BERT-MRC:统一化MRC框架提升NER任务效果
原创作者 | 疯狂的Max
01 背景
命名实体识别任务分为嵌套命名实体识别(nested NER)和普通命名实体识别(flat NER),而序列标注模型只能给一个token标注一个标签,因此对于嵌套NER任务,需要使用两个以上的序列标注模型来完成标注任务。
为了解决这一问题大部分人[1][2][3]用pipelined systems处理嵌套NER任务,但这种处理方式存在错误传播、运行时间长、手工提取特征强度大等问题。
受到当下一些研究者[4][5]将NLP问题转换为QA任务的启发,作者提出一种统一化MRC框架来同时解决nested NER和flat NER两种类型任务。
具体来说,就是将NER任务从原本的序列标注转变为MRC的任务形式[6]:每一个实体类型被表述为一句自然语言陈述的问句query,与文本context一起作为输入进入模型,对应的answer为问句中询问的实体在文本中的span位置或者对应的span内容。
此外,用MRC框架来解决NER任务的构想还带来了另一个好处。传统的NER任务,仅仅通过标注文本中的每个字符来解决问题,并没有充分利用对实体类型本身的语言表述所蕴含的先验知识。
而MRC任务,query中对实体类型本身的表述会一起进入模型,帮助模型理解实体类型的含义,从而更有利于在给定的context找出对应的实体。
举个例子,当query是“find an organization such as company, agency and institution in the context”,那么这样的query会促使模型将“organization”这个词和context中真正识别到的 organization 类型的实体联系起来。
同时,通过编码query中对“organization”更复杂的表述(“such as company, agency and institution”)进一步帮助模型消除对organization这一实体类型的近似类型的歧义,更好的理解“organization”这一实体类别本身的含义。
作者将BERT-MRC在nested NER和flat NER数据集上都进行实验,结果表明其性能都取得了SOTA的效果。
02 相关工作
1.NER
传统的NER任务都是通过序列标注模型实现的,从CRF发展到结合神经网络模型(LSTM,CNN,BiLSTM)+CRF的结构,而最近几年的大规模预训练模型BERT和ELMo进一步提升了NER任务的效果。
2.Nested NER
从2003年开始,就有研究针对实体的重叠问题采用手工规则进行定义。而后,相继出现用双层CRF结构的模型、基于语法树的模型等方式解决嵌套实体识别任务。近年来,随着预训练模型的兴起,一些研究利用BERT-based model处理nested NER任务,亦或是将其转化为sequence-to-sequence问题来处理。
3.MRC
MRC模型是指通过query来抽取出context中对应的answer spans,本质上来说属于2个多分类任务,即需要对context中的每个token输出其是否为answer span的starting position和ending position。
在过去的一两年里,各种NLP任务趋向于转换成MRC任务[6],而作者也提到之所以提出用MRC任务解决NER问题是受到[7]中将实体关系抽取任务转换为多轮QA问题处理的启发。
同时,作者认为该论文中利用模板化程式生成query会导致query缺乏多样性,因此在构造query时作者使用同义词或者举例的方式加入了更多的现实类知识以增强query的多样性。
03 NER任务转换为MRC任务的技术实现
1.任务形式

2.Query构造
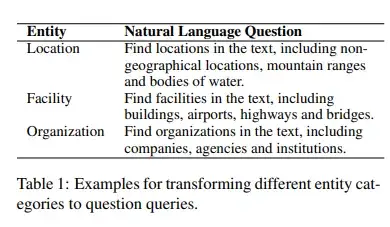
3.模型细节
3.1 模型主干
BERT-MRC将BERT作为基础模型主干,通过[CLS]和[SEP]将query和context连接起来,进入BERT模型训练,取BERT最后一层的context中字符的对应输出作为最终的输出。
3.2 Span 选择
MRC任务对于span选择有2种策略,一种是直接预测answer span的开始位置和结束位置分别对应的token index,但这种策略在给定query的情况下只能输出单个span。
另一种策略是对输入中的每个token都做一个二分类,来判断其是否为开始位置或者结束位置,这种策略就可以输出多个开始索引和多个结束索引,从而得到多个span。本文采用第二种策略。
对于start index的预测,通过BERT输出表示矩阵点乘一个可学习的参数矩阵T,然后通过softmax获得该token是否为start index, 如下图所示:
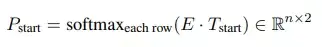
同理,end index的预测也通过以上方式获得。
对于每一个给定X,会出现多个可能的start index和end index,通过就近原则将他们匹配对应起来,显然是不合理的,因此将argmax运用于输出矩阵每行的

从而得到所有有可能的start index 和end index,如下所示:
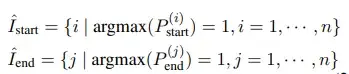
对于任意一个

通过sigmoid函数,构造一个二分类的输出即可,如下图所示(其中m也是一个可学习的参数矩阵):

04 损失计算
在训练阶段,X 中的每个token都会被赋予是否为start index和end index两个标签,其对应的损失函数计算如下:

而start和end匹配的损失函数,则表示如下:

最终模型的总损失,通过3个参数连接起来,其中

如下图公式所示:

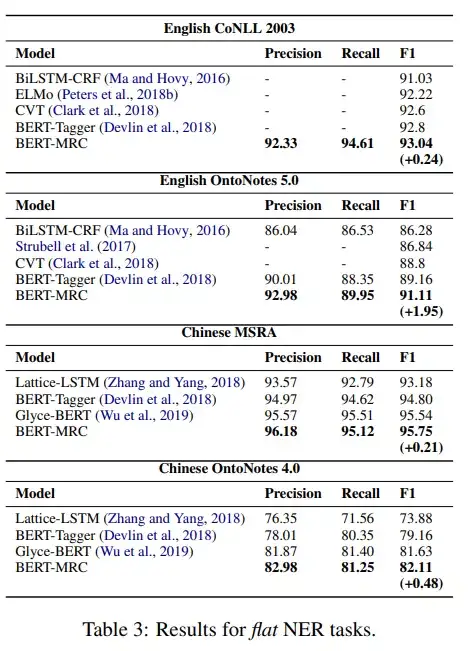
05 实验结果
如以下Table 2和Table 3所示,在nest NER任务和flat NER任务上,BERT-MRC的实验结果都超过了SOTA。

06 消融分析
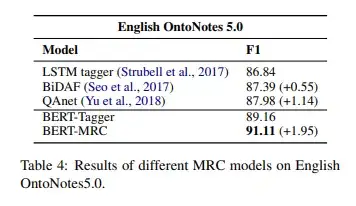
对于BERT-MRC性能的提升原因探究,不能确定是来自于将任务转化为了MRC形式还是来源于大规模BERT预训练模型自身。
因此,作者对比了LSTM-CRF模型和其他的MRC模型QAnet[8]和BiDAF[9],后两者并不依赖大规模预训练模型。
由下表Table 4可以看出,尽管效果不如BERT-Tagger,但基于MRC的方法QAnet和BiDAF仍然显著优于基于LSTM-CRF模型,由此可以证明将NER任务转换为MRC任务是有用的。
另外,从以下表Table 5可以看出,query的构造对结果也有重要影响。
其中值得一提的是,Position index of labels表现最差,原因在于仅仅使用标签对应的index来构造query,比如query被表述为“one”, “two”, “three”,不带有任何语义信息;另外,Wikipedia效果也不佳,可能是因为其表述过于笼统,比如其query是“an organization is an entity comprising multiple people, such as an institution or an association.”不能带来有效的语义信息补充。

还值得一提的是,由于BERT-MRC利用了query中的关于实体类型表述的先验知识,作者推测在较少训练数据的情况下,BERT-MRC也会有更好的表现。
如下图Figure 3所示:在中文OntoNotes4.0训练集上,基于query的BERT-MRC方法在训练数据量减半的情况下也能获得与BERT-Tagger相当的性能。

07 结论与研究思考
BERT-MRC模型将NER任务转换成MRC任务,其优势在于:
1)使用统一框架同时解决nested NER任务和flat NER任务;
2)有效利用了query中关于实体类型表述的先验知识,提高模型表现效果。
这样的模型改造方法可以应用到实际场景中,提升BERT-base的预训练模型在NER任务上的表现,并且在未来的研究中,可以更多关注于query的构造,不同垂直行业的NER任务有可能更依赖于对应的query构造策略来最大化先验知识带来的性能增益。
参考文献
[1] Beatrice Alex, Barry Haddow, and Claire Grover. 2007. Recognising nested named entities in biomedical text. In Proceedings of the Workshop on BioNLP 2007: Biological, Translational, and Clinical Language Processing, pages 65–72. Association for Computational Linguistics.
[2] Arzoo Katiyar and Claire Cardie. 2018. Nested named entity recognition revisited. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 861–871.
[3] Wei Lu and Dan Roth. 2015. Joint mention extraction and classification with mention hypergraphs. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 857–867.
[4] Omer Levy, Minjoon Seo, Eunsol Choi, and Luke Zettlemoyer. 2017. Zero-shot relation extraction via reading comprehension. arXiv preprint arXiv:1706.04115.
[5] Bryan McCann, Nitish Shirish Keskar, Caiming Xiong, and Richard Socher. 2018. The natural language decathlon: Multitask learning as question answering. arXiv preprint arXiv:1806.08730.
[6] 详解如何充分发挥先验信息优势,用MRC框架解决各类NLP任务
https://mp.weixin.qq.com/s/tvcG8sZSCUrUqob8MA6Nvw
[7] Xiaoya Li, Fan Yin, Zijun Sun, Xiayu Li, Arianna Yuan, Duo Chai, Mingxin Zhou, and Jiwei Li. 2019. Entity-relation extraction as multi-turn question answering. In Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, July 28- August 2, 2019, Volume 1: Long Papers, pages 1340–1350.
[8] Adams Wei Yu, David Dohan, Minh-Thang Luong, Rui Zhao, Kai Chen, Mohammad Norouzi, and Quoc V. Le. 2018. Qanet: Combining local convolution with global self-attention for reading comprehension. In 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April
[9] Omer Levy, Minjoon Seo, Eunsol Choi, and Luke Zettlemoyer. 2017. Zero-shot relation extraction via reading comprehension. arXiv preprint arXiv:1706.04115
私信我领取目标检测与R-CNN/数据分析的应用/电商数据分析/数据分析在医疗领域的应用/NLP学员项目展示/中文NLP的介绍与实际应用/NLP系列直播课/NLP前沿模型训练营等干货学习资源。
BERT-MRC:统一化MRC框架提升NER任务效果的更多相关文章
- 外媒速递:十大最佳心理学概念助你提升Web设计效果
外媒速递是核子可乐精选的近日国外媒体的精彩文章推荐,希望大家喜欢! 本期给大家推荐的是帮助你提升Web设计效果的十大最佳心理学概念.改善企业云环境协作效率的九款卓越工具.选择移动应用开发工具时要考虑的 ...
- 基于vue项目的组件中导入mui框架初始化滑动等效果时需移除严格模式的问题
基于vue项目的组件中导入mui框架初始化滑动等效果时,控制台报错:Uncaught TypeError: 'caller', 'callee', and 'arguments' properties ...
- NLP 基于kashgari和BERT实现中文命名实体识别(NER)
准备工作,先准备 python 环境,下载 BERT 语言模型 Python 3.6 环境 需要安装kashgari Backend pypi version desc TensorFlow 2.x ...
- 实用fork/join框架提升程序效率
实用fork/join框架提成程序效率 原文地址:https://www.jianshu.com/p/9ce243796d4a 业务场景 最近再做一个接口,我是一个中央的消息接受方,当我接受到消息后要 ...
- 运动曲线提升CSS动画效果
原文链接 译文\译者鞠大宝 先有UI动画,然后才会有好的UI动画.好的动画会让人惊叹“哇哦!”——因为页面看上去很流畅.很漂亮,最重要的是,自然,一点都不会让人觉得不和谐或者僵硬死板.如果你经常逛Dr ...
- 使用TypeScript如何提升JavaScript编程效果?
TypeScript是个什么鬼?和JavaScript有什么关系? TypeScript是由微软开发的一种可快速入门的开源的编程语言,是JavaScript的一个超集,且向这个语言添加了可选的静态类型 ...
- EDM邮件群发十大技巧提升邮件群发效果
有很多人抱怨现在邮件群发没有什么效果,其实不然,每一种推广方式都有他的优势,没有看到效果说明你没有掌握好方法.个人觉得EDM邮件群发的优势在于传播速度快.不受地域限制.不受时间限制.邮件内容能够多元化 ...
- 微信公众号开发系列-13、基于RDIFramework.NET框架整合微信开发应用效果展示
1.前言 通过前面一系列文章的学习,我们对微信公众号开发已经有了一个比较深入和全面的了解. 微信公众号开发为企业解决那些问题呢? 我们经常看到微信公众号定制开发.微信公众平台定制开发,都不知道这些能给 ...
- JAVA SE 框架之俄罗斯方块的效果
Mygame package com.sun.c; import java.awt.event.KeyListener; import com.sun.v.MyJpanel; import com.s ...
随机推荐
- Interesting Yang Yui Triangle(hdu3304)
Interesting Yang Yui Triangle Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K ...
- 【模型推理】量化实现分享三:详解 ACIQ 对称量化算法实现
欢迎关注我的公众号 [极智视界],回复001获取Google编程规范 O_o >_< o_O O_o ~_~ o_O 大家好,我是极智视界,本文剖析一下AC ...
- DAGs with NO TEARS: Continuous Optimization for Structure Learning
DAGs with NO TEARS: Continuous Optimization for Structure Learning 目录 DAGs with NO TEARS: Continuous ...
- rabbitmq-安装部署及基础操作
rabbitmq 官网: https://www.rabbitmq.com/ yum 安装 rabbitmq # centos7 # In /etc/yum.repos.d/rabbitmq.repo ...
- 2. node接口搭建--连接MongoDB数据库 (参考https://blog.csdn.net/ncepu_Chen/article/details/98725104#_337)
1.使用mongoose连接MongoDB数据库 npm install mongoose 2.新建文件夹config存放数据库地址 3.安装MongoDB
- IM2603资料 Type-C 扩展坞电源管理芯片
用于带有集成降压转换器的 Type-C 外围应用的电源管理 IC IM2603 是一款主要用于 Type-C 外围应用的电源管理 IC. 它集成了一个带有内置高侧 MOSFET 的同步降压转换器和一个 ...
- Linux_Vmtools的重安装与设置共享文件夹
前置准备 已经安装了Linux的Vm虚拟机 2. 虚拟机上已经安装gcc 重装Vmtools Part1 用root账号登录Linux 弹出原来cd Vm菜单栏 - 虚拟机(M) - 重新安装VmWa ...
- 使用 windows bat 脚本命令 一键启动MySQL服务
@echo off rem Copyright (c) 2019 Moses and/or its affiliates. rem Get Administrator Rights >nul 2 ...
- C#/.NET之WebAPI(从入门到放弃一)
1.怎么理解WebApi,他究竟是什么? 关于这一篇,视频学习可参照B站up主:全栈ACE,全栈ACE的个人空间,社区QQ群如下,有什么问题也可加群咨询. 首先使用Visual Studio创建一个新 ...
- JZOJ5405 & AtCoder Grand Contest 001 F. Permutation
题目大意 给出一个长度为\(n\)的排列\(P\)与一个正整数\(k\). 你需要进行如下操作任意次, 使得排列\(P\)的字典序尽量小. 对于两个满足\(|i-j|>=k\) 且\(|P_i- ...