【Spark调优】数据倾斜及排查
【数据倾斜及调优概述】
大数据分布式计算中一个常见的棘手问题——数据倾斜:
在进行shuffle的时候,必须将各个节点上相同的key拉取到某个节点上的一个task来进行处理,比如按照key进行聚合或join等操作。此时如果某个key对应的数据量特别大的话,就会发生数据倾斜。比如大部分key对应10条数据,但是个别key却对应了百万条数据,那么大部分task可能就只会分配到10条数据,然后1秒钟就运行完了;但是个别task可能分配到了百万数据,要运行一两个小时。木桶原理,整个作业的运行进度是由运行时间最长的那个task决定的。
出现数据倾斜的时候,绝大多数task执行得都非常快,但个别task执行极慢。例如,总共有1000个task,997个task都在1分钟之内执行完了,但是剩余两三个task却要一两个小时。这种情况很常见。原本能够正常执行的Spark作业,某天突然报出OOM(内存溢出)异常,观察异常栈,是我们写的业务代码造成的。这种情况比较少见。
此时Spark作业的性能会比期望差很多。数据倾斜调优,就是使用各种技术方案解决不同类型的数据倾斜问题,以保证Spark作业的性能。
【定位发生数据倾斜的代码】
1) 数据倾斜只会发生在shuffle过程中。所以关注一些常用的并且可能会触发shuffle操作的算子:distinct、groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition等。出现数据倾斜时,可能就是代码中使用了这些算子中的某一个所导致的。
2)通过观察spark UI的界面,定位数据倾斜发生在第几个stage中。
如果是用yarn-client模式提交,那么本地是直接可以看到log的,可以在log中找到当前运行到了第几个stage;如果是用yarn-cluster模式提交,则可以通过Spark Web UI来查看当前运行到了第几个stage。此外,无论是使用yarn-client模式还是yarn-cluster模式,我们都可以在Spark Web UI上深入看一下当前这个stage各个task分配的数据量,从而进一步确定是不是task分配的数据不均匀导致了数据倾斜。
- 1段提交代码是1个Application
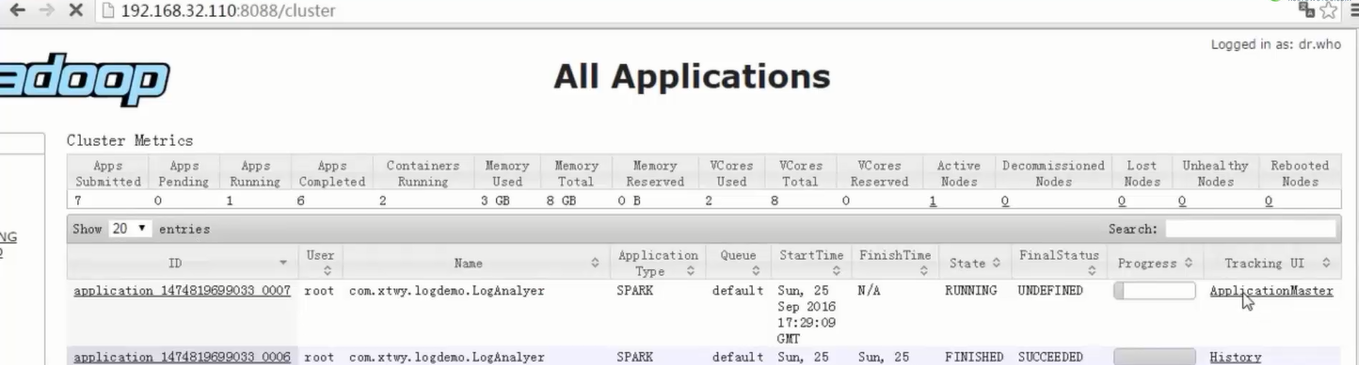
- 1个action算子是1个job
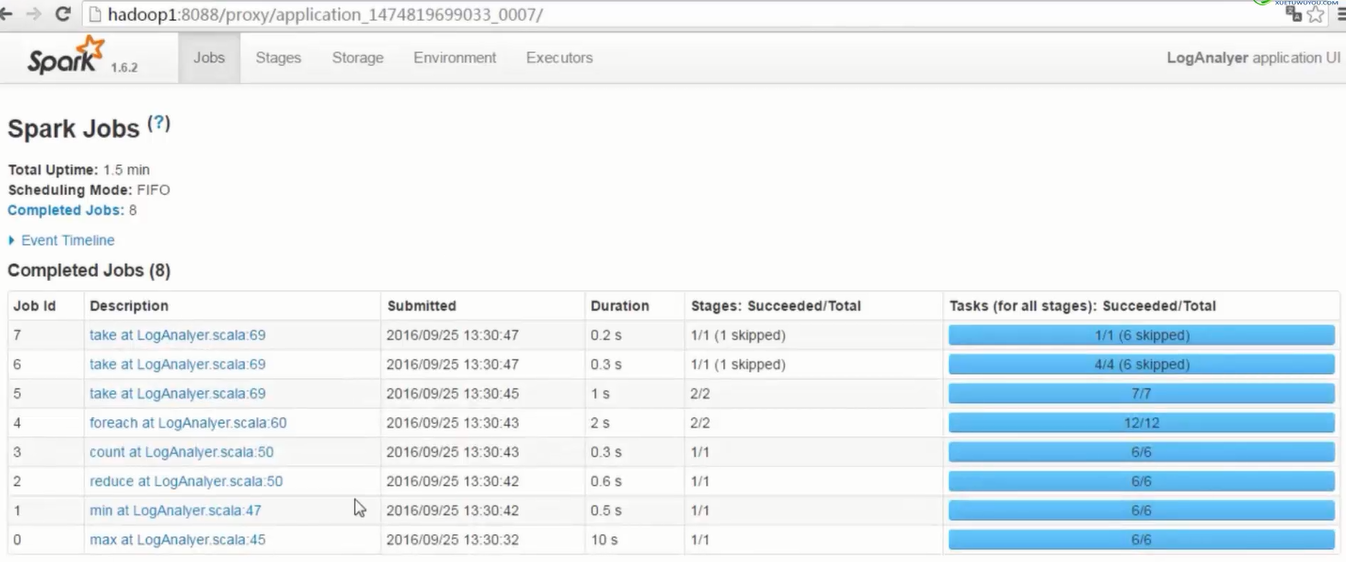
- 1个job中,以宽依赖为分割线,划分成不同stage,stage编号从0开始
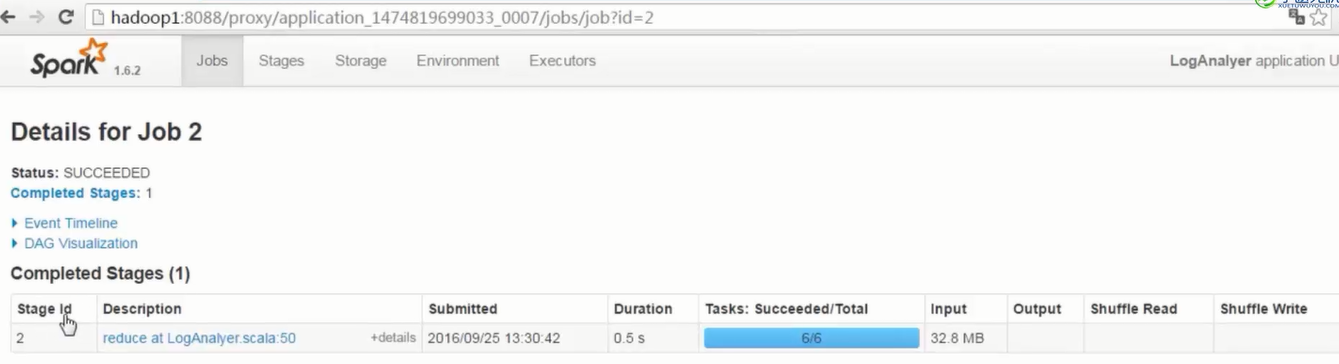
- 1个stage中,划分出参数指定数量的task,注意观察Locality Level和Duration列

- Executor数量是配置参数指定的
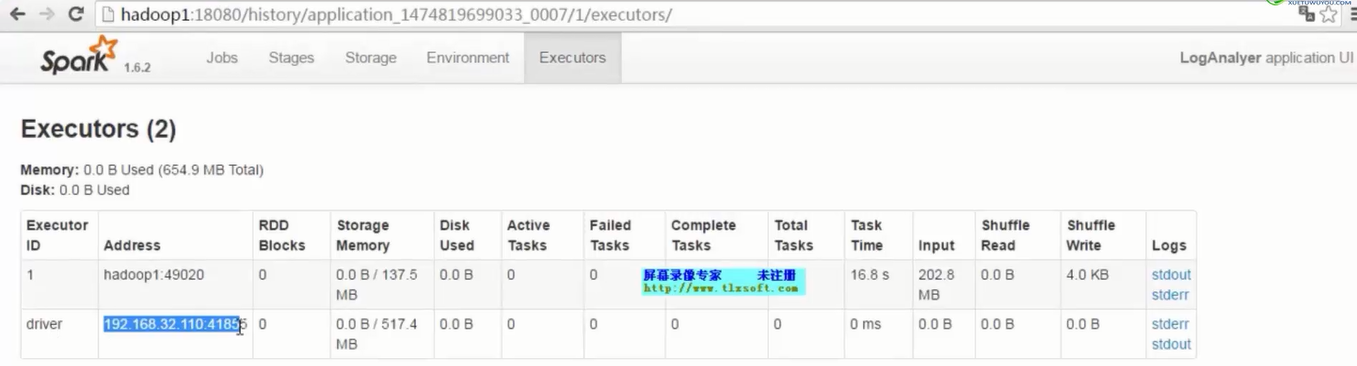
- 看结果文件---自己统计代码中println的打印
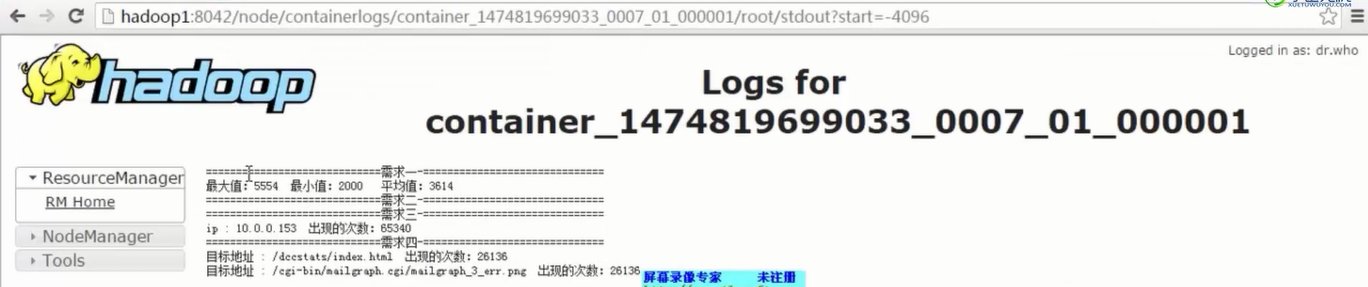
3)根据 【Spark工作原理】stage划分原理理解 中的stage的划分算法定位到极有可能发生数据倾斜的代码

【查看导致数据倾斜的key的分布情况】
1. 如果是Spark SQL中的group by、join语句导致的数据倾斜,那么就查询一下SQL中使用的表的key分布情况。
2. 如果是对Spark RDD执行shuffle算子导致的数据倾斜,那么可以在Spark作业中加入查看key分布的代码,比如RDD.countByKey()。然后对统计出来的各个key出现的次数,collect/take到客户端打印一下,就可以看到key的分布情况。
不放回sample+countByKey查看key分布,是否数据倾斜
val sampledPairs = pairs.sample(false, 0.1)
val sampledWordCounts = sampledPairs.countByKey()
sampledWordCounts.foreach(println(_))
【Spark调优】数据倾斜及排查的更多相关文章
- Spark调优 数据倾斜
1. Spark数据倾斜问题 Spark中的数据倾斜问题主要指shuffle过程中出现的数据倾斜问题,是由于不同的key对应的数据量不同导致的不同task所处理的数据量不同的问题. 例如,reduce ...
- spark调优——数据倾斜
Spark中的数据倾斜问题主要指shuffle过程中出现的数据倾斜问题,是由于不同的key对应的数据量不同导致的不同task所处理的数据量不同的问题. 例如,reduce点一共要处理100万条数据,第 ...
- spark性能调优 数据倾斜 内存不足 oom解决办法
[重要] Spark性能调优——扩展篇 : http://blog.csdn.net/zdy0_2004/article/details/51705043
- Greenplum 调优--数据倾斜排查(二)
上次有个朋友咨询我一个GP数据倾斜的问题,他说查看gp_toolkit.gp_skew_coefficients表时花费了20-30分钟左右才出来结果,后来指导他分析原因并给出其他方案来查看数据倾斜. ...
- Greenplum 调优--数据倾斜排查(一)
对于分布式数据库来说,QUERY的运行效率取决于最慢的那个节点. 当数据出现倾斜时,某些节点的运算量可能比其他节点大.除了带来运行慢的问题,还有其他的问题,例如导致OOM,或者DISK FULL等问题 ...
- 1-Spark-1-性能调优-数据倾斜1-特征/常见原因/后果/常见调优方案
数据倾斜特征:个别Task处理大部分数据 后果:1.OOM;2.速度变慢,甚至变得慢的不可接受 常见原因: 数据倾斜的定位: 1.WebUI(查看Task运行的数据量的大小). 2.Log,查看log ...
- 2-Spark-1-性能调优-数据倾斜2-Join/Broadcast的使用场景
技术点:RDD的join操作可能产生数据倾斜,当两个RDD不是非常大的情况下,可以通过Broadcast的方式在reduce端进行类似(Join)的操作: broadcast是进程级别的,只读的. b ...
- spark 调优概述
分为几个部分: 开发调优.资源调优.数据倾斜调优.shuffle调优 开发调优: 主要包括这几个方面 RDD lineage设计.算子的合理使用.特殊操作的优化等 避免创建重复的RDD,尽可能复用同一 ...
- 【Spark调优】大表join大表,少数key导致数据倾斜解决方案
[使用场景] 两个RDD进行join的时候,如果数据量都比较大,那么此时可以sample看下两个RDD中的key分布情况.如果出现数据倾斜,是因为其中某一个RDD中的少数几个key的数据量过大,而另一 ...
随机推荐
- boost asio死锁一例
socket close -> sendmessage -> io_service stop 先关闭socket句柄,再给windows窗口发送消息,然后io_service停止. 当se ...
- windows 上安装冷门python模块
最近在逼乎看到 笑虎大大 的python 撸代码学知识专栏..就下载他的Pspider 框架 安装了一下,准备耍耍. 由于是在Windows下的pycharm 有个 pybloom_live 模块 老 ...
- 第5-7次OO作业总结分析
(1)从多线程的协同和同步控制方面,分析和总结自己三次作业来的设计策略及其变化. 第五次作业 第五次作业是对多线程的初步探索,所以对于多线程的基本书写机制的认识比较多.本次作业难点在于了解多线程的运作 ...
- JSP 页面跳转中的参数传递
1. 从一个 JSP 页面跳转到另一个 JSP 页面时的参数传递 1)使用 request 内置对象获取客户端提交的信息 2)使用 session 对象获取客户端提交的信息 3)利用隐藏域传递数据 4 ...
- PostgreSQL时间段查询
1.今日 select * from "表名" where to_date("时间字段"::text,'yyyy-mm-dd')=current_date 2. ...
- pycharm汉化(3.6版本)
step 1:下载pycharm汉化包 链接:https://pan.baidu.com/s/1htgcbZY 密码:8uia step 2:将pycharm安装目录下的lib文件夹内下的resou ...
- OvO
OvO 知乎 网易云 图书馆 B站 小众软件 360极速浏览器下载 开源下载工具 下载地址1 下载地址2 下载地址3
- springBoot 使用拦截器 入坑
近期使用SpringBoot 其中用到了拦截器 结果我的静态资源被全部拦截了,让我导致了好久才搞好: 看下图项目结构: 问题描述:上图划红框的资源都被拦截器给拦截了,搞得项目中不能访问:解决问题就是在 ...
- vue,react,angular
一.Vue.js: 其实Vue.js不是一个框架,因为它只聚焦视图层,是一个构建数据驱动的Web界面的库. Vue.js通过简单的API(应用程序编程接口)提供高效的数据绑定和灵活的组 ...
- C++数论板题(弹药科技):Lengendre定理和欧拉函数
弹药科技 时间限制: 1 Sec 内存限制: 128 MB 题目描述 经过精灵族全力抵挡,精灵终于坚持到了联络系统的重建,于是精灵向人类求助, 大魔法师伊扎洛决定弓}用博士的最新科技来抗敌. 伊扎洛: ...