洗礼灵魂,修炼python(69)--爬虫篇—番外篇之feedparser模块
feedparser模块
1.简介
feedparser是一个Python的Feed解析库,可以处理RSS ,CDF,Atom 。使用它我们可从任何 RSS 或 Atom 订阅源得到标题、链接和文章的条目了。
RSS(Really Simple
Syndication,简易信息聚合):是一种描述和同步网站内容的格式你可以认为是一种定制个性化推送信息的服务。RSS 是用于分发 Web
站点上的内容的摘要的一种简单的 XML
格式它能够解决你漫无目的的浏览网页的问题。它的信息越是过剩,它的意义也越加彰显。网络中充斥着大量的信息垃圾,每天摄入了太多自己根本不关心的信息。让自己关注的信息主动来找自己,且这些信息都是用户自己所需要的,这就是RSS的意义
比如这个链接:http://feed.cnblogs.com/blog/sitehome/rss
打开得:

其实点个人博客主页的这里也可以:

不过点击去是个人的rss,里面全是个人的随笔或者文章:

2.方法/属性
feedparser是第三方库,需要pip或者easy_install安装,这些略过了
3.常用方法/属性解析
其他的方法都不用说了,基本上没用到,最常用的就是parse方法了
import feedparser
print(feedparser.parse('http://feed.cnblogs.com/blog/u/385429/rss'))
结果:
{'feed': {'title': '博客园_yangva', 'title_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '博客园_yangva'}, 'subtitle': '', 'subtitle_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': ''}, 'id': 'uuid:48bcc04f-645a-4725-a261-6d035a48dc1d;id=448', 'guidislink': True, 'link': 'uuid:48bcc04f-645a-4725-a261-6d035a48dc1d;id=448', 'updated': '2017-11-26T10:22:05Z', 'updated_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=26, tm_hour=10, tm_min=22, tm_sec=5, tm_wday=6, tm_yday=330, tm_isdst=0), 'authors': [{'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}], 'author_detail': {'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}, 'href': 'http://www.cnblogs.com/yangva/', 'author': 'yangva', 'generator_detail': {'name': 'feed.cnblogs.com'}, 'generator': 'feed.cnblogs.com'}, 'entries': [{'id': 'http://www.cnblogs.com/yangva/p/7811622.html', 'guidislink': True, 'link': 'http://www.cnblogs.com/yangva/p/7811622.html', 'title': '洗礼灵魂,修炼python(67)--爬虫篇—cookielib之爬取需要账户登录验证的网站 - yangva', 'title_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '洗礼灵魂,修炼python(67)--爬虫篇—cookielib之爬取需要账户登录验证的网站 - yangva'}, 'summary': '学完前面的教程,相信你已经能爬取大部分的网站信息了,但是当你爬的网站多了,你应该会发现一个新问题,有的网站需要登录账户才能看到更多的信息对吧?那么这种网站怎么爬取呢?这些登录数据就是今天要说的——cookie cookie 其实在前面在解析requests模块时也提到过的。 Cookie,指某些网站', 'summary_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '学完前面的教程,相信你已经能爬取大部分的网站信息了,但是当你爬的网站多了,你应该会发现一个新问题,有的网站需要登录账户才能看到更多的信息对吧?那么这种网站怎么爬取呢?这些登录数据就是今天要说的——cookie cookie 其实在前面在解析requests模块时也提到过的。 Cookie,指某些网站'}, 'published': '2017-11-23T10:19:00Z', 'published_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=23, tm_hour=10, tm_min=19, tm_sec=0, tm_wday=3, tm_yday=327, tm_isdst=0), 'updated': '2017-11-23T10:19:00Z', 'updated_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=23, tm_hour=10, tm_min=19, tm_sec=0, tm_wday=3, tm_yday=327, tm_isdst=0), 'authors': [{'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}], 'author_detail': {'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}, 'href': 'http://www.cnblogs.com/yangva/', 'author': 'yangva', 'links': [{'rel': 'alternate', 'href': 'http://www.cnblogs.com/yangva/p/7811622.html', 'type': 'text/html'}, {'rel': 'alternate', 'type': 'text/html', 'href': 'http://www.cnblogs.com/yangva/p/7811622.html'}], 'content': [{'type': 'text/html', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': "该文只有注册用户登录后才能阅读。<a href='http://www.cnblogs.com/yangva/p/7811622.html' target='_blank'>阅读全文</a>。"}]}, {'id': 'http://www.cnblogs.com/yangva/p/7814108.html', 'guidislink': True, 'link': 'http://www.cnblogs.com/yangva/p/7814108.html', 'title': '洗礼灵魂,修炼python(66)--爬虫篇—BeauitifulSoup进阶之“我让你忘记那个负心汉,有我就够了” - yangva', 'title_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '洗礼灵魂,修炼python(66)--爬虫篇—BeauitifulSoup进阶之“我让你忘记那个负心汉,有我就够了” - yangva'}, 'summary': '该文被密码保护。', 'summary_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '该文被密码保护。'}, 'published': '2017-11-10T10:39:00Z', 'published_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=10, tm_hour=10, tm_min=39, tm_sec=0, tm_wday=4, tm_yday=314, tm_isdst=0), 'updated': '2017-11-10T10:39:00Z', 'updated_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=10, tm_hour=10, tm_min=39, tm_sec=0, tm_wday=4, tm_yday=314, tm_isdst=0), 'authors': [{'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}], 'author_detail': {'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}, 'href': 'http://www.cnblogs.com/yangva/', 'author': 'yangva', 'links': [{'rel': 'alternate', 'href': 'http://www.cnblogs.com/yangva/p/7814108.html', 'type': 'text/html'}, {'rel': 'alternate', 'type': 'text/html', 'href': 'http://www.cnblogs.com/yangva/p/7814108.html'}], 'content': [{'type': 'text/html', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '该文被密码保护。'}]}, {'id': 'http://www.cnblogs.com/yangva/p/7805300.html', 'guidislink': True, 'link': 'http://www.cnblogs.com/yangva/p/7805300.html', 'title': '洗礼灵魂,修炼python(65)--爬虫篇—BeautifulSoup:“忘掉正则表达式吧,我拉车养你” - yangva', 'title_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '洗礼灵魂,修炼python(65)--爬虫篇—BeautifulSoup:“忘掉正则表达式吧,我拉车养你” - yangva'}, 'summary': '该文被密码保护。', 'summary_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '该文被密码保护。'}, 'published': '2017-11-10T04:25:00Z', 'published_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=10, tm_hour=4, tm_min=25, tm_sec=0, tm_wday=4, tm_yday=314, tm_isdst=0), 'updated': '2017-11-10T04:25:00Z', 'updated_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=10, tm_hour=4, tm_min=25, tm_sec=0, tm_wday=4, tm_yday=314, tm_isdst=0), 'authors': [{'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}], 'author_detail': {'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}, 'href': 'http://www.cnblogs.com/yangva/', 'author': 'yangva', 'links': [{'rel': 'alternate', 'href': 'http://www.cnblogs.com/yangva/p/7805300.html', 'type': 'text/html'}, {'rel': 'alternate', 'type': 'text/html', 'href': 'http://www.cnblogs.com/yangva/p/7805300.html'}], 'content': [{'type': 'text/html', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '该文被密码保护。'}]}, {'id': 'http://www.cnblogs.com/yangva/p/7797316.html', 'guidislink': True, 'link': 'http://www.cnblogs.com/yangva/p/7797316.html', 'title': '洗礼灵魂,修炼python(64)--爬虫篇—re模块/正则表达式(2) - yangva', 'title_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '洗礼灵魂,修炼python(64)--爬虫篇—re模块/正则表达式(2) - yangva'}, 'summary': '该文被密码保护。', 'summary_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '该文被密码保护。'}, 'published': '2017-11-09T07:14:00Z', 'published_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=9, tm_hour=7, tm_min=14, tm_sec=0, tm_wday=3, tm_yday=313, tm_isdst=0), 'updated': '2017-11-09T07:14:00Z', 'updated_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=9, tm_hour=7, tm_min=14, tm_sec=0, tm_wday=3, tm_yday=313, tm_isdst=0), 'authors': [{'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}], 'author_detail': {'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}, 'href': 'http://www.cnblogs.com/yangva/', 'author': 'yangva', 'links': [{'rel': 'alternate', 'href': 'http://www.cnblogs.com/yangva/p/7797316.html', 'type': 'text/html'}, {'rel': 'alternate', 'type': 'text/html', 'href': 'http://www.cnblogs.com/yangva/p/7797316.html'}], 'content': [{'type': 'text/html', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '该文被密码保护。'}]}, {'id': 'http://www.cnblogs.com/yangva/p/7792055.html', 'guidislink': True, 'link': 'http://www.cnblogs.com/yangva/p/7792055.html', 'title': '洗礼灵魂,修炼python(63)--爬虫篇—re模块/正则表达式(1) - yangva', 'title_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '洗礼灵魂,修炼python(63)--爬虫篇—re模块/正则表达式(1) - yangva'}, 'summary': '该文被密码保护。', 'summary_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '该文被密码保护。'}, 'published': '2017-11-06T14:31:00Z', 'published_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=6, tm_hour=14, tm_min=31, tm_sec=0, tm_wday=0, tm_yday=310, tm_isdst=0), 'updated': '2017-11-06T14:31:00Z', 'updated_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=6, tm_hour=14, tm_min=31, tm_sec=0, tm_wday=0, tm_yday=310, tm_isdst=0), 'authors': [{'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}], 'author_detail': {'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}, 'href': 'http://www.cnblogs.com/yangva/', 'author': 'yangva', 'links': [{'rel': 'alternate', 'href': 'http://www.cnblogs.com/yangva/p/7792055.html', 'type': 'text/html'}, {'rel': 'alternate', 'type': 'text/html', 'href': 'http://www.cnblogs.com/yangva/p/7792055.html'}], 'content': [{'type': 'text/html', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '该文被密码保护。'}]}, {'id': 'http://www.cnblogs.com/yangva/p/7794251.html', 'guidislink': True, 'link': 'http://www.cnblogs.com/yangva/p/7794251.html', 'title': '洗礼灵魂,修炼python(62)--爬虫篇—模仿游戏 - yangva', 'title_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '洗礼灵魂,修炼python(62)--爬虫篇—模仿游戏 - yangva'}, 'summary': '该文被密码保护。', 'summary_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '该文被密码保护。'}, 'published': '2017-11-06T09:34:00Z', 'published_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=6, tm_hour=9, tm_min=34, tm_sec=0, tm_wday=0, tm_yday=310, tm_isdst=0), 'updated': '2017-11-06T09:34:00Z', 'updated_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=6, tm_hour=9, tm_min=34, tm_sec=0, tm_wday=0, tm_yday=310, tm_isdst=0), 'authors': [{'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}], 'author_detail': {'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}, 'href': 'http://www.cnblogs.com/yangva/', 'author': 'yangva', 'links': [{'rel': 'alternate', 'href': 'http://www.cnblogs.com/yangva/p/7794251.html', 'type': 'text/html'}, {'rel': 'alternate', 'type': 'text/html', 'href': 'http://www.cnblogs.com/yangva/p/7794251.html'}], 'content': [{'type': 'text/html', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '该文被密码保护。'}]}, {'id': 'http://www.cnblogs.com/yangva/p/7767445.html', 'guidislink': True, 'link': 'http://www.cnblogs.com/yangva/p/7767445.html', 'title': '洗礼灵魂,修炼python(61)--爬虫篇—【转载】requests模块 - yangva', 'title_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '洗礼灵魂,修炼python(61)--爬虫篇—【转载】requests模块 - yangva'}, 'summary': '该文被密码保护。', 'summary_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '该文被密码保护。'}, 'published': '2017-11-06T02:22:00Z', 'published_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=6, tm_hour=2, tm_min=22, tm_sec=0, tm_wday=0, tm_yday=310, tm_isdst=0), 'updated': '2017-11-06T02:22:00Z', 'updated_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=6, tm_hour=2, tm_min=22, tm_sec=0, tm_wday=0, tm_yday=310, tm_isdst=0), 'authors': [{'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}], 'author_detail': {'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}, 'href': 'http://www.cnblogs.com/yangva/', 'author': 'yangva', 'links': [{'rel': 'alternate', 'href': 'http://www.cnblogs.com/yangva/p/7767445.html', 'type': 'text/html'}, {'rel': 'alternate', 'type': 'text/html', 'href': 'http://www.cnblogs.com/yangva/p/7767445.html'}], 'content': [{'type': 'text/html', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '该文被密码保护。'}]}, {'id': 'http://www.cnblogs.com/yangva/p/7786802.html', 'guidislink': True, 'link': 'http://www.cnblogs.com/yangva/p/7786802.html', 'title': '洗礼灵魂,修炼python(60)--爬虫篇—httplib2模块 - yangva', 'title_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '洗礼灵魂,修炼python(60)--爬虫篇—httplib2模块 - yangva'}, 'summary': '该文被密码保护。', 'summary_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '该文被密码保护。'}, 'published': '2017-11-05T09:57:00Z', 'published_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=5, tm_hour=9, tm_min=57, tm_sec=0, tm_wday=6, tm_yday=309, tm_isdst=0), 'updated': '2017-11-05T09:57:00Z', 'updated_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=5, tm_hour=9, tm_min=57, tm_sec=0, tm_wday=6, tm_yday=309, tm_isdst=0), 'authors': [{'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}], 'author_detail': {'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}, 'href': 'http://www.cnblogs.com/yangva/', 'author': 'yangva', 'links': [{'rel': 'alternate', 'href': 'http://www.cnblogs.com/yangva/p/7786802.html', 'type': 'text/html'}, {'rel': 'alternate', 'type': 'text/html', 'href': 'http://www.cnblogs.com/yangva/p/7786802.html'}], 'content': [{'type': 'text/html', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '该文被密码保护。'}]}, {'id': 'http://www.cnblogs.com/yangva/p/7783392.html', 'guidislink': True, 'link': 'http://www.cnblogs.com/yangva/p/7783392.html', 'title': '洗礼灵魂,修炼python(59)--爬虫篇—httplib模块 - yangva', 'title_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '洗礼灵魂,修炼python(59)--爬虫篇—httplib模块 - yangva'}, 'summary': '该文被密码保护。', 'summary_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '该文被密码保护。'}, 'published': '2017-11-05T02:39:00Z', 'published_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=5, tm_hour=2, tm_min=39, tm_sec=0, tm_wday=6, tm_yday=309, tm_isdst=0), 'updated': '2017-11-05T02:39:00Z', 'updated_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=5, tm_hour=2, tm_min=39, tm_sec=0, tm_wday=6, tm_yday=309, tm_isdst=0), 'authors': [{'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}], 'author_detail': {'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}, 'href': 'http://www.cnblogs.com/yangva/', 'author': 'yangva', 'links': [{'rel': 'alternate', 'href': 'http://www.cnblogs.com/yangva/p/7783392.html', 'type': 'text/html'}, {'rel': 'alternate', 'type': 'text/html', 'href': 'http://www.cnblogs.com/yangva/p/7783392.html'}], 'content': [{'type': 'text/html', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '该文被密码保护。'}]}, {'id': 'http://www.cnblogs.com/yangva/p/7782359.html', 'guidislink': True, 'link': 'http://www.cnblogs.com/yangva/p/7782359.html', 'title': '洗礼灵魂,修炼python(58)--爬虫篇—【转载】urllib3模块 - yangva', 'title_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '洗礼灵魂,修炼python(58)--爬虫篇—【转载】urllib3模块 - yangva'}, 'summary': '该文被密码保护。', 'summary_detail': {'type': 'text/plain', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '该文被密码保护。'}, 'published': '2017-11-04T03:31:00Z', 'published_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=4, tm_hour=3, tm_min=31, tm_sec=0, tm_wday=5, tm_yday=308, tm_isdst=0), 'updated': '2017-11-04T03:31:00Z', 'updated_parsed': time.struct_time(tm_year=2017, tm_mon=11, tm_mday=4, tm_hour=3, tm_min=31, tm_sec=0, tm_wday=5, tm_yday=308, tm_isdst=0), 'authors': [{'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}], 'author_detail': {'name': 'yangva', 'href': 'http://www.cnblogs.com/yangva/'}, 'href': 'http://www.cnblogs.com/yangva/', 'author': 'yangva', 'links': [{'rel': 'alternate', 'href': 'http://www.cnblogs.com/yangva/p/7782359.html', 'type': 'text/html'}, {'rel': 'alternate', 'type': 'text/html', 'href': 'http://www.cnblogs.com/yangva/p/7782359.html'}], 'content': [{'type': 'text/html', 'language': None, 'base': 'http://feed.cnblogs.com/blog/u/385429/rss', 'value': '该文被密码保护。'}]}], 'bozo': 0, 'headers': {'Cache-Control': 'private', 'Content-Type': 'application/xml', 'Content-Encoding': 'gzip', 'Vary': 'Accept-Encoding', 'Server': 'Microsoft-IIS/7.5', 'Set-Cookie': 'ASP.NET_SessionId=vqicjsq5n41af0lenvppfqim; path=/; HttpOnly', 'X-AspNetMvc-Version': '4.0', 'X-AspNet-Version': '4.0.30319', 'X-Powered-By': 'ASP.NET', 'X-UA-Compatible': 'IE=edge', 'Date': 'Sun, 26 Nov 2017 12:00:58 GMT', 'Connection': 'close', 'Content-Length': '2333'}, 'href': 'http://feed.cnblogs.com/blog/u/385429/rss', 'status': 200, 'encoding': 'utf-8', 'version': 'atom10', 'namespaces': {'': 'http://www.w3.org/2005/Atom'}}
这样就把一些数据拿到了,标题,摘要,url地址全有了,相信你学到这里了,这些参数你基本上能看懂了
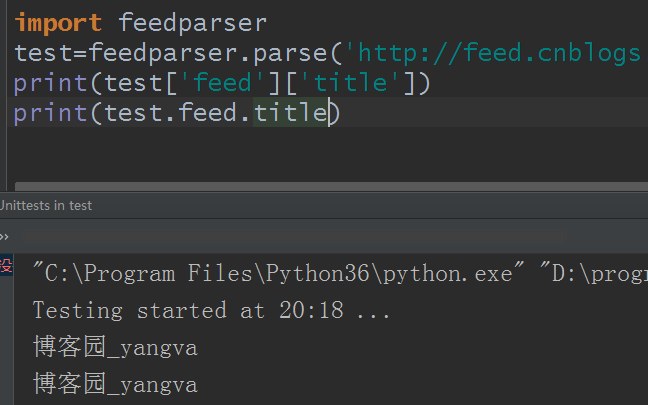
每个 RSS 和 Atom 订阅源都包含一个标题(.feed.title)
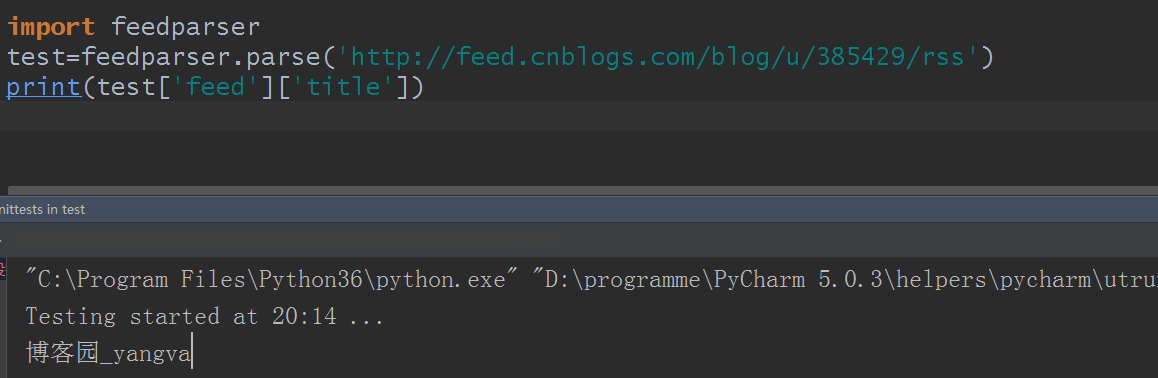
也可以通过属性访问:
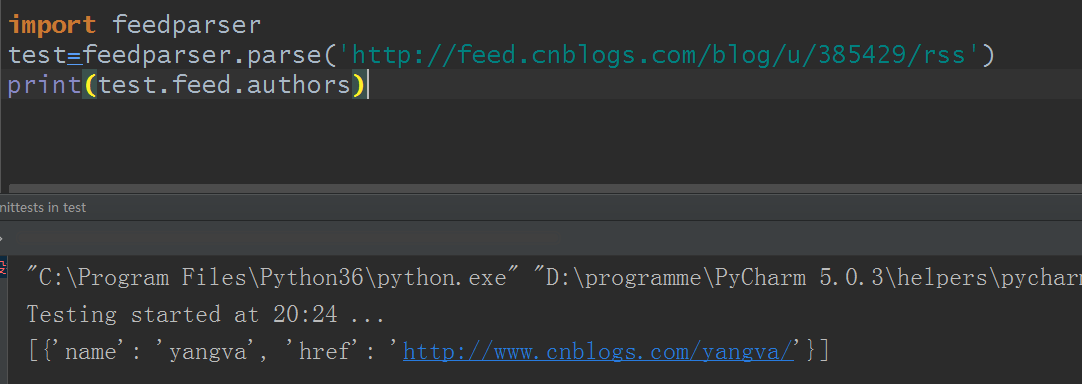
还有authors作者以及主页等
还有一组文章条目(.entries)

每个文章条目都有一段摘要(.entries[i].summary)

或者是包含了条目中实际文本的描述性标签(.entries[i].description)

还有很多很多,只要对象feedparser.parse(url)里面有的,基本都可以访问,根据实际情况来就行
综合使用
- 可以刷博客访问量
- 爬取别人的博客文章(我之前那些被爬虫爬取的博客文章不出意外就是用的rss爬的)
- ……
有朋友肯定想,我不用webbrowser和feedparser也可以爬取啊,是的,不过有了feedparser就多了一种办法啊,并且还不止干这些,你还可以结合上一篇的webbrowser模块一起使用:
import webbrowser,time,os,feedparser
browser_path = r'C:\Users\Administrator\AppData\Local\Google\Chrome\Application\chrome.exe'
test = feedparser.parse('http://feed.cnblogs.com/blog/sitehome/rss')
blog_urls = [entry.id for entry in test.entries] #这是根据parse对象匹配出来的,根据实际情况匹配就行
count = 0
for url in blog_urls: #个人建议,已经有for循环用来迭代url了,不需要在用while,不然嵌套太多层,不利于优化
webbrowser.register('chrome',None,webbrowser.BackgroundBrowser(browser_path))
webbrowser.get('chrome').open_new_tab(url)
count += 1
time.sleep(3)
if not count%5: #注意这里的if not,很巧妙,可以实现每打开五个标签就关闭,再次重新打开,直到for循环结束
os.system('taskkill /F /IM chrome.exe')
同样的,不方便展示效果,自己复制代码下去测试体验吧,还是那句话,没必要去刷博客访问量,没意思。
另外同样的,不要一直去测试运行代码,别把博客园服务器搞崩了,这样就太不好了
声明:本篇博文只是作为python学术研究和知识分享,并不会对博客园进行任何恶意的攻击等等操作,也永远不会这么做,也请各位看客不要这么做。以及对文中涉及到的博客文章原作者表示谢意和歉意,并不是有意拿你们的文章做实验对象,只是在这里做测试,也并没有爬取您们辛苦码好的文章,也永远不会这么做,也请各位看客不要这么做,尊重作者,尊重原创
洗礼灵魂,修炼python(69)--爬虫篇—番外篇之feedparser模块的更多相关文章
- 洗礼灵魂,修炼python(68)--爬虫篇—番外篇之webbrowser模块
题外话: 爬虫学到这里,我想你大部分的网站已经不再话下了对吧?有检测报文头的,我们可以伪造报文头为浏览器,有检测IP,我们可以用代理IP,有检测请求速度的,我们可以用time模块停顿一下,需要登录验证 ...
- Python之路【番外篇】回顾&类的静态字段
回顾 回顾:字符串.列表.字典的修改关于内存的情况 一.字符串 str1 = 'luotianshuai' str2 = str1 print id(str1) print id(str2) prin ...
- python之爬虫--番外篇(一)进程,线程的初步了解
整理这番外篇的原因是希望能够让爬虫的朋友更加理解这块内容,因为爬虫爬取数据可能很简单,但是如何高效持久的爬,利用进程,线程,以及异步IO,其实很多人和我一样,故整理此系列番外篇 一.进程 程序并不能单 ...
- 给深度学习入门者的Python快速教程 - 番外篇之Python-OpenCV
这次博客园的排版彻底残了..高清版请移步: https://zhuanlan.zhihu.com/p/24425116 本篇是前面两篇教程: 给深度学习入门者的Python快速教程 - 基础篇 给深度 ...
- python的类和对象——番外篇(类的静态字段)
什么是静态字段 在开始之前,先上图,解释一下什么是类的静态字段(我有的时候会叫它类的静态变量,总之说的都是它.后面大多数情况可能会简称为类变量.): 我们看上面的例子,这里的money就是静态字段,首 ...
- python自动化测试应用-番外篇--接口测试1
篇1 book-python-auto-test-番外篇--接口测试1 --lamecho辣么丑 1.1概要 大家好! 我是lamecho(辣么丑),至今<安卓a ...
- python自动化测试应用-番外篇--接口测试2
篇2 book-python-auto-test-番外篇--接口测试2 --lamecho辣么丑 大家好! 我是lamecho(辣么丑),今天将继续上一篇python接 ...
- python的类和对象——类的静态字段番外篇
什么是静态字段 在开始之前,先上图,解释一下什么是类的静态字段(我有的时候会叫它类的静态变量,总之说的都是它.后面大多数情况可能会简称为类变量.): 我们看上面的例子,这里的money就是静态字段,首 ...
- #3使用html+css+js制作网页 番外篇 使用python flask 框架 (II)
#3使用html+css+js制作网页 番外篇 使用python flask 框架 II第二部 0. 本系列教程 1. 登录功能准备 a.python中操控mysql b. 安装数据库 c.安装mys ...
随机推荐
- JavaScript高级编程(1)——JavaScript初识
一.javascript的简介 1.1 javascript的历史回顾. Javascript诞生于1995年.当时,它主要的目的是用来处理一些由服务器端处理的输入验证操作.在javascript没有 ...
- 解决Unity中模型部件的MeshCollider不随动画一起运动的问题
Unity的3d游戏开发中,经常遇到需要将模型的某一部分(比如武器),单独做碰撞处理的情况. 导入模型后,给武器部分添加MeshCollider,MeshCollider的Mesh通常包含在模型里,如 ...
- 【干货】利用MVC5+EF6搭建博客系统(四)(上)前后台页面布局页面实现,介绍使用的UI框架以及JS组件
一.博客系统进度回顾以及页面设计 1.1页面设计说明 紧接前面基础基本完成了框架搭建,现在开始设计页面,前台页面设计我是模仿我博客园的风格来设计的,后台是常规的左右布局风格. 1.2前台页面风格 主页 ...
- linux中gdb的使用
断点 在代码的指定位置中断,使程序在此中断. break <function> 在进入指定函数时停住 break <linenum> 在指定行号停住. break ...
- jsp、jQuery、servlet交互实现登录功能
做一个web项目,往往需要有一个登录模块,验证用户名和密码之后跳转页面.为了实现更好的交互,往往需要用到 jQuery 等实现一些友好提示.比如用户名或者密码输入为空的时候提示不能为空:点击提交的时候 ...
- PCA实现教程
数据是机器学习模型的生命燃料.对于特定的问题,总有很多机器学习技术可供选择,但如果没有很多好的数据,问题将不能很好的解决.数据通常是大部分机器学习应用程序中性能提升背后的驱动因素. 有时,数据可能很复 ...
- Java 容器源码分析之 LinkedList
概览 同 ArrayList 一样,LinkedList 也是对 List 接口的一种具体实现.不同的是,ArrayList 是基于数组来实现的,而 LinkedList 是基于双向链表实现的.Lin ...
- kubernets 单节点安装
关闭防火墙和Selinux. setenforce 0 systemctl stop firewalld systemctl disable firewalld 配置EPEL源 yum install ...
- 一致性Hash算法(分布式算法)
一致性哈希算法是分布式系统中常用的算法,为什么要用这个算法? 比如:一个分布式存储系统,要将数据存储到具体的节点(服务器)上, 在服务器数量不发生改变的情况下,如果采用普通的hash再对服务器总数量取 ...
- MySQL索引建立和使用的基本原则
合理设计和使用索引 在关键字段的索引上,建与不建索引,查询速度相差近100倍. 差的索引和没有索引效果一样. 索引并非越多越好,因为维护索引需要成本. 每个表的索引应在5个以下,应合理利用 ...