Python_序列化和反序列化模块
序列化:将对象转换为可通过网络传输或可存储到本地磁盘的数据格式的转换过程,称为序列化,反之,称为反序列化
json: 用来实现不同语言,不同程序直接的信息交互,json支持所有高级语言之间的序列化交互,json只能通过 字典—>字符串—>字典 的格式转换
注:json是读写序列化格式
pickle: python 中独有的序列化方法,如果有需要Python可以把Python中几乎所有的类型都可以序列化转换
注:pickle是二进制读写序列化格式
json与pickle都有相同的方法:
x.dumps():将得到的json或pickle数据序列化为一个bytes,然后将这个bytes写入磁盘或进行传输
x.loads():把得到的json或pickle数据从磁盘中读到内存中时,把内容先读到一个bytes中,然后再用loads反序列化出对象
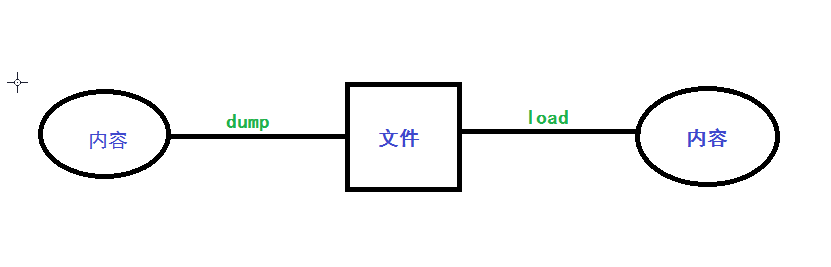
x.dump():可直接将得到的json或pickle数据序列化后保存到文件中
x.load():可直接读取文件中的json或pickle数据进行反序列化
实例:
- import json,pickle
- # f = open('测试文件.txt', 'w') # json 运用 'w',写入
- f = open('测试文件.txt', 'wb') # pickle 运用二进制'wb'写入
- info = {
- 'Presly': 'come on',
- 'Vera': '',
- 'mini': 'hello'
- }
- # json.dump(info, f) # 转为纯字符串
- # f.write(json.dumps(info))
- pickle.dump(info, f) # 转为二进制
- # f.write(pickle.dumps(info))
- f.close()
序列化
- import json , pickle
- # f = open('测试文件.txt', 'r')
- f = open('测试文件.txt', 'rb')
- # data = json.load(f) # 只能识别字符串,不能识别二进制
- # data = json.loads(f.read())
- # data = pickle.load(f) # 只能识别二进制
- data = pickle.loads(f.read())
- print(data)
- f.close()
反序列化
Python_序列化和反序列化模块的更多相关文章
- Python库:序列化和反序列化模块pickle介绍
1 前言 在“通过简单示例来理解什么是机器学习”这篇文章里提到了pickle库的使用,本文来做进一步的阐述. 通过简单示例来理解什么是机器学习 pickle是python语言的一个标准模块,安装pyt ...
- Python—序列化和反序列化模块(json、pickle和shelve)
什么是序列化 我们把对象(或者变量)从内存中变为可存储或者可传输的过程称为序列化.在python中为pickling,在其他语言中也被称之为serialization,marshalling,flat ...
- 【Python】Json序列化和反序列化模块dumps、loads、dump、load函数介绍
1.json.dumps() json.dumps()用于将dict类型的数据转成str,因为如果直接将dict类型的数据写入json文件中会发生报错,因此在将数据写入时需要用到该函数. 转换案例: ...
- day5-python中的序列化与反序列化-json&pickle
一.概述 玩过稍微大型一点的游戏的朋友都知道,很多游戏的存档功能使得我们可以方便地迅速进入上一次退出的状态(包括装备.等级.经验值等在内的一切运行时数据),那么在程序开发中也存在这样的需求:比较简单的 ...
- 第十八天python3 序列化和反序列化
思考: 内存中的字典.列表.集合以及各种对象,如何保存到一个文件中? 如果是自己定义的类的实例,如何保存到一个文件中? 如何从文件中读取数据,并让它们在内存中再次变成自己对应的类的实例? 要设计一套协 ...
- 序列化与反序列化,json,pickle,xml,shelve,configparser模块
序列化与反序列化 什么是序列化?序列化就是将内存中的数据结构转换成一种中间格式存储到硬盘或者基于网络传输.反序列化就是将硬盘中或者网络中传来的一种数据格式转换成内存中数据结构. 为什么要有? 1.可以 ...
- Python开发之序列化与反序列化:pickle、json模块使用详解
1 引言 在日常开发中,所有的对象都是存储在内存当中,尤其是像python这样的坚持一切接对象的高级程序设计语言,一旦关机,在写在内存中的数据都将不复存在.另一方面,存储在内存够中的对象由于编程语言. ...
- python 之 序列化与反序列化、os模块
6.6 序列化与反序列化 特殊的字符串 , 只有:int / str / list / dict 最外层必须是列表或字典,如果包含字符串,必须是双引号"". 序列化:将Python ...
- DRF框架(二)——解析模块(parsers)、异常模块(exception_handler)、响应模块(Response)、三大序列化组件介绍、Serializer组件(序列化与反序列化使用)
解析模块 为什么要配置解析模块 1)drf给我们提供了多种解析数据包方式的解析类 form-data/urlencoded/json 2)我们可以通过配置来控制前台提交的哪些格式的数据后台在解析,哪些 ...
随机推荐
- 13)django-ORM(连表一对多,外键创建,创建数据,3种查询)
一对多需要使用外键 一:外键创建ForeignKey b=models.ForeignKey(to="Business",to_field=("id"))#dj ...
- linux学习之软件包安装
本学习基于redhat系统或者centos系统 一.软件包的安装 1.rpm安装,rpm安装分为俩种,一种是直接安装xxx.rpm包,另一种是通过yum安装一系列的rpm包. #推荐使用yum安装,y ...
- swift 实践- 12 -- UIPickerView
import UIKit class ViewController: UIViewController , UIPickerViewDelegate,UIPickerViewDataSource{ v ...
- Oracle12c 从入门到精通(第二版) 闫红岩 金松河 编著
声明:本文只是用于学习笔记使用.方便查询.若需要书本,请到书店购买. 本书封面 前言 第1章 Oracle数据库概述 1.1 Oracle数据库产品结构及组成 1.1.1 标准版 1.1.2 标准版 ...
- Confluence 6 已经存在的安装配置数据库字符集编码
针对已经存在的 Confluence 安装,如果你安装的 Confluence 版本是 6.4 或者早期的版本,我们在安装的时候没有检查你数据库的字符设置. 如果你的数据库当前没有被配置使用 UTF- ...
- Confluence 6 创建一个主题
如果你希望创建你自己的主题,你需要写一个 Confluence 插件.请参考我们开发文档中的下面页面 开始使用 插件开发. 请参考开发者指南的页面来 写一个 Confluence 主题. 使用 主题插 ...
- LoadRunner监控window系统各项指标详解
一.监控系统时,需要监控的项 System 系统 Processor 处理器 Memory 内存 PhysicalDisk 磁盘 Server 服务器 二.指标详解 (一). PhysicalDisk ...
- matalb 产生信号源 AM调制解调 FM调制解调
%%%%%%%%%%%%%%%%%%%%%%%%%%% %AM调制解调系统 %%%%%%%%%%%%%%%%%%%%%%%%%%% clear; clf; close all Fs=800000;%采 ...
- MySQL数据库之安装
一.基础部分 1.数据库是什么 之前所学,数据要永久保存,比如用户注册的用户信息,都是保存于文件中,而文件只能存在于某一台机器上. 如果我们不考虑从文件中读取数据的效率问题,并且假设我们的程序所有的组 ...
- js之DOM对象一
一.什么是HTML DOM HTML Document Object Model(文档对象模型) HTML DOM 定义了访问和操作HTML文档的标准方法 HTML DOM 把 HTML 文档呈现 ...