GAN 简介
GAN
原理:
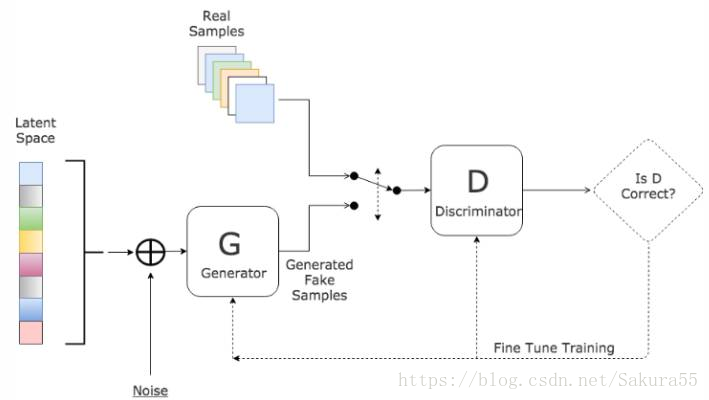
GAN 的主要灵感来源于博弈论中零和博弈的思想,应用到深度学习神经网络上来说,就是通过生成网络 G(Generator)和判别网络 D(Discriminator)不断博弈,进而使 G 学习到数据的分布,如果用到图片生成上,则训练完成后,G 可以从一段随机数中生成逼真的图像。
- G 是一个生成网络,其输入为一个随机噪音,在训练中捕获真实数据的分布,从而生成尽可能真实的数据并让 D 犯错
- D 是一个判别网络,判别生成的数据是不是“真实的”。它的输入参数是 x,输出 D(x) 代表 x 为真实数据的概率,如果为 1,就代表 100% 是真实的数据,而输出为 0,就代表不可能是真实的数据
为了从数据 x 中学习到生成器的分布 \(p_g\),我们定义一个输入噪音变量 \(p_z(z)\),然后将其映射到数据空间得到 \(G(z;\theta_g)\)。\(D(x; \theta_d)\) 输出是一个数,代表 \(x\) 来自真实数据而不是 \(p_g\) 的概率。
&\min_G \max_D V(D,G) = E_{x∼p_{data}(x)}[log(D(x))]+E_{z∼p_{z}(z)}[log(1−D(G(z)))] \qquad ①\\
&训练 D 来最大化辨别能力:\quad \max_D V(D,G)=E_{x∼p_{data}(x)}[log(D(x))]+E_{z∼p_z(z)}[log(1−D(G(z)))]\qquad② \\
&训练 G 来最小化log(1−D(G(z))):\quad \min_G V(D,G)=E_{z∼p_z(z)}[log(1−D(G(z)))]\qquad③ \\
\end{aligned}
\]
注:\(\max_D\) 表示令 \(D(x)\) 尽可能大以便找出真实数据,而令 \(D(G(z))\) 尽可能小以便区分出伪造数据,最后导致 ② 式尽可能大;\(\min_G\) 表示令 \(D(G(z))\) 尽可能大从而混淆判别器,最后导致 ③ 式尽可能小。训练早期,G 的拟合程度很低,D 可以被训练得很好,导致 log(1-D(G(z))) 趋于 0,进而使回传梯度很小,导致训练效果不行。因此,比起 minimize log(1-D(G(z))),maximize log(D(G(z))) 会更好。
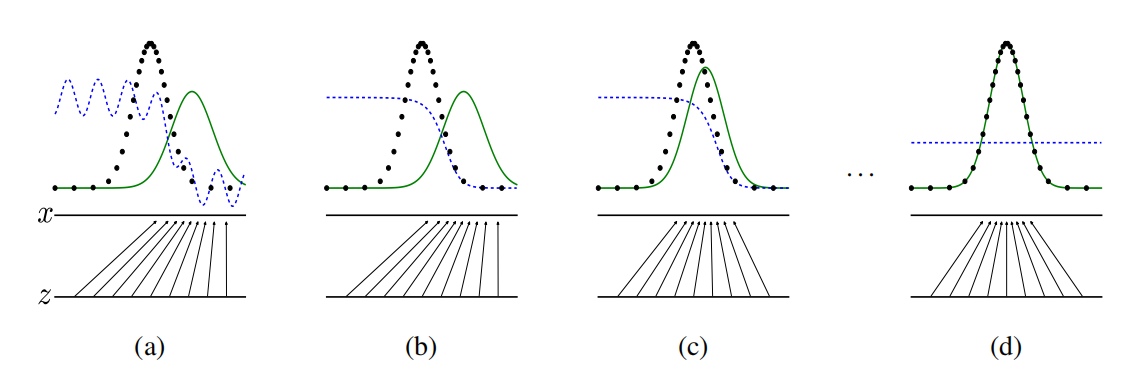
注:将随机噪音 z 映射到 x 上(x = G(z)),使 x 尽可能拟合真实数据 data 的分布。绿色实线为生成的数据 p_g,黑色点为真实数据 p_data,蓝色虚线为判别器 D。每次训练 G 都使 p_g 尽可能拟合 p_data,而判别器 D 则会调整从而尽可能将 p_g 和 p_data 区分开。当 D(x) = 0.5 时,判别器将无法区分真假。
算法:

小结:
命题1:当 G 被固定住时,最优的辨别器 D 如下
\]
证明:
&E_{x∼p}f(x) = \int_xp(x)f(x)dx \qquad x = g(z) \\
&V(G, D) = \int_x p_{data}(x)\log{(D(x))}dx + \int_zp_z(z)\log{(1-D(g(z)))}dz = \int_x p_{data}(x)\log{(D(x))} + p_g(x)\log{(1-D(x))}dx\\
&记:V(G, D) = \int_x a \cdot \log(y) + b \cdot \log{(1-y)} dx\qquad \\
&则函数 \quad y \rightarrow a \cdot \log(y) + b \cdot \log{(1-y)} 在 [0, 1]里最大值为:\quad \frac{a}{a+b} = \frac{p_{data}(x)}{p_{data}(x)+p_g(x)}
\end{aligned}
\]
定理1:当且仅当 \(p_g\) = \(p_{data}\) 时, C(G) 取得全局最小值,为 -log4
C(G) &= \max_DV(G, D) = E_{x∼p_{data}}[log(D_G^*(x))]+E_{z∼p_z}[log(1−D_G^*(G(z)))]\\
&= E_{x∼p_{data}}[log(D_G^*(x))]+E_{x∼p_g}[log(1−D_G^*(x)] = E_{x∼p_{data}}[log\frac{p_{data}(x)}{p_{data}(x)+ p_g(x)}]+E_{x∼p_g}[log\frac{p_g(x)}{p_{data}(x)+ p_g(x)}]\\
\end{aligned}
\]
KL 散度:KL(p||q) = \(E_{x∼p}\log{\frac{p(x)}{q(x)}}\)
证明:
&E_{x∼p_{data}}[-\log2] + E_{x∼p_g}[-\log2] = -\log4,则 \\
&C(G) = -\log(4) + KL(p_{data} || \frac{p_{data} + p_g}{2}) + KL(p_g || \frac{p_{data} + p_g}{2})
= -\log(4) + 2 \cdot JSD(p_{data} || p_g) \\
&由于 JSD 非负,且仅当其两个参数相等时才为 0,故,当 p_{data} = p_g 时 C(G) 取最小值为 -\log(4)
\end{aligned}
\]
命题2:当 G 和 D 有足够容量,且算法 1 中我们允许每一步 D 是可以达到他的最优解。那么如果我们对 G 的优化是去迭代下面这一步骤,则 p_g 会收敛到 p_{data}
\]
优缺点:
特点:
- 相比较传统的模型,GAN 存在两个不同的网络,而不是单一的网络,并且训练方式采用的是对抗训练方式
- GAN 中 G 的梯度更新信息来自判别器 D,而不是来自数据样本
优点:
- GAN 是一种生成式模型,相比较其他生成模型(玻尔兹曼机和GSNs)只用到了反向传播,而不需要复杂的马尔科夫链
- 相比其他所有模型, GAN 可以产生更加清晰、真实的样本
对 f 期望的求导等价于对 f 自己求导 => 通过误差的反向传递对 GAN 进行求解:\(\lim_{\sigma\rightarrow0}\nabla_xE_{\epsilon∼N(0, \sigma^2I)}f(x+\epsilon) = \nabla_xf(x)\)
- GAN 采用的是一种无监督学习方式训练,可以被广泛用在无监督学习和半监督学习领域。但却用一个有监督学习的损失函数来做无监督学习,在训练上会高效很多
- 相比于变分自编码器(VAE),GANs 没有引入任何决定性偏置( deterministic bias),变分方法引入决定性偏置。因为他们优化对数似然的下界,而不是似然度本身,这导致了 VAEs 生成的实例比 GANs 更模糊
- 相比 VAE,GANs 没有变分下界,如果鉴别器训练良好,那么生成器可以完美的学习到训练样本的分布。换句话说,GANs 是渐进一致的,而 VAE 是有偏差的
由于 GAN 的无监督,在生成过程中,G 就会按照自己的意思天马行空生成一些“诡异”的图片,可怕的是 D 还可能给一个很高的分数。这就是无监督目的性不强所导致的,所以在同年的NIPS大会上,有一篇论文 conditional GAN 就加入了监督性进去,将可控性增强,表现效果也好很多
缺点:
- 训练GAN需要达到纳什均衡,有时候可以用梯度下降法做到,但有时候做不到。我们还没有找到很好的达到纳什均衡的方法,所以训练 GAN 相比 VAE 或者 PixelRNN 是不稳定的,但我认为在实践中它还是比训练玻尔兹曼机稳定的多
- GAN 不适合处理离散形式的数据,比如文本
- GAN 存在训练不稳定、梯度消失、模式崩溃的问题(目前已解决)
GAN 的目的是在高维非凸的参数空间中找到纳什均衡点,GAN 的纳什均衡点是一个鞍点,但是 SGD 只会找到局部极小值,因为 SGD 解决的是一个寻找最小值的问题,GAN 是一个博弈问题。同时,SGD容易震荡,容易使GAN训练不稳定。因此,GAN 中的优化器不常用 SGD
补充:Generative Adversarial Net、GAN(生成对抗神经网络)原理解析、简单理解与实验生成对抗网络GAN、blogs from CSDN
GAN 简介的更多相关文章
- GAN实战笔记——第一章GAN简介
GAN简介 一.什么是GAN GAN是一类由两个同时训练的模型组成的机器学习技术:一个是生成器,训练其生成伪数据:另一个是鉴别器,训练其从真实数据中识别伪数据. 生成(generative)一词预示着 ...
- 不要怂,就是GAN (生成式对抗网络) (一): GAN 简介
前面我们用 TensorFlow 写了简单的 cifar10 分类的代码,得到还不错的结果,下面我们来研究一下生成式对抗网络 GAN,并且用 TensorFlow 代码实现. 自从 Ian Goodf ...
- GAN简介
GAN Generative Adversarial Networks 生成对抗网络.学习真实世界的真实数据的分布,用于创造以假乱真的数据.比如前段时间很火的应用deep fake.deep nude ...
- GAN模型生成手写字
概述:在前期的文章中,我们用TensorFlow完成了对手写数字的识别,得到了94.09%的识别准确度,效果还算不错.在这篇文章中,笔者将带领大家用GAN模型,生成我们想要的手写数字. GAN简介 对 ...
- DA-GAN技术【简介】【机器通过文字描述创造图像】
[题外话:今天上课我做了一个关于DA-GAN技术的ppt演讲,写一点东西留念一下...] 转载请注明出处:https://www.cnblogs.com/GraceSkyer/p/9107471.ht ...
- 2019年上半年收集到的人工智能GAN干货文章
2019年上半年收集到的人工智能GAN干货文章 GAN简介及其常见应用 训练GAN,你应该知道的二三事 了解生成对抗网络(GAN) CosmoGAN:训练GAN,让AI寻找宇宙中的暗物质 关于GAN的 ...
- 【机器学习PAI实战】—— 玩转人工智能之利用GAN自动生成二次元头像
前言 深度学习作为人工智能的重要手段,迎来了爆发,在NLP.CV.物联网.无人机等多个领域都发挥了非常重要的作用.最近几年,各种深度学习算法层出不穷, Generative Adverarial Ne ...
- 用Tensorflow实现DCGAN
1. GAN简介 最近几年,深度神经网络在图像识别.语音识别以及自然语言处理方面的应用有了爆炸式的增长,并且都达到了极高的准确率,某些方面甚至超过了人类的表现.然而人类的能力远超出图像识别和语音识别的 ...
- 用 Python 可以实现侧脸转正脸?我也要试一下!
作者 | 李秋键 责编 | Carol 封图 | CSDN 下载自视觉中国 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做案例 ...
随机推荐
- CF1463E Plan of Lectures
考虑我们两种操作: 我们把第一种操作在\(x\to y\)连一条权为-1的边. 第二种操作\(x\to y\)连-1,\(y\to x\)连1的边. 当无法操作则是环里有负环. 否则我们把第二种操作涉 ...
- LOJ 3399 -「2020-2021 集训队作业」Communication Network(推式子+组合意义+树形 DP)
题面传送门 一道推式子题. 首先列出柿子,\(ans=\sum\limits_{T_2}|T_1\cap T_2|·2^{T_1\cap T_2}\) 这个东西没法直接处理,不过注意到有一个柿子 \( ...
- Codeforces 1500E - Subset Trick(线段树)
Codeforces 题目传送门 & 洛谷题目传送门 一道线段树的套路题(似乎 ycx 会做这道题?orzorz!!11) 首先考虑什么样的 \(x\) 是"不合适"的,我 ...
- PHP非对称加密-RSA
对称加密算法是在加密和解密时使用同一个密钥.与对称加密算法不同,非对称加密算法需要两个密钥--公开密钥(public key)和私有密钥(private key)进行加密和解密.公钥和密钥是一对,如果 ...
- dlang ref的作用
ref 作用 1 import std.stdio, std.string; 2 3 void main() 4 { 5 string[] color=["red","b ...
- window修改dns本地文件
文件地址: C:\Windows\System32\drivers\etc 先修改权限: 最后用记事本打开编辑保存即可
- goto 的用法
#include <stdio.h> int main() { printf("go to cpy \n"); goto FLASH_CPY; printf(" ...
- kubernetes部署kube-scheduler服务
同样的分非认证授权和认证授权: 非认证授权: cat > /lib/systemd/system/kube-scheduler.service <<EOF [Unit] Descri ...
- Output of C++ Program | Set 10
Predict the output of following C++ programs. Question 1 1 #include<iostream> 2 #include<st ...
- android:为TextView添加样式、跑马灯、TextSwitcher和ImageSwitcher实现平滑过渡
一.样式 设置下划线: textView.getPaint().setFlags(Paint.UNDERLINE_TEXT_FLAG);//下划线 textView.getPaint().setAnt ...