asyncio并发编程
一. 事件循环

1.注:
实现搭配:事件循环+回调(驱动生成器【协程】)+epoll(IO多路复用),asyncio是Python用于解决异步编程的一整套解决方案;
基于asynico:tornado,gevent,twisted(Scrapy,django channels),tornado(实现了web服务器,可以直接部署,真正部署还是要加nginx),django,flask(uwsgi,gunicorn+nginx部署)
import asyncio
import time
async def get_html(url):
print('start get url')
#不能直接使用time.sleep,这是阻塞的函数,如果使用time在并发的情况有多少个就有多少个2秒
await asyncio.sleep(2)
print('end get url')
if __name__=='__main__':
start_time=time.time()
loop=asyncio.get_event_loop()
task=[get_html('www.baidu.com') for i in range(10)]
loop.run_until_complete(asyncio.wait(task))
print(time.time()-start_time)
2.如何获取协程的返回值(和线程池类似):
import asyncio
import time
from functools import partial
async def get_html(url):
print('start get url')
await asyncio.sleep(2)
print('end get url')
return "HAHA"
#需要接收task,如果要接收其他的参数就需要用到partial(偏函数),参数需要放到前面
def callback(url,future):
print(url+' success')
print('send email')
if __name__=='__main__':
loop=asyncio.get_event_loop()
task=loop.create_task(get_html('www.baidu.com'))
#原理还是获取event_loop,然后调用create_task方法,一个线程只有一个loop
# get_future=asyncio.ensure_future(get_html('www.baidu.com'))也可以
#loop.run_until_complete(get_future)
#run_until_complete可以接收future类型,task类型(是future类型的一个子类),也可以接收可迭代类型
task.add_done_callback(partial(callback,'www.baidu.com'))
loop.run_until_complete(task)
print(task.result())
3.wait和gather的区别:
3.1wait简单使用:
import asyncio
import time
from functools import partial
async def get_html(url):
print('start get url')
await asyncio.sleep(2)
print('end get url') if __name__=='__main__':
loop=asyncio.get_event_loop()
tasks=[get_html('www.baidu.com') for i in range(10)]
#wait和线程的wait相似
loop.run_until_complete(asyncio.wait(tasks))
协程的wait和线程的wait相似,也有timeout,return_when(什么时候返回)等参数
3.2gather简单使用:
import asyncio
import time
from functools import partial
async def get_html(url):
print('start get url')
await asyncio.sleep(2)
print('end get url') if __name__=='__main__':
loop=asyncio.get_event_loop()
tasks=[get_html('www.baidu.com') for i in range(10)]
#gather注意加*,这样就会变成参数
loop.run_until_complete(asyncio.gather(*tasks))
3.3gather和wait的区别:(定制性不强时可以优先考虑gather)
gather更加高层,可以将tasks分组;还可以成批的取消任务
import asyncio
import time
from functools import partial
async def get_html(url):
print('start get url')
await asyncio.sleep(2)
print('end get url') if __name__=='__main__':
loop=asyncio.get_event_loop()
groups1=[get_html('www.baidu.com') for i in range(10)]
groups2=[get_html('www.baidu.com') for i in range(10)]
#gather注意加*,这样就会变成参数
loop.run_until_complete(asyncio.gather(*groups1,*groups2))
#这种方式也可以
# groups1 = [get_html('www.baidu.com') for i in range(10)]
# groups2 = [get_html('www.baidu.com') for i in range(10)]
# groups1=asyncio.gather(*groups1)
# groups2=asyncio.gather(*groups2)
#取消任务
# groups2.cancel()
# loop.run_until_complete(asyncio.gather(groups1,groups2))
二. 协程嵌套
1.run_util_complete()源码:和run_forever()区别并不大,只是可以在运行完指定的协程后可以把loop停止掉,而run_forever()不会停止
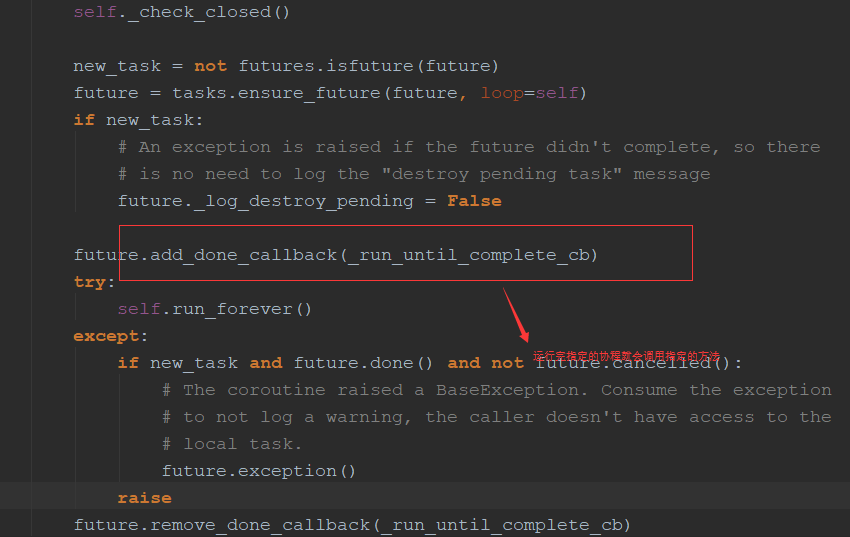

2.loop会被放在future里面,future又会放在loop中
3.取消future(task):
3.1子协程调用原理:
官网例子:

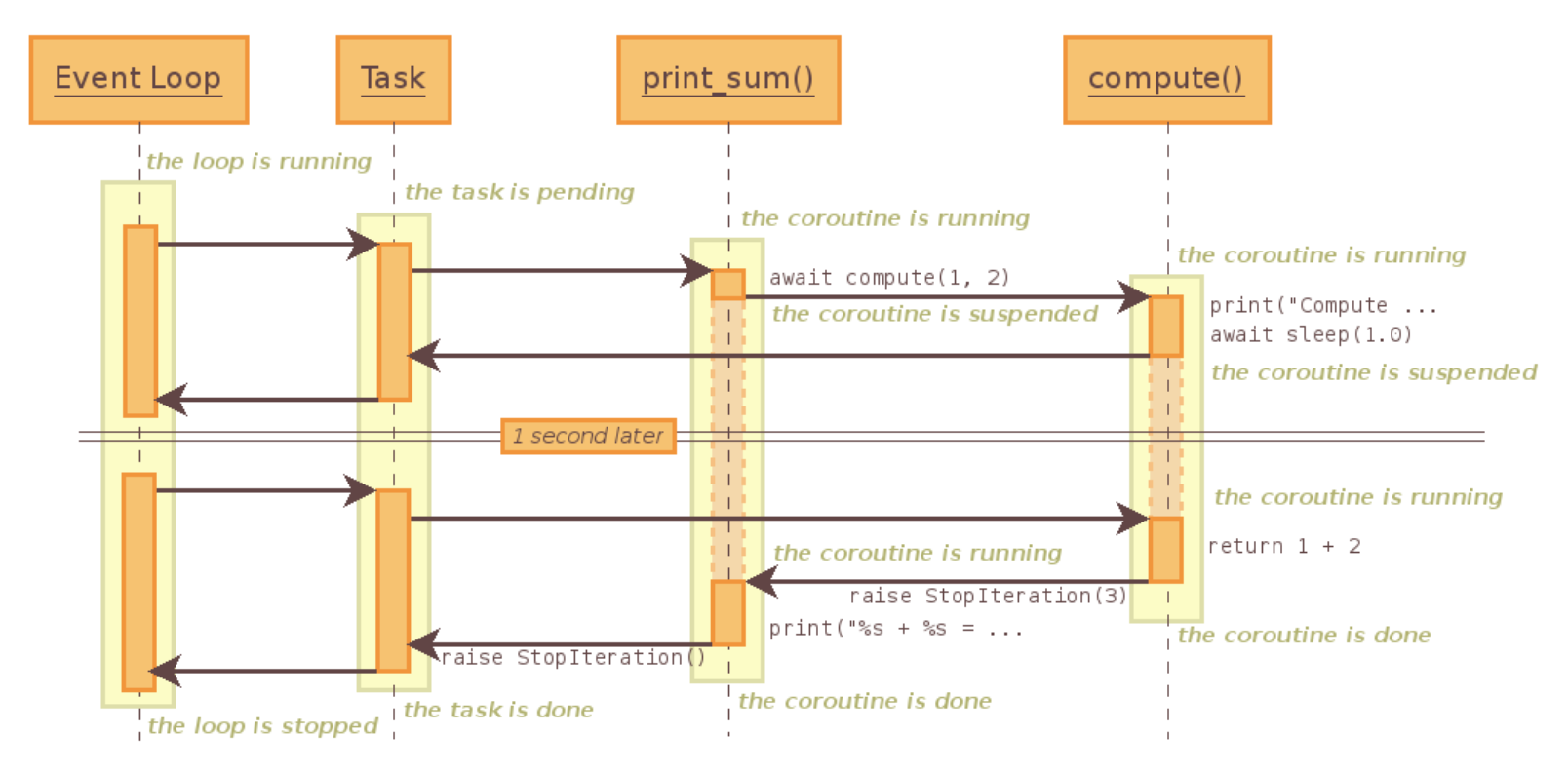
解释: await相当于yield from,loop运行协程print_sum(),print_sum又会去调用另一个协程compute,run_util_complete会把协程print_sum注册到loop中。
1.event_loop会为print_sum创建一个task,通过驱动task执行print_sum(task首先会进入pending【等待】的状态);
2.print_sum直接进入字协程的调度,这个时候转向执行另一个协程(compute,所以print_sum变为suspended【暂停】状态);
3.compute这个协程首先打印,然后去调用asyncio的sleep(此时compute进入suspende的状态【暂停】),直接把返回值返回给Task(没有经过print_sum,相当于yield from,直接在调用方和子生成器通信,是由委托方print_sum建立的通道);
4.Task会告诉Event_loop暂停,Event_loop等待一秒后,通过Task唤醒(越过print_sum和compute建立一个通道);
5.compute继续执行,变为状态done【执行完成】,然后抛一个StopIteration的异常,会被await语句捕捉到,然后提取出1+2=3的值,进入print_sum,print_sum也被激活(因为抛出了StopIteration的异常被print_sum捕捉),print_sum执行完也会被标记为done的状态,同时抛出StopIteration会被Task接收
三. call_soon、call_later、call_at、call_soon_threadsafe
1.call_soon:可以直接接收函数,而不用协程
import asyncio
#函数
def callback(sleep_time):
print('sleep {} success'.format(sleep_time))
#通过该函数暂停
def stoploop(loop):
loop.stop()
if __name__=='__main__':
loop=asyncio.get_event_loop()
#可以直接传递函数,而不用协程,call_soon其实就是调用的call_later,时间为0秒
loop.call_soon(callback,2)
loop.call_soon(stoploop,loop)
#不能用run_util_complete(因为不是协程),run_forever找到call_soon一直运行
loop.run_forever()
2.call_later:可以指定多长时间后启动(实际调用call_at,时间不是传统的时间,而是loop内部的时间)
import asyncio
#函数
def callback(sleep_time):
print('sleep {} success'.format(sleep_time))
#通过该函数暂停
def stoploop(loop):
loop.stop()
if __name__=='__main__':
loop=asyncio.get_event_loop()
loop.call_later(3,callback,1)
loop.call_later(1, callback, 2)
loop.call_later(1, callback, 2)
loop.call_later(1, callback, 2)
loop.call_soon(callback,4)
# loop.call_soon(stoploop,loop)
#不能用run_util_complete(因为不是协程),run_forever找到call_soon一直运行
loop.run_forever()
3.call_at:指定某个时间执行
import asyncio
#函数
def callback(sleep_time):
print('sleep {} success'.format(sleep_time))
#通过该函数暂停
def stoploop(loop):
loop.stop()
if __name__=='__main__':
loop=asyncio.get_event_loop()
now=loop.time()
print(now)
loop.call_at(now+3,callback,1)
loop.call_at(now+1, callback, 0.5)
loop.call_at(now+1, callback, 2)
loop.call_at(now+1, callback, 2)
# loop.call_soon(stoploop,loop)
#不能用run_util_complete(因为不是协程),run_forever找到call_soon一直运行
loop.run_forever()
4.call_soon_threadsafe:
线程安全的方法,不仅能解决协程,也能解决线程,进程,和call_soon几乎一致,多了self._write_to_self(),和call_soon用法一致
四. ThreadPoolExecutor+asyncio(线程池和协程结合)
1.使用run_in_executor:就是把阻塞的代码放进线程池运行,性能并不是特别高,和多线程差不多
#使用多线程,在协程中集成阻塞io
import asyncio
import socket
from urllib.parse import urlparse
from concurrent.futures import ThreadPoolExecutor
import time
def get_url(url):
#通过socket请求html
url=urlparse(url)
host=url.netloc
path=url.path
if path=="":
path="/"
#建立socket连接
client=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
client.connect((host,80))
#向服务器发送数据
client.send("GET {} HTTP/1.1\r\nHost:{}\r\nConnection:close\r\n\r\n".format(path, host).encode("utf8"))
#将数据读取完
data=b""
while True:
d=client.recv(1024)
if d:
data+=d
else:
break
#会将header信息作为返回字符串
data=data.decode('utf8')
print(data.split('\r\n\r\n')[1])
client.close() if __name__=='__main__':
start_time=time.time()
loop=asyncio.get_event_loop()
excutor=ThreadPoolExecutor()
tasks=[]
for i in range(20):
task=loop.run_in_executor(excutor,get_url,'http://www.baidu.com')
tasks.append(task)
loop.run_until_complete(asyncio.wait(tasks))
print(time.time()-start_time)
五. asyncio模拟http请求
注:asyncio目前没有提供http协议的接口
# asyncio目前没有提供http协议的接口
import asyncio
from urllib.parse import urlparse
import time async def get_url(url):
# 通过socket请求html
url = urlparse(url)
host = url.netloc
path = url.path
if path == "":
path = "/"
# 建立socket连接(比较耗时),非阻塞需要注册,都在open_connection中实现了
reader, writer = await asyncio.open_connection(host, 80)
# 向服务器发送数据,unregister和register都实现了
writer.write("GET {} HTTP/1.1\r\nHost:{}\r\nConnection:close\r\n\r\n".format(path, host).encode("utf8"))
# 读取数据
all_lines = []
# 源码实现较复杂,有__anext__的魔法函数(协程)
async for line in reader:
data = line.decode('utf8')
all_lines.append(data)
html = '\n'.join(all_lines)
return html async def main():
tasks = []
for i in range(20):
url = "http://www.baidu.com/"
tasks.append(asyncio.ensure_future(get_url(url)))
for task in asyncio.as_completed(tasks):
result = await task
print(result) if __name__ == '__main__':
start_time = time.time()
loop = asyncio.get_event_loop()
# tasks=[get_url('http://www.baidu.com') for i in range(10)]
# 在外部获取结果,保存为future对象
# tasks = [asyncio.ensure_future(get_url('http://www.baidu.com')) for i in range(10)]
# loop.run_until_complete(asyncio.wait(tasks))
# for task in tasks:
# print(task.result())
# 执行完一个打印一个
loop.run_until_complete(main())
print(time.time() - start_time)
六. future和task
1.future:协程中的future和线程池中的future相似

future中的方法,都和线程池中的相似
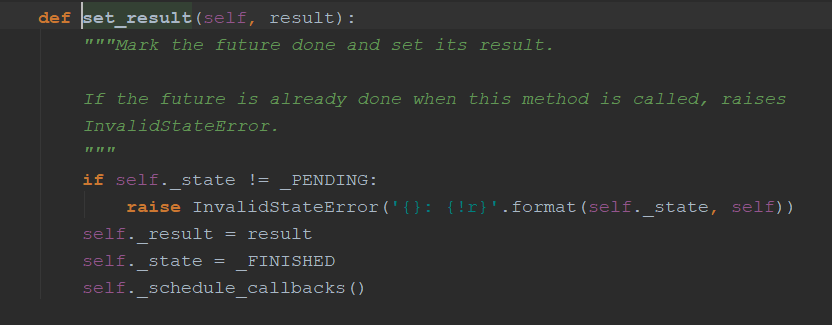
set_result方法
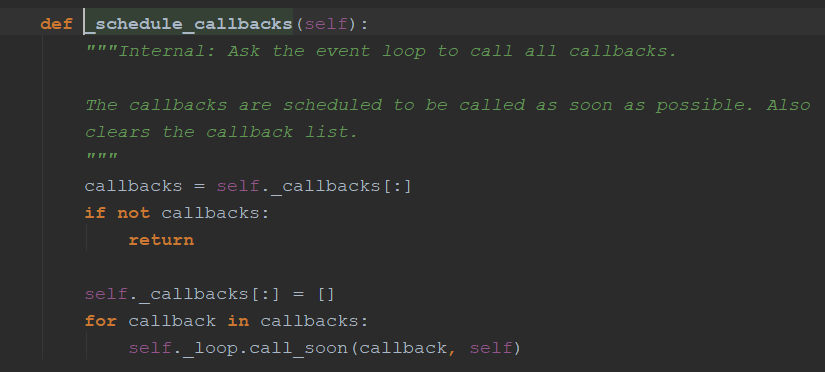
不像线程池中运行完直接运行代码(这是单线程的,会调用call_soon方法)
2.task:是future的子类,是future和协程之间的桥梁
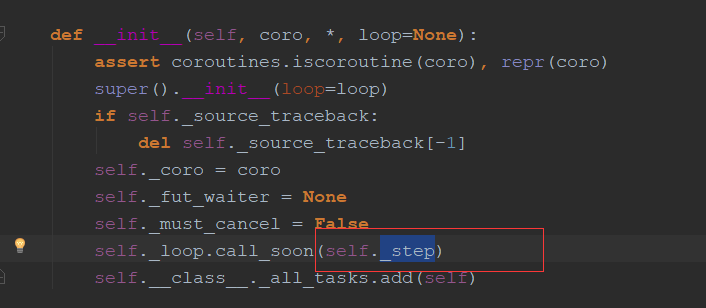
会首先启动_step方法

该方法会首先启动协程,把返回值(StopIteration的值)做处理,用于解决协程和线程不一致的地方
七. asyncio同步和通信
1.单线程协程不需要锁:
import asyncio
total=0
async def add():
global total
for i in range(1000000):
total+=1 async def decs():
global total
for i in range(1000000):
total-=1
if __name__=='__main__':
loop=asyncio.get_event_loop()
tasks=[add(),decs()]
loop.run_until_complete(asyncio.wait(tasks))
print(total)
2.某种情况需要锁:
asyncio中的锁(同步机制)
import asyncio,aiohttp
#这是并没有调用系统的锁,只是简单的自己实现(注意是非阻塞的),Queue也是非阻塞的,都用了yield from,不用用到condition【单线程】】
#Queue还可以限流,如果只需要通信还可以直接使用全局变量否则可以
from asyncio import Lock,Queue
catche={}
lock=Lock()
async def get_stuff():
#实现了__enter__和__exit__两个魔法函数,可以用with
# with await lock:
#更明确的语法__aenter__和__await__
async with lock:
#注意加await,是一个协程
#await lock.acquire()
for url in catche:
return catche[url]
#异步的接收
stauff=aiohttp.request('Get',url)
catche[url]=stauff
return stauff
#release是一个简单的函数
#lock.release() async def parse_stuff():
stuff=await get_stuff() async def use_stuff():
stuff=await get_stuff()
#如果没有同步机制,就会发起两次请求(这里就可以加一个同步机制)
tasks=[parse_stuff(),use_stuff()]
loop=asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
八. aiohttp实现高并发爬虫
# asyncio去重url,入库(异步的驱动aiomysql)
import aiohttp
import asyncio
import re
import aiomysql
from pyquery import pyquery start_url = 'http://www.jobbole.com/'
waiting_urls = []
seen_urls = []
stopping = False
#限制并发数
sem=asyncio.Semaphore(3) async def fetch(url, session):
async with sem:
await asyncio.sleep(1)
try:
async with session.get(url) as resp:
print('url_status:{}'.format(resp.status))
if resp.status in [200, 201]:
data = await resp.text()
return data
except Exception as e:
print(e) def extract_urls(html):
'''
解析无io操作
'''
urls = []
pq = pyquery(html)
for link in pq.items('a'):
url = link.attr('href')
if url and url.startwith('http') and url not in urls:
urls.append(url)
waiting_urls.append(url)
return urls async def init_urls(url, session):
html = await fetch(url, session)
seen_urls.add(url)
extract_urls(html) async def handle_article(url, session, pool):
'''
处理文章
'''
html = await fetch(url, session)
seen_urls.append(url)
extract_urls(html)
pq = pyquery(html)
title = pq('title').text()
async with pool.acquire() as conn:
async with conn.cursor() as cur:
insert_sql = "insert into Test(title) values('{}')".format(title)
await cur.execute(insert_sql) async def consumer(pool):
with aiohttp.CLientSession() as session:
while not stopping:
if len(waiting_urls) == 0:
await asyncio.sleep(0.5)
continue
url = waiting_urls.pop()
print('start url:' + 'url')
if re.match('http://.*?jobble.com/\d+/', url):
if url not in seen_urls:
asyncio.ensure_future(handle_article(url, session, pool))
await asyncio.sleep(30)
else:
if url not in seen_urls:
asyncio.ensure_future(init_urls(url, session)) async def main():
# 等待mysql连接好
pool = aiomysql.connect(host='localhost', port=3306, user='root',
password='', db='my_aio', loop=loop, charset='utf8', autocommit=True)
async with aiohttp.CLientSession() as session:
html = await fetch(start_url, session)
seen_urls.add(start_url)
extract_urls(html)
asyncio.ensure_future(consumer(pool)) if __name__ == '__main__':
loop = asyncio.get_event_loop()
asyncio.ensure_future(loop)
loop.run_forever(main(loop))
asyncio并发编程的更多相关文章
- gj13 asyncio并发编程
13.1 事件循环 asyncio 包含各种特定系统实现的模块化事件循环 传输和协议抽象 对TCP.UDP.SSL.子进程.延时调用以及其他的具体支持 模仿futures模块但适用于事件循环使用的Fu ...
- Python进阶:多线程、多进程和线程池编程/协程和异步io/asyncio并发编程
gil: gil使得同一个时刻只有一个线程在一个CPU上执行字节码,无法将多个线程映射到多个CPU上执行 gil会根据执行的字节码行数以及时间片释放gil,gil在遇到io的操作时候主动释放 thre ...
- Python高级编程和异步IO并发编程
第1章 课程简介介绍如何配置系统的开发环境以及如何加入github私人仓库获取最新源码. 1-1 导学 试看 1-2 开发环境配置 1-3 资源获取方式第2章 python中一切皆对象本章节首先对比静 ...
- Python并发编程之初识异步IO框架:asyncio 上篇(九)
大家好,并发编程 进入第九篇. 通过前两节的铺垫(关于协程的使用),今天我们终于可以来介绍我们整个系列的重点 -- asyncio. asyncio是Python 3.4版本引入的标准库,直接内置了对 ...
- Python并发编程之实战异步IO框架:asyncio 下篇(十一)
大家好,并发编程 进入第十一章. 前面两节,我们讲了协程中的单任务和多任务 这节我们将通过一个小实战,来对这些内容进行巩固. 在实战中,将会用到以下知识点: 多线程的基本使用 Queue消息队列的使用 ...
- Python并发编程之学习异步IO框架:asyncio 中篇(十)
大家好,并发编程 进入第十章.好了,今天的内容其实还挺多的,我准备了三天,到今天才整理完毕.希望大家看完,有所收获的,能给小明一个赞.这就是对小明最大的鼓励了.为了更好地衔接这一节,我们先来回顾一下上 ...
- asyncio:python3未来并发编程主流、充满野心的模块
介绍 asyncio是Python在3.5中正式引入的标准库,这是Python未来的并发编程的主流,非常重要的一个模块.有一个web框架叫sanic,就是基于asyncio,语法和flask类似,使用 ...
- Python3 与 C# 并发编程之~ 协程篇
3.协程篇¶ 去年微信公众号就陆陆续续发布了,我一直以为博客也汇总同步了,这几天有朋友说一直没找到,遂发现,的确是漏了,所以补上一篇 在线预览:https://github.lesschina.c ...
- python 闯关之路四(上)(并发编程与数据库理论)
并发编程重点: 并发编程:线程.进程.队列.IO多路模型 操作系统工作原理介绍.线程.进程演化史.特点.区别.互斥锁.信号. 事件.join.GIL.进程间通信.管道.队列. 生产者消息者模型.异步模 ...
随机推荐
- D. Diverse Garland
题意:灯有三种颜色R,G,B.只要同一种颜色相邻就不可以.问最少需要换几次,可以使在一串灯中没有相邻灯的颜色相同. 思路:贪心思路:我们知道一个程序都是要子阶段,然后子阶段各个组合起来形成这个程序.那 ...
- 吴恩达课后作业学习2-week1-2正则化
参考:https://blog.csdn.net/u013733326/article/details/79847918 希望大家直接到上面的网址去查看代码,下面是本人的笔记 4.正则化 1)加载数据 ...
- 深蓝词库转换2.2发布,支持手心输入法和Win10微软拼音
距离上一次大版本的发布已经很久很久了,中间是不是会收到一些用户的来信,提出新的需求,于是只是做小版本的更新,终于积累了一些更新后,打算做个大版本的发布了. 深蓝词库转换是一个输入法的词库互转和生成软件 ...
- Feature Extractor[googlenet v1]
1 - V1 google团队在模型上,更多考虑的是实用性,也就是如何能让强大的深度学习模型能够用在嵌入式或者移动设备上.传统的想增强模型的方法无非就是深度和宽度,而如果简单的增加深度和宽度,那么带来 ...
- 深入理解Spring Boot数据源与连接池原理
Create by yster@foxmail.com 2018-8-2 一:开始 在使用Spring Boot数据源之前,我们一般会导入相关依赖.其中数据源核心依赖就是spring‐boot‐s ...
- 从高德采集最新的省市区三级坐标和行政区域边界,用js在浏览器中运行
本文描述的是对国家统计局于2019-01-31发布的<2018年统计用区划代码和城乡划分代码(截止2018年10月31日)>中省市区三级的坐标和行政区域边界的采集. 本文更新(移步查阅): ...
- Roslyn入门(二)-C#语义
先决条件 Visual Studio 2017 .NET Compiler Platform SDK Rosyln入门(一)-C#语法分析 简介 今天,Visual Basic和C#编译器是黑盒子:输 ...
- Redis中单机数据库的实现
1. 内存操作层 zmalloc 系接口 redis为了优化内存操作, 封装了一层内存操作接口. 默认情况下, 其底层实现就是最简朴的libc中的malloc系列接口. 如果有定制化需求, 可以通过配 ...
- 我去年码了个表(WPF MvvM)
又快个把月没写博客了(最近忙着学JAVA去了,都是被逼的/(ㄒoㄒ)/~~),然后用WPF码了个表,其实想加上那种提醒功能什么的,额,就这样了吧,主要是感受一下数据驱动的思想. 效果如下: 前端XAM ...
- H5 文字属性的缩写
05-文字属性的缩写 abc我是段落 <!DOCTYPE html> <html lang="en"> <head> <meta char ...