clickhouse分布式集群
一.环境准备:
| 主机 | 系统 | 应用 | ip |
|---|---|---|---|
| ckh-01 | centos 8 | jdk,zookeeper,clickhouse | 192.168.205.190 |
| ckh-02 | centos 8 | jdk,zookeeper,clickhouse | 192.168.205.191 |
| ckh-03 | centos 8 | jdk,zookeeper,clickhouse | 192.168.205.192 |
| ckh-04 | centos 8 | jdk,clickhouse | 192.168.205.193 |
| ckh-05 | centos 8 | jdk,clickhouse | 192.168.205.194 |
| ckh-06 | centos 8 | jdk,clickhouse | 192.168.205.195 |
java环境和zookeeper集群安装省略
各节点安装clickhouse
yum -y install yum-utils
rpm --import https://repo.clickhouse.tech/CLICKHOUSE-KEY.GPG yum-config-manager --add-repo https://repo.clickhouse.tech/rpm/stable/x86_64
dnf -y install clickhouse-server clickhouse-client
二.集群配置:(这里用原有配置文件/etc/clickhouse-server/config.xml)使用/etc/metrika.xml配置文件,后面测试配置无法生效
在配置文件/etc/clickhouse-server/config.xml找到
<!-- <listen_host>::</listen_host> -->取消掉注释
<listen_host>::</listen_host>
使用3节点2副本6台服务器配置(以一台为例子,配置完成拷贝至其他节点。然后将副本改成唯一)
在<remote_servers></remote_servers>标签中加入如下配置
<!--<perftest_3shards_1replicas>可以改成自定义名-->
<perftest_3shards_1replicas>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>ckh-01</host>
<port>9000</port>
<user>admin</user>
<password>111111</password>
</replica>
<replica>
<host>ckh-02</host>
<port>9000</port>
<user>admin</user>
<password>111111</password>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>ckh-03</host>
<port>9000</port>
<user>admin</user>
<password>111111</password>
</replica>
<replica>
<host>ckh-04/host>
<port>9000</port>
<user>admin</user>
<password>111111</password>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>ckh-05</host>
<port>9000</port>
<user>admin</user>
<password>111111</password>
</replica>
<replica>
<host>ckh-06</host>
<port>9000</port>
<user>admin</user>
<password>111111</password>
</replica>
</shard>
</perftest_3shards_1replicas>
将如下配置加入到<yandex></yandex>标签中
<!--zookeeper相关配置-->
<zookeeper>
<node>
<host>ckh-01</host>
<port>2181</port>
</node>
<node>
<host>ckh-02</host>
<port>2181</port>
</node>
<node >
<host>ckh-03</host>
<port>2181</port>
</node>
</zookeeper>
<macros>
<shard>01</shard>
<replica>ckh-01-01</replica>
</macros>
<networks>
<ip>::/0</ip>
</networks>
<clickhouse_compression>
<case>
<min_part_size>10000000000</min_part_size>
<min_part_size_ratio>0.01</min_part_size_ratio>
<method>lz4</method>
</case>
</clickhouse_compression>
在<macros></macros>标签中接入对应分片和副本信息,确保每台副本唯一
| 主机名 | 分片 | 副本(主机名+副本编号) |
|---|---|---|
| ckh-01 | 01 | ckh-01-01 |
| ckh-02 | 01 | ckh-02-02 |
| ckh-03 | 02 | ckh-03-01 |
| ckh-04 | 02 | ckh-04-02 |
| ckh-05 | 03 | ckh-05-01 |
| ckh-06 | 03 | ckh-06-02 |
修改以下文件,以便在一个节点上执行语句其他节点也同步执行
vim /etc/clickhouse-server/config.xml
三:用户密码配置
vim /etc/clickhouse-server/users.xml
如果配置密文加密请参照注释说明
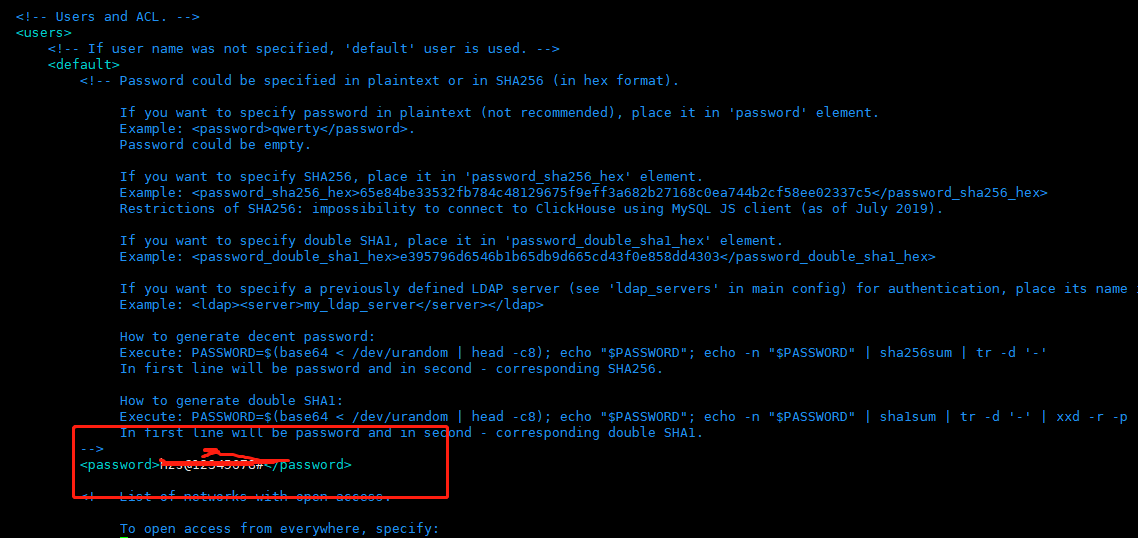
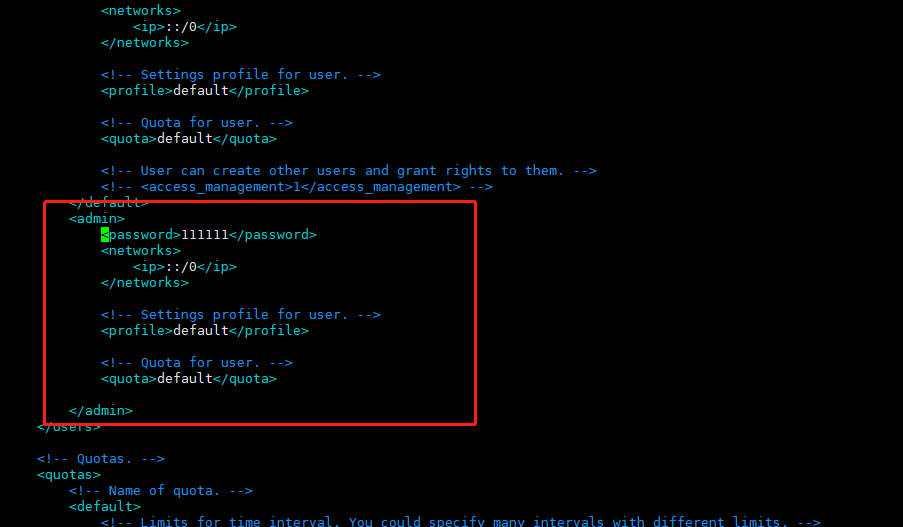
clickhouse 默认用户为default 无密码可以登录,我们可以改成其他用户 或禁用default
在<users></users>标签里添加其他用户配置
<admin>
<password>111111</password>
<networks incl="networks" replace="replace">
<ip>::/0</ip>
</networks>
<!-- Settings profile for user. -->
<profile>default</profile>
<!-- Quota for user. -->
<quota>default</quota>
</admin>
注 <networks incl="networks" replace="replace"> 此处需要加上 incl="networks" replace="replace"
高版本已取消 ,在使用flink运行任务时会出现连接clickhouse超时现象
四.进入clickhouse-client:(注意如果需要外部访问需要将vim /etc/clickhouse-server/config.xml配置文件listen_host改成如下设置)

各节点启动服务:
systemctl start clickhouse-server
然后连接通过以下命令连接(-m为多行命令操作)
clickhouse-client -h 192.168.205.190 --port 9000 -m -u admin --password 111111

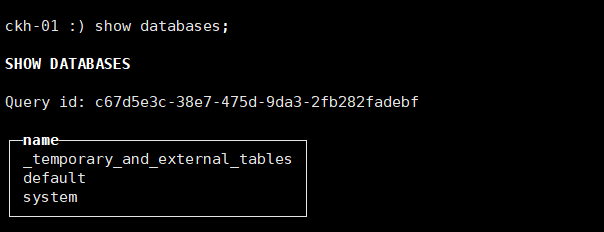
查看数据库信息:
show databases;
五.查看集群信息(任意一节点均可查看):
select * from system.clusters;

-------------------------------------------------------------------------------------------------------------------------------------
创建本地表及分布式表:
在各个节点分表创建数据库test(在一个节点执行即可)
create database test ON CLUSTER perftest_3shards_1replicas;
下面给出ReplicatedMergeTree引擎的完整建表DDL语句。
创建本地表及表引擎
Replicated Table & ReplicatedMergeTree Engines
CREATE TABLE IF NOT EXISTS test.events_local ON CLUSTER perftest_3shards_1replicas ( ts_date Date, ts_date_time DateTime, user_id Int64, event_type String, site_id Int64, groupon_id Int64, category_id Int64, merchandise_id Int64, search_text String ) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/test/events_local','{replica}') PARTITION BY ts_date ORDER BY (ts_date,toStartOfHour(ts_date_time),site_id,event_type) SETTINGS index_granularity = 8192;
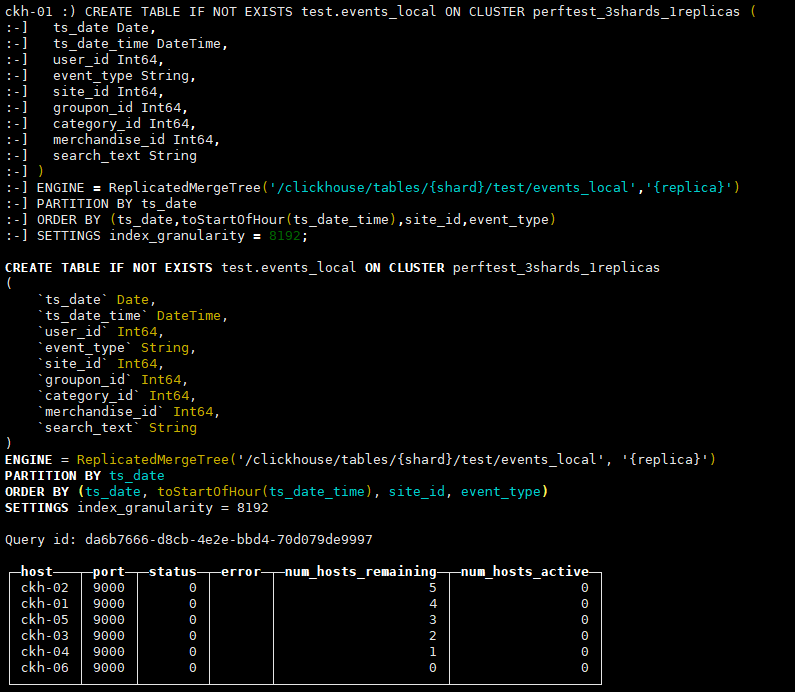
其中,ON CLUSTER语法表示分布式DDL,即执行一次就可在集群所有实例上创建同样的本地表。集群标识符{cluster}、分片标识符{shard}和副本标识符{replica}来自之前提到过的复制表宏配置,即config.xml中<macros>一节的内容,配合ON CLUSTER语法一同使用,可以避免建表时在每个实例上反复修改这些值。
分布式表及分布式表引擎
Distributed Table & Distributed Engine
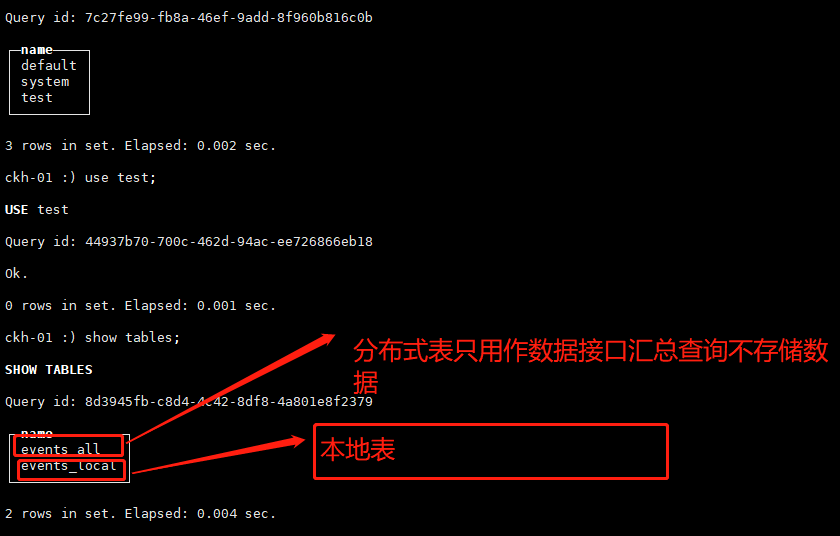
ClickHouse分布式表的本质并不是一张表,而是一些本地物理表(分片)的分布式视图,本身并不存储数据。
支持分布式表的引擎是Distributed,建表DDL语句示例如下,_all只是分布式表名比较通用的后缀而已。
CREATE TABLE IF NOT EXISTS test.events_all ON CLUSTER perftest_3shards_1replicas AS test.events_local ENGINE = Distributed(perftest_3shards_1replicas,test,events_local,rand());

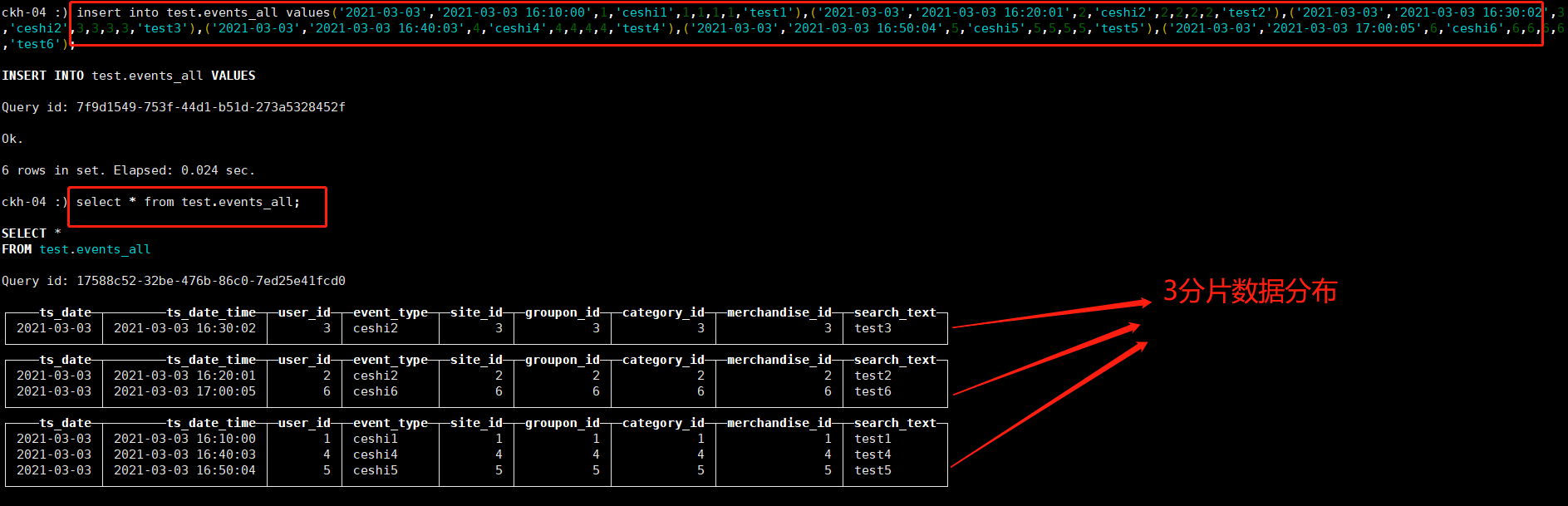
任意节点插入数据:
insert into test.events_all values('2021-03-03','2021-03-03 16:10:00',1,'ceshi1',1,1,1,1,'test1'),('2021-03-03','2021-03-03 16:20:01',2,'ceshi2',2,2,2,2,'test2'),('2021-03-03','2021-03-03 16:30:02',3,'ceshi2',3,3,3,3,'test3'),('2021-03-03','2021-03-03 16:40:03',4,'ceshi4',4,4,4,4,'test4'),('2021-03-03','2021-03-03 16:50:04',5,'ceshi5',5,5,5,5,'test5'),('2021-03-03','2021-03-03 17:00:05',6,'ceshi6',6,6,6,6,'test6');
查询各分片数据:
select * from test.events_all;
查看副本节点也复制了一份同样的数据
-------------------------------------------------------------------------------------
clickhouse基本操作:
查询clickhouse集群信息
select * from system.clusters;
创建数据库命令(一个节点上执行,多个节点同时创建)
create database test ON CLUSTER perftest_3shards_1replicas
删除数据库命令(一个节点上执行,多个节点同时删除)
drop database test ON CLUSTER perftest_3shards_1replicas
删除本地表数据(分布式表无法删除表数据)
alter table test.events_local ON CLUSTER perftest_3shards_1replicas delete where 1=1;
1=1表示删除所有数据,可以接字段名删除满足某个条件的数据
查看zookeeper下目录
select * from system.zookeeper WHERE path='/'

clickhouse分布式集群的更多相关文章
- Hadoop伪分布式集群环境搭建
本教程讲述在单机环境下搭建Hadoop伪分布式集群环境,帮助初学者方便学习Hadoop相关知识. 首先安装Hadoop之前需要准备安装环境. 安装Centos6.5(64位).(操作系统再次不做过多描 ...
- ElasticSearch 5学习(7)——分布式集群学习分享2
前面主要学习了ElasticSearch分布式集群的存储过程中集群.节点和分片的知识(ElasticSearch 5学习(6)--分布式集群学习分享1),下面主要分享应对故障的一些实践. 应对故障 前 ...
- ElasticSearch 5学习(6)——分布式集群学习分享1
在使用中我们把文档存入ElasticSearch,但是如果能够了解ElasticSearch内部是如何存储的,将会对我们学习ElasticSearch有很清晰的认识.本文中的所使用的ElasticSe ...
- Redis分布式集群几点说道
原文地址:http://www.cnblogs.com/verrion/p/redis_structure_type_selection.html Redis分布式集群几点说道 Redis数据量日益 ...
- Hadoop学习笔记—13.分布式集群中节点的动态添加与下架
开篇:在本笔记系列的第一篇中,我们介绍了如何搭建伪分布与分布模式的Hadoop集群.现在,我们来了解一下在一个Hadoop分布式集群中,如何动态(不关机且正在运行的情况下)地添加一个Hadoop节点与 ...
- 安装ClouderaManager以及使用ClouderaManager安装分布式集群的若干细节
目录 前言 整体介绍 分步安装介绍 总结 一.前言 周末干了近四十个小时中间只休息了五个小时终于成功安装了ClouderaManager以及分布式集群,其中各种辛酸无以言表,唯有泪两行. ...
- Zookeeper分布式集群搭建
实验条件:3台安装linux的机子,配置好Java环境. 步骤1:下载并分别解包到每台机子的/home/iHge2k目录下,附上下载地址:http://mirrors.cnnic.cn/apache/ ...
- 分布式集群搭建(hadoop2.6.0+CentOS6.5)
摘要:之前安装过hadoop1.2.1集群,发现比较老了,后来安装cloudera(hadoop2.6.0),发现集成度比较高,想知道原生的hadoop什么样子,于是着手搭建一个伪分布式集群(三台), ...
- MySQL分布式集群之MyCAT(转)
原文地址:http://blog.itpub.net/29510932/viewspace-1664499/ 隔了好久,才想起来更新博客,最近倒腾的数据库从Oracle换成了MySQL,研究了一段时间 ...
随机推荐
- Wide-Bandgap宽禁带(WBG)器件(如GaN和SiC)市场将何去何从?
Wide-Bandgap宽禁带(WBG)器件(如GaN和SiC)市场将何去何从? Where Is the Wide-Bandgap Market Going? 电力电子在采用宽禁带(WBG)器件(如 ...
- C语言编译器开发之旅(二):解析器
本节是我们这个编译器系列的第二节,进入语法分析与语义分析的部分解.在本节我们会编写一个简单的解析器. 解析器的主要功能分为两个部分: 识别输入的语法元素生成AST(Abstract Syntax Tr ...
- 【C++】解决c++中cout输出中文乱码问题
问题:cout输出中文乱码.例如下面的代码输出会乱码. cout << "成功!" << endl; 输出结果: 解决方案: 控制台还原旧版即可,打开程序- ...
- 强烈推荐!15 个Github 顶级Java教程类开源项目
大家好,我是 Guide 哥!今天给大家推荐 15 个新手也能看懂的 Java 教程方向的开源项目.这些项目无论是对于你学习 Java 还是准备 Java 方向的面试都非常有帮助. 正如我第一个要推荐 ...
- C#《大话设计模式》之模板方法模式学习笔记
static void Main(string[] args) { Console.WriteLine("学生甲抄的试卷:"); TestPaper A = new TestPap ...
- 安聊服务端Netty的应用
Netty简介 Netty是一个面向网络编程的Java基础框架,它基于异步的事件驱动,并且内置多种网络协议的支持,可以快速地开发可维护的高性能的面向协议的服务器和客户端. 安聊简介 安聊是一个即时聊天 ...
- 从ReentrantLock看AQS (AbstractQueuedSynchronizer) 运行流程
从ReentrantLock看AQS (AbstractQueuedSynchronizer) 运行流程 概述 本文将以ReentrantLock为例来讲解AbstractQueuedSynchron ...
- Pycharm破解版_安装从失败到成功
前言: 入门学习的时候一直用的是社区版的,现在想换个专业版的玩玩. 本文使用的环境说明: win10系统 安装过pycharm社区版,已卸载 已安装python 3.8.5 (建议看完整篇文章后再自行 ...
- 温故知新,.Net Core遇见Digital Signature(MD5/RSA/SM),微服务签名机制设计
什么是数字签名(Digital Signature) 数字签名(Digital Signature)是只有信息的发送者才能产生的别人无法伪造的一段数字串,这段数字串同时也是对信息的发送者发送信息真实性 ...
- Gitlab触发jenkins并获取项目post参数
jenkins -- Generic Webhook Trigger插件 此插件是git webhook的高阶应用,安装后会暴露出来一个公共API,GWT插件接收到 JSON 或 XML 的 HTTP ...