Python 爬虫三 beautifulsoup模块
beautifulsoup模块
BeautifulSoup模块
BeautifulSoup是一个模块,该模块用于接收一个HTML或XML字符串,然后将其进行格式化,之后遍可以使用他提供的方法进行快速查找指定元素,从而使得在HTML或XML中查找指定元素变得简单。
安装:
- pip install beautifulsoup4
在python自动化模块对bs已经简单介绍了。这里直接看快速使用:
- import requests
- from bs4 import BeautifulSoup
- import os
- response = requests.get( # get请求
- url='https://www.autohome.com.cn/news/'
- )
- response.encoding = response.apparent_encoding # 使用默认的编码原则
- soup = BeautifulSoup(response.text, features='html.parser') # 实例化soup对象的两种参数方式
- # soup = BeautifulSoup(response.text, features='lxml')
- # print(response.text)
- target = soup.find(id='auto-channel-lazyload-article') # 取指定id的对象
- # obj = target.find('li') # 找到第一个li
- li_list = target.find_all('li') # 找到所有的li, 是一个列表,里面是bs对象
- for i in li_list: # 遍历li的列表内对象
- a = i.find('a')
- if a:
- # print(a.attrs) # {'href': '//www.autohome.com.cn/news/201807/919525.html#pvareaid=102624'}
- # print(a.attrs.get('href'))
- # txt = a.find('h3') # 本质上是对象,但是打印出来是字符串
- txt = a.find('h3').txt # 提取内部字符串
- print(txt)
- img_url = a.find('img').attrs.get('src')
- img_url = img_url.strip('//') # src ==> //www.autohome.com.cn/**********/***.jpg
- print(img_url)
- img_type = img_url.split('.')[-1]
- print(img_type)
- img_response = requests.get(url='http://' + img_url) # 对于img的路径再次发送get请求
- import uuid
- with open(os.path.join('file', str(uuid.uuid4()) + '.' + img_type), 'wb') as f:
- f.write(img_response.content) # 二进制文件写入文件句柄内
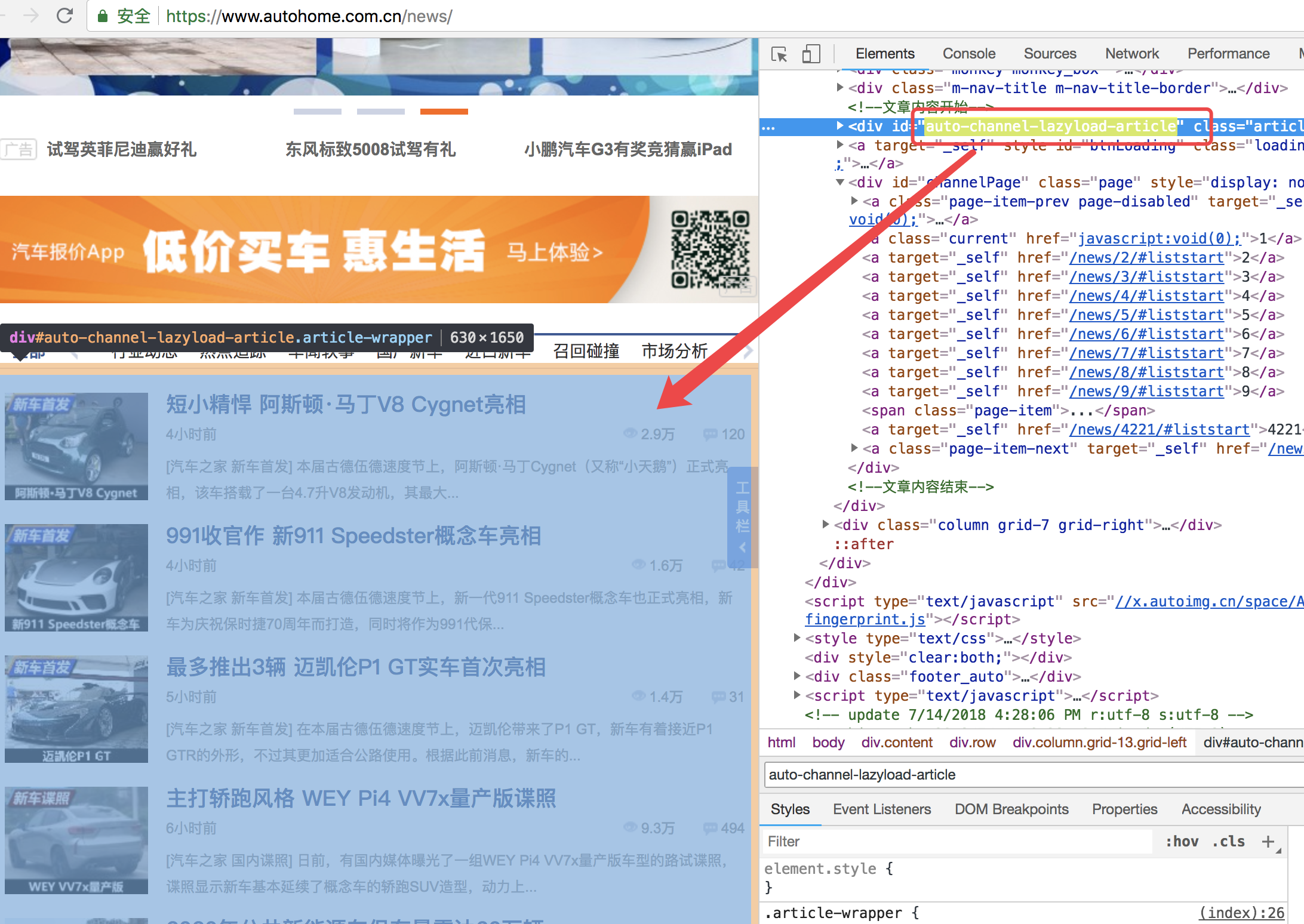
此段代码,定向的抓去了目的div的内部a标签的资源,循环发送get请求抓去处图片保存到了本地:

解析器
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果我们不安装它,则 Python 会使用 Python默认的解析器,lxml 解析器更加强大,速度更快,推荐安装。
下面是常见解析器:

推荐使用lxml作为解析器,因为效率更高. 在Python2.7.3之前的版本和Python3中3.2.2之前的版本,必须安装lxml或html5lib, 因为那些Python版本的标准库中内置的HTML解析方法不够稳定.
基本使用
在快速使用中我们添加如下代码:
print(soup.title)
print(type(soup.title))
print(soup.head)
print(soup.p)
通过这种soup.标签名 我们就可以获得这个标签的内容
这里有个问题需要注意,通过这种方式获取标签,如果文档中有多个这样的标签,返回的结果是第一个标签的内容,如上面我们通过soup.p获取p标签,而文档中有多个p标签,但是只返回了第一个p标签内容
使用示例:
- from bs4 import BeautifulSoup
- html_doc = """
- <html><head><title>The Dormouse's story</title></head>
- <body>
- ...
- </body>
- </html>
- """
- soup = BeautifulSoup(html_doc, features="lxml")
1、标签名称
- tag = soup.find('a')
- name = tag.name # 获取
- print(name)
- tag.name = 'span' # 设置
- print(soup)
2、标签属性
- tag = soup.find('a')
- attrs = tag.attrs # 获取
- print(attrs)
- tag.attrs = {'ik':123} # 设置
- tag.attrs['id'] = 'iiiii' # 设置
- print(soup)
3、字标签
- body = soup.find('body')
- v = body.children
4、所有子孙标签
- body = soup.find('body')
- v = body.descendants
5、clear、将标签的所有子标签全部清空(保留标签名)
- tag = soup.find('body')
- tag.clear()
- print(soup)
6、decompose、递归的删除所有标签
- body = soup.find('body')
- body.decompose()
- print(soup)
7、extract、递归的删除所有的标签,并获取删除的标签对象
- body = soup.find('body')
- v = body.extract()
- print(soup)
8、decode,转换为字符串(含当前标签);decode_contents(不含当前标签)
- body = soup.find('body')
- v = body.decode()
- v = body.decode_contents()
- print(v)
9、encode,转换为字节(含当前标签);encode_contents(不含当前标签)
- body = soup.find('body')
- v = body.encode()
- v = body.encode_contents()
- print(v)
10、find,获取匹配的第一个标签
- tag = soup.find('a')
- print(tag)
- tag = soup.find(name='a', attrs={'class': 'sister'}, recursive=True, text='Lacie')
- tag = soup.find(name='a', class_='sister', recursive=True, text='Lacie')
- print(tag)
11、find_all,获取匹配的所有标签
- # tags = soup.find_all('a')
- # print(tags)
- # tags = soup.find_all('a',limit=1)
- # print(tags)
- # tags = soup.find_all(name='a', attrs={'class': 'sister'}, recursive=True, text='Lacie')
- # # tags = soup.find(name='a', class_='sister', recursive=True, text='Lacie')
- # print(tags)
- # ####### 列表 #######
- # v = soup.find_all(name=['a','div'])
- # print(v)
- # v = soup.find_all(class_=['sister0', 'sister'])
- # print(v)
- # v = soup.find_all(text=['Tillie'])
- # print(v, type(v[0]))
- # v = soup.find_all(id=['link1','link2'])
- # print(v)
- # v = soup.find_all(href=['link1','link2'])
- # print(v)
- # ####### 正则 #######
- import re
- # rep = re.compile('p')
- # rep = re.compile('^p')
- # v = soup.find_all(name=rep)
- # print(v)
- # rep = re.compile('sister.*')
- # v = soup.find_all(class_=rep)
- # print(v)
- # rep = re.compile('http://www.oldboy.com/static/.*')
- # v = soup.find_all(href=rep)
- # print(v)
- # ####### 方法筛选 #######
- # def func(tag):
- # return tag.has_attr('class') and tag.has_attr('id')
- # v = soup.find_all(name=func)
- # print(v)
- # ## get,获取标签属性
- # tag = soup.find('a')
- # v = tag.get('id')
- # print(v)
12、has_attr,检查标签是否具有该属性
- tag = soup.find('a')
- v = tag.has_attr('id')
- print(v)
13、get_text,获取标签内部文本内容
- tag = soup.find('a')
- v = tag.get_text('id')
- print(v)
14、index,检查标签在某标签中的索引位置
- tag = soup.find('body')
- v = tag.index(tag.find('div'))
- print(v)
- tag = soup.find('body')
- for i, v in enumerate(tag):
- print(i,v)
15、is_empty_element,是否是空标签(是否可以是空)或者自闭合标签
- # 判断是否是如下标签:'br' , 'hr', 'input', 'img', 'meta','spacer', 'link', 'frame', 'base'
- tag = soup.find('br')
- v = tag.is_empty_element
- print(v)
16、当前的关联标签
- soup.next # 不跳过内容
- soup.next_element # 只找下一个对象,标签对象
- soup.next_elements
- soup.next_sibling
- soup.next_siblings
- tag.previous
- tag.previous_element
- tag.previous_elements
- tag.previous_sibling
- tag.previous_siblings
- tag.parent
- tag.parents
17、查找某标签的关联标签
- tag.find_next(...) # 参数跟find、 find_all一样
- tag.find_all_next(...)
- tag.find_next_sibling(...)
- tag.find_next_siblings(...)
- tag.find_previous(...)
- tag.find_all_previous(...)
- tag.find_previous_sibling(...)
- tag.find_previous_siblings(...)
- tag.find_parent(...)
- tag.find_parents(...)
- # 参数同find_all
18. select,select_one, CSS选择器
- soup.select("title")
- soup.select("p nth-of-type(3)")
- soup.select("body a")
- soup.select("html head title")
- tag = soup.select("span,a")
- soup.select("head > title")
- soup.select("p > a")
- soup.select("p > a:nth-of-type(2)")
- soup.select("p > #link1")
- soup.select("body > a")
- soup.select("#link1 ~ .sister")
- soup.select("#link1 + .sister")
- soup.select(".sister")
- soup.select("[class~=sister]")
- soup.select("#link1")
- soup.select("a#link2")
- soup.select('a[href]')
- soup.select('a[href="http://example.com/elsie"]')
- soup.select('a[href^="http://example.com/"]')
- soup.select('a[href$="tillie"]')
- soup.select('a[href*=".com/el"]')
- from bs4.element import Tag
- def default_candidate_generator(tag):
- for child in tag.descendants:
- if not isinstance(child, Tag):
- continue
- if not child.has_attr('href'):
- continue
- yield child
- tags = soup.find('body').select("a", _candidate_generator=default_candidate_generator)
- print(type(tags), tags)
- from bs4.element import Tag
- def default_candidate_generator(tag):
- for child in tag.descendants:
- if not isinstance(child, Tag):
- continue
- if not child.has_attr('href'):
- continue
- yield child
- tags = soup.find('body').select("a", _candidate_generator=default_candidate_generator, limit=1)
- print(type(tags), tags)
19、标签的内容
- tag = soup.find('span')
- print(tag.string) # 获取,可以修改
- tag.string = 'new content' # 设置
- print(soup)
- tag = soup.find('body')
- print(tag.string)
- tag.string = 'xxx'
- print(soup)
- tag = soup.find('body')
- v = tag.stripped_strings # 递归内部获取所有标签的文本
- print(v)
20、append在当前标签内部追加一个标签
- tag = soup.find('body')
- tag.append(soup.find('a'))
- print(soup)
- from bs4.element import Tag
- obj = Tag(name='i',attrs={'id': 'it'})
- obj.string = '我是一个新来的'
- tag = soup.find('body')
- tag.append(obj)
- print(soup)
21、insert在当前标签内部指定位置插入一个标签
- from bs4.element import Tag
- obj = Tag(name='i', attrs={'id': 'it'})
- obj.string = '我是一个新来的'
- tag = soup.find('body')
- tag.insert(2, obj)
- print(soup)
22、insert_after,insert_before 在当前标签后面或前面插入
- from bs4.element import Tag
- obj = Tag(name='i', attrs={'id': 'it'})
- obj.string = '我是一个新来的'
- tag = soup.find('body')
- # tag.insert_before(obj)
- tag.insert_after(obj)
- print(soup)
23、replace_with 在当前标签替换为指定标签
- from bs4.element import Tag
- obj = Tag(name='i', attrs={'id': 'it'})
- obj.string = '我是一个新来的'
- tag = soup.find('div')
- tag.replace_with(obj)
- print(soup)
24、创建标签之间的关系
- tag = soup.find('div')
- a = soup.find('a')
- tag.setup(previous_sibling=a)
- print(tag.previous_sibling) # 只改关联关系,不改变位置
25、wrap,将指定标签把当前标签包裹起来
- from bs4.element import Tag
- obj1 = Tag(name='div', attrs={'id': 'it'})
- obj1.string = '我是一个新来的'
- tag = soup.find('a')
- v = tag.wrap(obj1)
- print(soup)
- tag = soup.find('a')
- v = tag.wrap(soup.find('p'))
- print(soup)
26、unwrap,去掉当前标签,将保留其包裹的标签
- tag = soup.find('a')
- v = tag.unwrap()
- print(soup)
总结
推荐使用lxml解析库,必要时使用html.parser
标签选择筛选功能弱但是速度快
建议使用find()、find_all() 查询匹配单个结果或者多个结果
如果对CSS选择器熟悉建议使用select()
记住常用的获取属性和文本值的方法
Python 爬虫三 beautifulsoup模块的更多相关文章
- Python爬虫之Beautifulsoup模块的使用
一 Beautifulsoup模块介绍 Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Be ...
- Python爬虫之urllib模块2
Python爬虫之urllib模块2 本文来自网友投稿 作者:PG-55,一个待毕业待就业的二流大学生. 看了一下上一节的反馈,有些同学认为这个没什么意义,也有的同学觉得太简单,关于Beautiful ...
- 孤荷凌寒自学python第六十七天初步了解Python爬虫初识requests模块
孤荷凌寒自学python第六十七天初步了解Python爬虫初识requests模块 (完整学习过程屏幕记录视频地址在文末) 从今天起开始正式学习Python的爬虫. 今天已经初步了解了两个主要的模块: ...
- Python爬虫练习(requests模块)
Python爬虫练习(requests模块) 关注公众号"轻松学编程"了解更多. 一.使用正则表达式解析页面和提取数据 1.爬取动态数据(js格式) 爬取http://fund.e ...
- Python爬虫之urllib模块1
Python爬虫之urllib模块1 本文来自网友投稿.作者PG,一个待毕业待就业二流大学生.玄魂工作室未对该文章内容做任何改变. 因为本人一直对推理悬疑比较感兴趣,所以这次爬取的网站也是平时看一些悬 ...
- 使用Python爬虫库BeautifulSoup遍历文档树并对标签进行操作详解(新手必学)
为大家介绍下Python爬虫库BeautifulSoup遍历文档树并对标签进行操作的详细方法与函数下面就是使用Python爬虫库BeautifulSoup对文档树进行遍历并对标签进行操作的实例,都是最 ...
- Python爬虫教程-09-error 模块
Python爬虫教程-09-error模块 今天的主角是error,爬取的时候,很容易出现错,所以我们要在代码里做一些,常见错误的处,关于urllib.error URLError URLError ...
- Python网络爬虫之BeautifulSoup模块
一.介绍: Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮 ...
- Python爬虫之BeautifulSoup的用法
之前看静觅博客,关于BeautifulSoup的用法不太熟练,所以趁机在网上搜索相关的视频,其中一个讲的还是挺清楚的:python爬虫小白入门之BeautifulSoup库,有空做了一下笔记: 一.爬 ...
随机推荐
- 第三十八篇-logcat的使用
很多時候,程序有问题时都需要debug,一般会设置几个信息点,查看程序是否运行,之前学过Toast,可以广播,但是终归是不太方便,今天学习一下logcat的用法. logcat里面是一些日志,内容太多 ...
- 为Druid监控配置访问权限(配置访问监控信息的用户与密码)
转: l 为Druid监控配置访问权限(配置访问监控信息的用户与密码) 2014-09-26 09:21:48 来源:renfufei的专栏 收藏 我要投稿 Druid是一 ...
- C#梳理【集合Collection】
C# 集合(Collection) 集合(Collection)类是专门用于数据存储和检索的类.这些类提供了对栈(stack).队列(queue).列表(list)和哈希表(hash table)的支 ...
- docker 基础之私有仓库
docker-registry 是官方提供的工具,可以用于构建私有的镜像仓库.安装运行 docker-registry容器 在安装了 Docker 后,可以通过获取官方 registry 镜像来运行. ...
- 利用 JMetal 实现大规模聚类问题的研究(一)JMetal配置
研究多目标优化问题,往往需要做实验来对比效果,所以需要很多多目标方面的经典代码,比如NSGA-II, SPEA, MOEA,MOEA/D, 或者PSO等等. 想亲自实现这些代码,非常浪费时间,还有可能 ...
- ssh-keygen Linux 免密登录
一.选择算法和密钥大小 rsa - 基于分解大数的难度的旧算法.RSA建议密钥大小至少为2048位,4096位更好.RSA正在变老,并且在保理方面取得了重大进展.可能建议选择不同的算法.在可预见的将来 ...
- zookeeper下的基本操作
安装好zk之后 启动服务端:在bin目录下 zkServer.sh restart 启动客户端 zkCli.sh 检查是否启动 直接输入jps命令,显示下面则表示启动成功 [root@iZbp12gg ...
- Docker记录-Docker部署记录
1.Docker介绍 Docker 是一个开源的应用容器引擎,基于 Go 语言 并遵从Apache2.0协议开源. Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级.可移植的容器中,然后 ...
- Sidekiq定时任务时间设置
minutely(2) #每2分钟执行一次 hourly.minute_of_hour(27) #每小时的27分钟执行 dail ...
- git的那些事
前言:记得在想学习git的时候,一直停留在思想的层面,总没有弄清楚它的运行机制,经常与github混淆,还好找到了一个好的教程,带我领略了git的风采 (一)git的优点 git的优点:版本控制在本地 ...