言 众所周知,操作系统使用伙伴系统管理内存,不仅会造成大量的内存碎片,同时处理效率也较低下.SLAB是一种内存管理机制,其拥有较高的处理效率,同时也 有效的避免内存碎片的产生,其核心思想是预分配 ...
- [转载]NGINX原理分析 之 SLAB分配机制
作者:邹祁峰 邮箱:Qifeng.zou.job@hotmail.com 博客:http://blog.csdn.net/qifengzou 日期:2013.09.15 23:19 转载请注明来自&q ...
- Linux盘符绑定槽位
服务器下的硬盘主有机械硬盘.固态硬盘以及raid阵列,通常内核分配盘符的顺序是/dev/sda./dev/sdb- -.在系统启动过程中,内核会按照扫描到硬盘的顺序分配盘符(先分配直通的,再分配阵列) ...
- Linux 线程实现机制分析 Linux 线程模型的比较:LinuxThreads 和 NPTL
Linux 线程实现机制分析 Linux 线程实现机制分析 Linux 线程模型的比较:LinuxThreads 和 NPTL http://www.ibm.com/developerworks/c ...
- centos7 盘符变动 绑定槽位
服务器下的硬盘主有机械硬盘.固态硬盘以及raid阵列,通常内核分配盘符的顺序是/dev/sda./dev/sdb… ….在系统启动过程中,内核会按照扫描到硬盘的顺序分配盘符(先分配直通的,再分配阵列) ...
- EMC存储同时分配空间到两台服务器路径不一致-双机盘符不一致
以下方式将i盘盘符换成g盘,g盘盘符换成i emcpadm rename -s emcpoweri -t emcpowerj emcpadm rename -s emcpowerg -t emcpow ...
随机推荐
- el 表达式遍历Map
el 表达式遍历Map<c:forEach var="item" items="${payMentMap}"> <option value=& ...
- 浅谈IOC
一.引言 IOC-Invertion of Control,即控制反转,是一种程序设计思想,世上本没有路,走的人多了便有了路,本文将一步步带你了解IOC设计思想的演进之路. 在学习IOC之前我们先初步 ...
- Spring 极速集成注解 redis 实录
Redis 做为基于内存的 Key-Value 数据库,用来做缓存服务器性价比相当高. 官方推出的面向 Java 的 Client Jedis,提供了很多接口和方法,可以让 Java 操作使用 Red ...
- 懒人的小技巧, 批处理修改IP
相信很多人都有这样的麻烦, 工作单位的IP网段与住的不一致, 自己的笔记本在单位和回家的时候每次都要更改IP, 很麻烦, 偷个懒, 做了个批处理来修改IP,方便一点. 还有就是可以把工作的时候才需要 ...
- [图形学] 结束 [Unity Shader] 开始
历时4个月,终于把<计算机图形学 with OpenGL>啃完了.如果边上班边看,即使一年应该都看不完. 虽然书里用到的GLUT库应该已经废弃,但并不影响用它去理解图形学的内容,我只把它当 ...
- java 中的重载与重写 抽象类与接口的区别
. 重载与重写的区别: 重载(overload) | 重写(override) 1 方法的名称相同,参数个数.类型不同 | 方法名称.参数列表.返回值类型与父类完全相同 2 ...
- MS SQL Server Management Studio中提示不允许保长度出现不允许保存更改。您所做的更改要求删除并重新创建以下表
在SQL Server Management Studio中直接修改正在连接的表结构会出现改不了的情况,如下图 解决方法:工具-选项-设计器--阻止保存要求重新创建表的更改,去掉对勾--确定即可
- 一大波jQuery事件即将来袭!
一.jQuery事件 1.focus()元素获得焦点 2.blur()元素失去焦点 3.change() 表单元素的值发生变化(可用于验证用户名是否存在) 4.click() 鼠标单击 5.dbcli ...
- SVN常见问题
one or more files are in a conflicted state.(一个或多个文件处于矛盾状态)意思是这个文件已经被其他人修改过了. 然后我点击ok按钮后,找到冲突的文件再次up ...
- ASP.NET MVC5 怒跨 Linux 平台
安装CentOS 安装Mono #安装yum工具包 yum -y install yum-utils #通过rpm添加Mono源 rpm --import "http://keyserver ...