| 1 |
SwinV2-G (HTC++) |
63.1 |
|
|
|
|
|
|
|
Swin Transformer V2: Scaling Up Capacity and Resolution |
Link |
|
2021 |
Swin-Transformer |
| 2 |
Florence-CoSwin-H |
62.4 |
|
|
|
|
|
|
|
Florence: A New Foundation Model for Computer Vision |
|
|
2021 |
Swin-Transformer |
| 3 |
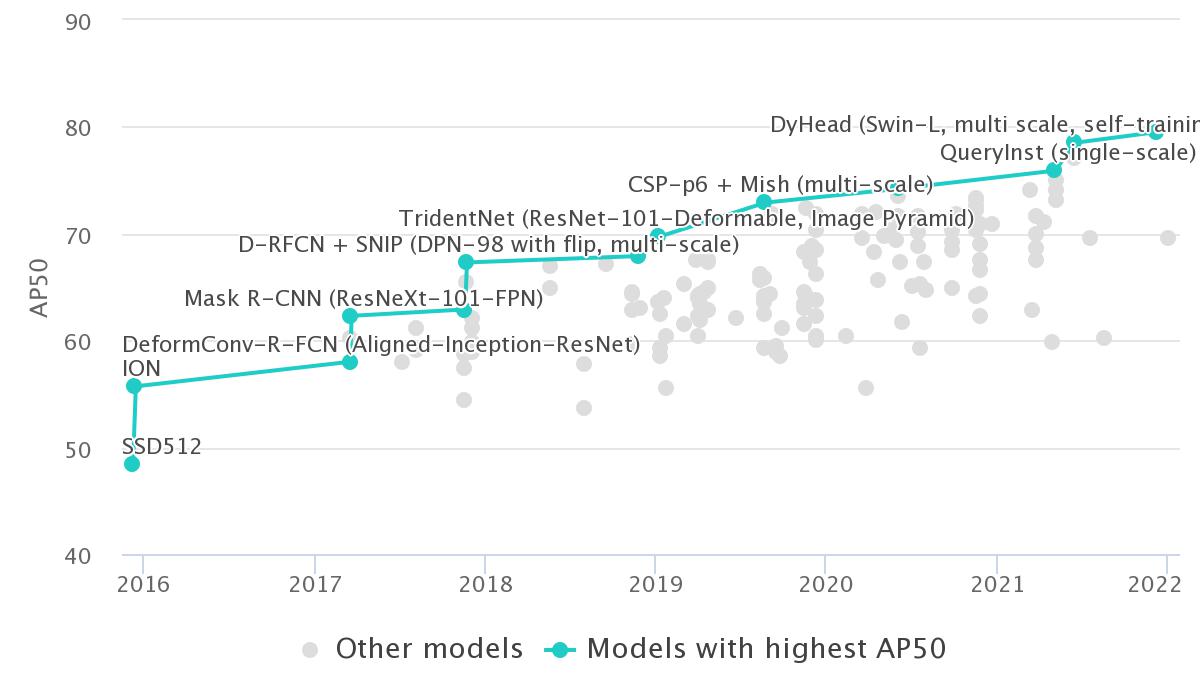
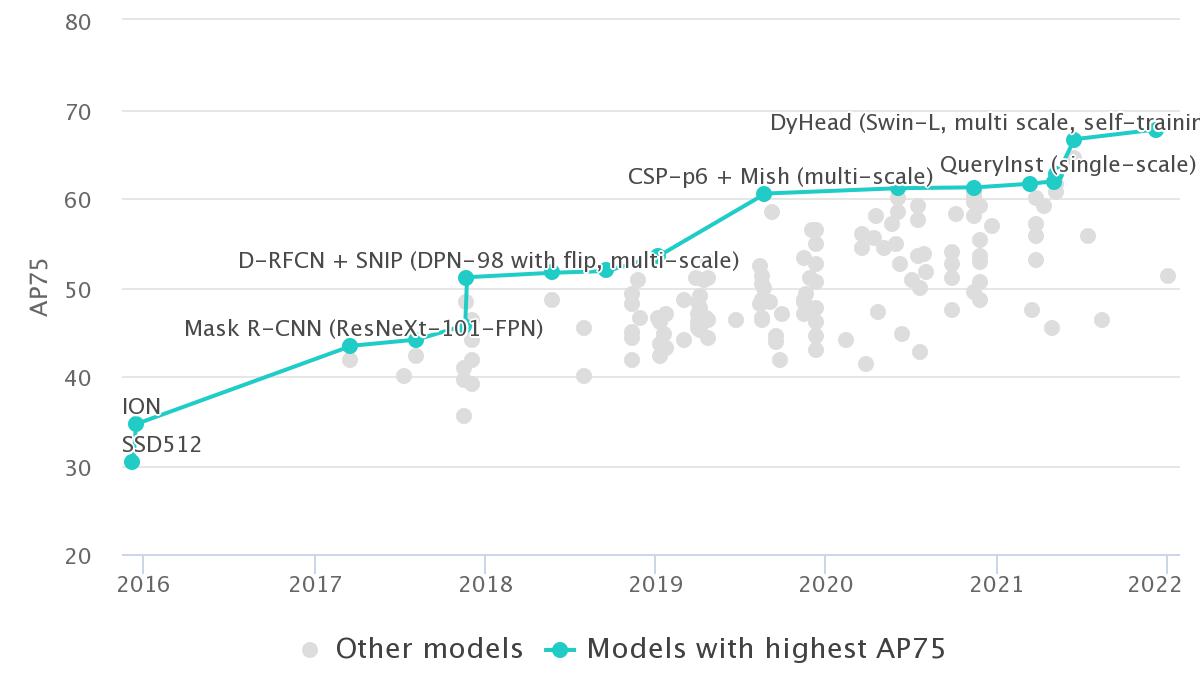
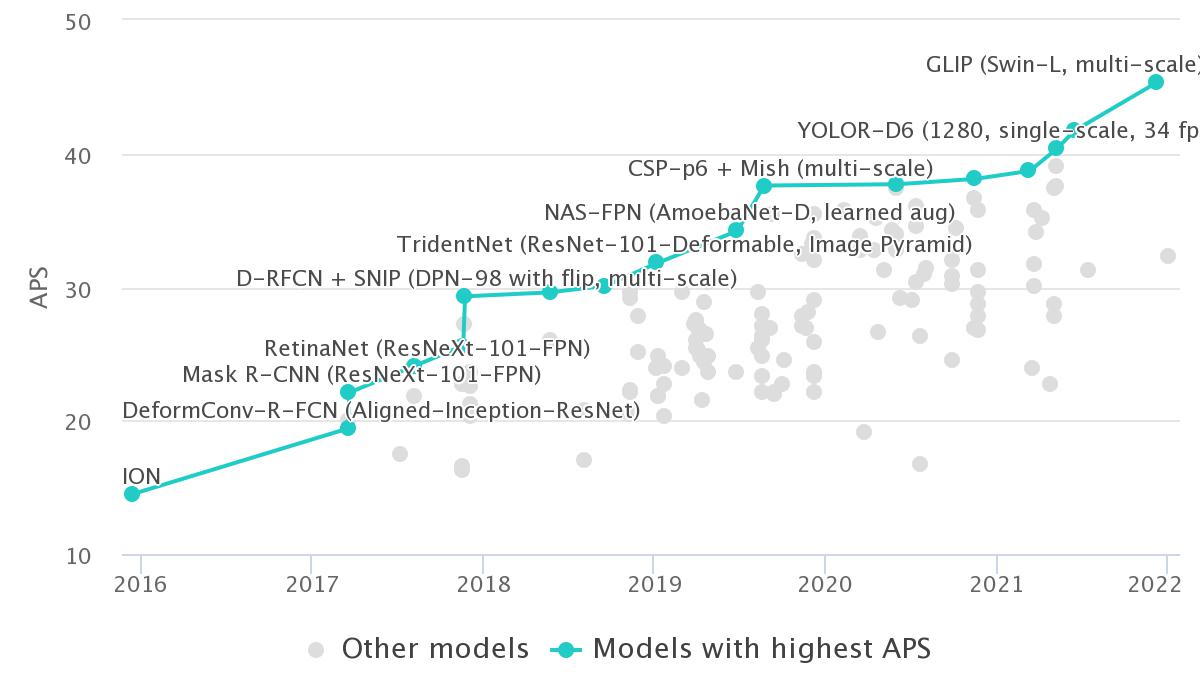
GLIP (Swin-L, multi-scale) |
61.5 |
79.5 |
67.7 |
45.3 |
64.9 |
75.0 |
|
|
Grounded Language-Image Pre-training |
|
|
2021 |
multiscale;
Vision Language;
Dynamic Head;
BERT-Base |
| 4 |
Soft Teacher + Swin-L (HTC++, multi-scale) |
61.3 |
|
|
|
|
|
|
|
End-to-End Semi-Supervised Object Detection with Soft Teacher |
|
|
2021 |
multiscale;
Swin-Transformer |
| 5 |
DyHead (Swin-L, multi scale, self-training) |
60.6 |
78.5 |
66.6 |
|
64.0 |
74.2 |
|
|
Dynamic Head: Unifying Object Detection Heads with Attentions |
|
|
2021 |
multiscale;
Swin-Transformer |
| 6 |
Dual-Swin-L (HTC, multi-scale) |
60.1 |
|
|
|
|
|
|
|
CBNetV2: A Composite Backbone Network Architecture for Object Detection |
|
|
2021 |
multiscale
Swin-Transformer |
| 7 |
Dual-Swin-L (HTC, single-scale) |
59.4 |
|
|
|
|
|
|
|
CBNetV2: A Composite Backbone Network Architecture for Object Detection |
|
|
2021 |
Swin-Transformer |
| 8 |
Focal-L (DyHead, multi-scale) |
58.9 |
|
|
|
|
|
|
|
Focal Self-attention for Local-Global Interactions in Vision Transformers |
|
|
2021 |
multiscale
Focal-Transformer |
| 9 |
DyHead (Swin-L, multi scale) |
58.7 |
77.1 |
64.5 |
41.7 |
62.0 |
72.8 |
|
|
Dynamic Head: Unifying Object Detection Heads with Attentions |
|
|
2021 |
multiscale
Swin-Transformer |
| 10 |
Swin-L (HTC++, multi scale) |
58.7 |
|
|
|
|
|
|
|
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows |
|
|
2021 |
multiscale
Swin-Transformer |
| 11 |
Focal-L (HTC++, multi-scale) |
58.4 |
|
|
|
|
|
|
|
Focal Self-attention for Local-Global Interactions in Vision Transformers |
|
|
2021 |
multiscale |
| 12 |
Swin-L (HTC++, single scale) |
57.7 |
|
|
|
|
|
|
|
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows |
|
|
2021 |
single scale
Swin-Transformer |
| 13 |
YOLOR-D6 (1280, single-scale, 34 fps) |
57.3 |
75.0 |
62.7 |
40.4 |
61.2 |
69.2 |
|
|
You Only Learn One Representation: Unified Network for Multiple Tasks |
|
|
2021 |
single scale
YOLO |
| 14 |
SOLQ (Swin-L, single) |
56.5 |
|
|
|
|
|
|
|
SOLQ: Segmenting Objects by Learning Queries |
|
|
2021 |
Transformer
single scale |
| 15 |
YOLOR-E6 (1280, single-scale, 45 fps) |
56.4 |
74.1 |
61.6 |
39.1 |
60.1 |
68.2 |
|
|
You Only Learn One Representation: Unified Network for Multiple Tasks |
|
|
2021 |
single scale
YOLO |
| 16 |
CenterNet2 (Res2Net-101-DCN-BiFPN, self-training, 1560 single-scale) |
56.4 |
74.0 |
61.6 |
38.7 |
59.7 |
68.6 |
|
|
Probabilistic two-stage detection |
|
|
2021 |
single scale
FPN
DCN |
| 17 |
QueryInst (single-scale) |
56.1 |
75.9 |
61.9 |
37.4 |
58.9 |
70.3 |
|
|
Instances as Queries |
|
|
2021 |
|
| 18 |
YOLOv4-P7 with TTA |
55.8 |
73.2 |
61.2 |
|
|
|
|
|
Scaled-YOLOv4: Scaling Cross Stage Partial Network |
|
|
2020 |
multiscale
YOLO |
| 19 |
DetectoRS (ResNeXt-101-64x4d, multi-scale) |
55.7 |
74.2 |
61.1 |
37.7 |
58.4 |
68.1 |
|
|
DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution |
|
|
2020 |
ResNeXt
multiscale |
| 20 |
YOLOR-W6 (1280, single-scale, 66 fps) |
55.5 |
73.2 |
60.6 |
37.6 |
59.5 |
67.7 |
|
|
You Only Learn One Representation: Unified Network for Multiple Tasks |
|
|
2021 |
single scale
YOLO |
| 21 |
YOLOv4-P7 CSP-P7 (single-scale, 16 fps) |
55.4 |
73.3 |
60.7 |
38.1 |
59.5 |
67.4 |
|
|
Scaled-YOLOv4: Scaling Cross Stage Partial Network |
|
|
2020 |
single scale
YOLO |
| 22 |
CSP-p6 + Mish (multi-scale) |
55.2 |
72.9 |
60.5 |
37.6 |
59.0 |
66.9 |
|
|
Mish: A Self Regularized Non-Monotonic Activation Function |
|
|
2019 |
multiscale |
| 23 |
YOLOv4-P6 with TTA |
54.9 |
72.6 |
60.2 |
|
|
|
|
|
Scaled-YOLOv4: Scaling Cross Stage Partial Network |
|
|
2020 |
multiscale
YOLO |
| 24 |
Cascade Eff-B7 NAS-FPN (1280) |
54.8 |
|
|
|
|
|
|
|
Simple Copy-Paste is a Strong Data Augmentation Method for Instance Segmentation |
|
|
2020 |
single scale
NAS-FPN |
| 25 |
DetectoRS (ResNeXt-101-32x4d, multi-scale) |
54.7 |
73.5 |
60.1 |
37.4 |
57.3 |
66.4 |
|
|
DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution |
|
|
2020 |
ResNeXt
multiscale |
| 26 |
YOLOv4-P6 CSP-P6 (single-scale, 32 fps) |
54.3 |
72.3 |
59.5 |
36.6 |
58.2 |
65.5 |
|
|
Scaled-YOLOv4: Scaling Cross Stage Partial Network |
|
|
2020 |
single scale
YOLO |
| 27 |
SpineNet-190 (1280, with Self-training on OpenImages, single-scale) |
54.3 |
|
|
|
|
|
|
|
Rethinking Pre-training and Self-training |
|
|
2020 |
single scale |
| 28 |
UniverseNet-20.08d (Res2Net-101, DCN, multi-scale) |
54.1 |
71.6 |
59.9 |
35.8 |
57.2 |
67.4 |
|
|
USB: Universal-Scale Object Detection Benchmark |
|
|
2021 |
multiscale
DCN |
| 29 |
EfficientDet-D7 (single-scale) |
53.7 |
72.4 |
|
|
57.0 |
66.3 |
|
|
EfficientDet: Scalable and Efficient Object Detection |
|
|
2019 |
single scale |
| 30 |
PAA (ResNext-152-32x8d + DCN, multi-scale) |
53.5 |
71.6 |
59.1 |
36.0 |
56.3 |
66.9 |
|
|
Probabilistic Anchor Assignment with IoU Prediction for Object Detection |
|
|
2020 |
ResNeXt
multiscale
DCN |
| 31 |
LSNet (Res2Net-101+ DCN, multi-scale) |
53.5 |
71.1 |
59.2 |
35.2 |
56.4 |
65.8 |
|
|
Location-Sensitive Visual Recognition with Cross-IOU Loss |
|
|
2021 |
multiscale
DCN |
| 32 |
ResNeSt-200 (multi-scale) |
53.3 |
72.0 |
58.0 |
35.1 |
56.2 |
66.8 |
|
|
ResNeSt: Split-Attention Networks |
|
|
2020 |
multiscale |
| 33 |
Cascade Mask R-CNN (Triple-ResNeXt152, multi-scale) |
53.3 |
71.9 |
58.5 |
35.5 |
55.8 |
66.7 |
|
|
CBNet: A Novel Composite Backbone Network Architecture for Object Detection |
|
|
2019 |
multiscale |
| 34 |
DetectoRS (ResNeXt-101-32x4d, single-scale) |
53.3 |
71.6 |
58.5 |
33.9 |
56.5 |
66.9 |
|
|
DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution |
|
|
2020 |
ResNeXt
single scale |
| 35 |
GFLV2 (Res2Net-101, DCN, multiscale) |
53.3 |
70.9 |
59.2 |
35.7 |
56.1 |
65.6 |
|
|
Generalized Focal Loss V2: Learning Reliable Localization Quality Estimation for Dense Object Detection |
|
|
2020 |
multiscale
DCN |
| 36 |
RelationNet++ (ResNeXt-64x4d-101-DCN) |
52.7 |
|
|
|
|
|
|
|
RelationNet++: Bridging Visual Representations for Object Detection via Transformer Decoder |
|
|
2020 |
ResNeXt
DCN |
| 37 |
YOLOv4-P5 with TTA |
52.5 |
70.3 |
58 |
|
|
|
|
|
Scaled-YOLOv4: Scaling Cross Stage Partial Network |
|
|
2020 |
multiscale
YOLO |
| 38 |
Deformable DETR (ResNeXt-101+DCN) |
52.3 |
71.9 |
58.1 |
34.4 |
54.4 |
65.6 |
|
|
Deformable DETR: Deformable Transformers for End-to-End Object Detection |
|
|
2020 |
ResNeXt
DCN |
| 39 |
GCNet (ResNeXt-101 + DCN + cascade + GC r4) |
52.3 |
70.9 |
56.9 |
|
|
|
|
|
Global Context Networks |
|
|
2020 |
ResNeXt
DCN
GCN |
| 40 |
RetinaNet (SpineNet-190, 1280x1280) |
52.1 |
71.8 |
56.5 |
35.4 |
55 |
63.6 |
|
|
SpineNet: Learning Scale-Permuted Backbone for Recognition and Localization |
|
|
2019 |
|
| 41 |
RepPoints v2 (ResNeXt-101, DCN, multi-scale) |
52.1 |
70.1 |
57.5 |
34.5 |
54.6 |
63.6 |
|
|
RepPoints V2: Verification Meets Regression for Object Detection |
|
|
2020 |
ResNeXt;
multiscale
DCN |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 42 |
AC-FPN Cascade R-CNN (X-152-32x8d-FPN-IN5k, multi scale, only CEM) |
51.9 |
70.4 |
57 |
34.2 |
54.8 |
64.7 |
|
|
Attention-guided Context Feature Pyramid Network for Object Detection |
|
|
2020 |
ResNeXt
multiscale
FPN |
| 43 |
OTA (ResNeXt-101+DCN, multiscale) |
51.5 |
68.6 |
57.1 |
34.1 |
53.7 |
64.1 |
|
|
OTA: Optimal Transport Assignment for Object Detection |
|
|
2021 |
|
| 44 |
UniverseNet-20.08d (Res2Net-101, DCN, single-scale) |
51.3 |
70.0 |
55.8 |
31.7 |
55.3 |
64.9 |
|
|
USB: Universal-Scale Object Detection Benchmark |
|
|
2021 |
single scale
DCN |
| 45 |
TSD (SENet154-DCN,multi-scale) |
51.2 |
71.9 |
56.0 |
33.8 |
54.8 |
64.2 |
|
|
Revisiting the Sibling Head in Object Detector |
|
|
2020 |
multiscale
DCN |
| 46 |
YOLOX-X (Modified CSP v5) |
51.2 |
69.6 |
55.7 |
31.2 |
56.1 |
66.1 |
|
|
YOLOX: Exceeding YOLO Series in 2021 |
|
|
2021 |
YOLO |
| 47 |
RetinaNet (SpineNet-143, 1280x1280) |
50.7 |
70.4 |
54.9 |
33.6 |
53.9 |
62.1 |
|
|
SpineNet: Learning Scale-Permuted Backbone for Recognition and Localization |
|
|
2019 |
|
| 48 |
ATSS (ResNetXt-64x4d-101+DCN,multi-scale) |
50.7 |
68.9 |
56.3 |
33.2 |
52.9 |
62.4 |
|
|
Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection |
|
|
2019 |
ResNeXt
multiscale
DCN |
| 49 |
NAS-FPN (AmoebaNet-D, learned aug) |
50.7 |
|
|
34.2 |
55.5 |
64.5 |
|
|
Learning Data Augmentation Strategies for Object Detection |
|
|
2019 |
FPN |
| 50 |
GFLV2 (Res2Net-101, DCN) |
50.6 |
69 |
55.3 |
31.3 |
54.3 |
63.5 |
|
|
Generalized Focal Loss V2: Learning Reliable Localization Quality Estimation for Dense Object Detection |
|
|
2020 |
DCN |
| 51 |
aLRP Loss (ResNext-101-64x4d, DCN, multiscale test) |
50.2 |
70.3 |
53.9 |
32.0 |
53.1 |
63.0 |
|
|
A Ranking-based, Balanced Loss Function Unifying Classification and Localisation in Object Detection |
|
|
2020 |
ResNeXt
multiscale
DCN |
| 52 |
FreeAnchor + SEPC (DCN, ResNext-101-64x4d) |
50.1 |
69.8 |
54.3 |
31.3 |
53.3 |
63.7 |
|
|
Scale-Equalizing Pyramid Convolution for Object Detection |
|
|
2020 |
ResNeXt
DCN |
| 53 |
D2Det (ResNet-101-DCN, multi-scale test) |
50.1 |
69.4 |
54.9 |
32.7 |
52.7 |
62.1 |
|
|
D2Det: Towards High Quality Object Detection and Instance Segmentation |
|
|
2020 |
multiscale
DCN
ResNet |
| 54 |
Dynamic R-CNN (ResNet-101-DCN, multi-scale) |
50.1 |
68.3 |
55.6 |
32.8 |
53.0 |
61.2 |
|
|
Dynamic R-CNN: Towards High Quality Object Detection via Dynamic Training |
|
|
2020 |
multiscale
DCN
ResNet |
| 55 |
TSD (ResNet-101-Deformable, Image Pyramid) |
49.4 |
69.6 |
54.4 |
32.7 |
52.5 |
61.0 |
|
|
Revisiting the Sibling Head in Object Detector |
|
|
2020 |
ResNet |
| 56 |
RepPoints v2 (ResNeXt-101, DCN) |
49.4 |
68.9 |
53.4 |
30.3 |
52.1 |
62.3 |
|
|
RepPoints V2: Verification Meets Regression for Object Detection |
|
|
2020 |
ResNeXt
DCN |
| 57 |
CPNDet (Hourglass-104, multi-scale) |
49.2 |
67.3 |
53.7 |
31.0 |
51.9 |
62.4 |
|
|
Corner Proposal Network for Anchor-free, Two-stage Object Detection |
|
|
2020 |
multiscale |
| 58 |
GFLV2 (ResNeXt-101, 32x4d, DCN) |
49 |
67.6 |
53.5 |
29.7 |
52.4 |
61.4 |
|
|
Generalized Focal Loss V2: Learning Reliable Localization Quality Estimation for Dense Object Detection |
|
|
2020 |
ResNeXt
DCN |
| 59 |
aLRP Loss (ResNext-101-64x4d, DCN, single scale) |
48.9 |
69.3 |
52.5 |
30.8 |
51.5 |
62.1 |
|
|
A Ranking-based, Balanced Loss Function Unifying Classification and Localisation in Object Detection |
|
|
2020 |
ResNeXt
single scale
DCN |
| 60 |
UniverseNet-20.08 (Res2Net-50, DCN, single-scale) |
48.8 |
67.5 |
53.0 |
30.1 |
52.3 |
61.1 |
|
|
USB: Universal-Scale Object Detection Benchmark |
|
|
2021 |
single scale
DCN |
| 61 |
SOLQ (ResNet101, single scale) |
48.7 |
|
|
|
|
|
|
|
SOLQ: Segmenting Objects by Learning Queries |
|
|
2021 |
Transformer
single scale |
| 62 |
RetinaNet (SpineNet-96, 1024x1024) |
48.6 |
68.4 |
52.5 |
32 |
52.3 |
62 |
|
|
SpineNet: Learning Scale-Permuted Backbone for Recognition and Localization |
|
|
2019 |
|
| 63 |
TridentNet (ResNet-101-Deformable, Image Pyramid) |
48.4 |
69.7 |
53.5 |
31.8 |
51.3 |
60.3 |
|
|
Scale-Aware Trident Networks for Object Detection |
|
|
2019 |
ResNet |
| 64 |
GCNet (ResNeXt-101 + DCN + cascade + GC r4) |
48.4 |
67.6 |
52.7 |
|
|
|
|
|
GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond |
|
|
2019 |
ResNeXt
DCN
GCN |
| 65 |
GFLV2 (ResNet-101-DCN) |
48.3 |
66.5 |
52.8 |
28.8 |
51.9 |
60.7 |
|
|
Generalized Focal Loss V2: Learning Reliable Localization Quality Estimation for Dense Object Detection |
|
|
2020 |
DCN
ResNet |
| 66 |
GFL (X-101-32x4d-DCN, single-scale) |
48.2 |
67.4 |
52.6 |
29.2 |
51.7 |
60.2 |
|
|
Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection |
|
|
2020 |
ResNeXt
single scale
DCN |
| 67 |
ISTR (ResNet101-FPN-3x, single-scale) |
48.1 |
|
|
28.7 |
50.4 |
61.5 |
|
|
ISTR: End-to-End Instance Segmentation with Transformers |
|
|
2021 |
|
| 68 |
aLRP Loss (ResNext-101-64x4d, single scale) |
47.8 |
68.4 |
51.1 |
30.2 |
50.8 |
59.1 |
|
|
A Ranking-based, Balanced Loss Function Unifying Classification and Localisation in Object Detection |
|
|
2020 |
ResNeXt
single scale |
| 69 |
MatrixNet Corners (ResNet-152, multi-scale) |
47.8 |
66.2 |
52.3 |
29.7 |
50.4 |
60.7 |
|
|
Matrix Nets: A New Deep Architecture for Object Detection |
|
|
2019 |
multiscale
ResNet |
| 70 |
SOLQ (ResNet50, single scale) |
47.8 |
|
|
|
|
|
|
|
SOLQ: Segmenting Objects by Learning Queries |
|
|
2021 |
Transformer
single scale |
| 71 |
SAPD (ResNeXt-101, single-scale) |
47.4 |
67.4 |
51.1 |
28.1 |
50.3 |
61.5 |
|
|
Soft Anchor-Point Object Detection |
|
|
2019 |
ResNeXt
single scale |
| 72 |
PANet (ResNeXt-101, multi-scale) |
47.4 |
67.2 |
51.8 |
30.1 |
51.7 |
60.0 |
|
|
Path Aggregation Network for Instance Segmentation |
|
|
2018 |
ResNeXt
multiscale |
| 73 |
HTC (HRNetV2p-W48) |
47.3 |
65.9 |
51.2 |
28.0 |
49.7 |
59.8 |
|
|
Deep High-Resolution Representation Learning for Visual Recognition |
|
|
2019 |
|
| 74 |
HTC (ResNeXt-101-FPN) |
47.1 |
63.9 |
44.7 |
22.8 |
43.9 |
54.6 |
|
|
Hybrid Task Cascade for Instance Segmentation |
|
|
2019 |
ResNeXt
FPN |
| 75 |
CenterNet511 (Hourglass-104, multi-scale) |
47.0 |
64.5 |
50.7 |
28.9 |
49.9 |
58.9 |
|
|
CenterNet: Keypoint Triplets for Object Detection |
|
|
2019 |
multiscale |
| 76 |
MAL (ResNeXt101, multi-scale) |
47.0 |
|
|
|
|
|
|
|
Multiple Anchor Learning for Visual Object Detection |
|
|
2019 |
ResNeXt
multiscale |
| 77 |
ISTR (ResNet50-FPN-3x) |
46.8 |
|
|
|
|
|
|
|
ISTR: End-to-End Instance Segmentation with Transformers |
|
|
2021 |
FPN
ResNet |
| 78 |
RetinaNet (SpineNet-49, 896x896) |
46.7 |
66.3 |
50.6 |
29.1 |
50.1 |
61.7 |
|
|
SpineNet: Learning Scale-Permuted Backbone for Recognition and Localization |
|
|
2019 |
|
| 79 |
RPDet (ResNet-101-DCN, multi-scale) |
46.5 |
67.4 |
50.9 |
30.3 |
49.7 |
57.1 |
|
|
RepPoints: Point Set Representation for Object Detection |
|
|
2019 |
multiscale
DCN
ResNet |
| 80 |
HoughNet (MS) |
46.4 |
65.1 |
50.7 |
29.1 |
48.5 |
58.1 |
|
|
HoughNet: Integrating near and long-range evidence for bottom-up object detection |
|
|
2020 |
multiscale |
| 81 |
PPDet (ResNeXt-101-FPN, multiscale) |
46.3 |
64.8 |
51.6 |
31.4 |
49.9 |
56.4 |
|
|
Reducing Label Noise in Anchor-Free Object Detection |
|
|
2020 |
ResNeXt
multiscale
FPN |
| 82 |
GFLV2 (ResNet-101) |
46.2 |
64.3 |
50.5 |
27.8 |
49.9 |
57 |
|
|
Generalized Focal Loss V2: Learning Reliable Localization Quality Estimation for Dense Object Detection |
|
|
2020 |
ResNet |
| 83 |
SNIPER (ResNet-101) |
46.1 |
67.0 |
51.6 |
29.6 |
48.9 |
58.1 |
|
|
SNIPER: Efficient Multi-Scale Training |
|
|
2018 |
ResNet |
| 84 |
Mask R-CNN (HRNetV2p-W48 + cascade) |
46.1 |
64.0 |
50.3 |
27.1 |
48.6 |
58.3 |
|
|
Deep High-Resolution Representation Learning for Visual Recognition |
|
|
2019 |
|
| 85 |
DCNv2 (ResNet-101, multi-scale) |
46.0 |
67.9 |
50.8 |
27.8 |
49.1 |
59.5 |
|
|
Deformable ConvNets v2: More Deformable, Better Results |
|
|
2018 |
multiscale
DCN
ResNet |
| 86 |
Gaussian-FCOS |
46 |
|
|
|
|
|
|
|
Localization Uncertainty Estimation for Anchor-Free Object Detection |
|
|
2020 |
|
| 87 |
Cascade R-CNN-FPN (ResNet-101, map-guided) |
45.9 |
64.2 |
50 |
26.3 |
49 |
58.6 |
|
|
InstaBoost: Boosting Instance Segmentation via Probability Map Guided Copy-Pasting |
|
|
2019 |
FPN
ResNet |
| 88 |
MAL (ResNeXt101, single-scale) |
45.9 |
|
|
|
|
|
|
|
Multiple Anchor Learning for Visual Object Detection |
|
|
2019 |
ResNeXt
single scale |
| 89 |
CenterMask+VoVNetV2-99 (single-scale) |
45.8 |
64.5 |
|
27.8 |
48.3 |
57.6 |
|
|
CenterMask : Real-Time Anchor-Free Instance Segmentation |
|
|
2019 |
single scale |
| 90 |
D-RFCN + SNIP (DPN-98 with flip, multi-scale) |
45.7 |
67.3 |
51.1 |
29.3 |
48.8 |
57.1 |
|
|
An Analysis of Scale Invariance in Object Detection - SNIP |
|
|
2017 |
multiscale |
| 91 |
YOLOv4 (CD53) |
45.5 |
64.1 |
49.5 |
27 |
49 |
56.7 |
|
|
Scaled-YOLOv4: Scaling Cross Stage Partial Network |
|
|
2020 |
single scale
YOLO |
| 92 |
PP-YOLO (608x608) |
45.2 |
65.2 |
49.9 |
26.3 |
47.8 |
57.2 |
|
|
PP-YOLO: An Effective and Efficient Implementation of Object Detector |
|
|
2020 |
YOLO |
| 93 |
AC-FPN Cascade R-CNN (ResNet-101, single scale) |
45 |
64.4 |
49 |
26.9 |
47.7 |
56.6 |
|
|
Attention-guided Context Feature Pyramid Network for Object Detection |
|
|
2019 |
single scale
FPN
ResNet |
| 94 |
FreeAnchor (ResNeXt-101) |
44.8 |
64.3 |
48.4 |
27 |
47.9 |
56 |
|
|
FreeAnchor: Learning to Match Anchors for Visual Object Detection |
|
|
2019 |
ResNeXt |
| 95 |
FCOS (ResNeXt-64x4d-101-FPN 4 + improvements) |
44.7 |
64.1 |
48.4 |
27.6 |
47.5 |
55.6 |
|
|
FCOS: Fully Convolutional One-Stage Object Detection |
|
|
2019 |
ResNeXt
FPN |
| 96 |
CenterMask+VoVNet2-57 (single-scale) |
44.7 |
63.1 |
48.6 |
27.1 |
|
55.9 |
|
|
CenterMask : Real-Time Anchor-Free Instance Segmentation |
|
|
2019 |
single scale |
| 97 |
FSAF (ResNeXt-101, multi-scale) |
44.6 |
65.2 |
48.6 |
29.7 |
47.1 |
54.6 |
|
|
Feature Selective Anchor-Free Module for Single-Shot Object Detection |
|
|
2019 |
ResNeXt
multiscale |
| 98 |
aLRP Loss (ResNext-101, DCN, 500 scale) |
44.6 |
65.0 |
47.5 |
24.6 |
48.1 |
58.3 |
|
|
A Ranking-based, Balanced Loss Function Unifying Classification and Localisation in Object Detection |
|
|
2020 |
ResNeXt
DCN |
| 99 |
CenterMask + X-101-32x8d (single-scale) |
44.6 |
63.4 |
48.4 |
|
47.2 |
|
|
|
CenterMask : Real-Time Anchor-Free Instance Segmentation |
|
|
2019 |
single scale |
| 100 |
RetinaNet (SpineNet-49, 640x640) |
44.3 |
63.8 |
47.6 |
25.9 |
47.7 |
61.1 |
|
|
SpineNet: Learning Scale-Permuted Backbone for Recognition and Localization |
|
|
2019 |
|
| 101 |
YOLOF-DC5 |
44.3 |
62.9 |
47.5 |
24.0 |
48.5 |
60.4 |
|
|
You Only Look One-level Feature |
|
|
2021 |
YOLO |
| 102 |
GFLV2 (ResNet-50) |
44.3 |
62.3 |
48.5 |
26.8 |
47.7 |
54.1 |
|
|
Generalized Focal Loss V2: Learning Reliable Localization Quality Estimation for Dense Object Detection |
|
|
2020 |
ResNet |
| 103 |
InterNet (ResNet-101-FPN, multi-scale) |
44.2 |
67.5 |
51.1 |
27.2 |
50.3 |
57.7 |
|
|
Feature Intertwiner for Object Detection |
|
|
2019 |
multiscale
FPN
ResNet |
| 104 |
M2Det (VGG-16, multi-scale) |
44.2 |
64.6 |
49.3 |
29.2 |
47.9 |
55.1 |
|
|
M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network |
|
|
2018 |
multiscale |
| 105 |
Faster R-CNN (LIP-ResNet-101-MD w FPN) |
43.9 |
65.7 |
48.1 |
25.4 |
46.7 |
56.3 |
|
|
LIP: Local Importance-based Pooling |
|
|
2019 |
FPN |
| 106 |
M2Det (ResNet-101, multi-scale) |
43.9 |
64.4 |
48 |
29.6 |
49.6 |
54.3 |
|
|
M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network |
|
|
2018 |
multiscale
ResNet |
| 107 |
YOLOv3 @800 + ASFF* (Darknet-53) |
43.9 |
64.1 |
49.2 |
27.0 |
46.6 |
53.4 |
|
|
Learning Spatial Fusion for Single-Shot Object Detection |
|
|
2019 |
YOLO |
| 108 |
FoveaBox (ResNeXt-101) |
43.9 |
63.5 |
47.7 |
26.8 |
46.9 |
55.6 |
|
|
FoveaBox: Beyond Anchor-based Object Detector |
|
|
2019 |
ResNeXt |
| 109 |
ExtremeNet (Hourglass-104, multi-scale) |
43.7 |
60.5 |
47.0 |
24.1 |
46.9 |
57.6 |
|
|
Bottom-up Object Detection by Grouping Extreme and Center Points |
|
|
2019 |
multiscale |
| 110 |
YOLOv4-608 |
43.5 |
65.7 |
47.3 |
26.7 |
46.7 |
53.3 |
|
|
YOLOv4: Optimal Speed and Accuracy of Object Detection |
|
|
2020 |
single scale
YOLO |
| 111 |
SNIPER (ResNet-50) |
43.5 |
65.0 |
48.6 |
26.1 |
46.3 |
56.0 |
|
|
SNIPER: Efficient Multi-Scale Training |
|
|
2018 |
ResNet |
| 112 |
CenterNet (HRNetV2-W48) |
43.5 |
|
46.5 |
22.2 |
|
57.8 |
|
|
Deep High-Resolution Representation Learning for Visual Recognition |
|
|
2019 |
|
| 113 |
D-RFCN + SNIP (ResNet-101, multi-scale) |
43.4 |
65.5 |
48.4 |
27.2 |
46.5 |
54.9 |
|
|
An Analysis of Scale Invariance in Object Detection - SNIP |
|
|
2017 |
multiscale
ResNet |
| 114 |
Grid R-CNN (ResNeXt-101-FPN) |
43.2 |
63.0 |
46.6 |
25.1 |
46.5 |
55.2 |
|
|
Grid R-CNN |
|
|
2018 |
ResNeXt
FPN |
| 115 |
FCOS (ResNeXt-101-64x4d-FPN) |
43.2 |
62.8 |
46.6 |
26.5 |
46.2 |
53.3 |
|
|
FCOS: Fully Convolutional One-Stage Object Detection |
|
|
2019 |
ResNeXt
FPN |
| 116 |
CornerNet-Saccade (Hourglass-104, multi-scale) |
43.2 |
|
|
24.4 |
44.6 |
57.3 |
|
|
CornerNet-Lite: Efficient Keypoint Based Object Detection |
|
|
2019 |
multiscale |
| 117 |
Libra R-CNN (ResNeXt-101-FPN) |
43.0 |
64 |
47 |
25.3 |
45.6 |
54.6 |
|
|
Libra R-CNN: Towards Balanced Learning for Object Detection |
|
|
2019 |
ResNeXt
FPN |
| 118 |
RPDet (ResNet-101-DCN) |
42.8 |
65.0 |
46.3 |
24.9 |
46.2 |
54.7 |
|
|
RepPoints: Point Set Representation for Object Detection |
|
|
2019 |
DCN
ResNet |
| 119 |
SpineNet-49 (640, RetinaNet, single-scale) |
42.8 |
62.3 |
46.1 |
23.7 |
45.2 |
57.3 |
|
|
SpineNet: Learning Scale-Permuted Backbone for Recognition and Localization |
|
|
2019 |
single scale |
| 120 |
Cascade R-CNN (ResNet-101-FPN+, cascade) |
42.8 |
62.1 |
46.3 |
23.7 |
45.5 |
55.2 |
|
|
Cascade R-CNN: Delving into High Quality Object Detection |
|
|
2017 |
FPN
ResNet |
| 121 |
Cascade R-CNN |
42.8 |
62.1 |
46.3 |
23.7 |
45.5 |
55.2 |
|
|
Cascade R-CNN: High Quality Object Detection and Instance Segmentation |
|
|
2019 |
|
| 122 |
TridentNet (ResNet-101) |
42.7 |
63.6 |
46.5 |
23.9 |
46.6 |
56.6 |
|
|
Scale-Aware Trident Networks for Object Detection |
|
|
2019 |
ResNet |
| 123 |
FCOS (ResNeXt-32x8d-101-FPN) |
42.7 |
62.2 |
46.1 |
26.0 |
45.6 |
52.6 |
|
|
FCOS: Fully Convolutional One-Stage Object Detection |
|
|
2019 |
ResNeXt
FPN |
| 124 |
RetinaMask (ResNeXt-101-FPN-GN) |
42.6 |
62.5 |
46.0 |
24.8 |
45.6 |
53.8 |
|
|
RetinaMask: Learning to predict masks improves state-of-the-art single-shot detection for free |
|
|
2019 |
ResNeXt
FPN |
| 125 |
TAL + TAP |
42.5 |
60.3 |
46.4 |
|
|
|
|
|
TOOD: Task-aligned One-stage Object Detection |
|
|
2021 |
|
| 126 |
Faster R-CNN (HRNetV2p-W48) |
42.4 |
63.6 |
46.4 |
24.9 |
44.6 |
53.0 |
|
|
Deep High-Resolution Representation Learning for Visual Recognition |
|
|
2019 |
|
| 127 |
HSD (Rest101, 768x768, single-scale test) |
42.3 |
61.2 |
46.9 |
22.8 |
47.3 |
55.9 |
|
|
Hierarchical Shot Detector |
|
|
2019 |
single scale |
| 128 |
CornerNet511 (Hourglass-104, multi-scale) |
42.1 |
57.8 |
45.3 |
20.8 |
44.8 |
56.7 |
|
|
CornerNet: Detecting Objects as Paired Keypoints |
|
|
2018 |
multiscale |
| 129 |
FoveaBox (ResNeXt-101) |
42.1 |
|
|
|
|
|
|
|
FoveaBox: Beyond Anchor-based Object Detector |
|
|
2019 |
ResNeXt |
| 130 |
FCOS (HRNet-W32-5l) |
42.0 |
60.4 |
45.3 |
25.4 |
45.0 |
51.0 |
|
|
FCOS: Fully Convolutional One-Stage Object Detection |
|
|
2019 |
|
| 131 |
RefineDet512+ (ResNet-101) |
41.8 |
62.9 |
45.7 |
25.6 |
45.1 |
54.1 |
|
|
Single-Shot Refinement Neural Network for Object Detection |
|
|
2017 |
ResNet |
| 132 |
GHM-C + GHM-R (RetinaNet-FPN-ResNeXt-101) |
41.6 |
62.8 |
44.2 |
22.3 |
45.1 |
55.3 |
|
|
Gradient Harmonized Single-stage Detector |
|
|
2018 |
FPN |
| 133 |
CenterNet-DLA (DLA-34, multi-scale) |
41.6 |
|
|
21.5 |
43.9 |
56.0 |
|
|
Objects as Points |
|
|
2019 |
multiscale |
| 134 |
RetinaNet (SpineNet-49S, 640x640) |
41.5 |
60.5 |
44.6 |
23.3 |
45 |
58 |
|
|
SpineNet: Learning Scale-Permuted Backbone for Recognition and Localization |
|
|
2019 |
|
| 135 |
RPDet (ResNet-101) |
41 |
62.9 |
44.3 |
23.6 |
44.1 |
51.7 |
|
|
RepPoints: Point Set Representation for Object Detection |
|
|
2019 |
ResNet |
| 136 |
M2Det (VGG-16, single-scale) |
41.0 |
59.7 |
45 |
22.1 |
46.5 |
53.8 |
|
|
M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network |
|
|
2018 |
single scale |
| 137 |
FSAF (ResNet-101, single-scale) |
40.9 |
61.5 |
44 |
24 |
44.2 |
51.3 |
|
|
Feature Selective Anchor-Free Module for Single-Shot Object Detection |
|
|
2019 |
single scale
ResNet |
| 138 |
RetinaNet (ResNeXt-101-FPN) |
40.8 |
61.1 |
44.1 |
24.1 |
44.2 |
51.2 |
|
|
Focal Loss for Dense Object Detection |
|
|
2017 |
ResNeXt
FPN |
| 139 |
Cascade R-CNN (ResNet-50-FPN+, cascade) |
40.6 |
59.9 |
44 |
22.6 |
42.7 |
52.1 |
|
|
Cascade R-CNN: Delving into High Quality Object Detection |
|
|
2017 |
FPN
ResNet |
| 140 |
Faster R-CNN (Cascade RPN) |
40.6 |
58.9 |
44.5 |
22.0 |
42.8 |
52.6 |
|
|
Cascade RPN: Delving into High-Quality Region Proposal Network with Adaptive Convolution |
|
|
2019 |
|
| 141 |
ResNet-50-DW-DPN (Deformable Kernels) |
40.6 |
|
|
24.6 |
43.9 |
53.3 |
|
|
Deformable Kernels: Adapting Effective Receptive Fields for Object Deformation |
|
|
2019 |
ResNet |
| 142 |
IoU-Net |
40.6 |
|
|
|
|
|
|
|
Acquisition of Localization Confidence for Accurate Object Detection |
|
|
2018 |
|
| 143 |
FCOS (HRNetV2p-W48) |
40.5 |
59.3 |
|
23.4 |
42.6 |
51.0 |
|
|
Deep High-Resolution Representation Learning for Visual Recognition |
|
|
2019 |
|
| 144 |
ResNet-50-FPN Mask R-CNN + KL Loss + var voting + soft-NMS |
40.4 |
|
|
|
|
|
|
|
Bounding Box Regression with Uncertainty for Accurate Object Detection |
|
|
2018 |
FPN
ResNet |
| 145 |
RDSNet (ResNet-101, RetinaNet, mask, MBRM) |
40.3 |
60.1 |
43 |
22.1 |
43.5 |
51.5 |
|
|
RDSNet: A New Deep Architecture for Reciprocal Object Detection and Instance Segmentation |
|
|
2019 |
ResNet |
| 146 |
ExtremeNet (Hourglass-104, single-scale) |
40.2 |
55.5 |
43.2 |
20.4 |
43.2 |
53.1 |
|
|
Bottom-up Object Detection by Grouping Extreme and Center Points |
|
|
2019 |
single scale |
| 147 |
Mask R-CNN (ResNet-101-FPN, CBN) |
40.1 |
60.5 |
44.1 |
35.8 |
57.3 |
38.5 |
|
|
Cross-Iteration Batch Normalization |
|
|
2020 |
FPN
ResNet |
| 148 |
Fast R-CNN (Cascade RPN) |
40.1 |
59.4 |
43.8 |
22.1 |
42.4 |
51.6 |
|
|
Cascade RPN: Delving into High-Quality Region Proposal Network with Adaptive Convolution |
|
|
2019 |
|
| 149 |
Mask R-CNN (ResNeXt-101-FPN) |
39.8 |
62.3 |
43.4 |
22.1 |
43.2 |
51.2 |
|
|
Mask R-CNN |
|
|
2017 |
ResNeXt
FPN |
| 150 |
GA-Faster-RCNN |
39.8 |
59.2 |
43.5 |
21.8 |
42.6 |
50.7 |
|
|
Region Proposal by Guided Anchoring |
|
|
2019 |
|
| 151 |
FPN (ResNet101 backbone) |
39.5 |
|
|
|
|
|
|
|
ChainerCV: a Library for Deep Learning in Computer Vision |
|
|
2017 |
FPN
ResNet |
| 152 |
RetinaMask (ResNet-50-FPN) |
39.4 |
58.6 |
42.3 |
21.9 |
42.0 |
51.0 |
|
|
RetinaMask: Learning to predict masks improves state-of-the-art single-shot detection for free |
|
|
2019 |
FPN
ResNet |
| 153 |
PP-YOLO (320x320) |
39.3 |
59.3 |
42.7 |
16.7 |
41.4 |
57.8 |
|
|
PP-YOLO: An Effective and Efficient Implementation of Object Detector |
|
|
2020 |
YOLO |
| 154 |
AA-ResNet-10 + RetinaNet |
39.2 |
|
|
|
|
|
|
|
Attention Augmented Convolutional Networks |
|
|
2019 |
|
| 155 |
MAL (ResNet50, single-scale) |
39.2 |
|
|
|
|
|
|
|
Multiple Anchor Learning for Visual Object Detection |
|
|
2019 |
single scale
ResNet |
| 156 |
RetinaNet (ResNet-101-FPN) |
39.1 |
59.1 |
42.3 |
21.8 |
42.7 |
50.2 |
|
|
Focal Loss for Dense Object Detection |
|
|
2017 |
FPN
ResNet |
| 157 |
Cascade R-CNN (ResNet-101-FPN+) |
38.8 |
61.1 |
41.9 |
21.3 |
41.8 |
49.8 |
|
|
Cascade R-CNN: Delving into High Quality Object Detection |
|
|
2017 |
FPN
ResNet |
| 158 |
M2Det (ResNet-101, single-scale) |
38.8 |
59.4 |
41.7 |
20.5 |
43.9 |
53.4 |
|
|
M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network |
|
|
2018 |
single scale
ResNet |
| 159 |
SaccadeNet (DLA-34-DCN) |
38.5 |
55.6 |
41.4 |
19.2 |
42.1 |
50.6 |
|
|
SaccadeNet: A Fast and Accurate Object Detector |
|
|
2020 |
DCN |
| 160 |
Mask R-CNN (ResNet-101-FPN) |
38.2 |
60.3 |
41.7 |
20.1 |
41.1 |
50.2 |
|
|
Mask R-CNN |
|
|
2017 |
FPN
ResNet |
| 161 |
WSMA-Seg |
38.1 |
|
|
|
|
|
|
|
Segmentation is All You Need |
|
|
2019 |
|
| 162 |
Faster R-CNN + FPN + CGD |
37.9 |
|
|
|
|
|
|
|
Compact Global Descriptor for Neural Networks |
|
|
2019 |
FPN |
| 163 |
CornerNet511 (Hourglass-52, single-scale) |
37.8 |
53.7 |
40.1 |
17.0 |
39.0 |
50.5 |
|
|
CornerNet: Detecting Objects as Paired Keypoints |
|
|
2018 |
single scale |
| 164 |
RefineDet512+ (VGG-16) |
37.6 |
58.7 |
40.8 |
22.7 |
40.3 |
48.3 |
|
|
Single-Shot Refinement Neural Network for Object Detection |
|
|
2017 |
|
| 165 |
DeformConv-R-FCN (Aligned-Inception-ResNet) |
37.5 |
58.0 |
|
19.4 |
40.1 |
52.5 |
|
|
Deformable Convolutional Networks |
|
|
2017 |
|
| 166 |
Faster R-CNN (ImageNet+300M) |
37.4 |
58 |
40.1 |
17.5 |
41.1 |
51.2 |
|
|
Revisiting Unreasonable Effectiveness of Data in Deep Learning Era |
|
|
2017 |
|
| 167 |
Mask R-CNN (Bottleneck-injected ResNet-50, FPN) |
36.9 |
|
|
|
|
|
|
|
torchdistill: A Modular, Configuration-Driven Framework for Knowledge Distillation |
|
|
2020 |
FPN
!!ResNet |
| 168 |
Faster R-CNN + TDM |
36.8 |
|
|
|
|
|
|
|
Beyond Skip Connections: Top-Down Modulation for Object Detection |
|
|
2016 |
|
| 169 |
Cascade R-CNN (ResNet-50-FPN+) |
36.5 |
59 |
39.2 |
20.3 |
38.8 |
46.4 |
|
|
Cascade R-CNN: Delving into High Quality Object Detection |
|
|
2017 |
FPN;
ResNet |
| 170 |
RefineDet512 (ResNet-101) |
36.4 |
57.5 |
39.5 |
16.6 |
39.9 |
51.4 |
|
|
Single-Shot Refinement Neural Network for Object Detection |
|
|
2017 |
ResNet |
| 171 |
Faster R-CNN + FPN |
36.2 |
|
|
|
|
|
|
|
Feature Pyramid Networks for Object Detection |
|
|
2016 |
FPN |
| 172 |
Faster R-CNN (Bottleneck-injected ResNet-50 and FPN) |
35.9 |
|
|
|
|
|
|
|
torchdistill: A Modular, Configuration-Driven Framework for Knowledge Distillation |
|
|
2020 |
FPN;
ResNet |
| 173 |
Faster R-CNN (box refinement, context, multi-scale testing) |
34.9 |
|
|
|
|
|
|
|
Deep Residual Learning for Image Recognition |
|
|
2015 |
multiscale |
| 174 |
Faster R-CNN |
34.7 |
|
|
|
|
|
|
|
Speed/accuracy trade-offs for modern convolutional object detectors |
|
|
2016 |
|
| 175 |
CornerNet-Squeeze |
34.4 |
|
|
|
|
|
|
|
CornerNet-Lite: Efficient Keypoint Based Object Detection |
|
|
2019 |
|
| 176 |
MultiPath Network |
33.2 |
|
|
|
|
|
|
|
A MultiPath Network for Object Detection |
|
|
2016 |
|
| 177 |
ION |
33.1 |
55.7 |
34.6 |
14.5 |
35.2 |
47.2 |
|
|
Inside-Outside Net: Detecting Objects in Context with Skip Pooling and Recurrent Neural Networks |
|
|
2015 |
|
| 178 |
RefineDet512 (VGG-16) |
33 |
54.5 |
35.5 |
16.3 |
36.3 |
44.3 |
|
|
Single-Shot Refinement Neural Network for Object Detection |
|
|
2017 |
|
| 179 |
YOLOv3 + Darknet-53 |
33.0 |
|
|
|
|
|
|
|
YOLOv3: An Incremental Improvement |
|
|
2018 |
YOLO |
| 180 |
SSD512 |
28.8 |
48.5 |
30.3 |
|
|
|
|
|
SSD: Single Shot MultiBox Detector |
|
|
2015 |
|
| 181 |
MnasFPN (MobileNetV2) |
26.1 |
|
|
|
|
|
|
|
MnasFPN: Learning Latency-aware Pyramid Architecture for Object Detection on Mobile Devices |
|
|
2019 |
FPN |
| 182 |
ESPNetv2-512 |
26.0 |
|
|
|
|
|
|
|
ESPNetv2: A Light-weight, Power Efficient, and General Purpose Convolutional Neural Network |
|
|
2018 |
|
| 183 |
MnasFPN (MobileNetV3) |
25.5 |
|
|
|
|
|
|
|
MnasFPN: Learning Latency-aware Pyramid Architecture for Object Detection on Mobile Devices |
|
|
2019 |
FPN |
| 184 |
MnasFPN (MNASNet-B1) |
24.6 |
|
|
|
|
|
|
|
MnasFPN: Learning Latency-aware Pyramid Architecture for Object Detection on Mobile Devices |
|
|
2019 |
FPN |
| 185 |
MnasFPN x0.7 (MobileNetV2) |
23.8 |
|
|
|
|
|
|
|
MnasFPN: Learning Latency-aware Pyramid Architecture for Object Detection on Mobile Devices |
|
|
2019 |
FPN |
| 186 |
MobielNet-v1-SSD-300x300+CGD |
21.4 |
|
|
|
|
|
|
|
Compact Global Descriptor for Neural Networks |
|
|
2019 |
|
| 187 |
Fast-RCNN |
19.7 |
|
|
|
|
|
|
|
Fast R-CNN |
|
|
2015 |
|
| 188 |
MobileNet |
19.3 |
|
|
|
|
|
|
|
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications |
|
|
2017 |
|
| 189 |
DAT-S (RetinaNet) |
|
69.6 |
51.2 |
32.3 |
51.8 |
63.4 |
47.9 |
|
Vision Transformer with Deformable Attention |
|
|
2022 |
|
| 190 |
CenterMask-VoVNet99 (multi-scale) |
|
68.3 |
53.2 |
32.4 |
|
60.0 |
|
|
CenterMask : Real-Time Anchor-Free Instance Segmentation |
|
|
2019 |
multiscale |
| 191 |
Mask R-CNN (HRNetV2p-W32 + cascade) |
|
62.5 |
48.6 |
|
|
56.3 |
|
|
Deep High-Resolution Representation Learning for Visual Recognition |
|
|
2019 |
|
| 192 |
FoveaBox (ResNeXt-101) |
|
61.9 |
45.2 |
|
46.8 |
|
|
|
FoveaBox: Beyond Anchor-based Object Detector |
|
|
2019 |
ResNeXt |
| 193 |
VirTex Mask R-CNN (ResNet-50-FPN) |
|
61.7 |
44.8 |
|
|
|
|
|
VirTex: Learning Visual Representations from Textual Annotations |
|
|
2020 |
FPN;
ResNet |
| 194 |
Centermask + ResNet101 |
|
61.6 |
46.9 |
|
|
|
|
|
CenterMask : Real-Time Anchor-Free Instance Segmentation |
|
|
2019 |
ResNet |
| 195 |
PAFNet (ResNet50-vd) |
|
59.8 |
45.3 |
22.8 |
45.8 |
59.2 |
|
|
PAFNet: An Efficient Anchor-Free Object Detector Guidance |
|
|
2021 |
ResNet |
| 196 |
IoU-Net+EnergyRegression |
|
58.5 |
41.8 |
|
|
|
|
|
Energy-Based Models for Deep Probabilistic Regression |
|
|
2019 |
|
| 197 |
Cascade R-CNN (HRNetV2p-W48) |
|
|
48.6 |
26.0 |
47.3 |
56.3 |
|
|
Deep High-Resolution Representation Learning for Visual Recognition |
|
|
2019 |
|
| 198 |
ISTR (ResNet50-FPN-3x, single-scale) |
|
|
|
27.8 |
48.7 |
59.9 |
|
|
ISTR: End-to-End Instance Segmentation with Transformers |
|
|
2021 |
|
| 199 |
FoveaBox (ResNeXt-101) |
|
|
|
24.9 |
|
|
|
|
FoveaBox: Beyond Anchor-based Object Detector |
|
|
2019 |
ResNeXt |
| 200 |
EfficientDet-D7x (single-scale) |
|
|
|
|
57.9 |
|
|
|
EfficientDet: Scalable and Efficient Object Detection |
|
|
2019 |
single scale |