大数据学习(08)—— Hive简介
前面的Hadoop学习是非常体系化的,有主线有细节。到了Hive这里,知识点非常零散,感觉没有什么主线能把它串起来。从官方网站上就能看出这点差异。
什么是Hive
Hive是一个基于Hadoop的企业级数据仓库,它的图标是大象头和蜜蜂身体。大象头表示它跟Hadoop有非常紧密的联系。
Hive通过类似SQL的方式做数据分析,它的数据存储在HDFS,而Hive SQL会转化为MapReduce任务。
由Hive SQL语句到具体的任务执行还需要经过解释器,编译器,优化器,执行器四部分才能完成。
(1)解释器:调用语法解释器和语义分析器将SQL语句转换成对应的可执行的java代码或者业务代码
(2)编译器:将对应的java代码转换成字节码文件或者jar包
(3)优化器:从Hive SQL语句到java代码的解析转化过程中需要调用优化器,进行相关策略的优化,实现最优的查询性能
(4)执行器:当业务代码转换完成之后,需要上传到MapReduce的集群中执行
为什么会出现Hive
当我们使用Hadoop来做数据分析的时候,编写MapReduce程序是非常麻烦的。一个MapReduce包含Map任务、自定义分区方法、排序比较器、分组比较器、Reduce任务。对像我这样十年的Java码农来说,编写一个完整的MapReduce程序尚且不是那么容易,可想而知对于那些没有Java基础的人来说,这种方式学习成本非常高。况且有相当一部分做数据分析工作的人是非计算机专业的,让他们写MapReduce代码几乎是不可能的。
这种情况下,Hive就出现了,它能够极大地降低数据分析门槛,只需要学习一些简单的类似SQL的语法就能快速上手数据分析工作。
Hive架构

Client
CLI(Command Line Interface):用户可以使用Hive自带的命令行接口执行Hive QL、设置参数等功能
JDBC/ODBC:用户可以使用JDBC或者ODBC的方式在代码中操作Hive
Web GUI:浏览器接口,用户可以在浏览器中对Hive进行操作(2.2之后淘汰)
Thrift Server
Thrift服务运行客户端使用Java、C++、Ruby等多种语言,通过编程的方式远程访问Hive。它介于Client和Driver之间。
Driver
Driver是Hive的核心,其中包含解释器、编译器、优化器等各个组件,完成Hive SQL查询从词法分析、语法分析、编译、优化以及查询计划的生成,生成的查询计划存储在HDFS中,并在随后由MapReduce调用执行。
Metastore
Hive的元数据存储服务,一般将数据存储在关系型数据库中,为了实现Hive元数据的持久化操作,Hive的安装包中自带了Derby内存数据库,但是在实际的生产环境中一般使用mysql来存储元数据。
Hive执行流程
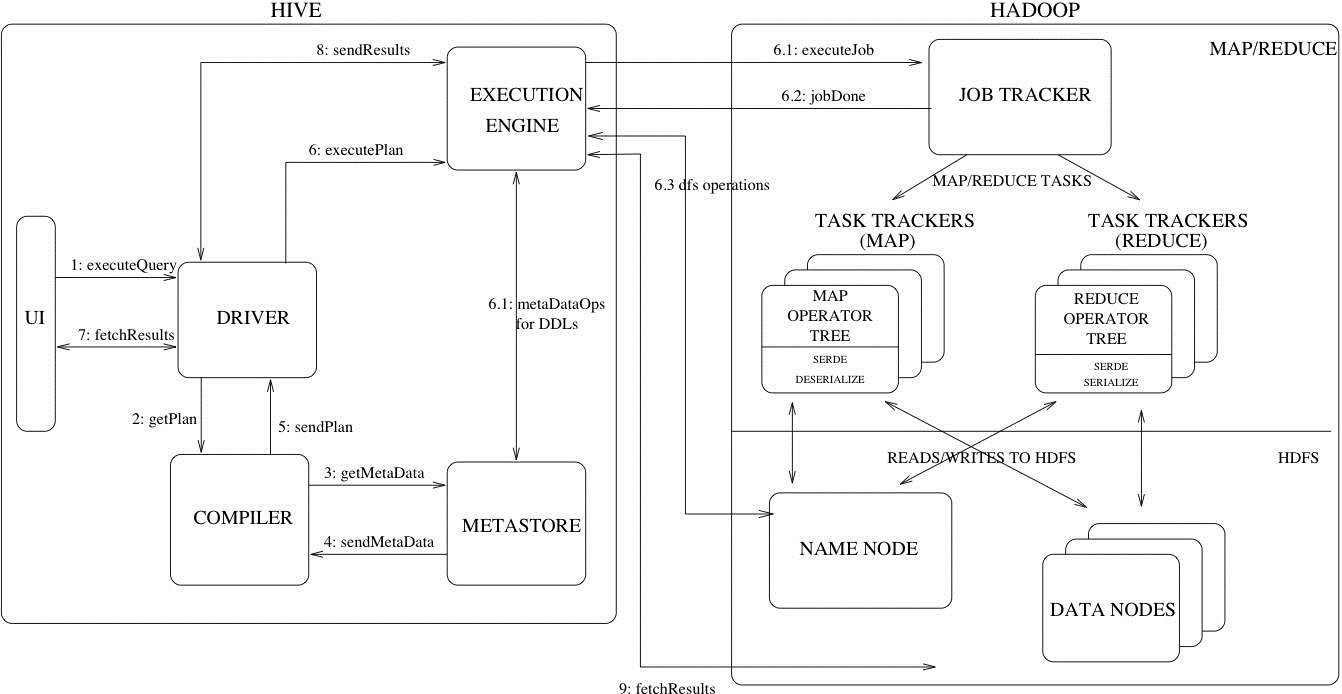
这张图详细描述了一个HiveSQL请求是怎么转换成MapReduce任务的。右边Hadoop的部分不是很准确,从Hadoop2.x开始,就由Yarn接管资源调度了,JobTracker还是Hadoop1.x特有的东西。
对于绝大多数使用Hive的人来说,不需要关注执行流程,优化器有100多个优化方法来帮助我们把HiveSQL转换成高效的MapRedcue任务,让使用者更加专注于业务逻辑。
大数据学习(08)—— Hive简介的更多相关文章
- 大数据学习day26----hive01----1hive的简介 2 hive的安装(hive的两种连接方式,后台启动,标准输出,错误输出)3. 数据库的基本操作 4. 建表(内部表和外部表的创建以及应用场景,数据导入,学生、分数sql练习)5.分区表 6加载数据的方式
1. hive的简介(具体见文档) Hive是分析处理结构化数据的工具 本质:将hive sql转化成MapReduce程序或者spark程序 Hive处理的数据一般存储在HDFS上,其分析数据底 ...
- 大数据学习——关于hive中的各种join
准备数据 2,b 3,c 4,d 7,y 8,u 2,bb 3,cc 7,yy 9,pp 建表: create table a(id int,name string) row format delim ...
- 大数据学习笔记——Hive完整部署流程
Hive详细部署教程 此篇博客承接上篇Hadoop和Zookeeper的部署教程,将会详细地对HIve的部署做一个整理,Hive相当于是封装在HDFS和Mapreduce上的一套sql引擎,只需要安装 ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习系列之九---- Hive整合Spark和HBase以及相关测试
前言 在之前的大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 中介绍了集群的环境搭建,但是在使用hive进行数据查询的时候会非常的慢,因为h ...
- 大数据学习(16)—— HBase环境搭建和基本操作
部署规划 HBase全称叫Hadoop Database,它的数据存储在HDFS上.我们的实验环境依然基于上个主题Hive的配置,参考大数据学习(11)-- Hive元数据服务模式搭建. 在此基础上, ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习之Linux基础01
大数据学习之Linux基础 01:Linux简介 linux是一种自由和开放源代码的类UNIX操作系统.该操作系统的内核由林纳斯·托瓦兹 在1991年10月5日首次发布.,在加上用户空间的应用程序之后 ...
随机推荐
- 从五大结构体,带你掌握鸿蒙轻内核动态内存Dynamic Memory
摘要:本文带领大家一起剖析了鸿蒙轻内核的动态内存模块的源代码,包含动态内存的结构体.动态内存池初始化.动态内存申请.释放等. 本文分享自华为云社区<鸿蒙轻内核M核源码分析系列九 动态内存Dyna ...
- Nginx报400 Bad Request
本地遇到此问题,关闭浏览器,重新运行代码即可
- Golang中GBK和UTF8编码格式互转
Golang中GBK和UTF8编码格式互转 需求 已知byte数组的编码格式转换 实现代码 package utils import ( "bytes" "golang. ...
- Centos7搭建内网DNS服务器
一.配置阿里云yum源 执行脚本配置阿里云的yum源,已配置yum源的可以忽略 #!/bin/bash # ******************************************** ...
- 【春节歌曲回味 | STM32小音乐盒 】PWM+定时器驱动无源蜂鸣器(STM32 HAL库)
l STM32通过PWM与定时器方式控制无源蜂鸣器鸣响 l STM32小音乐盒,歌曲进度条图形显示与百分比显示,歌曲切换 l 编程使用STM32 HAL库 l IIC OLED界面编程,动画实 ...
- python之字典(dict)基础篇
字典:dict 特点: 1>,可变容器模型,且可存储任意类型对象,字符串,列表,元组,集合均可: 2>,以key-value形式存在,每个键值 用冒号 : 分割,每个键值对之间用逗号 , ...
- 『心善渊』Selenium3.0基础 — 22、使用浏览器加载项配置实现用户免登陆
目录 1.浏览器的加载项配置 2.加载Firefox配置 3.加载Chrome配置 1.浏览器的加载项配置 在很多情况下,我们在登录网站的时候,浏览器都会弹出一个是否保存登录账号的信息.如果我们选择保 ...
- 关于mysql binlog二进制
binlog 在mysql中,当发生数据变更时,都会将变更数据的语句,通过二进制形式,存储到binlog日志文件中. 通过binlog文件,你可以查看mysql一段时间内,对数据库的所有改动. 也可以 ...
- 抓包工具-Charles
1.简介Charles Charles其实是一款代理服务器,通过成为电脑或者浏览器的代理,然后截取请求和请求结果达到分析抓包的目的.charles有Window版本和Mac OS版本,也同时支持ios ...
- java测试银行系统源代码
1 package Kaoshi; 2 3 /*信1705-3 20173442 田昕可*/ 4 import java.util.*; 5 import java.io.*; 6 7 class A ...