unittest+ddt_实现数据驱动测试(7)
我们设计测试用例时,会出现测试步骤一样,只是其中的测试数据有变化的情况,比如测试登录时的账号密码。这个时候,如果我们依然使用一条case一个方法的话,会出现大量的代码冗余,而且效率也会大大降低。此时,ddt模块就能帮助我们解决这个问题。
ddt(data-driven test),顾名思义,数据驱动测试。这个模块是第三方库,需要我们自己下载。或者直接在命令行输入pip install ddt。
ddt用法
先看一个简单的演示:
import unittest
import ddt @ddt.ddt # 解析Demo中使用了ddt装饰器的方法
class Demo(unittest.TestCase): @ddt.data(1, 2) # 迭代的参数值
def test_case_1(self, v): # 迭代的参数个数需要与方法中的形参个数一致
print(f"v:{v}") @ddt.data((1, 2), [3, 4]) # 迭代的参数值类型可以为元组或列表
@ddt.unpack # 当迭代的参数为多维数组时,需要使用该装饰器来解析参数
def test_case_2(self, v1, v2):
print(f"v1:{v1} v2:{v2}") @ddt.data({"v3": 1, "v4": 2}, {"v3": 3, "v4": 4}) # 迭代的参数值类型可以为字典,字典的key值需要与形参的名称一致
@ddt.unpack
def test_case_3(self, v3, v4):
print(f"v3:{v3} v4:{v4}") if __name__ == '__main__':
unittest.main()
演示结果:
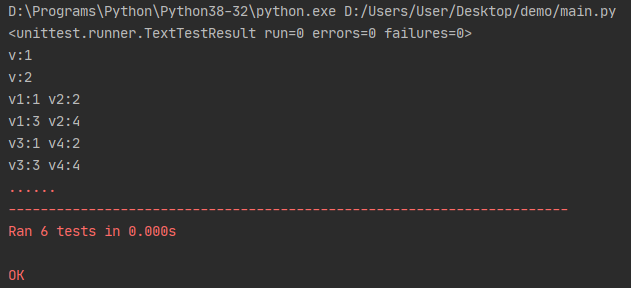
ddt缺陷
按照上面的方法将ddt运用到实际项目中,就能实现数据驱动的功能了。但是,用dir(Demo)查看类的属性时,发现找不到 test_case_1,*2,*3的方法名称,而是出现下图类似的名称。

这是因为ddt为了防止方法名冲突,自动修改了方法名称。名称改变后,表面看起来也没影响用例的执行,这是因为我们使用的是自动搜索用例的方法执行的用例,如果使用addTest这种指定用例的方法就会报错:ValueError: no such test method in <class '__main__.Demo'>: test_case_1
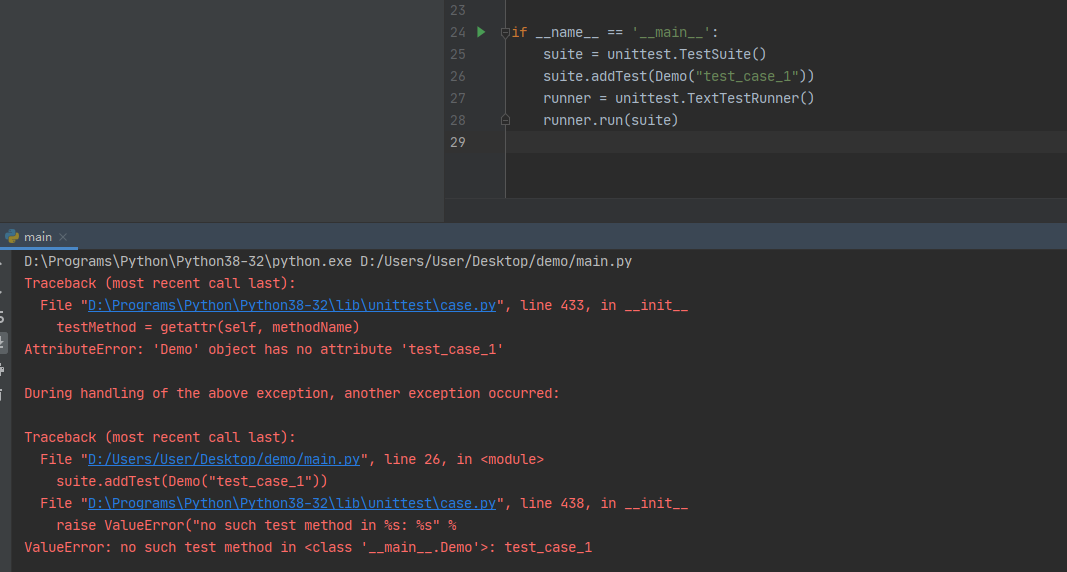
如果我们不实用指定用例的方法那是不是就没有问题了呢?执行上确实没问题,但如果我们使用了自动生成报告的模块(比如:BeautifulReport),生成的报告中,用例名称显示的是修改后的名称。

修复ddt缺陷
添加指定用例的方法看起来是无解的,因为使用数据驱动迭代的过程中,ddt必然会修改被装饰方法的方法名称,那怎么办呢?既然是ddt在解析用例过程中修改的方法名称,那么我们在解析过程中自定义用例名。
综合考虑各数据类型的特性后,决定不修改ddt对元组和列表类型数据的处理方式,只在字典类型的数据中添加指定用例名称的方法。
通读ddt源码,发现ddt是在 mk_test_name() 函数中定义的用例名称,具体代码如下:
def mk_test_name(name, value, index=0, name_fmt=TestNameFormat.DEFAULT):
# Add zeros before index to keep order
index = "{0:0{1}}".format(index + 1, index_len) if name_fmt is TestNameFormat.INDEX_ONLY or not is_trivial(value):
return "{0}_{1}".format(name, index)
try:
value = str(value)
except UnicodeEncodeError:
# fallback for python2
value = value.encode('ascii', 'backslashreplace')
test_name = "{0}_{1}_{2}".format(name, index, value)
return re.sub(r'\W|^(?=\d)', '_', test_name)
我们只要在这部分代码中增加对字典类型的数据处理即可,增加蓝色区域代码如下:
def mk_test_name(name, value, index=0, name_fmt=TestNameFormat.DEFAULT):
# Add zeros before index to keep order
index = "{0:0{1}}".format(index + 1, index_len)
if name_fmt is TestNameFormat.INDEX_ONLY or not is_trivial(value):
if isinstance(value, dict):
test_name = value.get("case_name")
if test_name is not None:
return test_name
return "{0}_{1}".format(name, index)
try:
value = str(value)
except UnicodeEncodeError:
# fallback for python2
value = value.encode('ascii', 'backslashreplace')
test_name = "{0}_{1}_{2}".format(name, index, value)
return re.sub(r'\W|^(?=\d)', '_', test_name)
修改代码后,自定义用例名称的用法是在数据中定义case_name的key,值就为用例名称。
代码演示如下:
import unittest
import ddt @ddt.ddt # 解析Demo中使用了ddt装饰器的方法
class Demo(unittest.TestCase): @ddt.data(1, 2) # 迭代的参数值
def test_case_1(self, v): # 迭代的参数个数需要与方法中的形参个数一致
print(f"v:{v}") @ddt.data((1, 2), [3, 4]) # 迭代的参数值类型可以为元组或列表
@ddt.unpack # 当迭代的参数为多维数组时,需要使用该装饰器来解析参数
def test_case_2(self, v1, v2):
print(f"v1:{v1} v2:{v2}") @ddt.data({"v3": 1, "v4": 2, "case_name": "test_normal"}, {"v3": 3, "v4": 4, "case_name": "test_error"}) # 在数据中定义case_name的key,值就为用例名称
@ddt.unpack
def test_case_3(self, v3, v4, case_name):
print(f"v3:{v3} v4:{v4}")
执行结果如下
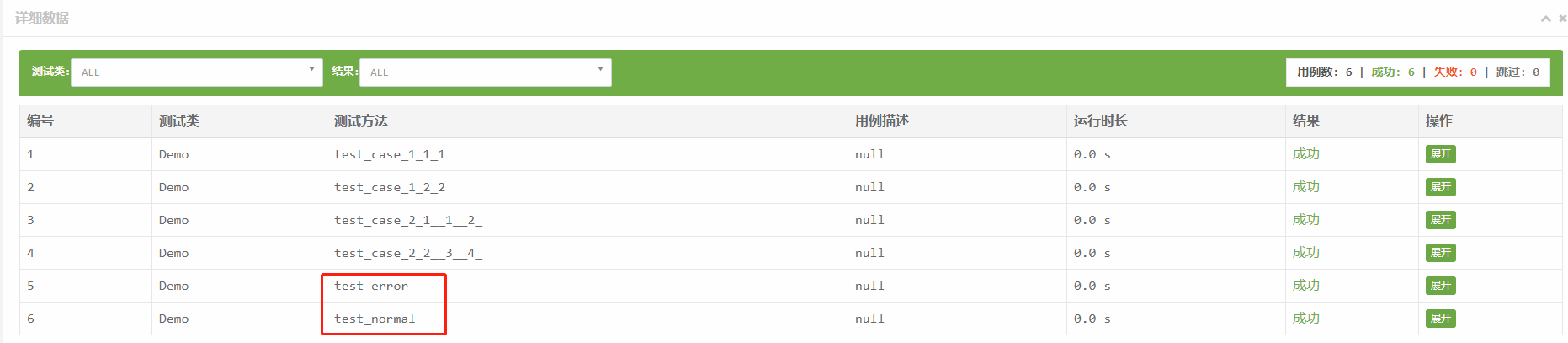
需要注意两点:
- 自定义的用例名称不能相同,虽然不会报错,但是只会执行一个用例。
- 自定义的用例名称也必须是test开头。
使用这种方法,也能解决addTest添加不了用例的问题,有兴趣自己可以试试,就不在演示了。
ddt的数据可在用例描述中参数化显示
ddt对用例描述使用format方法进行了初始化
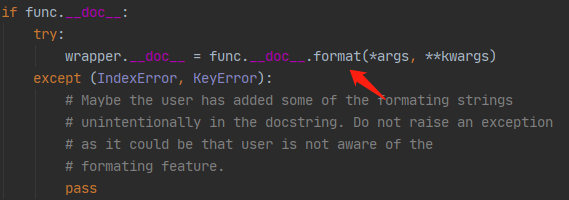
因此在用例描述中,增加参数值的显示
@ddt.ddt # 解析Demo中使用了ddt装饰器的方法
class Demo(unittest.TestCase): @ddt.data({"v3": 1, "v4": 2, "case_name": "test_normal"}, {"v3": 3, "v4": 4, "case_name": "test_error"}) # 在数据中定义case_name的key,值就为用例名称
@ddt.unpack
def test_case(self, v3, v4, case_name):
"""参数值为v3:{v3},v4:{v4}"""
print(f"v3:{v3} v4:{v4}")
执行结果

unittest+ddt_实现数据驱动测试(7)的更多相关文章
- Python3|ddt|unittest|浅议数据驱动测试
目录 1.DDT简介 2.data装饰器 3.unpack装饰器 4.file_data装饰器 5.总结 1.DDT简介 Data-Driven Tests(DDT)即数据驱动测试.它允许您通过不同的 ...
- python Unittest+excel+ddt数据驱动测试
#!user/bin/env python # coding=utf- # @Author : Dang # @Time : // : # @Email : @qq.com # @File : # @ ...
- 如何快速掌握DDT数据驱动测试?
1.前言 (网盗概念^-^)相同的测试脚本使用不同的测试数据来执行,测试数据和测试行为完全分离, 这样的测试脚本设计模式称为数据驱动.(网盗结束)当我们测试某个网站的登录功能时,我们往往会使用不同的用 ...
- Python Selenium 之数据驱动测试
数据驱动模式的测试好处相比普通模式的测试就显而易见了吧!使用数据驱动的模式,可以根据业务分解测试数据,只需定义变量,使用外部或者自定义的数据使其参数化,从而避免了使用之前测试脚本中固定的数据.可以将测 ...
- Python+Selenium笔记(十二):数据驱动测试
(一) 前言 通过使用数据驱动测试,实现对输入值和预期结果的参数化.(例如:输入数据和预期结果可以直接读取Excel文档的数据) (二) ddt 使用ddt执行数据驱动测试,ddt库可以将测试 ...
- python - 数据驱动测试 - ddt
# -*- coding:utf-8 -*- ''' @project: jiaxy @author: Jimmy @file: study_ddt.py @ide: PyCharm Communit ...
- Python Selenium 之数据驱动测试的实现
数据驱动模式的测试好处相比普通模式的测试就显而易见了吧!使用数据驱动的模式,可以根据业务分解测试数据,只需定义变量,使用外部或者自定义的数据使其参数化,从而避免了使用之前测试脚本中固定的数据.可以将测 ...
- 【python接口自动化】- DDT数据驱动测试
简单介绍 DDT(Date Driver Test),所谓数据驱动测试,简单来说就是由数据的改变从而驱动自动化测试的执行,最终引起测试结果的改变.通过使用数据驱动测试的方法,可以在需要验证多组数据 ...
- 【python】以souhu邮箱为例学习DDT数据驱动测试
前言 DDT(Data-Driven Tests)是针对 unittest 单元测试框架设计的扩展库.允许使用不同的测试数据来运行一个测试用例,并将其展示为多个测试用例.通俗理解为相同的测试脚本使用不 ...
随机推荐
- 【Spring Framework】Spring注解设置Bean的初始化、销毁方法的方式
bean的生命周期:创建---初始化---销毁. Spring中声明的Bean的初始化和销毁方法有3种方式: @Bean的注解的initMethod.DestroyMethod属性 bean实现Ini ...
- Spring Boot的异步任务、定时任务和邮件任务
一.异步任务 1.启动类添加注解@EnableAsync,开启异步任务注解功能: 2.需要异步执行的方法上添加@Async注解. 二.定时任务 1.启动类添加注解@EnableScheduling,开 ...
- vue 项目如何使用animate.css
Animate.css是一款酷炫丰富的跨浏览器动画库,它在GitHub上的star数至今已有5.3万+. 在vue项目中我们可以借助于animate.css,用十分简单的代码来实现一个个炫酷的效果!( ...
- MySQL增删改查的常用语句汇总
MySQL增删改查的常用语句汇总 以下是总结的mysql的常用语句,欢迎指正和补充~ 一.创建库,删除库,使用库 1.创建数据库:create database 库名; 2.删除数据库:drop da ...
- 【LeetCode】1466. 重新规划路线 Reorder Routes to Make All Paths Lead to the City Zero (Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客:http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 DFS BFS 日期 题目地址:https://lee ...
- 【LeetCode】520. Detect Capital 解题报告(Java & Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 循环判断三个条件 大写字母个数和位置判断 根据首字符 ...
- 【LeetCode】939. Minimum Area Rectangle 解题报告(Python & C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 确定对角线,找另外两点(4sum) 字典保存出现的x ...
- 【LeetCode】859. Buddy Strings 解题报告(Python & C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 字典 日期 题目地址:https://leetcod ...
- 【LeetCode】684. Redundant Connection 解题报告(Python & C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 并查集 日期 题目地址:https://leetco ...
- mac学习Python第二天:开发工具安装、编程方式、中文编码、syntaxError语法错误、注释、语法格式
一.python集成开发工具Visual Studio Code安装配置 1.官网下载安装VSCode 官网地址 https://code.visualstudio.com/下载软件包 VSCode ...