机器学习之支持向量机(python)
参考链接:https://blog.csdn.net/weixin_33514582/article/details/113321749、https://blog.csdn.net/weixin_44196785/article/details/109263326。
一、简介
支持向量机 (Support Vector Machine) 是由Vapnik等人于1995年提出来的,之后随着统计理论的发展,支持向量机 SVM 也逐渐受到了各领域研究者的关注,在很短的时间就得到了很广泛的应用。支持向量机是被公认的比较优秀的分类模型。同时,在支持向量机的发展过程中,其理论方面的研究得到了同步的发展,为支持向量机的研究提供了强有力的理论支撑。
1 SVM、SVC、SVR三者的区别
- SVM=Support Vector Machine 是支持向量机
- SVC=Support Vector Classification就是支持向量机用于分类,
- SVR=Support Vector Regression.就是支持向量机用于回归分析
2 算法(python-sklearn)
SVM模型的几种
- svm.LinearSVC Linear Support Vector Classification.
- svm.LinearSVR Linear Support Vector Regression.
- svm.NuSVC Nu-Support Vector Classification.
- svm.NuSVR Nu Support Vector Regression.
- svm.OneClassSVM Unsupervised Outlier Detection.
- svm.SVC C-Support Vector Classification.
- svm.SVR Epsilon-Support Vector Regression.
二、svr预测
1 SVR原理简述
线性回归的基本模型为:
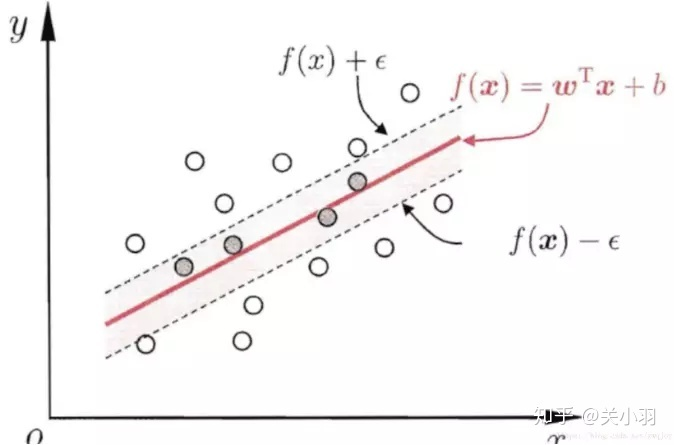
SVR 示意图
从图例中分析,支持向量机回归与线性回归相比,支持向量回归表示只要在虚线内部的值都可认为是预测正确,只要计算虚线外部的值的损失即可。考虑到SVM中线性不可分的情形,在引入松弛变量
最终得出支持向量机回归的最优化问题:
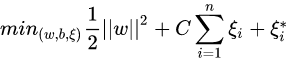
引入拉格朗日乘数,经过一系列求解与对偶,求的线性拟合函数为:
引入核函数,则得:
2 python函数介绍
sklearn.svm.SVR(
kernel ='rbf',
degree = 3,
gamma ='auto_deprecated',
coef0 = 0.0,
tol = 0.001,
C = 1.0,
epsilon = 0.1,
shrinking = True,
cache_size = 200,
verbose = False,
max_iter = -1
)
'''
kernel:指定要在算法中使用的内核类型。它必须是'linear','poly','rbf', 'sigmoid',
'precomputed'或者callable之一。 degree: int,可选(默认= 3)多项式核函数的次数('poly')。被所有其他内核忽略。 gamma : float,(默认='auto'),'rbf','poly'和'sigmoid'的核系数。当前默认值为'auto',
它使用1 / n_features。 coef0 : float,(默认值= 0.0)核函数中的独立项。它只在'poly'和'sigmoid'中很重要。 tol : float,(默认值= 1e-3)容忍停止标准。 C : float,可选(默认= 1.0)错误术语的惩罚参数C. epsilon : float,optional(默认值= 0.1)epsilon在epsilon-SVR模型中。
它指定了epsilon-tube,其中训练损失函数中没有惩罚与在实际值的距离epsilon内预测的点。 shrinking : 布尔值,可选(默认= True)是否使用收缩启发式。 cache_size : float,可选,指定内核缓存的大小(以MB为单位)。 verbose : bool,默认值:False 启用详细输出。请注意,
此设置利用libsvm中的每进程运行时设置,如果启用,则可能无法在多线程上下文中正常运行。 max_iter : int,optional(默认值= -1) 求解器内迭代的硬限制,或无限制的-1
'''
3 示例代码
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.svm import SVR
from sklearn.metrics import r2_score np.random.seed(0) x = np.random.randn(80, 2)
y = x[:, 0] + 2*x[:, 1] + np.random.randn(80) clf = SVR(kernel='linear', C=1.25)
x_tran,x_test,y_train,y_test = train_test_split(x, y, test_size=0.25)
clf.fit(x_tran, y_train)
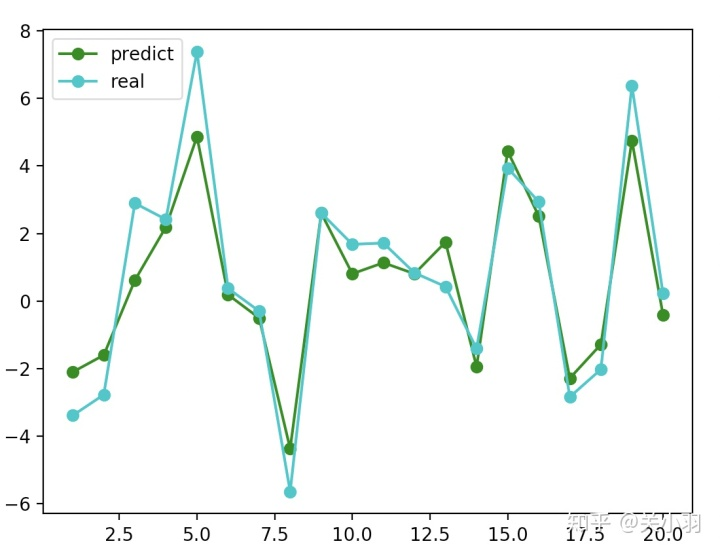
y_hat = clf.predict(x_test) print("得分:", r2_score(y_test, y_hat)) r = len(x_test) + 1
print(y_test)
plt.plot(np.arange(1,r), y_hat, 'go-', label="predict")
plt.plot(np.arange(1,r), y_test, 'co-', label="real")
plt.legend()
plt.show()
三、svm代码
1 线性支持向量机
#encoding=utf8
from sklearn.svm import LinearSVC def linearsvc_predict(train_data,train_label,test_data):
'''
input:train_data(ndarray):训练数据
train_label(ndarray):训练标签
output:predict(ndarray):测试集预测标签
'''
#********* Begin *********#
clf = LinearSVC(dual=False)
clf.fit(train_data,train_label)
predict = clf.predict(test_data)
#********* End *********#
return predict
2 非线性支持向量机
#encoding=utf8
from sklearn.svm import SVC def svc_predict(train_data,train_label,test_data,kernel):
'''
input:train_data(ndarray):训练数据
train_label(ndarray):训练标签
kernel(str):使用核函数类型:
'linear':线性核函数
'poly':多项式核函数
'rbf':径像核函数/高斯核
output:predict(ndarray):测试集预测标签
'''
#********* Begin *********#
clf =SVC(kernel=kernel)
clf.fit(train_data,train_label)
predict = clf.predict(test_data)
#********* End *********#
return predict
3 序列最小优化算法
#encoding=utf8
import numpy as np
class smo:
def __init__(self, max_iter=100, kernel='linear'):
'''
input:max_iter(int):最大训练轮数
kernel(str):核函数,等于'linear'表示线性,等于'poly'表示多项式
'''
self.max_iter = max_iter
self._kernel = kernel
#初始化模型
def init_args(self, features, labels):
self.m, self.n = features.shape
self.X = features
self.Y = labels
self.b = 0.0
# 将Ei保存在一个列表里
self.alpha = np.ones(self.m)
self.E = [self._E(i) for i in range(self.m)]
# 错误惩罚参数
self.C = 1.0
#********* Begin *********#
#kkt条件
def _KKT(self, i):
y_g = self._g(i)*self.Y[i]
if self.alpha[i] == 0:
return y_g >= 1
elif 0 < self.alpha[i] < self.C:
return y_g == 1
else:
return y_g <= 1
# g(x)预测值,输入xi(X[i])
def _g(self, i):
r = self.b
for j in range(self.m):
r += self.alpha[j]*self.Y[j]*self.kernel(self.X[i], self.X[j])
return r
# 核函数,多项式添加二次项即可
def kernel(self, x1, x2):
if self._kernel == 'linear':
return sum([x1[k]*x2[k] for k in range(self.n)])
elif self._kernel == 'poly':
return (sum([x1[k]*x2[k] for k in range(self.n)]) + 1)**2
return 0
# E(x)为g(x)对输入x的预测值和y的差
def _E(self, i):
return self._g(i) - self.Y[i]
#初始alpha
def _init_alpha(self):
# 外层循环首先遍历所有满足0<a<C的样本点,检验是否满足KKT
index_list = [i for i in range(self.m) if 0 < self.alpha[i] < self.C]
# 否则遍历整个训练集
non_satisfy_list = [i for i in range(self.m) if i not in index_list]
index_list.extend(non_satisfy_list)
for i in index_list:
if self._KKT(i):
continue
E1 = self.E[i]
# 如果E2是+,选择最小的;如果E2是负的,选择最大的
if E1 >= 0:
j = min(range(self.m), key=lambda x: self.E[x])
else:
j = max(range(self.m), key=lambda x: self.E[x])
return i, j
#选择alpha参数
def _compare(self, _alpha, L, H):
if _alpha > H:
return H
elif _alpha < L:
return L
else:
return _alpha
#训练
def fit(self, features, labels):
'''
input:features(ndarray):特征
label(ndarray):标签
'''
self.init_args(features, labels)
for t in range(self.max_iter):
i1, i2 = self._init_alpha()
# 边界
if self.Y[i1] == self.Y[i2]:
L = max(0, self.alpha[i1]+self.alpha[i2]-self.C)
H = min(self.C, self.alpha[i1]+self.alpha[i2])
else:
L = max(0, self.alpha[i2]-self.alpha[i1])
H = min(self.C, self.C+self.alpha[i2]-self.alpha[i1])
E1 = self.E[i1]
E2 = self.E[i2]
# eta=K11+K22-2K12
eta = self.kernel(self.X[i1], self.X[i1]) + self.kernel(self.X[i2], self.X[i2]) - 2*self.kernel(self.X[i1], self.X[i2])
if eta <= 0:
continue
alpha2_new_unc = self.alpha[i2] + self.Y[i2] * (E2 - E1) / eta
alpha2_new = self._compare(alpha2_new_unc, L, H)
alpha1_new = self.alpha[i1] + self.Y[i1] * self.Y[i2] * (self.alpha[i2] - alpha2_new)
b1_new = -E1 - self.Y[i1] * self.kernel(self.X[i1], self.X[i1]) * (alpha1_new-self.alpha[i1]) - self.Y[i2] * self.kernel(self.X[i2], self.X[i1]) * (alpha2_new-self.alpha[i2])+ self.b
b2_new = -E2 - self.Y[i1] * self.kernel(self.X[i1], self.X[i2]) * (alpha1_new-self.alpha[i1]) - self.Y[i2] * self.kernel(self.X[i2], self.X[i2]) * (alpha2_new-self.alpha[i2])+ self.b
if 0 < alpha1_new < self.C:
b_new = b1_new
elif 0 < alpha2_new < self.C:
b_new = b2_new
else:
# 选择中点
b_new = (b1_new + b2_new) / 2
# 更新参数
self.alpha[i1] = alpha1_new
self.alpha[i2] = alpha2_new
self.b = b_new
self.E[i1] = self._E(i1)
self.E[i2] = self._E(i2)
def predict(self, data):
'''
input:data(ndarray):单个样本
output:预测为正样本返回+1,负样本返回-1
'''
r = self.b
for i in range(self.m):
r += self.alpha[i] * self.Y[i] * self.kernel(data, self.X[i])
return 1 if r > 0 else -1
#********* End *********#
4 支持向量回归
#encoding=utf8
from sklearn.svm import SVR def svr_predict(train_data,train_label,test_data):
'''
input:train_data(ndarray):训练数据
train_label(ndarray):训练标签
output:predict(ndarray):测试集预测标签
'''
#********* Begin *********#
svr = SVR(kernel='rbf',C=100,gamma= 0.001,epsilon=0.1)
svr.fit(train_data,train_label)
predict = svr.predict(test_data) #********* End *********#
return predict
机器学习之支持向量机(python)的更多相关文章
- 机器学习算法与Python实践之(四)支持向量机(SVM)实现
机器学习算法与Python实践之(四)支持向量机(SVM)实现 机器学习算法与Python实践之(四)支持向量机(SVM)实现 zouxy09@qq.com http://blog.csdn.net/ ...
- 机器学习算法与Python实践之(三)支持向量机(SVM)进阶
机器学习算法与Python实践之(三)支持向量机(SVM)进阶 机器学习算法与Python实践之(三)支持向量机(SVM)进阶 zouxy09@qq.com http://blog.csdn.net/ ...
- 机器学习算法与Python实践之(二)支持向量机(SVM)初级
机器学习算法与Python实践之(二)支持向量机(SVM)初级 机器学习算法与Python实践之(二)支持向量机(SVM)初级 zouxy09@qq.com http://blog.csdn.net/ ...
- 机器学习之支持向量机(四):支持向量机的Python语言实现
注:关于支持向量机系列文章是借鉴大神的神作,加以自己的理解写成的:若对原作者有损请告知,我会及时处理.转载请标明来源. 序: 我在支持向量机系列中主要讲支持向量机的公式推导,第一部分讲到推出拉格朗日对 ...
- 机器学习之支持向量机(三):核函数和KKT条件的理解
注:关于支持向量机系列文章是借鉴大神的神作,加以自己的理解写成的:若对原作者有损请告知,我会及时处理.转载请标明来源. 序: 我在支持向量机系列中主要讲支持向量机的公式推导,第一部分讲到推出拉格朗日对 ...
- 机器学习之支持向量机(二):SMO算法
注:关于支持向量机系列文章是借鉴大神的神作,加以自己的理解写成的:若对原作者有损请告知,我会及时处理.转载请标明来源. 序: 我在支持向量机系列中主要讲支持向量机的公式推导,第一部分讲到推出拉格朗日对 ...
- 机器学习算法与Python实践之(七)逻辑回归(Logistic Regression)
http://blog.csdn.net/zouxy09/article/details/20319673 机器学习算法与Python实践之(七)逻辑回归(Logistic Regression) z ...
- 机器学习算法与Python实践之(五)k均值聚类(k-means)
机器学习算法与Python实践这个系列主要是参考<机器学习实战>这本书.因为自己想学习Python,然后也想对一些机器学习算法加深下了解,所以就想通过Python来实现几个比较常用的机器学 ...
- 机器学习算法与Python实践之(六)二分k均值聚类
http://blog.csdn.net/zouxy09/article/details/17590137 机器学习算法与Python实践之(六)二分k均值聚类 zouxy09@qq.com http ...
- 机器学习 Top 20 Python 开源项目
转自:http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=2652565022&idx=1&sn=9aa035097120 ...
随机推荐
- js学习笔记之正则
() 是为了提取匹配的字符串.表达式中有几个()就有几个相应的匹配字符串.(\s*)表示连续空格的字符串.[]是定义匹配的字符范围.比如 [a-zA-Z0-9] 表示相应位置的字符要匹配英文字符和数字 ...
- Python 爬取页面内容
import urllib.request import requests from bs4 import BeautifulSoup url = "http://www.stats.gov ...
- 微信小程序 -- 英语词典 (小程序插件)
英语词典小程序 基于英语词典小程序插件 - 提供开源地址 项目地址 英语词典小程序插件: 微信小程序 词典 真题基础服务插件(gitee.com) 功能特色 [x] 全面详实的经典词库,详细释义覆盖约 ...
- 「必知必会」最细致的 ArrayList 原理分析
从今天开始也正式开 JDK 原理分析的坑了,其实写源码分析的目的不再是像以前一样搞懂原理,更重要的是看看他们编码风格更进一步体会到他们的设计思想.看源码前先自己实现一个再比对也许会有不一样的收获! ...
- NCB | 定量蛋白质组学揭示细胞外泌体通用标志物Syntenin-1
外泌体 (exosomes) 是由哺乳动物细胞通过"内吞-融合-外排"等机制,主动向胞外释放的纳米级 (直径40~60 nm) 双层囊泡小体,携带蛋白质.核酸.脂质等多种生物活性分 ...
- 方法对了,你做1年Android开发能顶别人做10年
前几天后台有读者问我这样的问题.他在一家互联网公司工作3年了,每天都很忙,事情又多又杂. 本想着学习多一些东西也不是坏事,可到头来一无所获,什么都没学会,满腔的热情也被消磨得差不多. 三天两头动辞职的 ...
- 阿里内部资料:Android开发核心知识笔记共2100页,58万字,完整版开放下载
作为一个3-5年的Android工程师,我们经常会遇到这些瓶颈: 1.技术视野窄长期在小型软件公司,外包公司工作,技术视野被限制的太厉害 2.薪资提升难初中级Android岗位薪资上升空间有限,基本上 ...
- 从门外汉到腾讯Android高级研发——一个半路出家菜鸟的艰难逆袭之路
我是在去年3月份加入腾讯公司,目前是腾讯公司某技术部门里面的一个小负责人,年薪月薪大税后概30K,谈不上多么厉害,但在回想自己半路出家学习编程,从一个销售到现在终于进入中国互联网顶尖公司,还是有些许感 ...
- Spring对Controller、Service、Dao进行Junit单元测试总结
测试类注解 @RunWith(SpringRunner.class) @SpringBootTest(classes={DemoApplication.class}) 以Controller层的的单元 ...
- 《手把手教你》系列技巧篇(十六)-java+ selenium自动化测试-元素定位大法之By xpath下卷(详细教程)
1.简介 按宏哥计划,本文继续介绍WebDriver关于元素定位大法,这篇介绍定位倒数二个方法:By xpath.xpath 的定位方法, 非常强大. 使用这种方法几乎可以定位到页面上的任意元素. ...