4 系统的 CPU 使用率很高,但为啥却找不到高 CPU的应用?
上一节讲了 CPU 使用率是什么,并通过一个案例教你使用 top、vmstat、pidstat 等工具,排查高 CPU 使用率的进程,然后再使用 perf top 工具,定位应用内部函数的问题。不过就有人留言了,说似乎感觉高 CPU 使用率的问题,还是挺容易排查的。那是不是所有 CPU 使用率高的问题,都可以这么分析呢?我想,你的答案应该是否定的。
回顾前面的内容,我们知道,系统的 CPU 使用率,不仅包括进程用户态和内核态的运行, 还包括中断处理、等待 I/O 以及内核线程等。所以,当你发现系统的 CPU 使用率很高的 时候,不一定能找到相对应的高 CPU 使用率的进程。
案例分析
准备
探究系统 CPU 使用率高的情况,所以这次实验的准备工作,与上节课的准备工作基本相同,差别在于案例所用的 Docker 镜像不同。
预先安装 docker、sysstat、perf、ab 等工具,如 yum install docker.io sysstat linux-tools-common apache2-utils ,ab(apache bench)是一个常用的 HTTP 服务性能测试工具,这里同样用来模拟 Nginx 的客户端。由于 Nginx 和 PHP 的配置比较麻烦,我把它们打包成了两个 Docker 镜像,这样只需要运行两个容器,就可以得到模拟环境。

其中一台用作 Web 服务器,来模拟性能问题;另一台用作 Web 服务器的客户端,来给 Web 服务增加压力请求。使用两台虚拟机是为了相互隔离,避免“交叉感染”。
docker run --name nginx -p 10000:80 -itd feisky/nginx:sp
docker run --name phpfpm -itd --network container:nginx feisky/php-fpm:sp 访问第一台机器
[root@bzhl ~]# curl http://23.106.155.240:10000/
It works!
测试
我们来测试一下这个 Nginx 服务的性能。在第二个终端运行下面的 ab 命令。要注意,与上次操作不同的是,这次我们需要并发 100 个请求测试 Nginx 性能,总共测试1000 个请求。
[root@bzhl ~]# ab -c 100 -n 1000 http://23.106.155.240:10000/ Complete requests: 1000
Failed requests: 0
Total transferred: 172000 bytes
HTML transferred: 9000 bytes
Requests per second: 112.08 [#/sec] (mean)
Time per request: 892.222 [ms] (mean)
Time per request: 8.922 [ms] (mean, across all concurrent requests)
Transfer rate: 18.83 [Kbytes/sec] received
从 ab 的输出结果我们可以看到,Nginx 能承受的每秒平均请求数,只有 112.08多一点,是不是感觉它的性能有点差呀。那么,到底是哪里出了问题呢?我们再用 top 和 pidstat 来观察一下。这次,我们在第二个终端,将测试的并发请求数改成 5,同时把请求时长设置为 10 分钟(-t 600)。这样,当你在第一个终端使用性能分析工具时, Nginx 的压力还是继续的。继续在第二个终端运行 ab 命令:
然后,我们在第一个终端运行 top 命令,观察系统的 CPU 使用情况:
top - 11:22:55 up 35 days, 21:36, 1 user, load average: 1.28, 0.52, 0.22
Tasks: 119 total, 6 running, 74 sleeping, 0 stopped, 0 zombie
%Cpu0 : 60.4 us, 14.7 sy, 0.0 ni, 24.6 id, 0.0 wa, 0.0 hi, 0.4 si, 0.0 st
%Cpu1 : 59.6 us, 15.7 sy, 0.0 ni, 22.3 id, 0.0 wa, 0.0 hi, 2.4 si, 0.0 st
KiB Mem : 2057308 total, 152184 free, 366672 used, 1538452 buff/cache
KiB Swap: 524284 total, 523760 free, 524 used. 1402364 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
32020 101 20 0 33104 3692 2276 S 3.7 0.2 0:01.67 nginx
2743 bin 20 0 336696 16064 8392 S 2.7 0.8 0:00.95 php-fpm
2752 bin 20 0 336696 16064 8392 S 2.3 0.8 0:00.96 php-fpm
2755 bin 20 0 336696 16064 8392 S 2.3 0.8 0:00.90 php-fpm
2738 bin 20 0 336696 16064 8392 S 2.0 0.8 0:00.95 php-fpm
2766 bin 20 0 336696 16064 8392 S 2.0 0.8 0:00.91 php-fpm
31726 root 20 0 655612 77988 39920 S 1.3 3.8 0:15.71 dockerd
31970 root 20 0 108756 8400 4504 S 1.3 0.4 0:00.87 containerd-shim
10 root 20 0 0 0 0 R 0.3 0.0 0:47.50 rcu_sched
6094 root 20 0 221712 20704 7596 S 0.3 1.0 32:23.52 python
1 root 20 0 125520 5220 3828 S 0.0 0.3 1:40.77 systemd
观察 top 输出的进程列表可以发现,CPU 使用率最高的进程也只不过才3.7%,看起来并不高。然而,再看系统 CPU 使用率( %Cpu )这一行,你会发现,系统的整体 CPU 使用率是比较高的:用户 CPU 使用率(us)已经到了 60%,系统 CPU 为 15.1%,而空闲 CPU(id)则只有 29%。为什么用户 CPU 使用率这么高呢?我们再重新分析一下进程列表,看看有没有可疑进程:
docker-containerd 进程是用来运行容器的,2.7% 的 CPU 使用率看起来正常;
Nginx 和 php-fpm 是运行 Web 服务的,它们会占用一些 CPU 也不意外,并且 2% 的CPU 使用率也不算高;
再往下看,后面的进程呢,只有 0.3% 的 CPU 使用率,看起来不太像会导致用户 CPU 使用率达到 80%。那就奇怪了,明明用户 CPU 使用率都 80% 了,可我们挨个分析了一遍进程列表,还是找不到高 CPU 使用率的进程。看来 top 是不管用了,那还有其他工具可以查看进程 CPU 使用情况吗?不知道你记不记得我们的老朋友 pidstat,它可以用来分析进程的 CPU 使用情况。
[root@doit ~]# pidstat 1
Linux 4.20.0-1.el7.elrepo.x86_64 (doit) 07/14/2019 _x86_64_ (2 CPU) 11:41:56 AM UID PID %usr %system %guest %wait %CPU CPU Command
11:41:57 AM 0 16 0.00 0.97 0.00 0.00 0.97 1 ksoftirqd/1
11:41:57 AM 1 7110 0.00 0.97 0.00 3.88 0.97 1 php-fpm
11:41:57 AM 1 7115 0.97 1.94 0.00 4.85 2.91 1 php-fpm
11:41:57 AM 1 7123 0.00 1.94 0.00 2.91 1.94 0 php-fpm
11:41:57 AM 1 7127 0.00 0.97 0.00 2.91 0.97 1 php-fpm
11:41:57 AM 1 7137 0.97 1.94 0.00 4.85 2.91 0 php-fpm
11:41:57 AM 0 24569 0.00 0.97 0.00 0.00 0.97 1 pidstat
11:41:57 AM 1 24780 0.00 2.91 0.00 0.00 2.91 1 php-fpm
11:41:57 AM 0 31726 0.97 0.00 0.00 0.00 0.97 1 dockerd
11:41:57 AM 0 31970 0.00 1.94 0.00 0.00 1.94 0 containerd-shim
11:41:57 AM 101 32020 0.97 1.94 0.00 11.65 2.91 0 nginx [root@doit ~]# uptime
11:42:56 up 35 days, 21:56, 1 user, load average: 2.82, 1.33, 0.81
观察一会儿,你是不是发现,所有进程的 CPU 使用率也都不高啊,最高的 Docker 和Nginx 也只有 4% 和 3%,即使所有进程的 CPU 使用率都加起来,也不过是 21%,离80% 还差得远呢!后来我发现,会出现这种情况,很可能是因为前面的分析漏了一些关键信息。你可以先暂 停一下,自己往上翻,重新操作检查一遍。或者,我们一起返回去分析 top 的输出,看看能不能有新发现。现在,我们回到第一个终端,重新运行 top 命令,并观察一会儿
top - 11:49:53 up 35 days, 22:03, 2 users, load average: 4.12, 3.15, 1.84
Tasks: 128 total, 4 running, 82 sleeping, 0 stopped, 0 zombie
%Cpu(s): 49.5 us, 12.6 sy, 0.0 ni, 36.7 id, 0.0 wa, 0.0 hi, 1.2 si, 0.0 st
KiB Mem : 2057308 total, 93240 free, 374216 used, 1589852 buff/cache
KiB Swap: 524284 total, 523760 free, 524 used. 1389000 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
32020 101 20 0 33104 3692 2276 S 2.6 0.2 0:21.73 nginx
12098 bin 20 0 336696 16064 8392 S 2.0 0.8 0:06.72 php-fpm
12124 bin 20 0 336696 16064 8392 S 2.0 0.8 0:06.70 php-fpm
31970 root 20 0 108756 8220 4504 S 2.0 0.4 0:13.37 containerd-shim
12075 bin 20 0 336696 16064 8392 S 1.7 0.8 0:06.89 php-fpm
12080 bin 20 0 336696 16064 8392 S 1.7 0.8 0:06.89 php-fpm
12083 bin 20 0 336696 16064 8392 S 1.7 0.8 0:06.66 php-fpm
31726 root 20 0 655612 77920 39920 S 1.0 3.8 0:22.63 dockerd
16 root 20 0 0 0 0 S 0.7 0.0 0:14.97 ksoftirqd/1
31383 bin 20 0 0 0 0 R 0.3 0.0 0:00.01 stress
这次从头开始看 top 的每行输出,咦?Tasks 这一行看起来有点奇怪,就绪队列中居然有6 个 Running 状态的进程(6 running),是不是有点多呢?回想一下 ab 测试的参数,并发请求数是 5。再看进程列表里, php-fpm 的数量也是 5, 再加上 Nginx,好像同时有 6 个进程也并不奇怪。但真的是这样吗?
再仔细看进程列表,这次主要看 Running(R) 状态的进程。你有没有发现, Nginx 和所有的 php-fpm 都处于 Sleep(S)状态,而真正处于 Running(R)状态的,却是几个stress 进程。这几个 stress 进程就比较奇怪了,需要我们做进一步的分析。
我们还是使用 pidstat 来分析这几个进程,并且使用 -p 选项指定进程的 PID。首先,从上面 top 的结果中,找到这几个进程的 PID。比如,先随便找一个 24344,然后用 pidstat 命令看一下它的 CPU 使用情况:
[root@doit ~]# pidstat -p 31383
Linux 4.20.0-1.el7.elrepo.x86_64 (doit) 07/14/2019 _x86_64_ (2 CPU)
11:50:40 AM UID PID %usr %system %guest %wait %CPU CPU Command
奇怪,居然没有任何输出。难道是 pidstat 命令出问题了吗?之前我说过,在怀疑性能工具出问题前,最好还是先用其他工具交叉确认一下。那用什么工具呢? ps 应该是最简单易用的。我们在终端里运行下面的命令,看看 24344 进程的状态: [root@doit ~]# ps aux |grep 31383
root 483 0.0 0.1 112720 2344 pts/1 S+ 11:51 0:00 grep --color=auto 31383
还是没有输出。现在终于发现问题,原来这个进程已经不存在了,所以 pidstat 就没有任何输出。既然进程都没了,那性能问题应该也跟着没了吧。我们再用 top 命令确认一下:
top - 11:53:11 up 35 days, 22:06, 2 users, load average: 2.46, 2.27, 1.71
Tasks: 126 total, 6 running, 75 sleeping, 0 stopped, 2 zombie
%Cpu(s): 53.8 us, 13.9 sy, 0.0 ni, 31.2 id, 0.0 wa, 0.0 hi, 1.0 si, 0.0 st
KiB Mem : 2057308 total, 125672 free, 353916 used, 1577720 buff/cache
KiB Swap: 524284 total, 523760 free, 524 used. 1412436 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
32020 101 20 0 33104 3692 2276 R 2.7 0.2 0:23.15 nginx
489 bin 20 0 336696 16064 8392 S 2.3 0.8 0:00.94 php-fpm
484 bin 20 0 336696 16064 8392 S 2.0 0.8 0:00.88 php-fpm
502 bin 20 0 336696 16064 8392 R 2.0 0.8 0:00.91 php-fpm
500 bin 20 0 336696 16064 8392 S 1.7 0.8 0:00.88 php-fpm
511 bin 20 0 336696 16064 8392 R 1.7 0.8 0:00.86 php-fpm
31970 root 20 0 108756 8340 4504 S 1.7 0.4 0:14.18 containerd-shim
31726 root 20 0 655612 77920 39920 S 1.0 3.8 0:23.15 dockerd
10 root 20 0 0 0 0 I 0.3 0.0 0:49.25 rcu_sched
11768 bin 20 0 8188 1624 540 R 0.3 0.1 0:00.01 stress
好像又错了。结果还跟原来一样,用户 CPU 使用率还是高达 80.9%,系统 CPU 接近15%,而空闲 CPU 只有 2.8%,Running 状态的进程有 Nginx、stress 等。
可是,刚刚我们看到 stress 进程不存在了,怎么现在还在运行呢?再细看一下 top 的输出,原来,这次 stress 进程的 PID 跟前面不一样了,原来的 PID 24344 不见了,现在的是 6779。
进程的 PID 在变,这说明什么呢?在我看来,要么是这些进程在不停地重启,要么就是全新的进程,这无非也就两个原因:
第一个原因,进程在不停地崩溃重启,比如因为段错误、配置错误等等,这时,进程在退出后可能又被监控系统自动重启了。
第二个原因,这些进程都是短时进程,也就是在其他应用内部通过 exec 调用的外面命令。这些命令一般都只运行很短的时间就会结束,你很难用 top 这种间隔时间比较长的工具发现(上面的案例,我们碰巧发现了)。
至于 stress,我们前面提到过,它是一个常用的压力测试工具。它的 PID 在不断变化中, 看起来像是被其他进程调用的短时进程。要想继续分析下去,还得找到它们的父进程。
要怎么查找一个进程的父进程呢?没错,用 pstree 就可以用树状形式显示所有进程之间的关系:
[root@doit ~]# pstree |grep stress
| | | |-php-fpm---sh---stress---stress
从这里可以看到,stress 是被 php-fpm 调用的子进程,并且进程数量不止一个(这里是3 个)。找到父进程后,我们能进入 app 的内部分析了。
首先,当然应该去看看它的源码。运行下面的命令,把案例应用的源码拷贝到 app 目录, 然后再执行 grep 查找是不是有代码再调用 stress 命令:
[root@doit ~]# docker cp phpfpm:/app .
grep 查找看看是不是有代码在调用 stress 命令 [root@doit ~]# grep stress -r app
app/index.php:// fake I/O with stress (via write()/unlink()).
app/index.php:$result = exec("/usr/local/bin/stress -t 1 -d 1 2>&1", $output, $status);
找到了,果然是 app/index.php 文件中直接调用了 stress 命令。再来看看 app/index.php 的源代码:
[root@doit ~]# cat app/index.php
<?php
// fake I/O with stress (via write()/unlink()).
$result = exec("/usr/local/bin/stress -t 1 -d 1 2>&1", $output, $status);
if (isset($_GET["verbose"]) && $_GET["verbose"]==1 && $status != 0) {
echo "Server internal error: ";
print_r($output);
} else {
echo "It works!";
}
可以看到,源码里对每个请求都会调用一个 stress 命令,模拟 I/O 压力。从注释上看, stress 会通过 write() 和 unlink() 对 I/O 进程进行压测,看来,这应该就是系统 CPU 使用率升高的根源了。
不过,stress 模拟的是 I/O 压力,而之前在 top 的输出中看到的,却一直是用户 CPU 和系统 CPU 升高,并没见到 iowait 升高。这又是怎么回事呢?stress 到底是不是 CPU 使
用率升高的原因呢?
我们还得继续往下走。从代码中可以看到,给请求加入 verbose=1 参数后,就可以查看stress 的输出。你先试试看,在第二个终端运行:
[root@bzhl ~]# curl http://23.106.155.240:10000?verbose=1
Server internal error: Array
(
[0] => stress: info: [9490] dispatching hogs: 0 cpu, 0 io, 0 vm, 1 hdd
[1] => stress: FAIL: [9491] (563) mkstemp failed: Permission denied
[2] => stress: FAIL: [9490] (394) <-- worker 9491 returned error 1
[3] => stress: WARN: [9490] (396) now reaping child worker processes
[4] => stress: FAIL: [9490] (400) kill error: No such process
[5] => stress: FAIL: [9490] (451) failed run completed in 0s
)
看错误消息 mkstemp failed: Permission denied ,以及 failed run completed in 0s。原来 stress 命令并没有成功,它因为权限问题失败退出了。看来,我们发现了一个 PHP 调用外部 stress 命令的 bug:没有权限创建临时文件。
从这里我们可以猜测,正是由于权限错误,大量的 stress 进程在启动时初始化失败,进而导致用户 CPU 使用率的升高。
分析出问题来源,下一步是不是就要开始优化了呢?当然不是!既然只是猜测,那就需要 再确认一下,这个猜测到底对不对,是不是真的有大量的 stress 进程。该用什么工具或指标呢?
我们前面已经用了 top、pidstat、pstree 等工具,没有发现大量的 stress 进程。那么, 还有什么其他的工具可以用吗?
还记得上一期提到的 perf 吗?它可以用来分析 CPU 性能事件,用在这里就很合适。依旧在第一个终端中运行 perf record -g 命令 ,并等待一会儿(比如 15 秒)后按 Ctrl+C 退出。然后再运行 perf report 查看报告:
[root@doit ~]# perf record -g
^C[ perf record: Woken up 13 times to write data ]
[ perf record: Captured and wrote 3.548 MB perf.data (25041 samples) ] [root@doit ~]# perf report
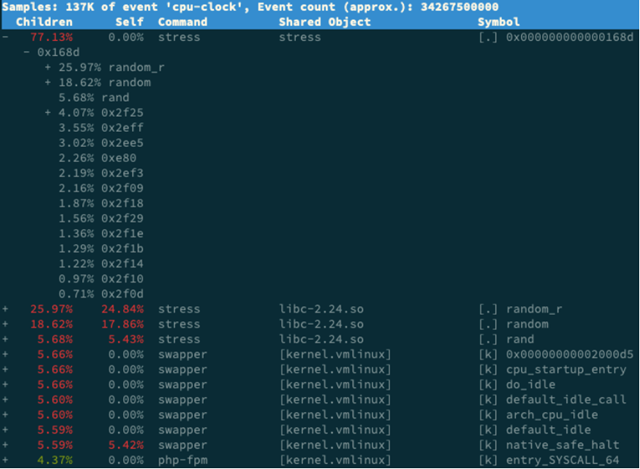
你看,stress 占了所有 CPU 时钟事件的 77%,而 stress 调用调用栈中比例最高的,是随机数生成函数 random(),看来它的确就是 CPU 使用率升高的元凶了。随后的优化就很简单了,只要修复权限问题,并减少或删除 stress 的调用,就可以减轻系统的 CPU 压力。
当然,实际生产环境中的问题一般都要比这个案例复杂,在你找到触发瓶颈的命令行后, 却可能发现,这个外部命令的调用过程是应用核心逻辑的一部分,并不能轻易减少或者删除。这时,你就得继续排查,为什么被调用的命令,会导致 CPU 使用率升高或 I/O 升高等问题。这些复杂场景的案例,我会在后面的综合实战里详细分析。最后,在案例结束时,不要忘了清理环境,执行下面的 Docker 命令,停止案例中用到的Nginx 进程:
docker rm -f nginx phpfpm
execsnoop
在这个案例中,我们使用了 top、pidstat、pstree 等工具分析了系统 CPU 使用率高的问题,并发现 CPU 升高是短时进程 stress 导致的,但是整个分析过程还是比较复杂的。对于这类问题,有没有更好的方法监控呢?
execsnoop 就是一个专为短时进程设计的工具。它通过 ftrace 实时监控进程的 exec() 行为,并输出短时进程的基本信息,包括进程 PID、父进程 PID、命令行参数以及执行的结果。
比如,用 execsnoop 监控上述案例,就可以直接得到 stress 进程的父进程 PID 以及它的命令行参数,并可以发现大量的 stress 进程在不停启动:
git clone --depth 1 https://github.com/brendangregg/perf-tools
[root@doit perf-tools]# ./execsnoop
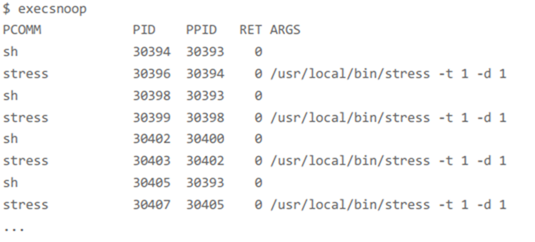
execsnoop 所用的 ftrace 是一种常用的动态追踪技术,一般用于分析 Linux 内核的运行时行为,后面课程我也会详细介绍并带你使用。
小结
碰到常规问题无法解释的 CPU 使用率情况时,首先要想到有可能是短时应用导致的问题, 比如有可能是下面这两种情况。
第一,应用里直接调用了其他二进制程序,这些程序通常运行时间比较短,通过 top 等工具也不容易发现。
第二,应用本身在不停地崩溃重启,而启动过程的资源初始化,很可能会占用相当多的CPU。
对于这类进程,我们可以用 pstree 或者 execsnoop 找到它们的父进程,再从父进程所在的应用入手,排查问题的根源。
perf record -ag -- sleep 2;perf report
4 系统的 CPU 使用率很高,但为啥却找不到高 CPU的应用?的更多相关文章
- 06 案例篇:系统的 CPU 使用率很高,但为啥却找不到高 CPU 的应用?
上一节我讲了 CPU 使用率是什么,并通过一个案例教你使用 top.vmstat.pidstat 等工具,排查高 CPU 使用率的进程,然后再使用 perf top 工具,定位应用内部函数的问题.不过 ...
- 06讲案例篇:系统的CPU使用率很高,但为啥却找不到高CPU的应用
小结 碰到常规问题无法解释的 CPU 使用率情况时,首先要想到有可能是短时应用导致的问题,比如有可能是下面这两种情况. 第一,应用里直接调用了其他二进制程序,这些程序通常运行时间比较短,通过 top ...
- 空循环导致CPU使用率很高
业务背景 业务背景就是需要将多张业务表中的数据增量同步到一张大宽表中,后台系统基于这张大宽表开展业务,所以就开发了一个数据同步工具,由中间件采集binlog消息到kafka里,然后我去消费,实现增量同 ...
- 记录一次mysql查询速度慢造成CPU使用率很高情况
1.某日zabbix告警,某台机器CPU使用率过高. 查看慢查询日志,看到很多sql语句都超过10秒 把sql语句拿出来放在查询窗口执行.前面加上explain就可以查看详细查询信息 playcode ...
- 解决linux中Kipmi0进程对CPU使用率很高问题
kipmi is supposed to run with low priority. When you say it consumes 70-90% of the CPUs, is that con ...
- 性能分析(3)- 短时进程导致用户 CPU 使用率过高案例
性能分析小案例系列,可以通过下面链接查看哦 https://www.cnblogs.com/poloyy/category/1814570.html 系统架构背景 VM1:用作 Web 服务器,来模拟 ...
- 线上cpu使用率过高解决方案
一个应用占用CPU很高,除了确实是计算密集型应用之外,通常原因都是出现了死循环. 下面我们将一步步定位问题,详尽的介绍每一步骤的相关知识. 一.通过top命令定位占用cpu高的进程 执行top命令得到 ...
- Cisco WS-C4503-E CPU使用率高问题排查
现状描述: 办公网环境下由2台VSS模式下WS-C4503-E 作为核心交换机,下接若干台WS-C2960X-48LPS-L作为接入.行政同事在进行工位改造的时候为方便将原工位网线下联若干台hub. ...
- 查看线程linux cpu使用率
Linux下如何查看高CPU占用率线程 LINUX CPU利用率计算 转 http://www.cnblogs.com/lidabo/p/4738113.html目录(?)[-] proc文件系统 p ...
随机推荐
- ASP.NET Core可视化日志组件使用
前言 今天站长推荐一款日志可视化组件LogDashboard,可以不用安装第三方进程,只需要在项目中安装相应的Nuget包,添加数行代码,就可以实现拥有带Web页面的日志管理面板,十分nice哦. 下 ...
- 恒骊学堂的JAVA初步学习总纲--转载
- 「一站式」兼容所有云厂商文件存储Spring Boot 实现
背景 在互联网发展的今天,近乎所有的云厂商都提供对象存储服务.一种海量.安全.低成本.高可靠的云存储服务,适合存放任意类型的文件.容量和处理能力弹性扩展,多种存储类型供选择,全面优化存储成本. 当我们 ...
- 10. Vue-Vue 的{{}}、v-html、v-text
{{ }} 将元素当成纯文本输出 v-html v-html会将元素当成HTML标签解析后输出 v-text v-text会将元素当成纯文本输出 代码: <!DOCTYPE html> & ...
- 次小生成树 详解及模板 (仅kruskal)
思路 关于次小生成树,首先求出最小生成树,然后枚举每条不在最小生成树上的边(在原本的节点上添加一个vis属性进行判断即可),并把这条边放到最小生成树上面,然后就一定会形成环,那么我们在这条环路中取出一 ...
- day9.函数2
一.函数对象 函数是第一类对象,第一等公民,函数对象即函数可以被当作变量去用. 具体分为四个方面: 1.可以被赋值 def func(): print('from func') f = func pr ...
- 脚本加载后执行JS回调函数的方法
动态脚本简单示例 // IE下: var HEAD = document.getElementsByTagName('head')[0] || document.documentElement var ...
- 16.PHP_Ajax模拟服务器登录验证
Ajax模拟登陆验证 index.php <script language="javascript"> var http_request = false; ...
- Day003 JavaDoc
JavaDoc javadoc命令是用来生成自己的Api文档的 参数信息 @author 作者名 @version 版本号 @since 指明需要最早使用的jdk版本 @param 参数名 @retu ...
- android 文件存储&SharedPreferences
一.文件存储 文件存储主要是I/O流的操作,没什么好说的,需要注意的是保存文件的各个目录. 下面为常用的目录: public static File getInFileDir(Context cont ...