【数据结构与算法Python版学习笔记】基本数据结构——列表 List,链表实现
无序表链表
定义
- 一种数据项按照相对位置存放的数据集
抽象数据类型无序列表 UnorderedList
方法
list()创建一个新的空列表。它不需要参数,而返回一个空列表。add(item)将新项添加到列表,没有返回值。假设元素不在列表中。remove(item)从列表中删除元素。需要一个参数,并会修改列表。此处假设元素在列表中。search(item)搜索列表中的元素。需要一个参数,并返回一个布尔值。isEmpty()判断列表是否为空。不需要参数,并返回一个布尔值。size()返回列表的元素数。不需要参数,并返回一个整数。append(item)在列表末端添加一个新的元素。它需要一个参数,没有返回值。假设该项目不在列表中。index(item)返回元素在列表中的位置。它需要一个参数,并返回位置索引值。此处假设该元素原本在列表中。insert(pos,item)在指定的位置添加一个新元素。它需要两个参数,没有返回值。假设该元素在列表中并不存在,并且列表有足够的长度满足参数提供的索引需要。pop()从列表末端移除一个元素并返回它。它不需要参数,返回一个元素。假设列表至少有一个元素。pop(pos)从指定的位置移除列表元素并返回它。它需要一个位置参数,并返回一个元素。假设该元素在列表中。
实现
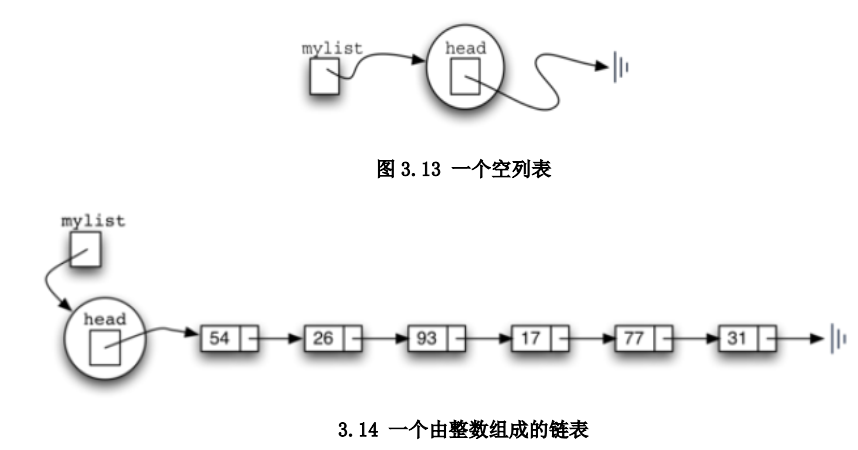
- 为了实现无序表数据结构,可以采用链接表的方案
- 虽然列表数据结构要求保持数据项的前后相对位置,但这种前后位置的保持,并不要求数据项依次存放在连续的存储空间
- 数据存放位置没有规则,但如果在数据项之间建立链向指向,就可以保持其前后相对位置
第一个和最后一个数据项需要显示标记出来 - 基本元素是节点Node
- 每个节点至少包含2个信息:
- 数据项本身
- 指向下一个节点的引用信息,next为None代表没有下一个节点
- 每个节点至少包含2个信息:
- 可以采用链接节点的方式构建数据集来实现无序表
- 链表的第一个和最后一个节点最重要
必须冲第一个节点head开始沿着链接遍历下去
class Node:
def __init__(self, initdata):
self.data = initdata
self.next = None
def getData(self):
return self.data
def getNext(self):
return self.next
def setData(self, newdata):
self.data = newdata
def setNext(self, newnext):
self.next = newnext
if __name__ == "__main__":
temp = Node(93)
print(temp.getData())
class UnorderedList:
def __init__(self):
self.head = None
def isEmpty(self):
return self.head == None
def add(self, item):
temp = Node(item)
temp.setNext(self.head)
self.head = temp
def size(self):
current = self.head
count = 0
while current != None:
count += 1
current = current.getNext()
return count
def search(self, item):
current = self.head
found = False
while current != None and not found:
if current.getData() == item:
found = True
else:
current = current.getNext()
return found
def remove(self, item):
current = self.head
previous = None
found = False
while not found:
if current.getData() == item:
found = True
else:
previous = current
current = current.getNext()
if previous == None:
self.head = current.getNext()
else:
previous.setNext(current.getNext())
有序表
定义
- 有序表是一种数据项依据其某种可比性质(如整数大小,字母表先后)来决定在列表中的位置
- 越“小”的数据项越靠近列表的头,越靠“前”
抽象数据类型:有序列表
操作
OrderedList():创建一个新的空有序列表。它返回一个空有序列表并且不需要传递任何参数。add(item):在保持原有顺序的情况下向列表中添加一个新的元素,新的元素作为参数传递进函数而函数无返回值。假设列表中原先并不存在这个元素。remove(item):从列表中删除某个元素。欲删除的元素作为参数,并且会修改原列表。假设原列表中存在欲删除的元素。search(item):在列表中搜索某个元素,被搜索元素作为参数,返回一个布尔值。isEmpty():测试列表是否为空,不需要输入参数并且其返回一个布尔值。size():返回列表中元素的数量。不需要参数,返回一个整数。index(item):返回元素在列表中的位置。需要被搜索的元素作为参数输入,返回此元素的索引值。假设这个元素在列表中。pop():删除并返回列表中的最后一项。不需要参数,返回删除的元素。假设列表中至少有一个元素。pop(pos):删除并返回索引 pos 指定项。需要被删除元素的索引值作为参数,并且返回这个元素。假设该元素在列表中。
实现
- 采用链表方法实现
- Node定义相同
- OrderedList也设置一个head来保存链表表头的引用
- search方法
- 无序表中,如果需要查找的数据项不存在,则会搜遍整个链表,直到表尾
- 对于有序表,可以利用链表节点有序排列的特性,来为search节省不存在数据项的查找时间
- add方法
- 必须保证加入数据添加在合适的位置,以维护整个链表的有序性
- 要和remove方法类似,引用一个previous的引用,跟随当前节点current
class Node:
def __init__(self, initdata):
self.data = initdata
self.next = None
def getData(self):
return self.data
def getNext(self):
return self.next
def setData(self, newdata):
self.data = newdata
def setNext(self, newnext):
self.next = newnext
if __name__ == "__main__":
temp = Node(93)
print(temp.getData())
def OrderedList:
def __init__(self):
self.head = None
def isEmpty(self):
return self.head == None
def add(self, item):
current = self.head
previous = None
stop= False
while current != None and not stop:
if current.getData()>item:
stop=True
else:
previous=current
current=current.getNext()
temp=Node(item)
if previous==None:
temp.setNext(self.head)
self.head=temp
else:
temp.setNext(current)
previous.setNext(temp)
def size(self):
current = self.head
count = 0
while current != None:
count += 1
current = current.getNext()
return count
def search(self, item):
current = self.head
found = False
stop= False
while current != None and not found and not stop:
if current.getData() == item:
found = True
else:
if current.getData()>item:
stop=True
else:
current = current.getNext()
return found
def remove(self, item):
current = self.head
previous = None
found = False
while not found:
if current.getData() == item:
found = True
else:
previous = current
current = current.getNext()
if previous == None:
self.head = current.getNext()
else:
previous.setNext(current.getNext())
链表实现的算法分析
- 对于链表复杂度的分析,主要看方法是否涉及到链表的遍历
- isEmpty O(1)
- size O(n)
- search/remove O(n)
- 有序表 add O(n)
- 无序表 add O(1)
- 链表实现的List,跟python内置的列表数据类型,在有些相同方法的实现上的时间复杂度不同。
原因在于python内置的列表数据类型是基于顺序存储来实现的,并进行了优化
【数据结构与算法Python版学习笔记】基本数据结构——列表 List,链表实现的更多相关文章
- 【数据结构与算法Python版学习笔记】引言
学习来源 北京大学-数据结构与算法Python版 目标 了解计算机科学.程序设计和问题解决的基本概念 计算机科学是对问题本身.问题的解决.以及问题求解过程中得出的解决方案的研究.面对一 个特定问题,计 ...
- 【数据结构与算法Python版学习笔记】查找与排序——散列、散列函数、区块链
散列 Hasing 前言 如果数据项之间是按照大小排好序的话,就可以利用二分查找来降低算法复杂度. 现在我们进一步来构造一个新的数据结构, 能使得查找算法的复杂度降到O(1), 这种概念称为" ...
- 【数据结构与算法Python版学习笔记】算法分析
什么是算法分析 算法是问题解决的通用的分步的指令的聚合 算法分析主要就是从计算资源的消耗的角度来评判和比较算法. 计算资源指标 存储空间或内存 执行时间 影响算法运行时间的其他因素 分为最好.最差和平 ...
- 【数据结构与算法Python版学习笔记】递归(Recursion)——定义及应用:分形树、谢尔宾斯基三角、汉诺塔、迷宫
定义 递归是一种解决问题的方法,它把一个问题分解为越来越小的子问题,直到问题的规模小到可以被很简单直接解决. 通常为了达到分解问题的效果,递归过程中要引入一个调用自身的函数. 举例 数列求和 def ...
- 【数据结构与算法Python版学习笔记】树——利用二叉堆实现优先级队列
概念 队列有一个重要的变体,叫作优先级队列. 和队列一样,优先级队列从头部移除元素,不过元素的逻辑顺序是由优先级决定的. 优先级最高的元素在最前,优先级最低的元素在最后. 实现优先级队列的经典方法是使 ...
- 【数据结构与算法Python版学习笔记】树——相关术语、定义、实现方法
概念 一种基本的"非线性"数据结构--树 根 枝 叶 广泛应用于计算机科学的多个领域 操作系统 图形学 数据库 计算机网络 特征 第一个属性是层次性,即树是按层级构建的,越笼统就越 ...
- 【数据结构与算法Python版学习笔记】目录索引
引言 算法分析 基本数据结构 概览 栈 stack 队列 Queue 双端队列 Deque 列表 List,链表实现 递归(Recursion) 定义及应用:分形树.谢尔宾斯基三角.汉诺塔.迷宫 优化 ...
- 【数据结构与算法Python版学习笔记】递归(Recursion)——优化问题与策略
分治策略:解决问题的典型策略,分而治之 将问题分为若干更小规模的部分 通过解决每一个小规模部分问题,并将结果汇总得到原问题的解 递归算法与分治策略 递归三定律 体现了分支策略 应用相当广泛 排序 查找 ...
- 【数据结构与算法Python版学习笔记】图——最短路径问题、最小生成树
最短路径问题 概念 可以通过"traceroute"命令来跟踪信息传送的路径: traceroute www.lib.pku.edu.cn 可以将互联网路由器体系表示为一个带权边的 ...
随机推荐
- (一)Superset 1.3图表篇——Table
本系列文章基于Superset 1.3.0版本.1.3.0版本目前支持分布,趋势,地理等等类型共59张图表.本次1.3版本的更新图表有了一些新的变化,而之前也一直没有做过非常细致的图表教程. 而且目前 ...
- Python__bs4模块
1 - 导入模块 from bs4 import BeautifulSoup 2 - 创建对象 fp = open('./test.html','r',encoding='utf-8') soup = ...
- Servlet体系结构
一.使用HttpServlet 其中,HttpServlet在重写的service()方法中对http请求的共7中提交方式进行了判断,所以只要我们只要重写对应的请求方式处理逻辑方法 doGet()和d ...
- SpringApplication启动-图解
- Linux上安装服务器监视工具,名为Scout_Realtime。
如何从浏览器监视Linux服务器和进程指标 在服务器上安装Ruby 1.9.3+ sudo yum -y install rubygems-devel 在Linux系统上安装了Ruby之后,现在可以使 ...
- k8s核心资源之namespace与pod污点容忍度生命周期进阶篇(四)
目录 1.命名空间namespace 1.1 什么是命名空间? 1.2 namespace应用场景 1.3 namespacs常用指令 1.4 namespace资源限额 2.标签 2.1 什么是标签 ...
- SpringMVC执行流程总结
SpringMVC 执行流程: 用户发送请求至前端控制器 DispatcherServlet DispatcherServlet 收到请求调用处理映射器 HandlerMapping 处理映射器根据请 ...
- 关于vue-cli的安装
(一):*安装 vue-cli 参考: https://cn.vuejs.org/v2/guide/installation.html https://github.com/vuejs/vue-cli ...
- Go学习【02】:理解Gin,搭一个web demo
Go Gin 框架 说Gin是一个框架,不如说Gin是一个类库或者工具库,其包含了可以组成框架的组件.这样会更好理解一点. 举个 下面的示例代码在这:github 利用Gin组成最基本的框架.说到框架 ...
- 配置 放上传文件的目录 apache(httpd)
1. 确认服务器 开放8088端口 https://www.apachefriends.org/download.html 下载XAMPP for Windows,安装 2. 修改apache主配置文 ...