scrapy之五大核心组件
scrapy之五大核心组件
scrapy一共有五大核心组件,分别为引擎、下载器、调度器、spider(爬虫文件)、管道。
爬虫文件的作用:
a. 解析数据
b. 发请求
调度器:
a. 队列
队列是一种数据结构,拥有先进先出的特性。
b. 过滤器
过滤器适用于过滤的,过滤重复的请求。
调度器是用来调度请求对象的。
引擎:
所有的实例化的过程都是由引擎来做的,根据那到的数据流进行判断实例化的时间。
处理流数据
触发事物
scrapy五大核心组件之间的工作流程:
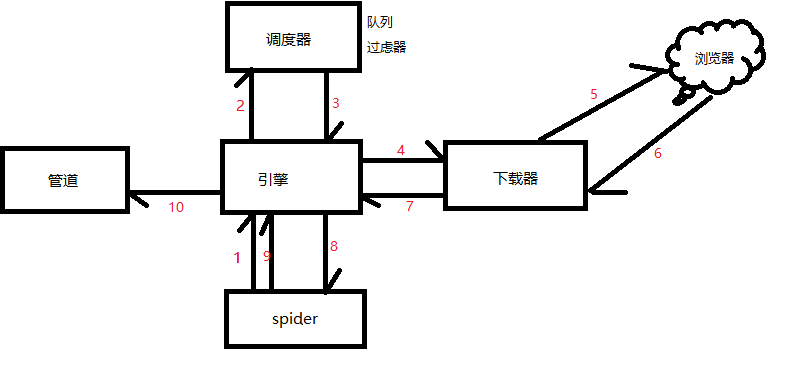
scrapy框架得的五大组件之间的工作流程上图所示:
当我们执行爬虫文件的时候,这五大组件就已经开始工作了 。其中,
1 首先,我们最原始的起始url是在我们爬虫文件中的,通常情况系,起始的url只有一个,当我们的爬虫文件执行的时候,首先对起始url发送请求,将起始url封装成了请求对象,将请求对象传递给了引擎,引擎就收到了爬虫文件给它发送的封装了起始URL的请求对象。我们在爬虫文件中发送的请求并没有拿到响应(没有马上拿到响应),只有请求发送到服务器端,服务器端返回响应,才能拿到响应。
2 引擎拿到这个请求对象以后,又将请求对象发送给了调度器,队列接受到的请求都放到了队列当中,队列中可能存在多个请求对象,然后通过过滤器,去掉重复的请求
3 调度器将过滤后的请求对象发送给了引擎,
4 引擎将拿到的请求对象给了下载器
5 下载器拿到请求后将请求拿到互联网进行数据下载
6 互联网将下载好的数据发送给下载器,此时下载好的数据是封装在响应对象中的
7 下载器将响应对象发送给引擎,引擎接收到了响应对象,此时引擎中存储了从互联网中下载的数据。
8 最终,这个响应对象又由引擎给了spider(爬虫文件),由parse方法中的response对象来接收,然后再parse方法中进行解析数据,此时可能解析到新的url,然后再次发请求;也可能解析到相关的数据,然后将数据进行封装得到item,
9 spider将item发送给引擎,
10 引擎将item发送给管道。
其中,在引擎和下载中间还有一个下载器中间件,spider和引擎中间有爬虫中间件,
下载器中间件
可以拦截请求和响应对象,请求和响应交互的时候一定会经过下载中间件,可以处理请求和响应。
爬虫中间件
拦截请求和响应,对请求和响应进行处理。
0
scrapy之五大核心组件的更多相关文章
- python爬虫---scrapy框架爬取图片,scrapy手动发送请求,发送post请求,提升爬取效率,请求传参(meta),五大核心组件,中间件
# settings 配置 UA USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, l ...
- Scrapy 框架 安装 五大核心组件 settings 配置 管道存储
scrapy 框架的使用 博客: https://www.cnblogs.com/bobo-zhang/p/10561617.html 安装: pip install wheel 下载 Twisted ...
- scrapy框架post请求发送,五大核心组件,日志等级,请求传参
一.post请求发送 - 问题:爬虫文件的代码中,我们从来没有手动的对start_urls列表中存储的起始url进行过请求的发送,但是起始url的确是进行了请求的发送,那这是如何实现的呢? - 解答: ...
- scrapy 五大核心组件-分页
scrapy 五大核心组件-分页 分页 思路 总的原理和之前是一样的,但是由于框架的原因,要遵循他框架的使用方式,每次更改他的url,并指定回调函数 # -*- coding: utf-8 -*- i ...
- Scrapy五大核心组件工作流程
一.Scrapy五大核心组件工作流程 1.核心组件 # 引擎(Scrapy) 对整个系统的数据流进行处理, 触发事务(框架核心). # 调度器(Scheduler) 用来接受引擎发过来的请求. 由过滤 ...
- scrapy五大核心组件和中间件以及UA池和代理池
五大核心组件的工作流程 引擎(Scrapy) 用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler) 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. ...
- Scrapy五大核心组件简介
五大核心组件 scrapy框架主要由五大组件组成,他们分别是调度器(Scheduler),下载器(Downloader),爬虫(Spider),和实体管道(Item Pipeline),Scrapy引 ...
- scrapy五大核心组件
scrapy五大核心组件 引擎(Scrapy)用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler)用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. ...
- Spring MVC(一)五大核心组件和配置
一,五大核心组件 1.DispatcherServlet 请求入口 2.HandlerMapping 请求派发,负责请求和控制器建立一一对应的关系 3.Controller 处理器 4.Mod ...
随机推荐
- no plugin found for prefix 'tomcat 7' in the current project and in the plugin groups的解决方法
解决方法一: 找到这个settings.xml文件,进行编辑,在pluginGroups标签下加入下面的配置 <pluginGroups><pluginGroup>org.ap ...
- php伪协议,利用文件包含漏洞
php支持多种封装协议,这些协议常被CTF出题中与文件包含漏洞结合,这里做个小总结.实验用的是DVWA平台,low级别,phpstudy中的设置为5.4.45版本, 设置allow_url_fopen ...
- June 6. 2018 Week 23rd Wednesday
You are confined only by the walls you build yourself. 限制你的只有你自己筑起的墙. From Andrew Murphy. Let's repe ...
- 【Linux基础】Linux下软件包管理(rpm-deb-yast-yum)
软件包管理是指系统中一种安装和维护软件的方法.通常软件以包的形式存储在仓库(repository)中,能满足许多人所有需要的软件. 在GNU/Linux(以下简称Linux)操作系统中,RPM和DPK ...
- A. On The Way to Lucky Plaza 概率 乘法逆元
A. On The Way to Lucky Plaza time limit per test 1.0 s memory limit per test 256 MB input standard i ...
- B. Yet Another Array Partitioning Task ——cf
B. Yet Another Array Partitioning Task time limit per test 2 seconds memory limit per test 256 megab ...
- Netty中ByteBuf 的零拷贝
转载:https://www.jianshu.com/p/1d1fa2fe1ed9 此文章已同步发布在我的 segmentfault 专栏. 根据 Wiki 对 Zero-copy 的定义: &quo ...
- Linux平台上轻松安装与配置Domino
Linux平台上轻松安装与配置Domino Domino Server的编译安装过程中需要用到libstdc++-2.9和glibc-2.1.1(或者其更高的版本)两个编译模块,它们是Linux开发编 ...
- Android自动登录功能的实现
登陆页面布局设计: <LinearLayout android:layout_width="wrap_content" android:layout_height=" ...
- UVA1608-Non-boring sequences(分治)
Problem UVA1608-Non-boring sequences Accept: 227 Submit: 2541Time Limit: 3000 mSec Problem Descript ...