ES集群
1. ElasticSerach集群安装
修改配置文件elasticserach.yml
[elk@localhost config]$ vi elasticsearch.yml
# ---------------------------------- Cluster -----------------------------------
# Use a descriptive name for your cluster:
cluster.name: my-es #集群中机器的name必须相同 # Use a descriptive name for the node:
node.name: node- ##集群中各个节点的名字(必须不同) #指定了该节点可能成为 master 节点,还可以是数据节点(Cent-os6上没配置它)
node.master: true
node.data: true # Path to directory where to store the data (separate multiple locations by comma):
path.data: /home/elk/es/data
# Path to log files:
path.logs: /home/elk/es/logs # Set the bind address to a specific IP (IPv4 or IPv6):
network.host: 192.168.1.101 # 当前节点的IP地址,每个机器的host是不一样的
# Set a custom port for HTTP: ##(CentOS6没配置它)
http.port: # 对外提供服务的端口
transport.tcp.port: #9300为集群服务的端口,各个节点之间互相通信 # The default list of hosts is ["127.0.0.1", "[::1]"] ##自发现配置,新节点向集群报到的主机名
discovery.zen.ping.unicast.hosts: ["192.168.1.102", "192.168.1.103"] #集群中节点IP地址,也可以使用域名,需要各节点能够解析;不能写本机的,自己不能和自己通信 # Prevent the "split brain" by configuring the majority of nodes (total number of master-eligible nodes / + ):
discovery.zen.minimum_master_nodes: # 为了避免脑裂,集群节点数最少为 半数+1 CestOS6没配置
# ----------------------------------- Memory -----------------------------------
#
# Lock the memory on startup: 把bootstrap自检程序关掉
#
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
######学习中修改下JVM的内存,默认是2G
[kris@hadoop101 config]$ vim jvm.options -Xms256m
-Xmx256m
修改linux配置
为什么要修改linux配置?
默认elasticsearch是单机访问模式,就是只能自己访问自己。
但是我们之后一定会设置成允许应用服务器通过网络方式访问。这时,elasticsearch就会因为嫌弃单机版的低端默认配置而报错,甚至无法启动。
所以我们在这里就要把服务器的一些限制打开,能支持更多并发。
问题1:max file descriptors [] for elasticsearch process likely too low, increase to at least [] elasticsearch
原因:系统允许 Elasticsearch 打开的最大文件数需要修改成65536
解决:vi /etc/security/limits.conf
添加内容:
* soft nofile
* hard nofile
* soft nproc
* hard nproc 注意:“*” 不要省略掉 问题2:max number of threads [] for user [judy2] likely too low, increase to at least [] (CentOS7.x 不用改) 原因:允许最大进程数修该成4096
解决:vi /etc/security/limits.d/-nproc.conf
修改如下内容:
* soft nproc
#修改为
* soft nproc 问题3:max virtual memory areas vm.max_map_count [] likely too low, increase to at least [] (CentOS7.x 不用改)
原因:一个进程可以拥有的虚拟内存区域的数量。
解决:
在 /etc/sysctl.conf 文件最后添加一行
vm.max_map_count=
即可永久修改 把修改的linux配置记得分发到其他机器中;xsync xxx
重启linux
es天然就是集群状态。
1、把ES的安装包分发给其他两台机器
2、根据第一台机器的linux系统配置,修改其他两台机子
3、在三台机器能够独立启动的情况下,修改/etc/elasticsearch/elasticsearch.yml
设置新主机的“报道中心”就行了
1 node-xx
2 network-host hadoop1
还要记得把 三台主机的node.name改成各自的
检查集群是否正确启动
http://192.168.1.101:9200/_cat/nodes?v
{"error":{"root_cause":[{"type":"master_not_discovered_exception","reason":null}],"type":"master_not_discovered_exception","reason":null},"status":503}
http://192.168.1.101:9200/
http://192.168.1.101:9200/_cat/nodes?v
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
192.168.1.102 7 96 10 0.39 0.41 0.19 mdi * node-1
192.168.1.101 7 96 8 0.28 0.37 0.20 mdi - node-2
注意yml配置文件中key: value格式冒号后面要跟一个空格。否则程序会报错;
注意:如果data和logs地址设为elasticsearch中的data和logs,则要清空data和logs数据;建议新建一个其他的目录
IP设置为1.0有可能和1.1之间通信时选择不了master!换成1.101和1.102
2. ES集群管理工具Cerebro
可在windows环境下直接启动
cerebro-0.8.1\bin\cerebro.bat
输入地址登陆(登陆任何一个节点的IP都可以): http://192.168.1.101:9200
3. 集群操作原理
集群:
一个节点(node)就是一个Elasticsearch实例,而一个集群(cluster)由一个或多个节点组成,它们具有相同的cluster.name,它们协同工作,分享数据和负载。
当加入新的节点或者删除一个节点时,集群就会感知到并平衡数据。
集群节点
1、集群中一个节点会被选举为主节点(master)
2、临时管理集群级别的一些变更,例如新建或删除索引、增加或移除节点等。
3、主节点不参与文档级别的变更或搜索,这意味着在流量增长的时候,该主节点不会成为集群的瓶颈。
4、任何节点都可以成为主节点。
5、用户,我们能够与集群中的任何节点通信,包括主节点。
6、每一个节点都知道文档存在于哪个节点上,它们可以转发请求到相应的节点上。
7、我们访问的节点负责收集各节点返回的数据,最后一起返回给客户端。这一切都由Elasticsearch处理。
集群健康状况
在Elasticsearch集群中可以监控统计很多信息,但是只有一个是最重要的:集群健康(cluster health)。集群健康有三种状态:green、yellow或red。
在一个没有索引的空集群中运行如上查询,将返回这些信息:
GET /_cluster/health 或者GET _cat/health?v
{
"cluster_name": "elasticsearch",
"status": "green",
"timed_out": false,
"number_of_nodes": ,
"number_of_data_nodes": ,
"active_primary_shards": ,
"active_shards": ,
"relocating_shards": ,
"initializing_shards": ,
"unassigned_shards":
}
status字段提供一个综合的指标来表示集群的的服务状况。三种颜色各自的含义:
颜色 意义
green 所有主要分片和复制分片都可用; 都得保证每个索引都得有副本;GET _cat/indices?v 查看索引的状况
比如3台机器中,r0(r2的副本)、 r1(r0的副本)、 r2(r1的副本)主要数据,如果r2机器宕了,它的副本还在,容错性提高,这样子情况下就是green状态;
yellow 所有主要分片可用,但不是所有复制分片都可用,至少是副本不足; 默认副本数replication是一个;
GET _cat/shards/索引名称 ;yellow是主片都还在,但是副本缺失,只有一份数据;(缺失副本有可能磁盘空间不足了:df -h) red 不是所有的主要分片都可用
集群分片
p0(r1、r2)| p1(r0、r2)| p3(r0、r2),p0、p1和p3是一份数据拆分成了3片存储到3台机器中(负载均衡),如果一个分片有两个副本,那么任何一个机器宕了,都可以正常使用,提高了容错性!!计算的时候跟mr有点相似,先把每个片中的数据全算完了之后,再去找台机器做合并,合并之后再给用户;(好处三个分片可以同时进行计算,并行度提高)
索引只是一个用来指向一个或多个分片(shards)的“逻辑命名空间(logical namespace)”.
分片(shard)是一个最小级别“工作单元(worker unit)”,它只是保存了索引中所有数据的一部分,是一个Lucene实例,并且它本身就是一个完整的搜索引擎。我们的文档存储在分片中,并且在分片中被索引,但是我们的应用程序不会直接与它们通信,取而代之的是,直接与索引通信。
分片是Elasticsearch在集群中分发数据的关键。把分片想象成数据的容器。文档存储在分片中,然后分片分配到你集群中的节点上。当你的集群扩容或缩小,Elasticsearch将会自动在你的节点间迁移分片,以使集群保持平衡。
1、主分片
索引中的每个文档属于一个单独的主分片,所以主分片的数量决定了索引最多能存储多少数据。
理论上主分片能存储的数据大小是没有限制的,限制取决于你实际的使用情况。分片的最大容量完全取决于你的使用状况:硬件存储的大小、文档的大小和复杂度、如何索引和查询你的文档,以及你期望的响应时间。
2、副分片
副分片只是主分片的一个副本,它可以防止硬件故障导致的数据丢失,同时可以提供读请求,比如搜索或者从别的shard取回文档。
当索引创建完成的时候,主分片的数量就固定了,但是副分片的数量可以随时调整。
只能增加副分片,不能增加主分片
创建分片:
PUT /blogs
{
"settings" : {
"number_of_shards" : ,
"number_of_replicas" :
}
} 增加副分片:
PUT /blogs/_settings
{
"number_of_replicas" :
}
集群的健康状态yellow表示所有的主分片(primary shards)启动并且正常运行了——集群已经可以正常处理任何请求——但是复制分片(replica shards)还没有全部可用。事实上所有的三个复制分片现在都是unassigned状态——它们还未被分配给节点。在同一个节点上保存相同的数据副本是没有必要的,如果这个节点故障了,那所有的数据副本也会丢失。
主节点:
临时管理集群级别,不参与文档级别的变更
自动选举主节点, 用户访问主节点,主节点再去分配让它去哪个节点
主节点相当于路由功能,负载平衡
创建索点击页面中的more-->:
①
name: my_cluster
number of shards:
number of replicas:
主分片2(实心-主分片和空心-副分片),副本2
(2个节点(nodes),2个主分片(shards),2个副本(replicas),集群中一共8个分片(shards))
开辟内存空间,把索引分成1和0两个分片; 每一个主分片中都有两个2分,两个副分片不可用,就报黄色
*(1主+2个副本),一个主只需一个副本即可,另外一个不需要unassigned shards; 两个nodes即2个副本不可用就会报黄色预警; 可添加一个机器,比如可加到0分片上; 副本分片,保证了集群的高可用,
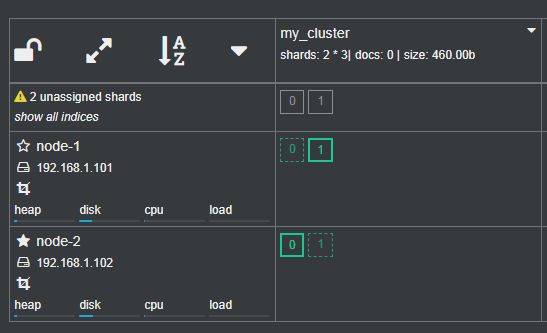
②
分片依赖于索引
name: my-es
number of shards:
number of replicas:
3个主分片,每个节点包含3个不同的分片

③
--> (黄色预警)
name: mycluster2
number of shards:
number of replicas:
给它设置为1个副分片就变成green了;
PUT /mycluster2/_settings
{
"number_of_replicas":
}
---->
{
"acknowledged": true
}
④ -->6个分片,1个主分片只能有1个副本
一共12个节点;增加了节点的存储量,再添加副本加进去就没意义了;
故障转移
在单一节点上运行意味着有单点故障的风险——没有数据备份。幸运的是,要防止单点故障,我们唯一需要做的就是启动另一个节点。
第二个节点已经加入集群,三个复制分片(replica shards)也已经被分配了——分别对应三个主分片,这意味着在丢失任意一个节点的情况下依旧可以保证数据的完整性。
文档的索引将首先被存储在主分片中,然后并发复制到对应的复制节点上。这可以确保我们的数据在主节点和复制节点上都可以被检索。
集群操作原理
路由
当你索引一个文档,它被存储在单独一个主分片上。Elasticsearch是如何知道文档属于哪个分片的呢?当你创建一个新文档,它是如何知道是应该存储在分片1还是分片2上的呢?
进程不能是随机的,因为我们将来要检索文档。
算法决定:shard = hash(routing) % number_of_primary_shards
routing值是一个任意字符串,它默认是_id但也可以自定义。
为什么主分片的数量只能在创建索引时定义且不能修改?
如果主分片的数量在未来改变了,所有先前的路由值就失效了,文档也就永远找不到了。
所有的文档API(get、index、delete、bulk、update、mget)都接收一个routing参数,它用来自定义文档到分片的映射。自定义路由值可以确保所有相关文档——例如属于同一个人的文档——被保存在同一分片上。
操作数据节点工作流程
每个节点都有能力处理任意请求。每个节点都知道任意文档所在的节点,所以也可以将请求转发到需要的节点。
执行:先在主节点路由--->其他节点上(具体哪个节点由算法决定:routing是默认文档id) 算法: shard = hash(routing) % number_of_primary_shards主分片数,PUT的数据存储在哪个分片上也是这个算法决定;
主分片(数)如果修改了,之前存的路由表就都失效了;这个算法取余数,值变了路由表就会变,就会乱了;
新建、索引和删除请求都是写(write)操作,它们必须在主分片上成功完成才能复制到相关的复制分片上。
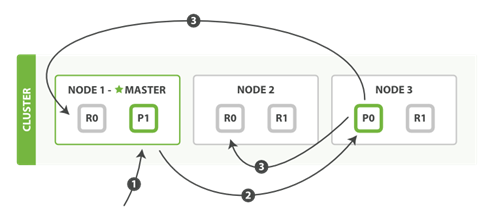
1. 客户端给Node 1发送新建、索引或删除请求。
2. 节点使用文档的_id确定文档属于分片0。它转发请求到Node 3,分片0位于这个节点上。
3. Node 3在主分片上执行请求,如果成功,它转发请求到相应的位于Node 1和Node 2的复制节点上。当所有的复制节点报告成功,Node 3报告成功到请求的节点,请求的节点再报告给客户端。
数据同步,R0 R0(P0的副本);并不是同步完之后才能查询;若同步失败,数据不一致了; 同步失败,会有超时时间,启动副本节点;异步操作(开线程)
replication
复制默认的值是sync。这将导致主分片得到复制分片的成功响应后才返回。
如果你设置replication为async,请求在主分片上被执行后就会返回给客户端。它依旧会转发请求给复制节点,但你将不知道复制节点成功与否。
上面的这个选项不建议使用。默认的sync复制允许Elasticsearch强制反馈传输。async复制可能会因为在不等待其它分片就绪的情况下发送过多的请求而使Elasticsearch过载。
检索流程
文档能够从主分片或任意一个复制分片被检索。(复制节点 也提供查询功能)
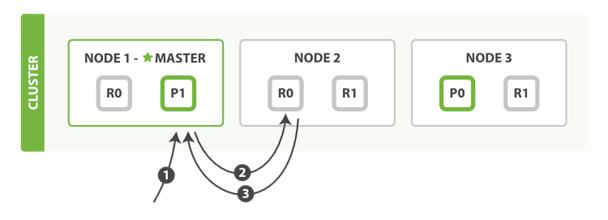
1. 客户端给Node 1发送get请求。
2. 节点使用文档的_id确定文档属于那个分片,主分片0对应的复制分片在三个节点上都有。此时,它转发请求到Node 2。
3. Node 2返回文档(document)给Node1主节点--->然后返回给客户端。
对于读请求,为了平衡负载,请求节点会为每个请求选择不同的分片——它会循环所有分片副本。
可能的情况是,一个被索引的文档已经存在于主分片上却还没来得及同步到复制分片上。这时复制分片会报告文档未找到,主分片会成功返回文档。一旦索引请求成功返回给用户,文档则在主分片和复制分片都是可用的。
若查询副本切片,它在两个不同分片上,两个复制分片会发给主分片,由主分片进行合并去响应客户端;
ES集群的更多相关文章
- ES 集群调整、升级 最佳实践
日常应用中我们会经常对es 集群做一些参数调整或者升级版本,但是每次关闭节点再打开 其中的数据同步的痛苦估计有很多人领悟过(有可能出现IO或者网络拥堵导致恶性循环)官网有套方案可以尝试一下: 1.关掉 ...
- windows单节点下安装es集群
linux下的es的tar包,拖到windows下,配置后,启动bin目录下的bat文件,也是可以正常运行的. 从linux下拷的tar包,需要修改虚拟机的内存elasticsearch.in.bat ...
- ES 集群上,业务单点如何优化升级?
摘要: 原创出处 https://www.bysocket.com 「公众号:泥瓦匠BYSocket 」欢迎关注和转载,保留摘要,谢谢! ES 基础 ES 集群 ES 集群上业务优化 一.ES 基础 ...
- es集群数据库~运维相关
一 数据同步方案 1 ES-JDBC 不能实现删除同步操作.MYSQL如果删除,ES不会删除 2 logstash-input-jdbc 能实现insert update,但是仍然不能实现删除 ...
- elasticsearch系列八:ES 集群管理(集群规划、集群搭建、集群管理)
一.集群规划 搭建一个集群我们需要考虑如下几个问题: 1. 我们需要多大规模的集群? 2. 集群中的节点角色如何分配? 3. 如何避免脑裂问题? 4. 索引应该设置多少个分片? 5. 分片应该设置几个 ...
- elasticsearch(es) 集群恢复触发配置(Local Gateway参数)
elasticsearch(es) 集群恢复触发配置(Local Gateway) 当你集群重启时,几个配置项影响你的分片恢复的表现. 首先,我们需要明白如果什么也没配置将会发生什么. 想象一下假设你 ...
- docker 快速部署ES集群 spark集群
1) 拉下来 ES集群 spark集群 两套快速部署环境, 并只用docker跑起来,并保存到私库. 2)弄清楚怎么样打包 linux镜像(或者说制作). 3)试着改一下,让它们跑在集群里面. 4) ...
- Elasticsearch-6.7.0系列(二)ES集群安装与验证
准备3台centos7机器/虚拟机,每台都安装上elasticsearch6.7.0 ,安装过程参考我的另一篇博客<Elasticsearch-6.7.0系列(一)9200端口 .tar.gz版 ...
- elk中es集群web管理工具cerebro
cerebo是kopf在es5上的替代者 安装es虽然不能再root下运行,但是cerebro 可以 run as root is ok wget https://github.com/lmeneze ...
随机推荐
- 排查linux系统是否被入侵
在日常繁琐的运维工作中,对linux服务器进行安全检查是一个非常重要的环节.今天,分享一下如何检查linux系统是否遭受了入侵? 一.是否入侵检查 1)检查系统日志 检查系统错误登陆日志,统计IP重试 ...
- python-异常处理、元类
一.异常处理 1.异常处理介绍: 异常是错误发生的信号,一旦程序出错就会产生一个异常,如果该异常没有被应用程序处理,那么该异常就会被抛出来,程序执行随之停止 2.异常通常包含三个部分 1.traceb ...
- 移动端判断ios还是android终端
<script> //判断ios还是android终端 var u = navigator.userAgent; var isAndroid = u.indexOf ...
- 处理数据库 Ora-00845: memory_traget not supported on this system 的错误
问题出现情况:在数据库启动的时候:如果出现如下图的错误: 查看官方文档: 处理操作步骤: [oracle@localhost orcl]$ su - root Password: [root@loca ...
- Confluence 6 使用主题
主题是被用来修改 Confluence 站点或空间的外观的. Confluence 安装了一个单一的默认主题,或者你也可以下载和安装其他的主题.你可以从 The Atlassian Marketpla ...
- django 中自带的加密方法
导入django 自带的加密算法 和flask中的哈希加密有一曲同工之妙. from django.contrib.auth.hashers import make_password, ...
- flask 初学1
py 文件中 from flask import Flask,redirect,request,url_for,jsonifyfrom Flask_5.config import Config fro ...
- 反向找related_name以及limit_fields_to
问题2:客户的添加页面,通过popup创建用户时 解决方案: 如果新创建的用户时:如果是销售部的人,页面才增加 目的是:拿到limit_choices_to,就可以判断了 当有两个Foreignkey ...
- 【linux】centos6.9通过virtualenv安装python3.5
参考:http://www.linuxidc.com/Linux/2015-08/121352.htm wget https://www.python.org/ftp/python/3.5.4/Pyt ...
- hiho1460 rmq模板题
好久没做rmq的题了,今天写了一遍,感觉打表有点像区间dp /* 给定长为n的字符串,要求在字符串中选择k个字符, 选择的子系列字典序最小 因为选择k个字符,那么就是去掉n-k个字符 那么[1,n-k ...