sql改写优化:简单规则重组实现
我们知道sql执行是一个复杂的过程,从sql到逻辑计划,到物理计划,规则重组,优化,执行引擎,都是很复杂的。尤其是优化一节,更是内容繁多。那么,是否我们本篇要来讨论这个问题呢?答案是否定的,我们只特定场景的特定优化问题。
1. 应用场景描述
应用场景是:我们提供一个功能,允许用户从提供的字段列表中,选择任意字段,然后配置好规则,后端根据这些规则,查询出相应的主键数据出来。可以理解为简单的可视化查询组件。
2. 整体思路解析
一般地,为了让前端规则支持任意配置,我们基本很难做到一种特定的数据结构,将每个查询条件拆分到一个个的rdb表字段中。所以,简单地,就是让前端超脱提交一个用户的整个查询规则上来就好了,这和数据库中的sql其实是一个道理,只是这里只有where条件。所以,我们要做的就是,如何根据where条件,构建出相应的sql问题了。
只有where条件规则的模式,既有好处也有不好的。首先说不好处,就是只有where条件,如何构建其他部分相对麻烦点,但因为我们蛤考虑主键查询,所以相对简单。其次好处是,我们可以在这个where条件的后面,任意转换成各种数据库查询,即我们存储层是可替换的,这就给了我们很多想像的空间。比如,最开始业务量小,我们用简单rdb,后来可以换成es,再可以换成其他数据库。这就很方便了。
那么,如何从一串where条件中,提取出关键信息,然后反解出整体概念呢?很简单,只需要将条件分词,分析一下就知道了。更直接的,我们从条件中提取出相应的元数据信息,再根据这些元数据就可以推导出上下文了。然后,再连接上where条件,自然就构建出完整的查询语句了。
但是有个问题,如果我们的整体where结构是不变的,那么好办,直接拼接或者简单的改写局部即可。但,如果我们想拆解成尽可能小的执行步骤呢?也就是本文标题指向,想尽可能把符合一个表的条件放在一块,甚至分解一家大的where条件为多个子查询,那又该如何呢?
解题思路:
1. 分解出所有的元数据信息;
2. 构建出所有查询的抽象语法树,树尽可能简单;
3. 根据元数据信息,将同表的查询条件聚合在一起;
4. 根据条件运算优先级,将相同优化级的条件聚合在一起;
5. 重新构建整体sql;
说得有点抽象,来个图表示一下。
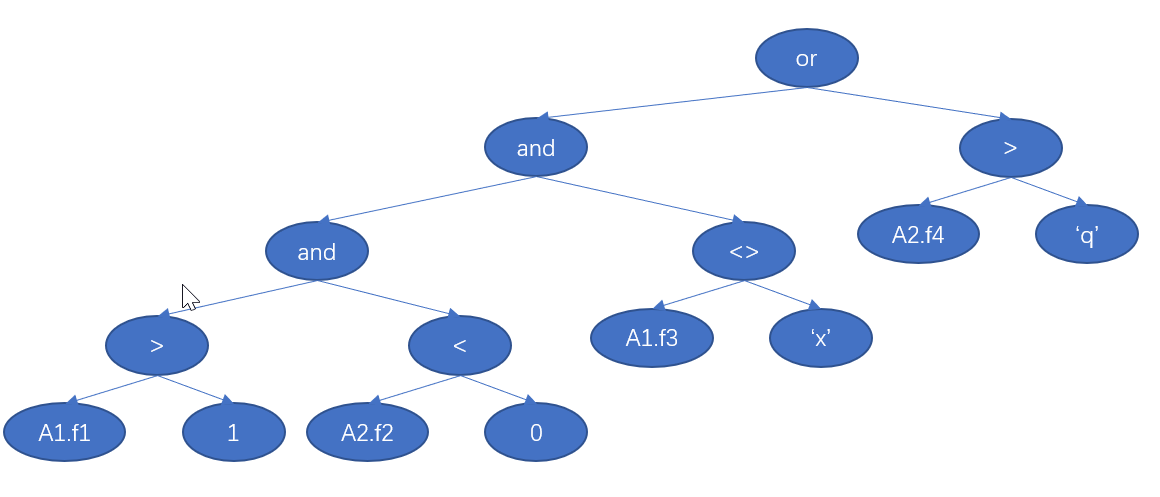
规则定义为:a1.f1 > 1 and a2.f2 < 0 and a1.f3 <> 'x' or a2.f4 > 'q'
原始规则树如下:
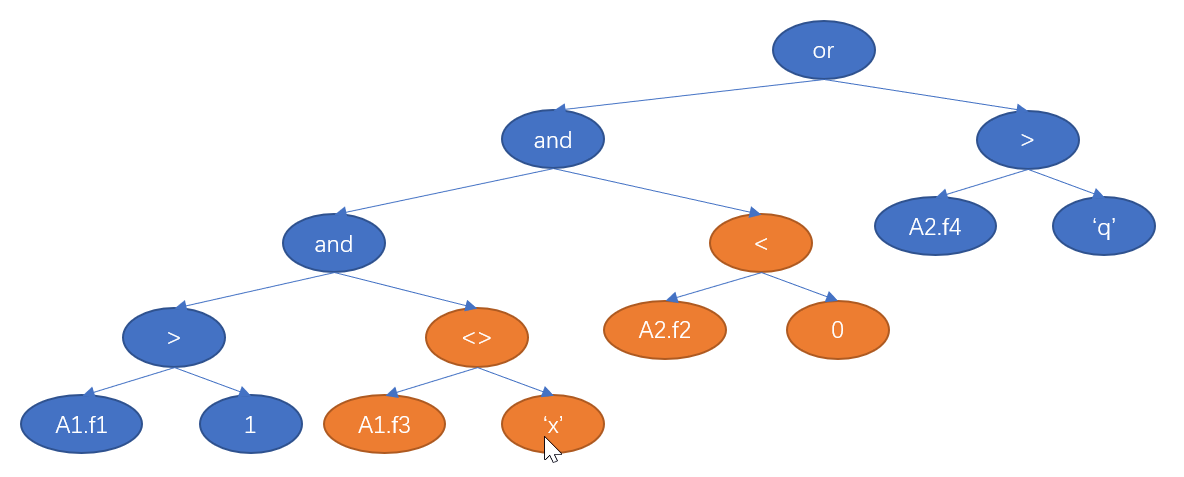
改写后的规则如下:
3. 实现步骤细节
大体上就是干这么一件事,以及如何干成。看起来好像蛮简单的,相信聪明如你也许早就做出来了。但是我还是要提醒大家,需要注意的事情其实也有那么几件。
1. 分词倒是简单,但也得做;
2. 如何构建原始二叉树?注意需要保持各优先级问题;
3. 改写的前提是什么?不是所有改写都能成立;
也许,我们应该用到一些开源的框架,以便让我们事半功倍。比如,我使用calcite框架的实现思路,将各单词构建出二叉树,因为calcite中有各种测试好的优先级定义,我只拿过来就即可。比如我暂且定义优先级如下:
/**
* 获取各操作符的优先级定义
* and -> 24
* or -> 22
* <,<=,=,>,>= -> 30
* NOT -> 26
* IN -> 32
* IS_NULL -> 58
* IS_NOT_NULL -> -
* LIKE -> 32
* BETWEEN -> 32
* +,- -> 40
* /,* -> 60
* between..and -> 90
*
* @see PrecedenceClimbingParser #highest() calcite 优先级定义
* org.apache.calcite.sql.fun.SqlStdOperatorTable
*/
private static int getTokenPrecedence(SyntaxToken token) {
if(token.getTokenType() == SyntaxTokenTypeEnum.COMPARE_OPERATOR) {
return 30;
}
String keyword = token.getRawWord();
if("and".equalsIgnoreCase(keyword)) {
token.changeTokenType(SyntaxTokenTypeEnum.SQL_AND);
return 24;
}
if("or".equalsIgnoreCase(keyword)) {
token.changeTokenType(SyntaxTokenTypeEnum.SQL_OR);
return 22;
}
if("in".equalsIgnoreCase(keyword) || "not in".equalsIgnoreCase(keyword)) {
return 32;
}
if("is".equalsIgnoreCase(keyword)) {
token.changeTokenType(SyntaxTokenTypeEnum.SQL_IS);
return 58;
}
if("like".equalsIgnoreCase(keyword) || "not like".equalsIgnoreCase(keyword)) {
return 32;
}
if("+".equalsIgnoreCase(keyword) || "-".equalsIgnoreCase(keyword)) {
return 40;
}
if("*".equalsIgnoreCase(keyword) || "/".equalsIgnoreCase(keyword)) {
return 60;
}
if(token.getTokenType() == SyntaxTokenTypeEnum.SQL_BETWEEN_AND) {
return 90;
}
// 非操作符
return -1;
}
然后,我需要假设场景再简单些,比如所有小规则都被括号包裹(这其实就不太灵活了,不过没关系,至少我们实践初期是可行的)。这样的话,构建原始规则树就容易了。
/**
* 按照括号进行语法分隔构建语法树
*
* @param rawList 原始单词列表
* @param treeList 目标树存放处
* @return 当次处理读取的单词数
*/
private static int
buildByPart(List<Object> rawList,
List<PrecedenceClimbingParser.Token> treeList) {
int len = rawList.size();
PrecedenceClimbingParser parser;
PrecedenceClimbingParser.Builder builder = new PrecedenceClimbingParser.Builder();
int i = 0;
for (i = 0; i < len; i++) {
Object stmtOrToken = rawList.get(i);
if(stmtOrToken instanceof SyntaxStatement) {
String stmtRawWord = stmtOrToken.toString();
if(stmtRawWord.startsWith("between ") || stmtRawWord.startsWith("case ")) {
if(stmtRawWord.startsWith("between ")) {
SyntaxToken op = new SyntaxToken("[between]",
SyntaxTokenTypeEnum.SQL_BETWEEN_AND);
addOperatorToParserBuilder(builder, op);
}
else if(stmtRawWord.startsWith("case ")) {
SyntaxToken op = new SyntaxToken("[case..when]",
SyntaxTokenTypeEnum.SQL_CASE_WHEN);
addOperatorToParserBuilder(builder, op);
}
builder.atom(new MySqlCustomHandler((SyntaxStatement)stmtOrToken));
// 立即触发一次运算构建
parser = builder.build();
parser.partialParse();
PrecedenceClimbingParser.Token token = parser.all().get(0);
treeList.add(token);
continue;
}
builder.atom(new MySqlCustomHandler((SyntaxStatement)stmtOrToken));
continue;
}
SyntaxToken raw1 = (SyntaxToken)rawList.get(i);
if("in".equals(raw1.getRawWord())
|| ("not".equals(raw1.getRawWord())
&& "in".equals(((SyntaxToken)rawList.get(i + 1)).getRawWord()))) {
// field in (1, 2, 3...)
i++;
if("not".equals(raw1.getRawWord())) {
++i;
raw1 = new SyntaxToken("not in", SyntaxTokenTypeEnum.SQL_NOT_IN);
}
if("(".equals(rawList.get(i).toString())) {
List<MySqlNode> inList = new ArrayList<>();
do {
++i;
Object stmtOrToken2 = rawList.get(i);
if(stmtOrToken2 instanceof SyntaxStatement) {
builder.atom(new MySqlCustomHandler((SyntaxStatement)stmtOrToken2));
continue;
}
SyntaxToken nextToken = (SyntaxToken) stmtOrToken2;
if(")".equals(nextToken.getRawWord())) {
break;
}
if(",".equals(nextToken.getRawWord())) {
continue;
}
inList.add(new MySqlLiteral(nextToken.getTokenType().name(), nextToken));
} while (i < len);
// 添加 in 解析
addOperatorToParserBuilder(builder, raw1);
// 添加 in item 解析
MySqlNodeList nodeList = new MySqlNodeList(inList);
builder.atom(nodeList);
continue;
}
// 位置还原,理论上已经出现不支持的语法
i--;
}
if ("(".equals(raw1.getRawWord())) {
// 递归进入
int skipLen
= buildByPart(rawList.subList(i + 1, len), treeList);
i += skipLen + 1;
PrecedenceClimbingParser.Token innerToken = treeList.get(treeList.size() - 1);
if(innerToken instanceof PrecedenceClimbingParser.Call) {
PrecedenceClimbingParser.Call call
= (PrecedenceClimbingParser.Call) innerToken;
builder.call(call.op, call.args.get(0), call.args.get(1));
continue;
}
else if(innerToken != null && innerToken.type == PrecedenceClimbingParser.Type.ATOM) {
builder.atom(innerToken.o);
continue;
}
log.warn("非call的构造返回,请检查, {}", innerToken);
throw new BizException("非call的构造返回");
}
if(")".equals(raw1.getRawWord())) {
// 弹出返回
parser = builder.build();
parser.partialParse();
if(parser.all().isEmpty()) {
throw new BizException("不支持空括号(无规则)配置,请检查!");
}
PrecedenceClimbingParser.Token token = parser.all().get(0);
treeList.add(token);
break;
}
if("not".equals(raw1.getRawWord())) {
if("like".equals(((SyntaxToken)rawList.get(i + 1)).getRawWord())) {
++i;
raw1 = new SyntaxToken("not like",
SyntaxTokenTypeEnum.SQL_NOT_LIKE);
}
}
addOperatorToParserBuilder(builder, raw1);
}
// 构建全量的语句
parser = builder.build();
parser.partialParse();
PrecedenceClimbingParser.Token token = parser.all().get(0);
if(treeList.size() == 1) {
treeList.add(0, token);
}
else {
if(treeList.isEmpty()) {
log.warn("规则解析失败: 构造语法语法树失败, 树节点为空,可能是不带括号导致:{}",
token.toString());
throw new BizException(300427, "规则解析失败: 构造语法语法树失败, 请确认括号问题");
}
treeList.set(0, token);
}
return i;
}
最后是重写的问题,重写我们的目标是同表规则尽可能重组到一块,以便可以更少次数的遍历表数据。但是,如果优先级不同,则不能合并,因为这会改变原始语义。这个问题,说起来简单,也就是通过遍历所有节点,然后重组语句完成。但实现起来可能还是有很多不连贯的地方。需要的可以参考后续的完整实例。
4. 完整规则重组实现参考
完整的实现样例参考如下:(主要为了将普通宽表的查询语句改写成以bitmap和宽表共同组成的查询语句)
4.1. 语法解析为树结构(分词及树优先级构建)


@Slf4j
public class SyntaxParser { /**
* 严格模式解析语法, 解析为树状node结构
*
* @see #parse(String, boolean)
*/
public static MyRuleSqlNodeParsedClause parseAsTree(String rawClause) {
log.info("开始解析: " + rawClause);
if(rawClause == null) {
log.warn("不支持空规则配置:{}, 或者解析分词出错,请排查", rawClause);
throw new BizException("不支持空规则配置:" + rawClause);
}
List<SyntaxToken> tokens = tokenize(rawClause, true);
if(tokens.isEmpty()) {
log.warn("不支持空规则配置:{}, 或者解析分词出错,请排查", rawClause);
throw new BizException("不支持空规则配置:" + rawClause);
}
Map<String, FieldInfoDescriptor> myIdList = enhanceTokenType(tokens);
List<PrecedenceClimbingParser.Token> root = new ArrayList<>();
List<Object> coalesceSpecialTokenTokenList = flattenTokenByStmt(tokens);
// list -> tree 转换, (a=1) 会得到 (a=1),(a=1), 但取0值就没问题了
buildByPart(coalesceSpecialTokenTokenList, root);
MySqlNode node = convert(root.get(0));
return new MyRuleSqlNodeParsedClause(myIdList, node, tokens);
} /**
* 将token树转换为 node 树,方便后续操作
*
* @param token token 词法树
* @return node 树
*/
private static MySqlNode convert(PrecedenceClimbingParser.Token token) {
switch (token.type) {
case ATOM:
Object o = token.o;
if(o instanceof MySqlNode) {
return (MySqlNode) o;
}
if(o instanceof SyntaxToken) {
return new MySqlLiteral(((SyntaxToken) o).getTokenType().name(), (SyntaxToken) o);
}
return (MySqlNode) o;
case CALL:
final PrecedenceClimbingParser.Call call =
(PrecedenceClimbingParser.Call) token;
final List<MySqlNode> list = new ArrayList<>();
for (PrecedenceClimbingParser.Token arg : call.args) {
list.add(convert(arg));
}
MySqlOperator operator = (MySqlOperator)call.op.o;
return new MySqlBasicCall(operator, list.toArray(new MySqlNode[0]));
default:
log.warn("语法解析错误,非预期的token类型:{}, {}", token.type, token);
throw new BizException("非预期的token类型" + token.type);
}
} /**
* 按照括号进行语法分隔构建语法树
*
* @param rawList 原始单词列表
* @param treeList 目标树存放处
* @return 当次处理读取的单词数
*/
private static int
buildByPart(List<Object> rawList,
List<PrecedenceClimbingParser.Token> treeList) {
int len = rawList.size();
PrecedenceClimbingParser parser;
PrecedenceClimbingParser.Builder builder = new PrecedenceClimbingParser.Builder();
int i = 0;
for (i = 0; i < len; i++) {
Object stmtOrToken = rawList.get(i);
if(stmtOrToken instanceof SyntaxStatement) {
String stmtRawWord = stmtOrToken.toString();
if(stmtRawWord.startsWith("between ") || stmtRawWord.startsWith("case ")) {
if(stmtRawWord.startsWith("between ")) {
SyntaxToken op = new SyntaxToken("[between]",
SyntaxTokenTypeEnum.SQL_BETWEEN_AND);
addOperatorToParserBuilder(builder, op);
}
else if(stmtRawWord.startsWith("case ")) {
SyntaxToken op = new SyntaxToken("[case..when]",
SyntaxTokenTypeEnum.SQL_CASE_WHEN);
addOperatorToParserBuilder(builder, op);
}
builder.atom(new MySqlCustomHandler((SyntaxStatement)stmtOrToken));
// 立即触发一次运算构建
parser = builder.build();
parser.partialParse();
PrecedenceClimbingParser.Token token = parser.all().get(0);
treeList.add(token);
continue;
}
builder.atom(new MySqlCustomHandler((SyntaxStatement)stmtOrToken));
continue;
}
SyntaxToken raw1 = (SyntaxToken)rawList.get(i);
if("in".equals(raw1.getRawWord())
|| ("not".equals(raw1.getRawWord())
&& "in".equals(((SyntaxToken)rawList.get(i + 1)).getRawWord()))) {
// field in (1, 2, 3...)
i++;
if("not".equals(raw1.getRawWord())) {
++i;
raw1 = new SyntaxToken("not in", SyntaxTokenTypeEnum.SQL_NOT_IN);
}
if("(".equals(rawList.get(i).toString())) {
List<MySqlNode> inList = new ArrayList<>();
do {
++i;
Object stmtOrToken2 = rawList.get(i);
if(stmtOrToken2 instanceof SyntaxStatement) {
builder.atom(new MySqlCustomHandler((SyntaxStatement)stmtOrToken2));
continue;
}
SyntaxToken nextToken = (SyntaxToken) stmtOrToken2;
if(")".equals(nextToken.getRawWord())) {
break;
}
if(",".equals(nextToken.getRawWord())) {
continue;
}
inList.add(new MySqlLiteral(nextToken.getTokenType().name(), nextToken));
} while (i < len);
// 添加 in 解析
addOperatorToParserBuilder(builder, raw1);
// 添加 in item 解析
MySqlNodeList nodeList = new MySqlNodeList(inList);
builder.atom(nodeList);
continue;
}
// 位置还原,理论上已经出现不支持的语法
i--;
}
if ("(".equals(raw1.getRawWord())) {
// 递归进入
int skipLen
= buildByPart(rawList.subList(i + 1, len), treeList);
i += skipLen + 1;
PrecedenceClimbingParser.Token innerToken = treeList.get(treeList.size() - 1);
if(innerToken instanceof PrecedenceClimbingParser.Call) {
PrecedenceClimbingParser.Call call
= (PrecedenceClimbingParser.Call) innerToken;
builder.call(call.op, call.args.get(0), call.args.get(1));
continue;
}
else if(innerToken != null && innerToken.type == PrecedenceClimbingParser.Type.ATOM) {
builder.atom(innerToken.o);
continue;
}
log.warn("非call的构造返回,请检查, {}", innerToken);
throw new BizException("非call的构造返回");
}
if(")".equals(raw1.getRawWord())) {
// 弹出返回
parser = builder.build();
parser.partialParse();
if(parser.all().isEmpty()) {
throw new BizException("不支持空括号(无规则)配置,请检查!");
}
PrecedenceClimbingParser.Token token = parser.all().get(0);
treeList.add(token);
break;
}
if("not".equals(raw1.getRawWord())) {
if("like".equals(((SyntaxToken)rawList.get(i + 1)).getRawWord())) {
++i;
raw1 = new SyntaxToken("not like",
SyntaxTokenTypeEnum.SQL_NOT_LIKE);
}
}
addOperatorToParserBuilder(builder, raw1);
}
// 构建全量的语句
parser = builder.build();
parser.partialParse();
PrecedenceClimbingParser.Token token = parser.all().get(0);
if(treeList.size() == 1) {
treeList.add(0, token);
}
else {
if(treeList.isEmpty()) {
log.warn("规则解析失败: 构造语法语法树失败, 树节点为空,可能是不带括号导致:{}",
token.toString());
throw new BizException(300427, "规则解析失败: 构造语法语法树失败, 请确认括号问题");
}
treeList.set(0, token);
}
return i;
} /**
* 添加一个操作符到builder中
*
* @param builder parser builder
* @param raw1 原始单词
*/
private static void addOperatorToParserBuilder(PrecedenceClimbingParser.Builder builder,
SyntaxToken raw1) {
int prec = getTokenPrecedence(raw1);
if(prec == -1) {
builder.atom(new MySqlLiteral(raw1.getTokenType().name(), raw1));
}
else {
PrecedenceClimbingParser.Token lastToken = builder.getLastToken();
if(lastToken != null
&& lastToken.o instanceof MySqlOperator) {
throw new BizException(300423, "规则配置错误:【" + lastToken.toString()
+ "】后配置了另一符号【" + raw1.getRawWord() + "】");
}
builder.infix(new MySqlOperator(raw1.getRawWord(), raw1.getTokenType()),
prec, true);
}
} /**
* 获取各操作符的优先级定义
* and,xand -> 24
* or,xor -> 22
* <,<=,=,>,>= -> 30
* NOT -> 26
* IN -> 32
* IS_NULL -> 58
* IS_NOT_NULL -> -
* LIKE -> 32
* BETWEEN -> 32
* +,- -> 40
* /,* -> 60
* between..and -> 90
*
* @param token 给定单词
* @see PrecedenceClimbingParser #highest() calcite 优先级定义
* org.apache.calcite.sql.fun.SqlStdOperatorTable
*/
private static int getTokenPrecedence(SyntaxToken token) {
if(token.getTokenType() == SyntaxTokenTypeEnum.COMPARE_OPERATOR) {
return 30;
}
String keyword = token.getRawWord();
if("and".equalsIgnoreCase(keyword) || "xand".equalsIgnoreCase(keyword)) {
token.changeTokenType(SyntaxTokenTypeEnum.SQL_AND);
return 24;
}
if("or".equalsIgnoreCase(keyword) || "xor".equalsIgnoreCase(keyword)) {
token.changeTokenType(SyntaxTokenTypeEnum.SQL_OR);
return 22;
}
if("in".equalsIgnoreCase(keyword) || "not in".equalsIgnoreCase(keyword)) {
return 32;
}
if("is".equalsIgnoreCase(keyword)) {
token.changeTokenType(SyntaxTokenTypeEnum.SQL_IS);
return 58;
}
if("like".equalsIgnoreCase(keyword) || "not like".equalsIgnoreCase(keyword)) {
return 32;
}
if("+".equalsIgnoreCase(keyword) || "-".equalsIgnoreCase(keyword)) {
return 40;
}
if("*".equalsIgnoreCase(keyword) || "/".equalsIgnoreCase(keyword)) {
return 60;
}
if(token.getTokenType() == SyntaxTokenTypeEnum.SQL_BETWEEN_AND) {
return 90;
}
// 非操作符
return -1;
} /**
* 复用原有小语句翻译能力,其他语句则保留原样,进行树的构造
*
* @param tokens 原始词组列表
* @return 带stmt实现的token列表
*/
private static List<Object> flattenTokenByStmt(List<SyntaxToken> tokens) {
List<Object> treesFlat = new ArrayList<>(tokens.size());
for (int i = 0; i < tokens.size(); i++) {
SyntaxToken token = tokens.get(i);
String word = token.getRawWord();
SyntaxTokenTypeEnum tokenType = token.getTokenType();
SyntaxStatement branch = null;
switch (tokenType) {
case FUNCTION_SYS_CUSTOM:
String funcName = word.substring(0, word.indexOf('('));
SyntaxStatementHandlerFactory handlerFactory
= SyntaxSymbolTable.getUdfHandlerFactory(funcName);
branch = handlerFactory.newHandler(token, i, tokenType, tokens);
break;
case KEYWORD_SYS_CUSTOM:
// 替换关键字信息
branch = SyntaxSymbolTable.getSysKeywordHandlerFactory()
.newHandler(token, i, tokenType, tokens);
break;
case KEYWORD_SQL:
// 替换关键字信息
branch = SyntaxSymbolTable.getSqlKeywordHandlerFactory()
.newHandler(token, i, tokenType, tokens);
break;
default:
treesFlat.add(token);
break;
}
if(branch != null) {
i += branch.getTokensSize() - 1;
treesFlat.add(branch);
}
}
return treesFlat;
} /**
* 语义增强处理
*
* 加强token类型描述,并返回 myId 信息
*/
private static Map<String, FieldInfoDescriptor>
enhanceTokenType(List<SyntaxToken> tokens) {
Map<String, FieldInfoDescriptor> myIdList = new LinkedHashMap<>();
for (int i = 0; i < tokens.size(); i++) {
SyntaxToken token = tokens.get(i);
String word = token.getRawWord().toLowerCase();
SyntaxTokenTypeEnum newTokenType = token.getTokenType();
switch (token.getTokenType()) {
case WORD_NORMAL:
if (word.startsWith("$")) {
newTokenType = SyntaxTokenTypeEnum.MY_ID;
myIdList.put(word, null);
} else if (NumberUtils.isCreatable(word)) {
newTokenType = SyntaxTokenTypeEnum.WORD_NUMBER;
} else {
newTokenType = SyntaxSymbolTable.keywordTypeOf(word);
}
if (newTokenType == SyntaxTokenTypeEnum.WORD_NORMAL) {
// 以fieldKey形式保存字段信息,用于反查数据
if (!"not".equals(word)
&& !"is".equals(word)
&& !"and".equals(word)
&& !"or".equals(word)
&& !"null".equals(word)
&& !"case".equals(word)
&& !"when".equals(word)
&& !"then".equals(word)
&& !"else".equals(word)
&& !"end".equals(word)
&& !"from".equals(word)
&& !"xand".equals(word)
&& !"xor".equals(word)
&& !"between".equals(word)
&& !"in".equals(word)
&& !"like".equals(word)
) {
myIdList.put(word, null);
newTokenType = SyntaxTokenTypeEnum.MY_ID_NAME;
}
}
if("is".equals(word)
&& "not".equals(tokens.get(i + 1).getRawWord())) {
if("null".equals(tokens.get(i + 2).getRawWord())) {
SyntaxToken notNullToken = new SyntaxToken("not null",
SyntaxTokenTypeEnum.SQL_NOT_NULL);
tokens.remove(i + 1);
tokens.set(i + 1, notNullToken);
i += 1;
}
// throw new BizException("is not 后面只能跟 null");
}
token.changeTokenType(newTokenType);
break;
case WORD_STRING:
// 被引号包围的关键字,如 '%#{monthpart}%'
String innerSysCustomKeyword = CommonUtil.readSplitWord(
word.toCharArray(), 1, "#{", "}");
if (innerSysCustomKeyword.length() > 3) {
newTokenType = SyntaxTokenTypeEnum.KEYWORD_SYS_CUSTOM;
}
token.changeTokenType(newTokenType);
break;
case FUNCTION_NORMAL:
newTokenType = SyntaxSymbolTable.functionTypeOf(word);
List<SyntaxToken> params = parseFunctionParams(token.getRawWord());
params.forEach(r -> {
String fieldName = null;
SyntaxTokenTypeEnum paramTokenType = r.getTokenType();
if (paramTokenType == SyntaxTokenTypeEnum.MY_ID
|| paramTokenType == SyntaxTokenTypeEnum.MY_ID_NAME) {
fieldName = r.getRawWord();
} else if (paramTokenType == SyntaxTokenTypeEnum.WORD_ARRAY) {
fieldName = parseExtendMyFieldInfo(r);
} else if (paramTokenType == SyntaxTokenTypeEnum.MY_ID_EXTEND) {
// 函数中的扩展,无开关强制解析
fieldName = parseExtendMyFieldInfo(r, false);
if(fieldName != null) {
fieldName = fieldName.toLowerCase();
}
}
if (fieldName != null) {
myIdList.put(r.getRawWord(), null);
}
});
token.changeTokenType(newTokenType);
break;
case WORD_ARRAY:
case MY_ID_EXTEND:
String fieldName = parseExtendMyFieldInfo(token);
if (fieldName != null) {
myIdList.put(fieldName, null);
}
break;
}
}
return myIdList;
} /**
* 解析字符串函数的参数列表 (可解析内嵌函数,但并未标记)
*
* @param func 如: substring(a_field ,0 ,1, 'abc')
* @return [a_field, 0, 1, 'abc']
*/
public static List<SyntaxToken> parseFunctionParams(String func) {
String paramStr = func.substring(func.indexOf("(") + 1,
func.lastIndexOf(")"));
List<StringBuilder> paramList = new ArrayList<>();
StringBuilder wrapParam = null;
boolean sQuotation = false;
boolean lastSpace = false;
boolean lastComma = false;
// 前置空格,忽略
paramStr = paramStr.trim();
for(int i = 0; i < paramStr.length(); i++) {
char ch = paramStr.charAt(i);
if(i == 0) {
wrapParam = new StringBuilder().append(ch);
paramList.add(wrapParam);
if(ch == '\'') {
sQuotation = !sQuotation;
}
continue;
}
if(ch == '\'') {
lastComma = false;
lastSpace = false;
wrapParam.append(ch);
sQuotation = !sQuotation;
continue;
}
if(sQuotation) {
wrapParam.append(ch);
continue;
}
if(ch == ' ') {
if(lastSpace) {
continue;
}
lastSpace = true;
continue;
}
if(ch == ',') {
if(lastComma) {
throw new BizException("函数中含有连续多个分隔号:,");
}
wrapParam = new StringBuilder();
paramList.add(wrapParam);
lastComma = true;
lastSpace = false;
continue;
}
lastComma = false;
lastSpace = false;
if(ch == '(' || ch == ')') {
wrapParam = new StringBuilder().append(ch);
paramList.add(wrapParam);
wrapParam = new StringBuilder();
paramList.add(wrapParam);
continue;
}
wrapParam.append(ch);
}
List<SyntaxToken> paramTokenList = new ArrayList<>();
for (StringBuilder p1 : paramList) {
if(p1.length() == 0) {
continue;
}
String p1Str = p1.toString();
char ch = p1Str.charAt(0);
if(ch == '\'' || ch == '"') {
paramTokenList.add(
new SyntaxToken(p1Str, SyntaxTokenTypeEnum.WORD_STRING));
continue;
}
if(ch == '$') {
paramTokenList.add(
new SyntaxToken(p1Str, SyntaxTokenTypeEnum.MY_ID));
continue;
}
if(NumberUtils.isCreatable(p1Str)) {
paramTokenList.add(
new SyntaxToken(p1Str, SyntaxTokenTypeEnum.WORD_NUMBER));
continue;
}
if(p1Str.contains("['")) {
paramTokenList.add(
new SyntaxToken(p1Str, SyntaxTokenTypeEnum.WORD_ARRAY));
continue;
}
if(p1Str.equals("(")) {
// 将上一个函数名,拼接上当前括号,作为分隔符
int lastIndex = paramTokenList.size() - 1;
SyntaxToken lastParam = paramTokenList.get(lastIndex);
paramTokenList.set(lastIndex,
new SyntaxToken(lastParam.getRawWord() + p1Str,
SyntaxTokenTypeEnum.FUNCTION_NORMAL));
continue;
}
if(p1Str.equals(")")) {
paramTokenList.add(
new SyntaxToken(p1Str, SyntaxTokenTypeEnum.CLAUSE_SEPARATOR));
continue;
}
if("current_timestamp".equalsIgnoreCase(p1Str)) {
paramTokenList.add(
new SyntaxToken(p1Str, SyntaxTokenTypeEnum.KEYWORD_SYS_CUSTOM));
continue;
}
// 忽略其他关键字,直接认为是字段信息
paramTokenList.add(
new SyntaxToken(p1Str, SyntaxTokenTypeEnum.MY_ID_NAME));
}
return paramTokenList;
} /**
* 查询语句分词操作
*
* 拆分为单个细粒度的词如:
* 单词
* 分隔符
* 运算符
* 数组
* 函数
*
* @param rawClause 原始查询语句
* @param strictMode 是否是严格模式, true:是, false:否
* @return token化的单词
*/
private static List<SyntaxToken> tokenize(String rawClause, boolean strictMode) {
char[] clauseItr = rawClause.toCharArray();
List<SyntaxToken> parsedTokenList = new ArrayList<>();
Stack<ClauseLineNumTable> specialSeparatorStack = new Stack<>();
int clauseLength = clauseItr.length;
StringBuilder field;
String fieldGot;
char nextChar; outer:
for (int i = 0; i < clauseLength; ) {
char currentChar = clauseItr[i];
switch (currentChar) {
case '\'':
case '\"':
fieldGot = readSplitWord(clauseItr, i,
currentChar, currentChar);
i += fieldGot.length();
parsedTokenList.add(
new SyntaxToken(fieldGot, SyntaxTokenTypeEnum.WORD_STRING));
continue outer;
case '[':
case ']':
case '(':
case ')':
case '{':
case '}':
case ',':
if(specialSeparatorStack.empty()) {
specialSeparatorStack.push(
ClauseLineNumTable.newData(i, currentChar));
parsedTokenList.add(
new SyntaxToken(currentChar,
SyntaxTokenTypeEnum.CLAUSE_SEPARATOR));
break;
}
parsedTokenList.add(
new SyntaxToken(currentChar,
SyntaxTokenTypeEnum.CLAUSE_SEPARATOR));
char topSpecial = specialSeparatorStack.peek().getKeyword().charAt(0);
if(topSpecial == '(' && currentChar == ')'
|| topSpecial == '[' && currentChar == ']'
|| topSpecial == '{' && currentChar == '}') {
specialSeparatorStack.pop();
break;
}
if(',' != currentChar) {
specialSeparatorStack.push(
ClauseLineNumTable.newData(i, currentChar));
}
break;
case ' ':
case '\t':
case '\r':
case '\n':
// 空格忽略
break;
case '@':
nextChar = clauseItr[i + 1];
// @{} 扩展, 暂不解析, 原样返回
if(nextChar == '{') {
fieldGot = CommonUtil.readSplitWord(clauseItr, i,
"@{", "}@");
i += fieldGot.length();
parsedTokenList.add(
new SyntaxToken(fieldGot,
SyntaxTokenTypeEnum.MY_ID_EXTEND));
continue outer;
}
break;
case '#':
nextChar = clauseItr[i + 1];
// #{} 系统关键字标识
if(nextChar == '{') {
fieldGot = CommonUtil.readSplitWord(clauseItr, i,
"#{", "}");
i += fieldGot.length();
parsedTokenList.add(
new SyntaxToken(fieldGot,
SyntaxTokenTypeEnum.KEYWORD_SYS_CUSTOM));
continue outer;
}
break;
case '+':
case '-':
case '*':
case '/':
nextChar = clauseItr[i + 1];
if(currentChar == '-'
&& nextChar >= '0' && nextChar <= '9') {
StringBuilder numberBuff = new StringBuilder(currentChar + "" + nextChar);
++i;
while ((i + 1) < clauseLength){
nextChar = clauseItr[i + 1];
if(nextChar >= '0' && nextChar <= '9'
|| nextChar == '.') {
++i;
numberBuff.append(nextChar);
continue;
}
break;
}
parsedTokenList.add(
new SyntaxToken(numberBuff.toString(),
SyntaxTokenTypeEnum.WORD_NUMBER));
break;
}
parsedTokenList.add(
new SyntaxToken(currentChar,
SyntaxTokenTypeEnum.SIMPLE_MATH_OPERATOR));
break;
case '=':
case '>':
case '<':
case '!':
// >=, <=, !=, <>
nextChar = clauseItr[i + 1];
if(nextChar == '='
|| currentChar == '<' && nextChar == '>') {
++i;
parsedTokenList.add(
new SyntaxToken(currentChar + "" + nextChar,
SyntaxTokenTypeEnum.COMPARE_OPERATOR));
break;
}
parsedTokenList.add(
new SyntaxToken(currentChar,
SyntaxTokenTypeEnum.COMPARE_OPERATOR));
break;
default:
field = new StringBuilder();
SyntaxTokenTypeEnum tokenType = SyntaxTokenTypeEnum.WORD_NORMAL;
do {
currentChar = clauseItr[i];
field.append(currentChar);
if(i + 1 < clauseLength) {
// 去除函数前置名后置空格
if(SyntaxSymbolTable.isUdfPrefix(field.toString())) {
do {
if(clauseItr[i + 1] != ' ') {
break;
}
++i;
} while (i + 1 < clauseLength);
}
nextChar = clauseItr[i + 1];
if(nextChar == '(') {
fieldGot = readSplitWordWithQuote(clauseItr, i + 1,
nextChar, ')');
field.append(fieldGot);
tokenType = SyntaxTokenTypeEnum.FUNCTION_NORMAL;
i += fieldGot.length();
break;
}
if(nextChar == '[') {
fieldGot = readSplitWord(clauseItr, i + 1,
nextChar, ']');
field.append(fieldGot);
tokenType = SyntaxTokenTypeEnum.WORD_ARRAY;
i += fieldGot.length();
break;
}
if(isSpecialChar(nextChar)
// 多个关键词情况, 实际上以上解析应以字符或数字作为判定
|| nextChar == '#') {
// 严格模式下,要求 -+ 符号前后必须带空格, 即会将所有字母后紧连的 -+ 视为字符连接号
// 非严格模式下, 即只要是分隔符即停止字符解析(非标准分隔)
if(!strictMode
|| nextChar != '-' && nextChar != '+') {
break;
}
}
++i;
continue;
}
break;
} while (i < clauseLength);
parsedTokenList.add(
new SyntaxToken(field.toString(), tokenType));
break;
}
// 正常单字解析迭代
i++;
}
if(!specialSeparatorStack.empty()) {
ClauseLineNumTable lineNumTableTop = specialSeparatorStack.peek();
throw new BizException("组合规则配置错误:检测到未闭合的符号, near '"
+ lineNumTableTop.getKeyword()+ "' at column "
+ lineNumTableTop.getColumnNum());
}
return parsedTokenList;
} /**
* 从源数组中读取某类词数据
*
* @param src 数据源
* @param offset 要搜索的起始位置 offset
* @param openChar word 的开始字符,用于避免循环嵌套 如: '('
* @param closeChar word 的闭合字符 如: ')'
* @return 解析出的字符
* @throws BizException 解析不到正确的单词时抛出
*/
private static String readSplitWord(char[] src, int offset,
char openChar, char closeChar)
throws BizException {
StringBuilder builder = new StringBuilder();
for (int i = offset; i < src.length; i++) {
if(openChar == src[i]) {
int aroundOpenCharNum = -1;
do {
builder.append(src[i]);
// 注意 openChar 可以 等于 closeChar
if(src[i] == openChar) {
aroundOpenCharNum++;
}
if(src[i] == closeChar) {
aroundOpenCharNum--;
}
} while (++i < src.length
&& (aroundOpenCharNum > 0 || src[i] != closeChar));
if(aroundOpenCharNum > 0
|| (openChar == closeChar && aroundOpenCharNum != -1)) {
throw new BizException("syntax error, un closed clause near '"
+ builder.toString() + "' at column " + --i);
}
builder.append(closeChar);
return builder.toString();
}
}
// 未找到匹配
return " ";
} /**
* 从源数组中读取某类词数据 (将 'xx' 作为一个单词处理)
*
* @param src 数据源
* @param offset 要搜索的起始位置 offset
* @param openChar word 的开始字符,用于避免循环嵌套 如: '('
* @param closeChar word 的闭合字符 如: ')'
* @return 解析出的字符
* @throws BizException 解析不到正确的单词时抛出
*/
private static String readSplitWordWithQuote(char[] src, int offset,
char openChar, char closeChar)
throws BizException {
StringBuilder builder = new StringBuilder();
for (int i = offset; i < src.length; i++) {
if(openChar == src[i]) {
int aroundOpenCharNum = -1;
do {
char ch = src[i];
if(ch == '\'') {
String strQuoted = readSplitWord(src, i, ch, ch);
builder.append(strQuoted);
i += strQuoted.length() - 1;
continue;
}
builder.append(ch);
// 注意 openChar 可以 等于 closeChar
if(ch == openChar) {
aroundOpenCharNum++;
}
if(ch == closeChar) {
aroundOpenCharNum--;
}
} while (++i < src.length
&& (aroundOpenCharNum > 0 || src[i] != closeChar));
if(aroundOpenCharNum > 0
|| (openChar == closeChar && aroundOpenCharNum != -1)) {
throw new BizException("syntax error, un closed clause near '"
+ builder.toString() + "' at column " + --i);
}
builder.append(closeChar);
return builder.toString();
}
}
// 未找到匹配
return " ";
} /**
* 检测字符是否特殊运算符
*
* @param value 给定检测字符
* @return true:是特殊字符, false:普通
*/
private static boolean isSpecialChar(char value) {
return SyntaxSymbolTable.OPERATOR_ALL.indexOf(value) != -1;
} }
4.2. 规则重组优化
@Slf4j
public class MyRuleSqlNodeParsedClause extends MyParsedClause { /**
* 规则语法树
*/
private MySqlNode binTreeRoot; public MyRuleSqlNodeParsedClause(Map<String, FieldInfoDescriptor> idMapping,
MySqlNode binTreeRoot,
List<SyntaxToken> rawTokens) {
super(idMapping, null, rawTokens);
this.binTreeRoot = binTreeRoot;
} /**
* 生成一个空的解析类
*/
private static MyRuleSqlNodeParsedClause EMPTY_CLAUSE
= new MyRuleSqlNodeParsedClause(
Collections.emptyMap(),
null,
Collections.emptyList());
public static MyRuleSqlNodeParsedClause emptyParsedClause() {
return EMPTY_CLAUSE;
} /**
* 转换语言表达式 (新的实现)
*
* @param sqlType sql类型
* @see MyDialectTypeEnum
* @return 翻译后的sql语句
*/
@Override
public String translateTo(MyDialectTypeEnum sqlType) {
boolean needHandleWhitespace = false;
String targetCode = binTreeRoot.toString();
log.info("翻译成目标语言:{}, targetCode: {}", sqlType, targetCode);
return targetCode;
} /**
* 专用实现翻译成ck sql (未经优化版本的)
*
* @return ck sql (bitmap)
*/
public String translateToFullCKSql(boolean onlyCnt) {
resetFlagContainers();
ClickHouseSqlBuilder sqlBuilder = new ClickHouseSqlBuilder();
if(binTreeRoot instanceof MySqlBasicCall) {
// 混合型规则配置操作
visitCallNode((MySqlBasicCall) binTreeRoot, sqlBuilder);
}
else if(binTreeRoot instanceof MySqlCustomHandler) {
log.warn("纯自定义函数转换尚未开发完成,请等待佳音:{}", binTreeRoot.toString());
throw new BizException(300132, "暂不支持的操作哦:" + binTreeRoot.toString());
}
else {
log.error("不支持的转换规则:{}", binTreeRoot.toString());
throw new BizException(300131, "不支持的转换规则:" + binTreeRoot.toString());
}
QueryTableDto primaryTable = queryTableDtoList.get(0);
sqlBuilder.from(primaryTable.getTableAlia(), null);
for (int i = 0; i < queryTableDtoList.size(); i++) {
QueryTableDto tableDto = queryTableDtoList.get(i);
if(i == 0) {
continue;
}
sqlBuilder.join(tableDto.getTableAlia(), null).on(tableDto.getTableAlia(),
primaryTable.getTableAlia() + "." + primaryTable.getJoinField()
+ "=" + tableDto.getTableAlia() + "." + tableDto.getJoinField());
}
// arrayJoin(bitmapToArray(bitmapOrCardinality(user0, user1))) as list
if(onlyCnt) {
sqlBuilder.select("bitmapCardinality(" + bitmapFunctionNodeContainer.get(binTreeRoot) + ")",
"cnt");
}
else {
sqlBuilder.select("arrayJoin(bitmapToArray(" + bitmapFunctionNodeContainer.get(binTreeRoot) + "))",
"cust_no");
// select 其余字段,该场景仅适用于预览,取数并不适合
queryTableDtoList.forEach(tableDto -> tableDto.getQueryFields().forEach(r -> {
if (r.getAlia().equals("join_id")) {
return;
}
// groupBitmapState(uv) ... 之类的运算辅助字段忽略
if(r.getField().contains("(")) {
return;
}
sqlBuilder.select(r.getAlia());
}));
}
sqlBuilder.limit(100);
return sqlBuilder.build(); } /**
* 当前正在构建的逻辑计划
*/
private List<SqlNodeSingleTableLogicalPlan> logicalContainer = new ArrayList<>(); /**
* 整体sql 构建辅助结构
*/
private AtomicInteger tableCounter = new AtomicInteger(0); private List<QueryTableDto> queryTableDtoList = new ArrayList<>(); private Map<MySqlNode /* node */, String /* bitmap function or param */>
bitmapFunctionNodeContainer = new HashMap<>(); private Map<MySqlNode /* node */, Boolean /* reverse bitmap */>
reverseBitmapFlagContainer = new HashMap<>(); /**
* 重置各容器,避免变量污染
*/
private void resetFlagContainers() {
logicalContainer = new ArrayList<>();
tableCounter = new AtomicInteger(0);
bitmapFunctionNodeContainer = new HashMap<>();
reverseBitmapFlagContainer = new HashMap<>();
queryTableDtoList = new ArrayList<>();
} /**
* 激进优化版本的生成sql方法
*
* @param onlyCnt 是否是进行计数
* @return 生成的完整sql
*/
public String translateFullCkSqlProf(boolean onlyCnt) {
resetFlagContainers();
LogicalPlan logicalPlan = binToRelConvert();
ClickHouseSqlBuilder sqlBuilder = new ClickHouseSqlBuilder();
return translateCkByLogicalPlan(logicalPlan, sqlBuilder, onlyCnt);
} // 根据逻辑计划生成ck-sql
private String translateCkByLogicalPlan(LogicalPlan logicalPlan,
ClickHouseSqlBuilder sqlBuilder,
boolean onlyCnt) {
int joinMethod = ApolloUtil.getIntProperty("manage_ck_preview_join_method", 1);
String bitmapFieldPri = buildSqlByLogical(logicalPlan, sqlBuilder, joinMethod); QueryTableDto primaryTable = queryTableDtoList.get(0);
sqlBuilder.from(primaryTable.getTableAlia(), null);
for (int i = 0; i < queryTableDtoList.size(); i++) {
QueryTableDto tableDto = queryTableDtoList.get(i);
if(i == 0) {
continue;
}
sqlBuilder.join(tableDto.getTableAlia(), null).on(tableDto.getTableAlia(),
primaryTable.getTableAlia() + "." + primaryTable.getJoinField()
+ "=" + tableDto.getTableAlia() + "." + tableDto.getJoinField());
}
// arrayJoin(bitmapToArray(bitmapOrCardinality(user0, user1))) as list
if(joinMethod == 1) {
if(onlyCnt) {
sqlBuilder.select("bitmapCardinality(" + bitmapFieldPri + ")",
"cnt");
}
else {
sqlBuilder.select("arrayJoin(bitmapToArray(" + bitmapFieldPri + "))",
"cust_no");
// select 其余字段,该场景仅适用于预览,取数并不适合
queryTableDtoList.forEach(tableDto -> tableDto.getQueryFields().forEach(r -> {
if(r.getAlia() == null) {
sqlBuilder.select(r.getField());
return;
}
if (r.getAlia().equals("join_id")) {
return;
}
// groupBitmapState(uv) ... 之类的运算辅助字段忽略
if(r.getField().contains("(")) {
return;
}
sqlBuilder.select(r.getAlia());
}));
}
}
else if(joinMethod == 2) { }
sqlBuilder.limit(100);
// todo: 其他附加字段如何取值??
return sqlBuilder.build();
} // 可以使用bitmap式的join,也可以使用宽表式的join。
// 1: 使用bitmap式join,即全部使用1 as join_id 进行关联,宽表使用bitmapBuild()进行转换
// 2. 使用宽表进行join,即将bitmap展开为array多行,而宽表则使用主键进行join
// 3. 待定备用,全部为bitmap时,使用bitmap,全部为宽表时,使用宽表join
private String buildSqlByLogical(LogicalPlan plan,
ClickHouseSqlBuilder sqlBuilder,
int joinMethod) {
if(plan instanceof LineUpTwoTablePlan) {
// 多表查询
LineUpTwoTablePlan twoTablePlan = (LineUpTwoTablePlan)plan;
String leftPri = buildSqlByLogical(twoTablePlan.getLeft(),
sqlBuilder, joinMethod);
String rightPri = buildSqlByLogical(twoTablePlan.getRight(),
sqlBuilder, joinMethod);
// 此处join仅仅是为了处理 bitmap 关系, 其他join关系已在单表时处理完成
// groupBitmap(), 左值如何得,右值如何得?
return joinLeftAndRight(leftPri, rightPri,
twoTablePlan.getJoinType(), joinMethod);
}
if(plan instanceof SqlNodeSingleTableLogicalPlan) {
SqlNodeSingleTableLogicalPlan planReal = (SqlNodeSingleTableLogicalPlan) plan;
// sqlBuilder.with(planReal.getTableName())
// .select(plan.fields());
if(planReal.isUseBitmap()) {
if(planReal.getRoot() instanceof MySqlCustomHandler) {
MySqlCustomHandler handler = (MySqlCustomHandler) planReal.getRoot();
String where = handler.getStmt().translateTo(
MyDialectTypeEnum.CLICK_HOUSE, getMyIdMapping());
int tableCounterIndex = tableCounter.getAndIncrement();
String tableAlias = "t" + tableCounterIndex;
String userBitmapAlias = "user" + tableCounterIndex;
Set<QueryFieldDto> fields = new HashSet<>();
fields.add(QueryFieldDto.newField("1", "join_id"));
fields.add(QueryFieldDto.newField("groupBitmapMergeState(uv)", userBitmapAlias));
sqlBuilder.with(tableAlias, fields,
planReal.getTableName()
+ " where " + where);
// 只能拉取客户号字段,其他字段会由于bitmap的加入而损失
QueryTableDto tableInfoOld = planReal.getTableInfo();
planReal.setTableAlias(tableAlias);
QueryTableDto tableInfoNew = new QueryTableDto(tableInfoOld.getTableName(),
tableAlias, null, fields, "join_id",
null, false);
queryTableDtoList.add(tableInfoNew);
return userBitmapAlias;
}
MySqlBasicCall root = (MySqlBasicCall)planReal.getRoot();
MySqlNode left = root.getOperands()[0];
SyntaxToken NameToken = null;
if(left.getKind() == SyntaxTokenTypeEnum.STATEMENT_HANDLER) {
List<SyntaxToken> IdList
= ((MySqlCustomHandler)left).getHoldingMyIdList();
NameToken = IdList.get(0);
}
else {
NameToken = ((MySqlLiteral)left).getValue();
}
FieldInfoDescriptor fieldInfoDescriptor
= CommonMyConditionAstHandler.getFieldInfoByToken(
NameToken, getMyIdMapping());
return buildSimpleBitmapTmpTable(root, left,
root.getOperands()[1], fieldInfoDescriptor, sqlBuilder);
}
// 使用宽表进行join
// 以下为错误的样例,因为只考虑到一个单一的条件情况,实际上该规则下包含了n个条件组合
if(joinMethod == 1) {
int tableCounterIndex = tableCounter.getAndIncrement();
String tableAlias = "t" + tableCounterIndex;
// 使用新的别名,生成宽表别名
QueryTableDto tableInfoOld = planReal.getTableInfo();
if(tableInfoOld == null) {
log.warn("未获取到表相关信息:{}, 请检查是否是apollo配置,或者读取字段元数据异常",
planReal.getRoot());
throw new BizException(300329, "未获取到表相关信息:" + planReal.getRoot());
}
String priField = tableInfoOld.getJoinField();
tableInfoOld.setTableAlia(tableAlias);
planReal.setTableAlias(tableInfoOld.getTableAlia());
MySqlNode curWhereRoot = planReal.getRoot();
planReal.setTableAlias(tableAlias);
String userBitmapAlias = "user" + tableCounterIndex;
Set<QueryFieldDto> fields = new HashSet<>();
fields.add(QueryFieldDto.newField("1", "join_id"));
fields.add(QueryFieldDto.newField("groupBitmapState(toUInt64OrZero(" + priField + "))", userBitmapAlias));
QueryTableDto tableInfoNew = new QueryTableDto(tableInfoOld.getTableName(),
tableAlias, null, fields, "join_id",
null, false);
queryTableDtoList.add(tableInfoNew);
// 只能拉取客户号字段,其他字段会由于bitmap的加入而损失
planReal.setTableInfo(tableInfoNew);
// todo: hive宽表转换为ck宽表,加分布式表分区后缀...
// todo: 将宽表确定提前至每个宽表生成时
String wideTableName = planReal.getTableName();
if(wideTableName.contains(".")) {
wideTableName = wideTableName.substring(wideTableName.lastIndexOf('.') + 1);
}
sqlBuilder.with(tableAlias, fields,
wideTableName
+ " where " + translateRuleNodePartAsPlainText(curWhereRoot));
// fields.add(QueryFieldDto.newField(Name, Name));
return userBitmapAlias;
}
if(joinMethod == 2) {
return null;
} }
throw new BizException(300232, "不支持的表类型:" + plan);
} /**
* 将规则节点翻译为普通文本(即where条件简单翻译)
*
* @param root 当前节点
* @return 翻译后的规则,如 $123 = 1 将翻译成 cust_no = 1
*/
private String translateRuleNodePartAsPlainText(MySqlNode root) {
if(!(root instanceof MySqlBasicCall)) {
if(root.getKind() == SyntaxTokenTypeEnum._ID
|| root.getKind() == SyntaxTokenTypeEnum._ID_NAME) {
FieldInfoDescriptor fieldInfo
= CommonMyConditionAstHandler.getFieldInfoByToken(
((MySqlLiteral) root).getValue(), getMyIdMapping());
if(fieldInfo == null) {
// 这种情况一般upp会拦截
log.warn("主键id未找到对应元数据信息或规则配置错误:{}, 如错误地将值解析为主键id,这个情况一般是因为数值类右值被配置了字符串值",
root.toString());
throw new BizException(300235,
"主键id未找到对应元数据信息或规则配置错误:" + root.toString());
}
return fieldInfo.getMyName();
}
if(root instanceof MySqlCustomHandler) {
MySqlCustomHandler handler = (MySqlCustomHandler) root;
SyntaxStatement stmt = handler.getStmt();
return stmt.translateTo(MyDialectTypeEnum.CLICK_HOUSE,
getMyIdMapping());
}
return root.toString();
}
MySqlBasicCall rootCall = (MySqlBasicCall) root;
MySqlNode[] childs = rootCall.getOperands();
if(childs.length != 2) {
log.warn("规则不支持非2个运算符, 个数不支持:{}, root:{}", childs.length, root);
throw new BizException(300130, "规则不支持非2个运算符");
}
String subRulePlainLeft = translateRuleNodePartAsPlainText(childs[0]);
String subRulePlainRight = translateRuleNodePartAsPlainText(childs[1]); MySqlOperator operator = rootCall.getOperator();
switch (operator.getKind()) {
case SQL_AND:
case SQL_AND_NOT:
return subRulePlainLeft + " and " + subRulePlainRight;
case SQL_OR:
return "( " + subRulePlainLeft + " or " + subRulePlainRight + " )";
case SIMPLE_MATH_OPERATOR:
// 简单四则运算,忽略,可能记录些东西
default:
// 语法已被后续handler处理,此处仅为占位符
if(isOperatorAsReplaceHolder(operator)) {
return "( " + subRulePlainLeft + " " + subRulePlainRight + " )";
}
return "( " + subRulePlainLeft + " " + operator.toString() + " " + subRulePlainRight + " )";
}
} /**
* 判定符号是否是占位符,或者标识符,此种情况逻辑会被后续或前缀token处理
* 如 between..and.. 的 between
*
* @param operator 当前符号
* @return true:是
*/
private boolean isOperatorAsReplaceHolder(MySqlOperator operator) {
return operator.getKind() == SyntaxTokenTypeEnum.SQL_BETWEEN_AND
|| operator.getKind() == SyntaxTokenTypeEnum.SQL_CASE_WHEN;
} // 两个bitmap 节点的逻辑连接主键字段处理
private String joinLeftAndRight(String leftPri,
String rightPri,
SyntaxTokenTypeEnum joinType,
int joinMethod) {
if(joinMethod == 2) {
return null;
}
if(joinType == SyntaxTokenTypeEnum.SQL_AND) {
return "bitmapAnd(" + leftPri + ", " + rightPri + ")";
}
if(joinType == SyntaxTokenTypeEnum.SQL_OR) {
return "bitmapOr(" + leftPri + ", " + rightPri + ")";
}
if(joinType == SyntaxTokenTypeEnum.SQL_AND_NOT) {
return "bitmapAndnot(" + leftPri + ", " + rightPri + ")";
}
throw new BizException(300233, "不支持的逻辑运算:" + joinType);
} /**
* 普通sqlNode 转换成 带一定关系型的节点表示(逻辑计划)
*
*/
private LogicalPlan binToRelConvert() {
// 1. 遍历到所有叶子节点
// 2. 如果叶子节点是表bitmap表示,则立即生成一个逻辑计划,即当前节点就是一个临时表查询
// 3. 如果是宽表节点,则标记当前节点未被使用,且暂不生成逻辑计划,继续向上查找
// 4. 如果向上回滚时,有以下情况之一的,立即将之前的节点划为一个逻辑计划结束,并开启一个新的逻辑计划
// 4.1. 当前节点是bitmap, 立即结束之前的计划,并生成一个当前计划,并立即结束
// 4.2. 如果是宽表,但与上一节点或者当前计划中对应的表不是一同一个的,结束之前的计划,开启新的;
// 4.3. 如果当前节点是右子节点时,且上一逻辑计划已结束,则立即将当前节点(宽表)作为临时表新的逻辑计划生成并结束;
// 最后,再进行遍历逻辑计划时,就不会存在太多表关联问题了(当然比最开始全是宽表的情况还是会多出很多临时表出来)
// 不用递归 ClickHouseSqlBuilder sqlBuilder = new ClickHouseSqlBuilder();
LogicalPlan logicalPlan = null;
if(binTreeRoot instanceof MySqlBasicCall) {
// 混合型规则配置操作
markNodeDepth((MySqlBasicCall) binTreeRoot, sqlBuilder);
logicalPlan = buildCallNodeLogical((MySqlBasicCall) binTreeRoot);
}
else if(binTreeRoot instanceof MySqlCustomHandler) {
// 单自定义函数类操作如 ui_lbs_range('', '') > 10
logicalPlan = buildLogicalWithCustomHandlerNode(
(MySqlCustomHandler) binTreeRoot);
}
else {
log.error("不支持的转换规则:{}", binTreeRoot.toString());
throw new BizException(300131, "不支持的转换规则:" + binTreeRoot.toString());
}
log.info("result:{}, logicalPlan:{}", binTreeRoot, logicalPlan);
return logicalPlan;
} /**
* 标记各节点的深度,为下一步处理做准备
*
* @param root 根节点
*/
private LogicalPlan buildCallNodeLogical(MySqlBasicCall root) {
MySqlNode[] childs = root.getOperands();
if(childs.length != 2) {
log.warn("规则不支持非2个运算符, 个数不支持:{}, root:{}", childs.length, root);
throw new BizException(300130, "规则不支持非2个运算符");
}
LogicalPlan[] curPlans = new LogicalPlan[2];
for (int i = 0; i < childs.length; i++) {
MySqlNode node = childs[i];
// todo: 如何判定当前节点是叶子节点?
if (node instanceof MySqlBasicCall) {
curPlans[i] = buildCallNodeLogical((MySqlBasicCall) node);
continue;
}
// todo: 自定义函数待完善
if (node instanceof MySqlCustomHandler) {
curPlans[i] = buildLogicalWithCustomHandlerNode((MySqlCustomHandler) node);
// 此处有问题,待解决
continue;
}
// node.setDistanceFromLeaf(0);
// if(node instanceof ATOM) {
// // 以你为起点
// }
} // 1. 遍历到所有叶子节点
// 2. 如果叶子节点是表bitmap表示,则立即生成一个逻辑计划,即当前节点就是一个临时表查询
// 3. 如果是宽表节点,则标记当前节点未被使用,且暂不生成逻辑计划,继续向上查找
// 4. 如果向上回滚时,有以下情况之一的,立即将之前的节点划为一个逻辑计划结束,并开启一个新的逻辑计划
// 4.1. 当前节点是bitmap, 立即结束之前的计划,并生成一个当前计划,并立即结束
// 4.2. 如果是宽表,但与上一节点或者当前计划中对应的表不是一同一个的,结束之前的计划,开启新的;
// 4.3. 如果当前节点是右子节点时,且上一逻辑计划已结束,则立即将当前节点(宽表)作为临时表新的逻辑计划生成并结束;
// 最后,再进行遍历逻辑计划时,就不会存在太多表关联问题了(当然比最开始全是宽表的情况还是会多出很多临时表出来)
// 不用递归 return buildLogicalWithBinaryOperator(root, curPlans[0], curPlans[1],
childs[0], childs[1]);
} /**
* udf类规则解析生成 逻辑计划
*/
private LogicalPlan buildLogicalWithCustomHandlerNode(MySqlCustomHandler handler) {
SyntaxStatement stmt = handler.getStmt();
MyRuleStmtMixedType mixedType = stmt.getStmtType();
if(mixedType == MyRuleStmtMixedType.UDF_HANDLER
|| mixedType == MyRuleStmtMixedType.LBS_FUNCTION) {
String partialSql = stmt.translateTo(
MyDialectTypeEnum.CLICK_HOUSE, getMyIdMapping());
log.info("ck partial function sql:{}", partialSql);
List<SyntaxToken> IdContainer = handler.getHoldingMyIdList();
checkMyIdNum(IdContainer);
// 仅有一主键id运算的情况下,where条件就是整个语句(无需拆分)
String where = partialSql;
FieldInfoDescriptor fieldInfoDescriptor
= CommonMyConditionAstHandler.getFieldInfoByToken(
IdContainer.get(0), getMyIdMapping());
return newLogicalPlan(handler, fieldInfoDescriptor);
// 根据主键元数据信息,构建外围sql
}
log.warn("CK不支持的函数操作:{}, 或者纯关键词解析(值解析),无需生成plan", handler.toString());
// throw new BizException(300436, "CK不支持的函数操作:" + handler.toString());
return null;
}
/**
* 对细粒度的二元操作,构建sql
*
* @param root 当前节点root
* @param leftPlan 左子树逻辑计划,叶子节点时为空
* @param rightPlan 右子树逻辑计划,叶子节点时为空
* @param left 左子节点
* @param right 右子节点
*/
private LogicalPlan buildLogicalWithBinaryOperator(
MySqlBasicCall root,
LogicalPlan leftPlan,
LogicalPlan rightPlan,
MySqlNode left,
MySqlNode right) {
MySqlOperator operator = root.getOperator();
// 如 (a > 1) and (b <= '2021-09-08')
// 走bitmapAndOr() 函数
SyntaxTokenTypeEnum joinType = operator.getKind();
switch (operator.getKind()) {
case SQL_AND:
// 做 剔除操作
if(reverseBitmapFlagContainer.get(right) != null
&& reverseBitmapFlagContainer.get(right)) {
joinType = SyntaxTokenTypeEnum.SQL_AND_NOT;
}
return mergePlan(root, leftPlan, rightPlan, joinType);
case SQL_OR:
if(reverseBitmapFlagContainer.get(right) != null
&& reverseBitmapFlagContainer.get(right)) {
log.warn("不支持的剔除操作, 或 不属于白名单 类型的操作不支持, {}", root.toString());
throw new BizException(300209, "不支持的剔除操作");
}
return mergePlan(root, leftPlan, rightPlan, joinType);
case SIMPLE_MATH_OPERATOR:
// 简单四则运算,忽略,可能记录些东西
log.warn("暂不支持四则运算的表达式:{}", root.toString());
throw new BizException(300520, "暂不支持四则运算的表达式:" + root.toString());
}
// a +-*/ 1 四则运算,暂时忽略
// 如 a > 1, 走子查询逻辑
// String sql = "SELECT 1 AS join_id, groupBitmapState(uv) AS users1 FROM _string_distribute WHERE name = '%s<主键名>' and value <operator> '%s<主键值>'";
if(left.getKind() == SyntaxTokenTypeEnum._ID
|| left.getKind() == SyntaxTokenTypeEnum._ID_NAME
|| left.getKind() == SyntaxTokenTypeEnum._ID_EXTEND) {
// todo: 解析出主键元数据信息,决定使用哪一个类型的bitmap表,或者宽表
FieldInfoDescriptor fieldInfo
= CommonMyConditionAstHandler.getFieldInfoByToken(
((MySqlLiteral)left).getValue(), getMyIdMapping());
if(fieldInfo == null) {
log.warn("未找到主键元数据信息:{},请检查", left.toString());
throw new BizException(300518, "未找到主键元数据信息:" + left.toString());
}
if(fieldInfo.isWhitelistMy()) {
String rightValue = right.toString();
if("0".equals(rightValue)) {
reverseBitmapFlagContainer.put(root, true);
}
}
// 剔除问题请参考原有实现
return newLogicalPlan(root, fieldInfo);
}
else if(left.getKind() == SyntaxTokenTypeEnum.STATEMENT_HANDLER) {
MySqlCustomHandler handler = (MySqlCustomHandler)left;
List<SyntaxToken> IdList = handler.getHoldingMyIdList();
checkMyIdNum(IdList);
FieldInfoDescriptor fieldInfo
= CommonMyConditionAstHandler.getFieldInfoByToken(
IdList.get(0), getMyIdMapping());
if(fieldInfo == null) {
log.warn("未找到主键元数据信息:{},请检查", left.toString());
throw new BizException(300518, "未找到主键元数据信息:" + left.toString());
}
// 剔除问题请参考原有实现
return newLogicalPlan(root, fieldInfo);
}
throw new BizException(300519, "分支判定错误, 未知的主键id:" + root.toString());
} // 合并两个单表查询计划
private LogicalPlan mergePlan(MySqlNode mergeOp,
LogicalPlan left,
LogicalPlan right,
SyntaxTokenTypeEnum joinType) {
// 最末的子节点规则合并
if(left instanceof SqlNodeSingleTableLogicalPlan
&& right instanceof SqlNodeSingleTableLogicalPlan) {
SqlNodeSingleTableLogicalPlan leftReal = (SqlNodeSingleTableLogicalPlan) left;
SqlNodeSingleTableLogicalPlan rightReal = (SqlNodeSingleTableLogicalPlan) right;
if(!leftReal.isUseBitmap()
&& !rightReal.isUseBitmap()
&& leftReal.getTableName().equals(rightReal.getTableName())) {
MySqlNode[] operands = new MySqlNode[2];
operands[0] = leftReal.getRoot();
operands[1] = rightReal.getRoot();
MySqlBasicCall root
= new MySqlBasicCall(new MySqlOperator(
joinType.name(), joinType), operands);
leftReal.setRoot(root);
leftReal.addFields(rightReal.getFields());
leftReal.getTableInfo().getQueryFields().addAll(rightReal.getFields());
leftReal.setLogicalOp(joinType);
return leftReal;
}
return new LineUpTwoTablePlan(left, right, joinType);
}
// 左子树为叶子节点或者已经经过合并后的结点
if(left instanceof SqlNodeSingleTableLogicalPlan) {
// 递归搜索右节点,如果找到同级别宽表,则返回right, 否则合并left+right
int backoffMergeDepth = mergeDeeplyRuleByExchangeLaw(mergeOp,
(SqlNodeSingleTableLogicalPlan) left,
(LineUpTwoTablePlan) right, joinType);
if(backoffMergeDepth == -1) {
return new LineUpTwoTablePlan(left, right, joinType);
}
return right;
}
// 右子树为叶子节点或者已经经过合并后的结点
if(right instanceof SqlNodeSingleTableLogicalPlan) {
// 递归搜索左节点,如果找到同级别宽表,则返回left, 否则合并left+right
int backoffMergeDepth = mergeDeeplyRuleByExchangeLaw(mergeOp,
(SqlNodeSingleTableLogicalPlan) right,
(LineUpTwoTablePlan) left, joinType);
if(backoffMergeDepth == -1) {
return new LineUpTwoTablePlan(left, right, joinType);
}
return left;
}
return new LineUpTwoTablePlan(left, right, joinType);
} /**
* 多层次同宽表合并逻辑计划
*
* @param mergeOp 当前计划节点合并方式,实际影响和 joinType 类似
* @param leafPlan 叶子计划(待合并的计划)
* @param masterPlan 主控计划(主分支,其他计划往其上合并)
* @param joinType 本次计算类型
* @return 被合并成功的深度(-1代表未合并成功,需外部再处理)
*/
private int mergeDeeplyRuleByExchangeLaw(MySqlNode mergeOp,
SqlNodeSingleTableLogicalPlan leafPlan,
LineUpTwoTablePlan masterPlan,
SyntaxTokenTypeEnum joinType) {
if(masterPlan == null) {
log.warn("主规则为空,请检查:{} -> {}, 可能遇到了不解析的规则", joinType, mergeOp);
throw new BizException(300326, "主规则为空,请检查:" + joinType + " -> " + mergeOp);
}
if(leafPlan == null) {
log.warn("叶子规则为空,请检查:{} -> {}, 可能遇到了不解析的规则", joinType, mergeOp);
throw new BizException(300326, "叶子规则为空,请检查:" + joinType + " -> " + mergeOp);
}
if(leafPlan.isUseBitmap()) {
return -1;
}
int depth = 0;
String leafTableName = leafPlan.getTableName();
if (masterPlan.getJoinType() == joinType) {
depth++;
// 先递归左节点
if(masterPlan.getLeft() instanceof SqlNodeSingleTableLogicalPlan) {
SqlNodeSingleTableLogicalPlan targetPlan
= (SqlNodeSingleTableLogicalPlan) masterPlan.getLeft();
if(leafTableName.equals(targetPlan.getTableName())) {
mergeSingleTablePlan(targetPlan, leafPlan, mergeOp, joinType);
return depth;
}
}
else if(masterPlan.getLeft() instanceof LineUpTwoTablePlan) {
int findDepth = mergeDeeplyRuleByExchangeLaw(mergeOp, leafPlan,
(LineUpTwoTablePlan)masterPlan.getLeft(), joinType);
if(findDepth != -1) {
return depth + findDepth;
}
}
// 再递归右节点
if(masterPlan.getRight() instanceof SqlNodeSingleTableLogicalPlan) {
SqlNodeSingleTableLogicalPlan targetPlan
= (SqlNodeSingleTableLogicalPlan) masterPlan.getRight();
if(leafTableName.equals(targetPlan.getTableName())) {
mergeSingleTablePlan(targetPlan, leafPlan, mergeOp, joinType);
return depth;
}
}
else if(masterPlan.getRight() instanceof LineUpTwoTablePlan) {
int findDepth = mergeDeeplyRuleByExchangeLaw(mergeOp, leafPlan,
(LineUpTwoTablePlan)masterPlan.getRight(), joinType);
if(findDepth != -1) {
return depth + findDepth;
}
}
}
return -1;
} /**
* 合并单表查询计划
*
* @param target 目标plan(往上合并)
* @param from 要合并的计划
* @param fromRoot 要合并的节点root
*/
private void mergeSingleTablePlan(SqlNodeSingleTableLogicalPlan target,
SqlNodeSingleTableLogicalPlan from,
MySqlNode fromRoot,
SyntaxTokenTypeEnum joinType) {
// todo: 注意论证左右节点顺序交换是否影响结果?
MySqlNode[] operands = new MySqlNode[2];
operands[0] = target.getRoot();
operands[1] = from.getRoot();
MySqlBasicCall root
= new MySqlBasicCall(new MySqlOperator(
joinType.name(), joinType), operands);
target.setRoot(root);
target.addFields(from.getFields());
target.getTableInfo().getQueryFields().addAll(from.getFields());
} /**
* 补充逻辑计划信息
*
* @param plan 计划描述
* @param fieldInfo 要补充的字段信息
*/
private void fullFillLogicalInfo(SqlNodeSingleTableLogicalPlan plan,
FieldInfoDescriptor fieldInfo) {
// go...
QueryTableDto tableDto = fieldInfo.getThemeTableInfo();
if(tableDto != null) {
plan.setTableInfo(tableDto);
plan.addFields(tableDto.getQueryFields());
if(StringUtils.isBlank(plan.getTableName())) {
plan.setTableName(tableDto.getTableName());
}
}
} private SqlNodeSingleTableLogicalPlan newLogicalPlan(MySqlNode root,
FieldInfoDescriptor fieldInfo) {
if(fieldInfo.isUseBitmap() && fieldInfo.getBitmapTable() == null) {
fieldInfo.setBitmapTable(tryGetMyBitmapTableName(fieldInfo));
}
SqlNodeSingleTableLogicalPlan logicalPlan = new SqlNodeSingleTableLogicalPlan(root);
logicalPlan.setTableName(fieldInfo.getBitmapTable());
logicalPlan.setUseBitmap(fieldInfo.getUseBitmap());
fullFillLogicalInfo(logicalPlan, fieldInfo);
logicalContainer.add(logicalPlan);
return logicalPlan;
} /**
* 标记各节点的深度,为下一步处理做准备
*
* @param root 根节点
* @param sqlBuilder x
*/
private void markNodeDepth(MySqlBasicCall root,
ClickHouseSqlBuilder sqlBuilder) {
MySqlNode[] childs = root.getOperands();
for (int i = 0; i < childs.length; i++) {
MySqlNode node = childs[i];
// todo: 如何判定当前节点是叶子节点?
if (node instanceof MySqlBasicCall) {
markNodeDepth((MySqlBasicCall) node, sqlBuilder);
root.setDistanceFromLeaf(Math.max(root.getDistanceFromLeaf(),
node.getDistanceFromLeaf()));
continue;
}
if (node instanceof MySqlCustomHandler) {
// 此处有问题,待解决
node.setDistanceFromLeaf(root.getDistanceFromLeaf());
continue;
}
}
if(childs.length != 2) {
log.warn("规则不支持非2个运算符, 个数不支持:{}, root:{}", childs.length, root);
throw new BizException(300130, "规则不支持非2个运算符");
}
root.setDistanceFromLeaf(root.getDistanceFromLeaf() + 1); } /**
* 逻辑计划统一接口
*/
private static class LogicalPlan { } /**
* 将两个查询条件连接起来的执行计划 (相当于join)
*
* 可聚合多个子条件
*/
private class LineUpTwoTablePlan extends LogicalPlan {
private LogicalPlan left;
private LogicalPlan right; /**
* 连接方式, 仅允许为 SQL_AND, SQL_OR , 其他方式一律不支持
*/
private SyntaxTokenTypeEnum joinType; public LineUpTwoTablePlan(LogicalPlan left,
LogicalPlan right,
SyntaxTokenTypeEnum joinType) {
this.left = left;
this.right = right;
this.joinType = joinType;
} public LogicalPlan getLeft() {
return left;
} public LogicalPlan getRight() {
return right;
} public SyntaxTokenTypeEnum getJoinType() {
return joinType;
} @Override
public String toString() {
return "JoinTwoTable#"
+ "[ " + left.toString() + " \n\t"
+ joinType.name() + " \n\t"
+ right.toString() + " ]";
}
} /**
* 单表执行计划
*/
private class SqlNodeSingleTableLogicalPlan extends LogicalPlan { /**
* 当前逻辑计划的根节点,如 (((a > 1) and b = '2') or (c <> 'x'))
* 相当于规则子表达式,此为规则分组
*/
private MySqlNode root; /**
* 代表当前表聚合了几个子表达式,提示性属性,无实际用处
*/
private int nodeCnt; /**
* 是否使用bitmap表,1:bitmap表, 0:宽表
*/
private int useBitmap;
private String tableName;
/**
* 表别名
*/
private String tableAlias; /**
* 临时生成的表顺序号
*/
private int tableIndex; private Set<QueryFieldDto> fields; private QueryTableDto tableInfo; private SqlNodeSingleTableLogicalPlan child;
private SqlNodeSingleTableLogicalPlan parent;
/**
* 与其兄弟节点的运算方式,and/or/andnot
*/
private SyntaxTokenTypeEnum logicalOp; public SqlNodeSingleTableLogicalPlan(MySqlNode root) {
this.root = root;
} public MySqlNode getRoot() {
return root;
} public void setRoot(MySqlNode root) {
this.root = root;
} public int getNodeCnt() {
return nodeCnt;
} public void setNodeCnt(int nodeCnt) {
this.nodeCnt = nodeCnt;
} public boolean isUseBitmap() {
return useBitmap == 1;
} public void setUseBitmap(int useBitmap) {
this.useBitmap = useBitmap;
} public String getTableName() {
return tableName;
} public void setTableName(String tableName) {
this.tableName = tableName;
} public Set<QueryFieldDto> getFields() {
return fields;
} public void setFields(Set<QueryFieldDto> fields) {
this.fields = fields;
} public void addFields(Collection<QueryFieldDto> fields) {
if(this.fields != null) {
this.fields.addAll(fields);
return;
}
this.fields = new LinkedHashSet<>();
this.fields.addAll(fields);
} public QueryTableDto getTableInfo() {
return tableInfo;
} public void setTableInfo(QueryTableDto tableInfo) {
this.tableInfo = tableInfo;
} public SqlNodeSingleTableLogicalPlan getChild() {
return child;
} public void setChild(SqlNodeSingleTableLogicalPlan child) {
this.child = child;
} public SqlNodeSingleTableLogicalPlan getParent() {
return parent;
} public void setParent(SqlNodeSingleTableLogicalPlan parent) {
this.parent = parent;
} public SyntaxTokenTypeEnum getLogicalOp() {
return logicalOp;
} public void setLogicalOp(SyntaxTokenTypeEnum logicalOp) {
this.logicalOp = logicalOp;
} public String getTableAlias() {
return tableAlias;
} public void setTableAlias(String tableAlias) {
this.tableAlias = tableAlias;
} public int getTableIndex() {
return tableIndex;
} public void setTableIndex(int tableIndex) {
this.tableIndex = tableIndex;
} @Override
public String toString() {
StringBuilder sb = new StringBuilder("SingleTableScan#")
.append(tableName)
.append("").append("[ ");
int i = 0;
for (QueryFieldDto r : fields) {
if(i++ == 0) {
sb.append(r.getField());
if(r.getAlia() != null) {
sb.append(" => ").append(r.getAlia());
}
continue;
}
sb.append(",").append(r.getField());
if(r.getAlia() != null) {
sb.append(" => ").append(r.getAlia());
}
}
sb.append(" where ").append(root.toString()).append(" ]");
return sb.toString();
}
} /**
* 获取解析树
*/
public MySqlNode getBinTreeRoot() {
return binTreeRoot;
} /**
* 处理普通的 三元操作节点
*
* @param root root
* @param sqlBuilder sql构造容器,所有sql结构直接写入该处
*/
private void visitCallNode(MySqlBasicCall root,
ClickHouseSqlBuilder sqlBuilder) {
MySqlNode[] childs = root.getOperands();
for (MySqlNode node : childs) {
if(node instanceof MySqlBasicCall) {
visitCallNode((MySqlBasicCall) node, sqlBuilder);
continue;
}
if(node instanceof MySqlCustomHandler) {
buildSqlWithCustomHandlerNode((MySqlCustomHandler) node, sqlBuilder);
continue;
}
}
if(childs.length != 2) {
log.warn("规则不支持非2个运算符, 个数不支持:{}, root:{}", childs.length, root);
throw new BizException(300130, "规则不支持非2个运算符");
}
buildSqlWithBinaryOperator(root, childs[0], childs[1], sqlBuilder); } /**
* udf类规则解析生成 sql
*/
private void buildSqlWithCustomHandlerNode(MySqlCustomHandler handler,
ClickHouseSqlBuilder sqlBuilder) {
SyntaxStatement stmt = handler.getStmt();
MyRuleStmtMixedType mixedType = stmt.getStmtType();
if(mixedType == MyRuleStmtMixedType.UDF_HANDLER
|| mixedType == MyRuleStmtMixedType.LBS_FUNCTION) {
String partialSql = stmt.translateTo(
MyDialectTypeEnum.CLICK_HOUSE, getMyIdMapping());
log.info("ck partial function sql:{}", partialSql);
List<SyntaxToken> IdContainer = handler.getHoldingMyIdList();
checkMyIdNum(IdContainer);
// 仅有一主键id运算的情况下,where条件就是整个语句(无需拆分)
String where = partialSql;
FieldInfoDescriptor fieldInfoDescriptor
= CommonMyConditionAstHandler.getFieldInfoByToken(
IdContainer.get(0), getMyIdMapping());
if(fieldInfoDescriptor.isUseBitmap()) {
String bitmapTableName = getMyBitmapTableName(fieldInfoDescriptor);
fieldInfoDescriptor.setBitmapTable(bitmapTableName);
buildBitmapTmpTableWithWhere(handler, fieldInfoDescriptor, where, sqlBuilder);
return;
}
else {
buildWideBitmapTmpTableWithWhere(handler, fieldInfoDescriptor, where, sqlBuilder);
return;
}
// 根据主键元数据信息,构建外围sql
}
} /**
* 宽表型的条件生成bitmap临时表方案
*/
private void buildWideBitmapTmpTableWithWhere(MySqlCustomHandler root,
FieldInfoDescriptor fieldInfoDescriptor,
String whereCondition,
ClickHouseSqlBuilder sqlBuilder) {
QueryTableDto themeTableInfo = getQueryWideTableInfoFromMyMeta(fieldInfoDescriptor);
String wideTableName = themeTableInfo.getTableName();
String custNoField = themeTableInfo.getJoinField();
// 主键名,字段名,注意map结构数据
String Name = fieldInfoDescriptor.getMyName();
// $123 转换,暂定样板
// bitmap表结构完全一样
String sqlAfterFrom = String.format("(SELECT %s, bitmapBuild(groupArray(toUInt64(%s))) uv " +
" FROM %s WHERE %s)", Name,
custNoField, wideTableName, whereCondition);
int tableIndex = tableCounter.getAndIncrement();
String tableAlias = "t" + tableIndex;
String userBitmapAlias = "user" + tableIndex;
Set<QueryFieldDto> fields = new HashSet<>();
fields.add(QueryFieldDto.newField("1", "join_id"));
fields.add(QueryFieldDto.newField("groupBitmapState(uv)", userBitmapAlias));
fields.add(QueryFieldDto.newField(Name, Name));
sqlBuilder.with(tableAlias, fields, sqlAfterFrom); QueryTableDto tableDto = new QueryTableDto(tableAlias, tableAlias, null,
fields, "join_id", null, false);
queryTableDtoList.add(tableDto); bitmapFunctionNodeContainer.put(root, userBitmapAlias);
} // 获取主键所在的宽表信息
private QueryTableDto getQueryWideTableInfoFromMyMeta(FieldInfoDescriptor fieldInfoDescriptor) {
QueryTableDto themeTableInfo = fieldInfoDescriptor.getThemeTableInfo();
if(themeTableInfo == null) {
List<ThemeIndex> themeIndexList
= themeIndexService.getByThemeID(fieldInfoDescriptor.getThemeId());
if(themeIndexList.isEmpty()) {
throw new BizException(300203, "主题索引信息未找到, 请先配置");
}
ThemeIndex themeIndex = themeIndexList.get(0);
String tableName = themeIndex.getValue();
if(tableName.contains(".")) {
tableName = StringUtils.substringAfterLast(tableName, ".");
}
String joinField = themeIndex.getCustField();
// no dt specify, all in one
themeTableInfo = new QueryTableDto(tableName, themeIndex.getAlias(), joinField, true);
fieldInfoDescriptor.setThemeTableInfo(themeTableInfo);
}
return themeTableInfo;
} /**
* 构建bitmap临时表(使用where条件) (如: udf函数处理)
*
* @param root 使用的运算节点
* @param Info 主键元数据信息
* @param whereCondition where查询条件
* @param sqlBuilder ck sql容器
*/
private void buildBitmapTmpTableWithWhere(MySqlCustomHandler root,
FieldInfoDescriptor Info,
String whereCondition,
ClickHouseSqlBuilder sqlBuilder) {
String bitmapTableName = Info.getBitmapTable();
String Name = Info.getMyName();
String sqlAfterFrom = String.format("%s WHERE %s", bitmapTableName, whereCondition);
int tableIndex = tableCounter.getAndIncrement();
String tableAlias = "t" + tableIndex;
String userBitmapAlias = "user" + tableIndex;
Set<QueryFieldDto> fields = new HashSet<>();
fields.add(QueryFieldDto.newField("1", "join_id"));
fields.add(QueryFieldDto.newField("groupBitmapMergeState(uv)", userBitmapAlias));
// fields.add(QueryFieldDto.newField("value", Name));
sqlBuilder.with(tableAlias, fields, sqlAfterFrom); QueryTableDto tableDto = new QueryTableDto(tableAlias, tableAlias, null,
fields, "join_id", null, false);
queryTableDtoList.add(tableDto); bitmapFunctionNodeContainer.put(root, userBitmapAlias);
} /**
* 暂只支持一个主键id进行带入运算
*/
private void checkMyIdNum(List<SyntaxToken> IdList) {
Map<String, Object> idMapping = new HashMap<>();
IdList.forEach(r -> {
Object v = idMapping.putIfAbsent(r.getRawWord(), r);
if(v != null) {
log.warn("主键id:{} 被引用多次,请检查是否是正常情况", r);
}
});
if(idMapping.size() > 1) {
throw new BizException(300206, "暂不支持函数中带多个主键id");
}
} /**
* 对细粒度的二元操作,构建sql
*
* @param root 当前节点root
* @param left 左子节点
* @param right 右子节点
* @param sqlBuilder sql构建器
*/
private void buildSqlWithBinaryOperator(MySqlBasicCall root,
MySqlNode left,
MySqlNode right,
ClickHouseSqlBuilder sqlBuilder) {
MySqlOperator operator = root.getOperator();
// 如 (a > 1) and (b <= '2021-09-08')
// 走bitmapAndOr() 函数
String leftBitmapParam = bitmapFunctionNodeContainer.get(left);
String rightBitmapParam = bitmapFunctionNodeContainer.get(right);
List<String> params = new ArrayList<>();
String currentBitmapFunc;
switch (operator.getKind()) {
case SQL_AND:
params.add(leftBitmapParam);
params.add(rightBitmapParam);
// 做 剔除操作
if(reverseBitmapFlagContainer.get(right) != null
&& reverseBitmapFlagContainer.get(right)) {
currentBitmapFunc = "bitmapAndnot(" + leftBitmapParam + "," + rightBitmapParam + ")";
}
else {
currentBitmapFunc = "bitmapAnd(" + leftBitmapParam + "," + rightBitmapParam + ")";
}
bitmapFunctionNodeContainer.put(root, currentBitmapFunc);
return;
case SQL_OR:
params.add(leftBitmapParam);
params.add(rightBitmapParam);
if(reverseBitmapFlagContainer.get(right) != null
&& reverseBitmapFlagContainer.get(right)) {
log.warn("不支持的剔除操作, 或 不属于白名单 类型的操作不支持, {}", root.toString());
throw new BizException(300209, "不支持的剔除操作");
}
else {
currentBitmapFunc = "bitmapOr(" + leftBitmapParam + "," + rightBitmapParam + ")";
}
bitmapFunctionNodeContainer.put(root, currentBitmapFunc);
return;
case SIMPLE_MATH_OPERATOR:
// 简单四则运算,忽略,可能记录些东西
log.warn("暂不支持四则运算的表达式:{}", root.toString());
throw new BizException(300211, "暂不支持四则运算的表达式:" + root.toString());
}
// a +-*/ 1 四则运算,暂时忽略
// 如 a > 1, 走子查询逻辑
// String sql = "SELECT 1 AS join_id, groupBitmapState(uv) AS users1 FROM _string_distribute WHERE name = '%s<主键名>' and value <operator> '%s<主键值>'";
if(left.getKind() == SyntaxTokenTypeEnum._ID
|| left.getKind() == SyntaxTokenTypeEnum._ID_NAME) {
// todo: 解析出主键元数据信息,决定使用哪一个类型的bitmap表,或者宽表
FieldInfoDescriptor fieldInfoDescriptor
= CommonMyConditionAstHandler.getFieldInfoByToken(
((MySqlLiteral)left).getValue(), getMyIdMapping());
if(fieldInfoDescriptor == null) {
log.warn("未找到主键元数据信息:{},请检查", left.toString());
}
else if(fieldInfoDescriptor.getUseBitmap() == 1) {
String bitmapTableName = getMyBitmapTableName(fieldInfoDescriptor);
fieldInfoDescriptor.setBitmapTable(bitmapTableName);
buildSimpleBitmapTmpTable(root, left, right, fieldInfoDescriptor, sqlBuilder);
return;
}
// 宽表的bitmap构建方式
else {
buildWideBitmapTmpTable(root, left, right, fieldInfoDescriptor, sqlBuilder);
return;
}
}
// $123 转换,暂定样板
// 以下仅试用于单测样例,在正式运行时不得执行
String sqlAfterFrom = "_string_distribute WHERE name = '" + left.toString()
+ "' and value " + operator.toString() + " " + right.toString() + "";
int tableIndex = tableCounter.getAndIncrement();
String tableAlias = "t" + tableIndex;
String userBitmapAlias = "user" + tableIndex;
Set<QueryFieldDto> fields = new HashSet<>();
fields.add(QueryFieldDto.newField("1", "join_id"));
fields.add(QueryFieldDto.newField("groupBitmapState(uv)", userBitmapAlias));
sqlBuilder.with(tableAlias, fields, sqlAfterFrom); QueryTableDto tableDto = new QueryTableDto(tableAlias, tableAlias, null,
fields, "join_id", null, false);
queryTableDtoList.add(tableDto); bitmapFunctionNodeContainer.put(root, userBitmapAlias);
} /**
* 获取主键所在的bitmap表名(如果不是bitmap型主键,抛出异常)
*
* @param fieldInfoDescriptor 主键元数据信息
* @return 主键所在bitmap表名
*/
private String getMyBitmapTableName(FieldInfoDescriptor fieldInfoDescriptor) {
if(!fieldInfoDescriptor.isUseBitmap()) {
throw new BizException(300208,
String.format("当前主键:%s不支持使用bitmap运算", fieldInfoDescriptor.getMyName()));
}
return tryGetMyBitmapTableName(fieldInfoDescriptor);
} /**
* 不抛出异常地获取bitmap表名
*
* @see #getMyBitmapTableName(FieldInfoDescriptor)
*/
private String tryGetMyBitmapTableName(FieldInfoDescriptor fieldInfoDescriptor) {
if(fieldInfoDescriptor.getBitmapTable() != null) {
return fieldInfoDescriptor.getBitmapTable();
}
// 白名单统一一张bitmap表
if(fieldInfoDescriptor.isWhitelistMy()) {
String tableName = ApolloUtil.getProperty(
"ck_whitelist_all_table_name", "bm_whitelist_all_bitmap");
fieldInfoDescriptor.setBitmapTable(tableName);
return tableName;
} /**
* tinyint
* smallint
* int
* bigint
* float
* double
* decimal
* timestamp
* date
* string
* varchar
* char
* boolean
* binary
* map
*/
String bitmapTableName = null;
String dataType = fieldInfoDescriptor.getDataType();
String distributeSuffix = "_Distribute_20210418";
if(dataType.equals("int") || dataType.endsWith("int")) {
bitmapTableName = "ch__int";
}
else if(dataType.equals("float")
|| dataType.equals("double")
|| dataType.equals("decimal")) {
bitmapTableName = "ch__double";
}
else if(dataType.equals("date") || dataType.equals("timestamp")) {
bitmapTableName = "ch__date";
}
else {
bitmapTableName = "ch__string";
}
// 如果是 is not null 类型,则到 ch__common 表中查询
bitmapTableName += distributeSuffix;
fieldInfoDescriptor.setBitmapTable(bitmapTableName);
return bitmapTableName;
} /**
* 非空用户bitmap集全表 (特殊表)
*/
private String getNotNullBitmapTableName() {
String bitmapTableName = "ch__common";
return bitmapTableName + "_Distribute_20210418";
} /**
* bitmap表的构建方式
*
* @param fieldInfoDescriptor 单个主键元数据信息
*/
private String buildSimpleBitmapTmpTable(MySqlBasicCall root,
MySqlNode left,
MySqlNode right,
FieldInfoDescriptor fieldInfoDescriptor,
ClickHouseSqlBuilder sqlBuilder) {
String bitmapTableName = fieldInfoDescriptor.getBitmapTable();
// todo: 此处仅假设只有一个主键左值,并无四则运算和函数运算
String Name = fieldInfoDescriptor.getMyName();
String sqlAfterFrom = null;
int tableIndex = tableCounter.getAndIncrement();
String tableAlias = "t" + tableIndex;
String userBitmapAlias = "user" + tableIndex;
Set<QueryFieldDto> fields = new HashSet<>();
fields.add(QueryFieldDto.newField("1", "join_id"));
if(fieldInfoDescriptor.isWhitelistMy()) {
String existOrNot = right.toString();
// xand $123 = 1, 且属于白名单,只需选出该白名单bitmap即可
// xor $123 = 1, 或属于白名单,结论是确定的
// xand $123 = 0, 且不属于白名单,需要做排除运算,这是个难题, 使用 andnot 上层处理
// xor $123 = 0, 或不属于白名单,需要上层运算改变,此处语义复杂,暂不实现
// 剔除属于白名单,属于白名单,不属于白名单,剔除不属于白名单
// SELECT arrayJoin(bitmapToArray(bitmapAndnot(bitmapBuild([1,2,3]),bitmapBuild([3,4,5])))) exclude_whitelist
sqlAfterFrom = String.format("%s WHERE name = '%s'",
bitmapTableName, Name);
fields.add(QueryFieldDto.newField("cust_no_bitmap_v", userBitmapAlias));
if("0".equals(existOrNot)) {
reverseBitmapFlagContainer.put(root, true);
}
}
else {
// $123 转换,暂定样板
// bitmap表结构完全一样
// is not null, 读取另一张特殊表
if(right.getKind() == SyntaxTokenTypeEnum.SQL_NOT_NULL) {
bitmapTableName = getNotNullBitmapTableName();
sqlAfterFrom = String.format("%s WHERE name = '%s'",
bitmapTableName, Name);
fields.add(QueryFieldDto.newField("groupBitmapMergeState(uv)", userBitmapAlias));
}
else {
String rightValue = translateRightNodeValue(right);
MySqlNode operator = root.getOperator();
// 如 (substring($123, 1, 10) = '2xx')
if(left instanceof MySqlCustomHandler) {
String leftSql = ((MySqlCustomHandler)left).getStmt().translateTo(
MyDialectTypeEnum.CLICK_HOUSE, getMyIdMapping());
String NameCond = "name = '" + Name + "'";
if(!leftSql.contains(NameCond)) {
leftSql = NameCond + " and " + leftSql;
}
sqlAfterFrom = String.format("%s WHERE %s %s %s",
bitmapTableName, leftSql, operator.toString(), rightValue);
}
else {
sqlAfterFrom = String.format("%s WHERE name = '%s' and value %s %s",
bitmapTableName, Name, operator.toString(), rightValue);
}
fields.add(QueryFieldDto.newField("groupBitmapMergeState(uv)", userBitmapAlias));
}
// mergeState后,无法获取具体的字段值了
// fields.add(QueryFieldDto.newField("value", Name));
}
sqlBuilder.with(tableAlias, fields, sqlAfterFrom); QueryTableDto tableDto = new QueryTableDto(tableAlias, tableAlias, null,
fields, "join_id", null, false);
queryTableDtoList.add(tableDto); bitmapFunctionNodeContainer.put(root, userBitmapAlias);
return userBitmapAlias;
} private static ThemeIndexService themeIndexService = SpringContextUtil.getBean(ThemeIndexService.class); /**
* 宽表型的条件生成bitmap临时表方案
*/
private String buildWideBitmapTmpTable(MySqlBasicCall root,
MySqlNode left,
MySqlNode right,
FieldInfoDescriptor fieldInfoDescriptor,
ClickHouseSqlBuilder sqlBuilder) {
QueryTableDto themeTableInfo = getQueryWideTableInfoFromMyMeta(fieldInfoDescriptor);
String bitmapTableName = themeTableInfo.getTableName();
String custNoField = themeTableInfo.getJoinField();
String Name = fieldInfoDescriptor.getMyName();
// bitmap表结构完全一样
MySqlNode operator = root.getOperator();
String rightValue = translateRightNodeValue(right);
String sqlAfterFrom = String.format(" %s " +
" WHERE %s %s %s", bitmapTableName,
Name, operator.toString(), rightValue);
int tableIndex = tableCounter.getAndIncrement();
String tableAlias = "t" + tableIndex;
String userBitmapAlias = "user" + tableIndex;
Set<QueryFieldDto> fields = new HashSet<>();
fields.add(QueryFieldDto.newField("1", "join_id"));
fields.add(QueryFieldDto.newField("groupBitmapState(toUInt64OrZero(" + custNoField + "))", userBitmapAlias));
// fields.add(QueryFieldDto.newField(Name, Name));
sqlBuilder.with(tableAlias, fields, sqlAfterFrom); QueryTableDto tableDto = new QueryTableDto(tableAlias, tableAlias, null,
fields, "join_id", null, false);
queryTableDtoList.add(tableDto); bitmapFunctionNodeContainer.put(root, userBitmapAlias);
return userBitmapAlias;
} /**
* 处理右节点值问题 (普通数据或简单关键词函数)
*
* @param right 右节点
* @return 翻译后的值
*/
private String translateRightNodeValue(MySqlNode right) {
String rightValue = null;
if(right.getKind() == SyntaxTokenTypeEnum.STATEMENT_HANDLER) {
MySqlCustomHandler handler = (MySqlCustomHandler)right;
rightValue = handler.getStmt().translateTo(
MyDialectTypeEnum.CLICK_HOUSE, getMyIdMapping());
log.info("ck partial function sql:{}", rightValue);
}
else {
rightValue = right.toString();
}
return rightValue;
} }
4.3. 单元测试
@Test
public void testNodeReGroup() {
MyRuleSqlNodeParsedClause parsedClause;
MySqlTranslator translator;
String ckSql;
String ruleEl;
MySqlTranslator.turnOnUseUnifiedParserSwitch(); ruleEl = "( substring ( field_2436 ,4 ,8 ) = '-08-' ) and ( substring ( field_4515 ,0 ,1 ) = '2' ) or ( substring ( field_27103 ,1 ,2 ) = '9' )";
testBinToRelConvertInner(ruleEl, null); ruleEl = "( field_461043 is not null ) and ( field_3728 is not null ) xor ( field_467492 = 1 )";
testBinToRelConvertInner(ruleEl, null); try {
ruleEl = "(field_4749 >= '2017-09-01') or (field_4748 >= '2017-09-01')";
testBinToRelConvertInner(ruleEl, null);
Assert.fail("ck支持lbs运算了?");
}
catch (Exception e) {
e.printStackTrace();
Assert.assertThat(e.getMessage(),
containsString("主键信息未找到,请检查:field_4748"));
} // is not null 处理
ruleEl = "( field_43221 is not null)";
testBinToRelConvertInner(ruleEl, null); ruleEl = "((field_469011 = 1 ) xor (field_469016 = 1 )) and ((field_40467 = '322') and (field_466911 = '0') and (substring(field_46789 ,0 ,2) in ('33')) and (field_40243 >= #{day-90}) and (field_40243 >= '20210704'))";
testBinToRelConvertInner(ruleEl, null); try {
// 空规则测试
ruleEl = " ";
testBinToRelConvertInner(ruleEl, null);
Assert.fail("空规则解析了?");
}
catch (Exception e) {
e.printStackTrace();
Assert.assertThat(e.getMessage(), containsString("不支持空规则配置"));
} try {
// 空规则测试
ruleEl = "( )";
testBinToRelConvertInner(ruleEl, null);
Assert.fail("空括号解析了?");
}
catch (Exception e) {
e.printStackTrace();
Assert.assertThat(e.getMessage(), containsString("不支持空括号"));
} try {
ruleEl = "( field_464592 is not null ) or ( field_472351 > 1 ) xor ( field_25100 = 1 )";
testBinToRelConvertInner(ruleEl, null);
Assert.fail("field_472351 主键元数据信息找到了?");
}
catch (Exception e) {
e.printStackTrace();
System.err.println("发现异常,忽略错误,报错信息待完善,暂不捕获");
} try {
ruleEl = "(field_3826 > Y) and (field_2475 = 1)";
testBinToRelConvertInner(ruleEl, null);
Assert.fail("Y被解析了?");
}
catch (Exception e) {
e.printStackTrace();
Assert.assertThat(e.getMessage(), containsString("主键id未找到对应元数据信息或规则配置错误:Y"));
} ruleEl = "( ( field_13428 between 500000 and 1999999.999 ) and ( field_37272 < 1999999.9999 ) and ( field_39866 < 1999999.9999 ) ) or ( ( field_13428 < 1999999.9999 ) and ( field_37272 between 500000 and 1999999.9999 ) and ( field_39866 < 1999999.9999 ) ) or ( ( field_13428 < 1999999.9999 ) and ( field_37272 < 1999999.9999 ) and ( field_39866 between 500000 and 1999999.9999 ) ) or ( field_3728 in ( '600103317730' , '600103331257' , '600205279354' ) )";
testBinToRelConvertInner(ruleEl, null); ruleEl = "( field_472691 = #{day+0} )";
testBinToRelConvertInner(ruleEl, null); ruleEl = "( field_471875 > 1 ) and ( field_27050 = 'Y' ) or field_471874 <> '3' or field_471831 < 'code'";
testBinToRelConvertInner(ruleEl, null); ruleEl = "( field_471875 > 1 ) and ( field_27050 = 'Y' ) or (field_471874 <> '3' and (field_471874 like 'abc%' or field_471874 < 'x')) or field_471831 < 'code'";
testBinToRelConvertInner(ruleEl, null); ruleEl = "( field_471875 > 1 ) and ( field_27050 = 'Y' ) or field_471831 < '__code' or (field_471874 <> '3' and (field_471874 like 'abc%' or (field_471874 < 'x' and field_471874 > 2))) or field_471831 < 'code'";
testBinToRelConvertInner(ruleEl, null); MySqlTranslator.turnOffUseUnifiedParserSwitch();
} private void testBinToRelConvertInner(String ruleEl, String expectSql) {
MyRuleSqlNodeParsedClause parsedClause;
MySqlTranslator translator;
String ckSql;
parsedClause = MySyntaxParser.parseAsTree(ruleEl);
parsedClause.resolveMyIdFromDB();
ckSql = parsedClause.translateFullCkSqlProf(false);
System.out.println("ckSql:" + ckSql);
}
4.4. 从calicite中摘取的 precedence util 参考
/**
* Parser that takes a collection of tokens (atoms and operators)
* and groups them together according to the operators' precedence
* and associativity.
*/
public class PrecedenceClimbingParser {
private Token first;
private Token last; private PrecedenceClimbingParser(List<Token> tokens) {
Token p = null;
for (Token token : tokens) {
if (p != null) {
p.next = token;
} else {
first = token;
}
token.previous = p;
token.next = null;
p = token;
}
last = p;
} public Token atom(Object o) {
return new Token(Type.ATOM, o, -1, -1);
} public Call call(Op op, ImmutableList<Token> args) {
return new Call(op, args);
} public Op infix(Object o, int precedence, boolean left) {
return new Op(Type.INFIX, o, precedence * 2 + (left ? 0 : 1),
precedence * 2 + (left ? 1 : 0));
} public Op prefix(Object o, int precedence) {
return new Op(Type.PREFIX, o, -1, precedence * 2);
} public Op postfix(Object o, int precedence) {
return new Op(Type.POSTFIX, o, precedence * 2, -1);
} public SpecialOp special(Object o, int leftPrec, int rightPrec,
Special special) {
return new SpecialOp(o, leftPrec * 2, rightPrec * 2, special);
} public Token parse() {
partialParse();
if (first != last) {
throw new AssertionError("could not find next operator to reduce: "
+ this);
}
return first;
} public void partialParse() {
for (;;) {
Op op = highest();
if (op == null) {
return;
}
final Token t;
switch (op.type) {
case POSTFIX:
t = call(op, ImmutableList.of(op.previous));
replace(t, op.previous.previous, op.next);
break;
case PREFIX:
t = call(op, ImmutableList.of(op.next));
replace(t, op.previous, op.next.next);
break;
case INFIX:
if(op.previous == null) {
throw new BizException(300421, "规则配置有误: 【" + op.toString()
+ "】的左边未配置值");
}
if(op.next == null) {
throw new BizException(300422, "规则配置有误: 【" + op.toString()
+ "】的右边未配置值");
}
t = call(op, ImmutableList.of(op.previous, op.next));
replace(t, op.previous.previous, op.next.next);
break;
case SPECIAL:
Result r = ((SpecialOp) op).special.apply(this, (SpecialOp) op);
Objects.requireNonNull(r);
replace(r.replacement, r.first.previous, r.last.next);
break;
default:
throw new AssertionError();
}
// debug: System.out.println(this);
}
} @Override public String toString() {
List<Token> all = all();
StringBuilder b = new StringBuilder(all.get(0).toString());
for (int i = 0; i < all.size(); i++) {
Token t = all.get(i);
b.append(", ").append(t.toString());
}
return b.toString();
} /** Returns a list of all tokens. */
public List<Token> all() {
return new TokenList();
} private void replace(Token t, Token previous, Token next) {
t.previous = previous;
t.next = next;
if (previous == null) {
first = t;
} else {
previous.next = t;
}
if (next == null) {
last = t;
} else {
next.previous = t;
}
} private Op highest() {
int p = -1;
Op highest = null;
for (Token t = first; t != null; t = t.next) {
if ((t.left > p || t.right > p)
&& (t.left < 0 || t.left >= prevRight(t.previous))
&& (t.right < 0 || t.right >= nextLeft(t.next))) {
p = Math.max(t.left, t.right);
highest = (Op) t;
}
}
return highest;
} /** Returns the right precedence of the preceding operator token. */
private int prevRight(Token token) {
for (; token != null; token = token.previous) {
if (token.type == Type.POSTFIX) {
return Integer.MAX_VALUE;
}
if (token.right >= 0) {
return token.right;
}
}
return -1;
} /** Returns the left precedence of the following operator token. */
private int nextLeft(Token token) {
for (; token != null; token = token.next) {
if (token.type == Type.PREFIX) {
return Integer.MAX_VALUE;
}
if (token.left >= 0) {
return token.left;
}
}
return -1;
} public String print(Token token) {
return token.toString();
} /** Token type. */
public enum Type {
ATOM,
CALL,
PREFIX,
INFIX,
POSTFIX,
SPECIAL
} /** A token: either an atom, a call to an operator with arguments,
* or an unmatched operator. */
public static class Token {
Token previous;
Token next;
public final Type type;
public final Object o;
final int left;
final int right; Token(Type type, Object o, int left, int right) {
this.type = type;
this.o = o;
this.left = left;
this.right = right;
} @Override public String toString() {
return o.toString();
} protected StringBuilder print(StringBuilder b) {
return b.append(o);
} public Token copy() {
return new Token(type, o, left, right);
}
} /** An operator token. */
public static class Op extends Token {
Op(Type type, Object o, int left, int right) {
super(type, o, left, right);
} @Override public Token copy() {
return new Op(type, o, left, right);
}
} /** An token corresponding to a special operator. */
public static class SpecialOp extends Op {
public final Special special; SpecialOp(Object o, int left, int right, Special special) {
super(Type.SPECIAL, o, left, right);
this.special = special;
} @Override public Token copy() {
return new SpecialOp(o, left, right, special);
}
} /** A token that is a call to an operator with arguments. */
public static class Call extends Token {
public final Op op;
public final ImmutableList<Token> args; Call(Op op, ImmutableList<Token> args) {
super(Type.CALL, null, -1, -1);
this.op = op;
this.args = args;
} @Override public Token copy() {
return new Call(op, args);
} @Override public String toString() {
return print(new StringBuilder()).toString();
} protected StringBuilder print(StringBuilder b) {
switch (op.type) {
case PREFIX:
b.append('(');
printOp(b, false, true);
args.get(0).print(b);
return b.append(')');
case POSTFIX:
b.append('(');
args.get(0).print(b);
return printOp(b, true, false).append(')');
case INFIX:
b.append('(');
args.get(0).print(b);
printOp(b, true, true);
args.get(1).print(b);
return b.append(')');
case SPECIAL:
printOp(b, false, false)
.append('(');
b.append("special");
// for (Ord<Token> arg : Ord.zip(args)) {
// if (arg.i > 0) {
// b.append(", ");
// }
// arg.e.print(b);
// }
return b.append(')');
default:
throw new AssertionError();
}
} private StringBuilder printOp(StringBuilder b, boolean leftSpace,
boolean rightSpace) {
String s = op.o.toString();
if (leftSpace) {
b.append(' ');
}
b.append(s);
if (rightSpace) {
b.append(' ');
}
return b;
}
} /** Callback defining the behavior of a special function. */
public interface Special {
/** Given an occurrence of this operator, identifies the range of tokens to
* be collapsed into a call of this operator, and the arguments to that
* call. */
Result apply(PrecedenceClimbingParser parser, SpecialOp op);
} /** Result of a call to {@link Special#apply}. */
public static class Result {
final Token first;
final Token last;
final Token replacement; public Result(Token first, Token last, Token replacement) {
this.first = first;
this.last = last;
this.replacement = replacement;
}
} /** Fluent helper to build a parser containing a list of tokens. */
public static class Builder {
final List<Token> tokens = new ArrayList<>();
private final PrecedenceClimbingParser dummy =
new PrecedenceClimbingParser(ImmutableList.of()); private Builder add(Token t) {
tokens.add(t);
return this;
} public Builder atom(Object o) {
return add(dummy.atom(o));
} public Builder call(Op op, Token arg0, Token arg1) {
return add(dummy.call(op, ImmutableList.of(arg0, arg1)));
} public Builder infix(Object o, int precedence, boolean left) {
return add(dummy.infix(o, precedence, left));
} public Builder prefix(Object o, int precedence) {
return add(dummy.prefix(o, precedence));
} public Builder postfix(Object o, int precedence) {
return add(dummy.postfix(o, precedence));
} public Builder special(Object o, int leftPrec, int rightPrec,
Special special) {
return add(dummy.special(o, leftPrec, rightPrec, special));
} /**
* 获取最末一个token 信息,辅助外部处理
*/
public Token getLastToken() {
if(tokens.isEmpty()) {
return null;
}
return tokens.get(tokens.size() - 1);
} public PrecedenceClimbingParser build() {
return new PrecedenceClimbingParser(tokens);
}
} /** List view onto the tokens in a parser. The view is semi-mutable; it
* supports {@link List#remove(int)} but not {@link List#set} or
* {@link List#add}. */
private class TokenList extends AbstractList<Token> {
@Override public Token get(int index) {
for (Token t = first; t != null; t = t.next) {
if (index-- == 0) {
return t;
}
}
throw new IndexOutOfBoundsException();
} @Override public int size() {
int n = 0;
for (Token t = first; t != null; t = t.next) {
++n;
}
return n;
} @Override public Token remove(int index) {
Token t = get(index);
if (t.previous == null) {
first = t.next;
} else {
t.previous.next = t.next;
}
if (t.next == null) {
last = t.previous;
} else {
t.next.previous = t.previous;
}
return t;
} @Override public Token set(int index, Token element) {
final Token t = get(index);
element.previous = t.previous;
if (t.previous == null) {
first = element;
} else {
t.previous.next = element;
}
element.next = t.next;
if (t.next == null) {
last = element;
} else {
t.next.previous = element;
}
return t;
}
}
} // End PrecedenceClimbingParser.java
以上,可以说是没有用现有大师轮子的情况下,自行实现了一个小的重组优化,也许现实意义并不太大,但是思考过程绝对是有用的。
sql改写优化:简单规则重组实现的更多相关文章
- SOAR SQL进行优化和改写的自动化工具
前言 SQL优化是程序开发中经常遇到的问题,尤其是在程序规模不断扩大的时候.SQL的好坏不仅制约着程序的规模,影响着用户的体验,甚至威胁着信息的安全. 我们经常听到说哪家平台挂了,哪家网站被黑了,但我 ...
- 小米正式开源 SQL 智能优化与改写工具 SOAR
近日,小米正式宣布开源 SOAR. 截至今日,该项目已经获得了 350 个「star」以及 44 个「fork」(GitHub项目地址:https://github.com/XiaoMi/soar) ...
- 从简单Sql探索优化之道
从简单Sql探索优化之道 梁敬彬 2016-03-17 09:39:41 本文需要优化的语句是select count(*) from t,这简单的统计语句一出,估计不少人纳闷了,能有啥优化空间,还优 ...
- dense_rank()+hash提示改写优化SQL
数据库环境:SQL SERVER 2005 今天看到一条SQL,返回10条数据,执行了50多S.刚好有空,就对它进行了优化,优化后1S出结果. 先看下原始SQL SELECT t1.line_no , ...
- sql的优化相关问题
这篇文章写的真心不错,值得仔细拜读,所以将其转载过来了. 一. 分析阶段 一 般来说,在系统分析阶段往往有太多需要关注的地方,系统各种功能性.可用性.可靠性.安全性需求往往吸引 ...
- SQL性能优化没有那么神秘
经常听说SQL Server最难的部分是性能优化,不禁让人感到优化这个工作很神秘,这种事情只有高手才能做.很早的时候我在网上看到一位高手写的博客,介绍了SQL优化的问题,从这些内容来看,优化并不都是一 ...
- ORACLE数据库学习之SQL性能优化详解
Oracle sql 性能优化调整 ...
- SQL 性能优化 总结
SQL 性能优化 总结 (1)选择最有效率的表名顺序(只在基于规则的优化器中有效): ORACLE的解析器按照从右到左的顺序处理FROM子句中的表名,FROM子句中写在最后的表(基础表 driving ...
- 深入SQL Server优化【推荐】
深入sql server优化,MSSQL优化,T-SQL优化,查询优化 十步优化SQL Server 中的数据访问故事开篇:你和你的团队经过不懈努力,终于使网站成功上线,刚开始时,注册用户较少,网站性 ...
随机推荐
- linux中conda升级R到4.0?
目录 前言 问题 曲线救国 前言 虽然我的win版本R已经用4了,但之前在Linux环境一直没用R4.0,因为Linux涉及的东西太多,担心不稳定,牵一发而动全身. 但现在有好些R包必须要用更新到R4 ...
- [linux] 常用命令及参数-2
sort 1 sort是把结果输出到标准输出,因此需要输出重定向将结果写入文件 2 sort seq.txt > file.txt 3 sort -u seq.txt 输出去重重复后的行 4 s ...
- R语言与医学统计图形-【12】ggplot2几何对象之条图
ggplot2绘图系统--几何对象之条图(包括误差条图) 1.条图 格式: geom_bar(mapping = , data = , stat = 'count', #统计变换默认计数 positi ...
- python 封装、绑定
目录 python 封装.绑定 1.数据.方法的封装 2.隐藏属性 3.开放接口 4.绑定方法 1.对象的绑定 2.类的绑定(classmethod) 3.非绑定方法(staticmethod) 4. ...
- C语言中的指针的小标可以是负数
首先,创建一个正常的数组 int A[20];.然后用指针指向其中间的元素 int *A2 = &(A[10]); 这样,A2[-10 ... 9] 就是一个可用的有效范围了. 1 2 3 4 ...
- 巩固java第七天
巩固内容: HTML 属性 属性是 HTML 元素提供的附加信息. HTML 属性 HTML 元素可以设置属性 属性可以在元素中添加附加信息 属性一般描述于开始标签 属性总是以名称/值对的形式出现,比 ...
- MapReduce03 框架原理InputFormat数据输入
目录 1 InputFormat数据输入 1.1 切片与MapTask并行度决定机制 问题引出 MapTask并行度决定机制 Job提交流程源码 切片源码 1.2 FileInputFormat切片机 ...
- 26. Linux GIT
windows git 下载链接: Msysgit https://git-scm.com/download/win 1 进入git bash进行第一次配置 git config --global ...
- 一起手写吧!Promise!
1.Promise 的声明 首先呢,promise肯定是一个类,我们就用class来声明. 由于new Promise((resolve, reject)=>{}),所以传入一个参数(函数),秘 ...
- keil 生成 bin 文件 gd32为例
fromelf --bin --output .\update\GD32F4xZ.bin .\Output\GD32450Z_EVAL.axf代表使用的keil内的工具代表输出公式,..表示: 输出 ...