RobotFramework + Python 自动化入门 三 (Web自动化)
在《RobotFramwork + Python 自动化入门 一》中,完成了一个Robot环境搭建及测试脚本的创建和执行。
在《RobotFramwork + Python 自动化入门 二》中,对RobotFramework的关键字使用和查看源码进行了介绍。
本节,介绍基于Web的RF自动化。
一、环境配置
1. 下载浏览器驱动程序
执行web端的测试脚本时,需要浏览器驱动,不同浏览器对应不同的驱动程序。
浏览器的驱动版本 要和 浏览器版本号对应或适配。
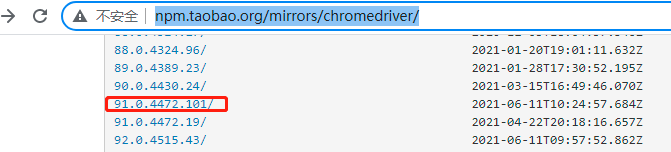
Chrome driver下载地址:http://npm.taobao.org/mirrors/chromedriver/
或百度搜索其他下载方式。
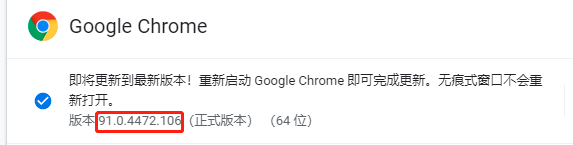
我的Chrome版本号为91.0.4472.106, 故下载最接近的chromedriver。
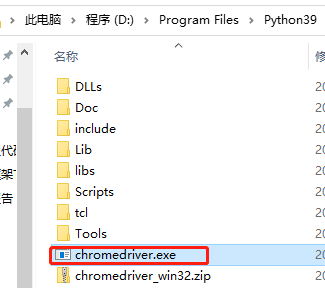
下载完成后放入Python安装目录(或者其他文件夹,但该文件夹要加入path路径)。
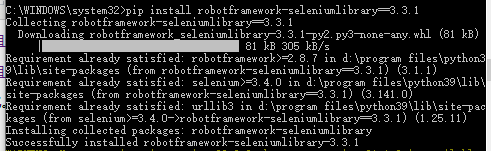
2.安装selenium库
安装命令(安装最新版): pip install robotframework-seleniumlibrary
指定版本号安装:pip install robotframework-seleniumlibrary==3.3.1
3. 添加依赖库
在RF项目中添加selenium library。
方法一:
双击打开red.xml文件,点击+按钮添加library。
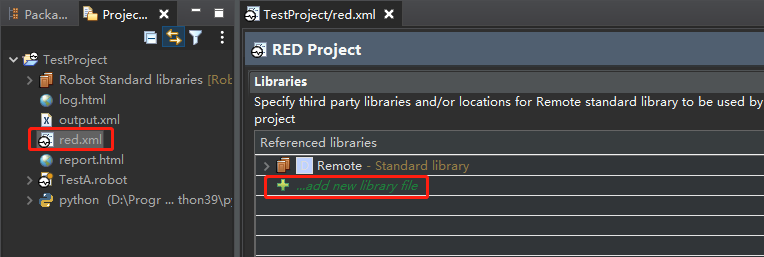
选择Python安装目录下的 \Lib\site-packages\SeleniumLibrary 文件夹中的__init__.py文件。
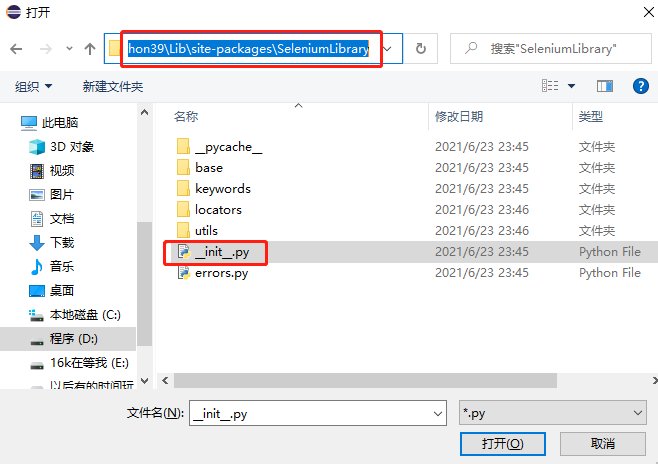
选择第一个SeleniumLibrary,点击OK。
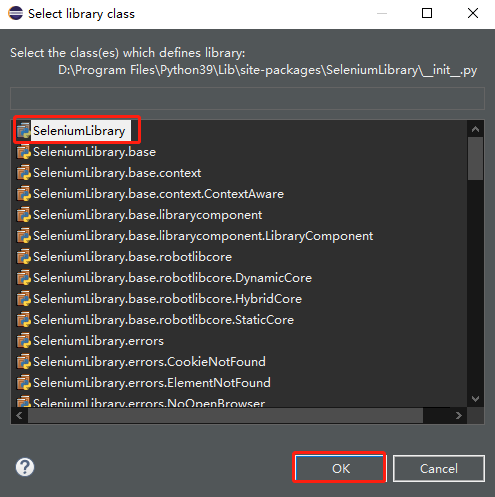
SeleniumLibrary添加成功。

点击保存按钮或 CTRL+S 快捷键。
Project目录下多了一个Robot Referenced libraries目录,SeleniumLibrary是其子目录,所有添加的第三方依赖都在这个目录下。
方法二:
右键 red.xml文件,点击Open With>Text Editor,以文本格式打开red.xml文件。

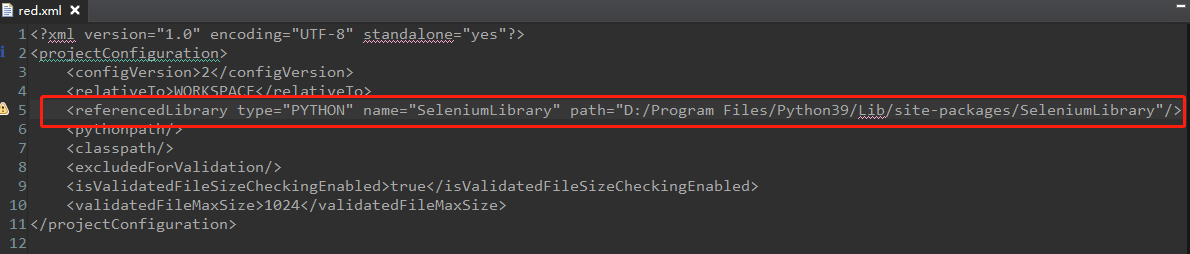
在red.xml文件中添加下方内容,保存:
<referencedLibrary type="PYTHON" name="SeleniumLibrary" path="D:/Program Files/Python39/Lib/site-packages/SeleniumLibrary"/>
4. 编码格式设置
在写中文环境的测试脚本时,经常会用到中文,故要设置编码格式为UTF-8。
如果不设置,当脚本中存在中文,执行脚本(robot文件)会报错。
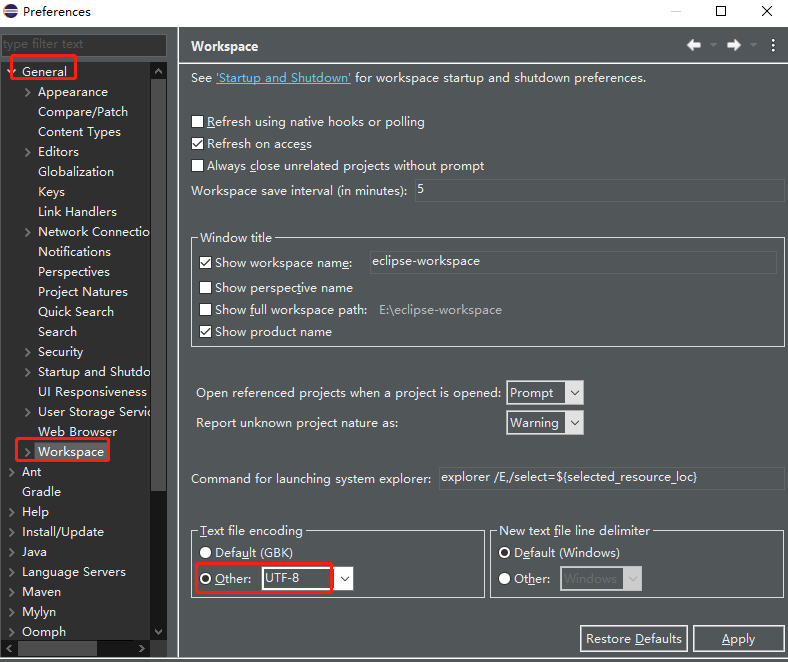
而且若只设置了单个项目的编码格式为UTF-8,在console界面会发现中文字符仍显示为乱码,故要设置整个workspace的编码格式。
设置方法:
菜单栏Window > Preferences > General > Workspace。
二、设计测试脚本
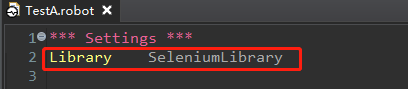
1. 引入SeleniumLibrary
当使用第三方库时,必须在文件中使用Library关键字 引入相应的库名。
2. 设计测试脚本
测试脚本流程如下:
1.打开谷歌浏览器,进入百度页面
2.搜索框中输入selenium
3.点击搜索按钮
4.页面搜索结果标题应包含selenium
5.关闭浏览器
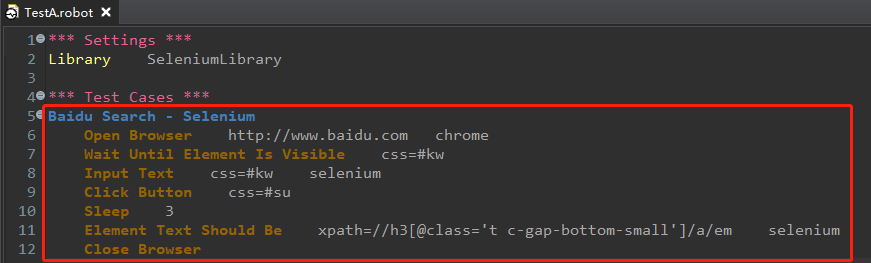
测试脚本:
Baidu Search - Selenium
Open Browser http://www.baidu.com chrome # chrome表示启动谷歌浏览器
Wait Until Element Is Visible css=#kw # css=#kw是搜索框的locator,css表示locator使用的是css定位方式
Input Text css=#kw selenium # css=#kw是输入框的locator
Click Button css=#su
Sleep 3
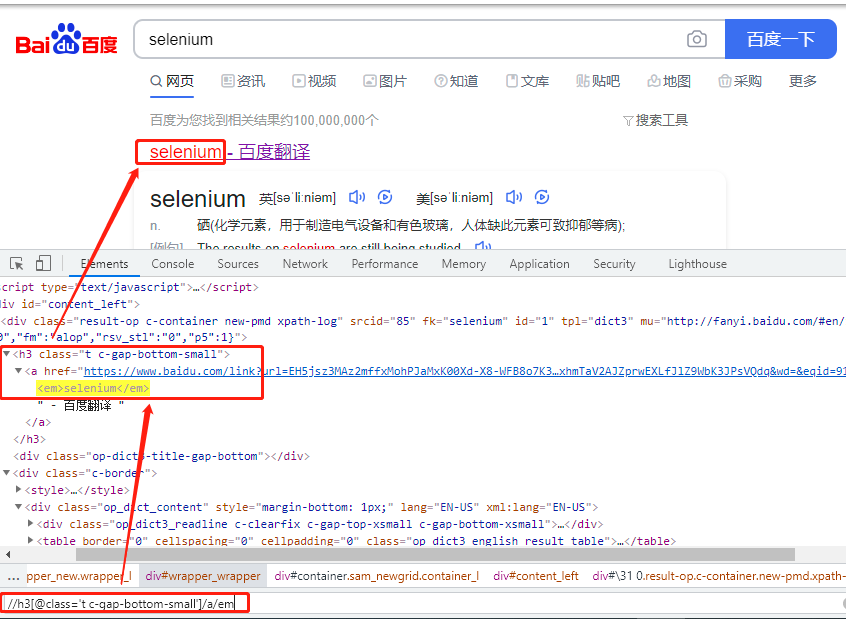
Element Text Should Be xpath=//h3[@class='t c-gap-bottom-small']/a/em selenium #xpath=//h3[@class='t c-gap-bottom-small']/a/em 是xpath格式的locator
Close Browser
Locator " xpath=//h3[@class='t c-gap-bottom-small']/a/em" 的含义如下:
3. 执行脚本
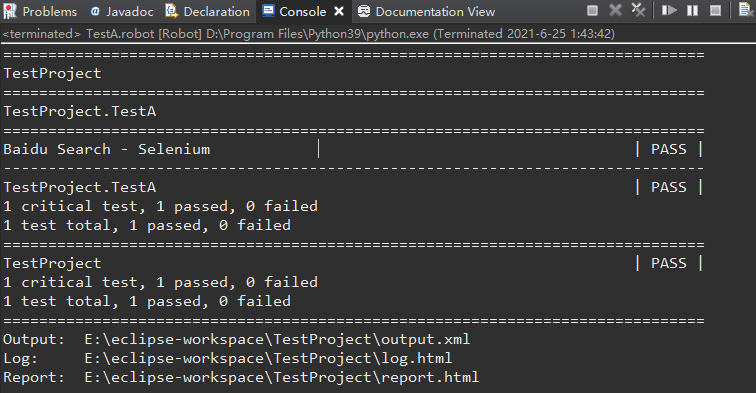
选择脚本文件,右键执行,或者直接点击工具栏”执行‘按钮。

执行结果如下:
RobotFramework + Python 自动化入门 三 (Web自动化)的更多相关文章
- 3.Python爬虫入门三之Urllib和Urllib2库的基本使用
1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解释才呈现出来的,实质它是一段HTML代码,加 JS.CSS ...
- 转 Python爬虫入门三之Urllib库的基本使用
静觅 » Python爬虫入门三之Urllib库的基本使用 1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器 ...
- python爬虫入门三:requests库
urllib库在很多时候都比较繁琐,比如处理Cookies.因此,我们选择学习另一个更为简单易用的HTTP库:Requests. requests官方文档 1. 什么是Requests Request ...
- Python爬虫入门三之Urllib库的基本使用
转自http://cuiqingcai.com/947.html 1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由 ...
- RobotFramework + Python 自动化入门 四 (Web进阶)
在<RobotFramwork + Python 自动化入门 一>中,完成了一个Robot环境搭建及测试脚本的创建和执行. 在<RobotFramwork + Python 自动化入 ...
- Python爬虫入门之Urllib库的基本使用
那么接下来,小伙伴们就一起和我真正迈向我们的爬虫之路吧. 1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解 ...
- RobotFramework自动化测试框架-Selenium Web自动化(三)关于在RobotFramework中如何使用Selenium很全的总结(下)
本文紧接着RobotFramework自动化测试框架-Selenium Web自动化(二)关于在RobotFramework中如何使用Selenium很全的总结(上)继续分享RobotFramewor ...
- RobotFramework + Python 自动化入门 二 (关键字)
在<RobotFramwork + Python 自动化入门 一>中,完成了Robot环境搭建及测试脚本的创建和执行. 本节,对RobotFramework的关键字使用和查看源码进行介绍. ...
- RobotFramework自动化测试框架-Selenium Web自动化(二)关于在RobotFramework中如何使用Selenium很全的总结(上)
好久没有继续分享关于自动化测试相关的东西了,自动化在现今的测试领域已经越来越重要了,大部分公司在测试岗位招聘中都需要会相关的自动化测试知识.而 RobotFramework自动化测试框架 是自动化测试 ...
随机推荐
- WTM Blazor,Blazor开发利器
Blazor从诞生到现在也有一段时间了,之前一直在观望,从dotnet5中Blazor的进步以及即将到来的dotnet6中的规划来看,Blazor的前途还是光明的,所以WtmBlazor来了! Bla ...
- 事后分析$\alpha$
项目 内容 课程:北航-2020-春-软件工程 博客园班级博客 要求 事后分析 我们在这个课程的目标是 提升团队管理及合作能力,开发一项满意的工程项目 这个作业在哪个具体方面帮助我们实现目标 组织组员 ...
- mybaties longtext 类型不能映射到自动生成的文件
假设数据库里有 fun_detail 这样一个字段. 使用 MyBatis Generator 生成的 XXExample 文件,发现没有 fun_detail 这个字段. 需要加一行: <co ...
- 数据流分析软件SQLFlow的高阶模式Job任务介绍
SQLFlow是一个可视化的在线处理SQL对象依赖关系的工具,只需要上传你的SQL脚本,它可以自动分析SQL里的数据对象,包括database.schema.table.view.column.pro ...
- [bug] MySQL 无法删除表
参考 https://blog.csdn.net/smbluesky/article/details/82427121
- mysql 无法执行select查询
场景:mysql无法执行select命令查询,对于已存在的数据库,除了mysql.information_schema数据库,其它诸如nova.keystone.cinder等数据库都有此现象. 日志 ...
- 057.Python前端Django模型ORM多表查询
一 基于对象的查询 1.1 一对多查询 设计路由 from django.contrib import admin from django.urls import path from app01 im ...
- Linux进阶之Jenkins持续集成介绍及安装演示
一.Jenkins介绍 Jenkins是一个开源软件项目,是基于Java开发的一种持续集成工具,用于监控持续重复的工作,旨在提供一个开放易用的软件平台,使软件的持续集成变成可能. Jenkins功能包 ...
- 启动kafaka失败了,提示zk保存kafka的ids已经在使用。
FATAL [Kafka Server 1], Fatal error during KafkaServer startup. Prepare to shutdown (kafka.server.Ka ...
- 微信小程序开发(后端Java)
微信使用的开发语言和文件很「特殊」. 小程序所使用的程序文件类型大致分为以下几种: ①WXML(WeiXin Mark Language,微信标记语言) ②WXSS(WeiXin Style Shee ...