yolo
 

将目标检测过程设计为为一个回归问题(One Stage Detection),一步到位, 直接从像素到 bbox 坐标和类别概率
优点:
- 速度快(45fps),效果还不错(mAP 63.4)
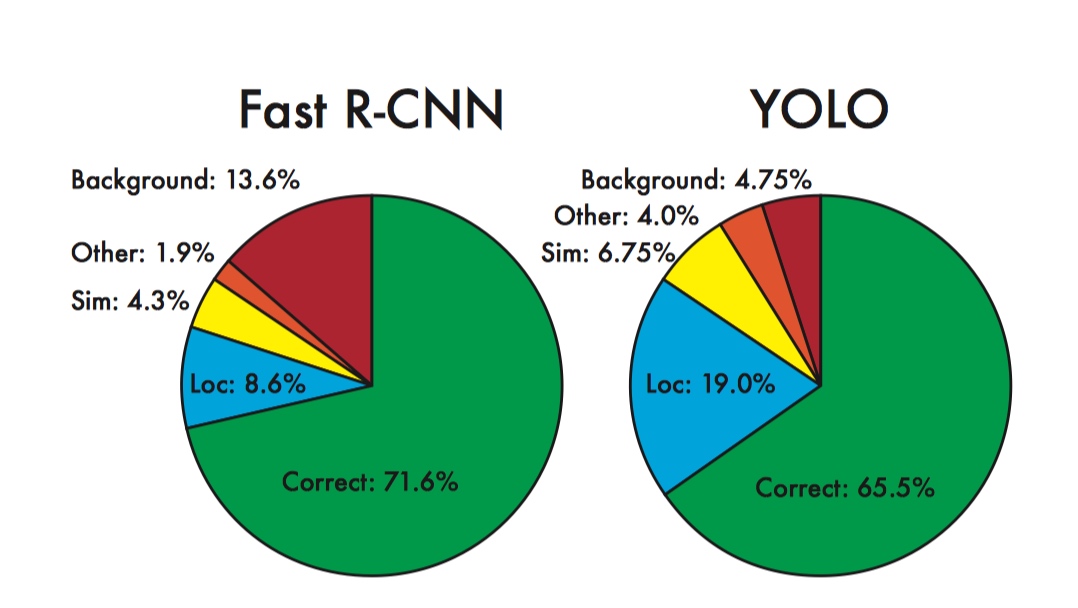
- 利用图片整体信息进行分类和 bbox坐标预测, 所以相较于其他基于 region proposal 的目标检测算法(如FRCN), yolo 很少将背景预测为前景, 虽然 yolo 会有更多的 localization error(主要由于小物体的定位差导致);
- yolo能够学习到物体更加泛化的特征, 当场景迁移到 artwork 时, yolo 效果更好

局限性:
- yolo 的架构设计对于每个 cell 能预测的 bbox 个数和类别做了很大的限制, 每个 cell 只能预测2个bbox和1组类别概率, 而且训练时, gt-box 的中心落在哪个 cell 中, 就有这个 cell 负责预测该物体, 也就是说只会有一个 cell 负责预测该物体; 而 SSD, 只要 anchor box 和 gt-box 的 IoU 大于 0.5, 训练时就会负责预测该 gt-box; 这样一种设计会导致 yolo 很难处理邻近(nearby)物体的预测; 特别是一组密集的小物体的预测;
- 模型的 bbox 坐标预测完全来自于对数据的学习, 没有添加 anchor (框大小, 宽高比)的先验知识, 所以训练好的模型很难泛化到具有与训练数据集不同尺寸和宽高比的新数据上. (98个 bbox 还是太少了, 多提bbox, 感觉才能好一些)
- 模型使用比较高层的 "粗糙特征" 来做预测 bbox坐标, 网络有总输入图片到输出有 5 个 downsample 层, 一般来说bbox坐标预测使用低层 feature map 的高解析度的特征进行预测比较好, SSD 通过这种手段实现很好的小物体预测.
- bbox 坐标预测损失函数设计上的缺陷, 使用的是MSE(mean square error)损失函数, 该函数的不足之处在于, 同等对待bbox坐标预测损失; 一个小的bbox坐标预测损失可能对于一个大的 bbox 坐标预测影响不大, 但是对于小bbox坐标预测的 IOU 却有很大的影响, 而 MSE 损失函数没法区别对待这种不同之处, 而小物体的 localization error 也是 yolo 算法 localization error 的主要来源.
设计思想简介
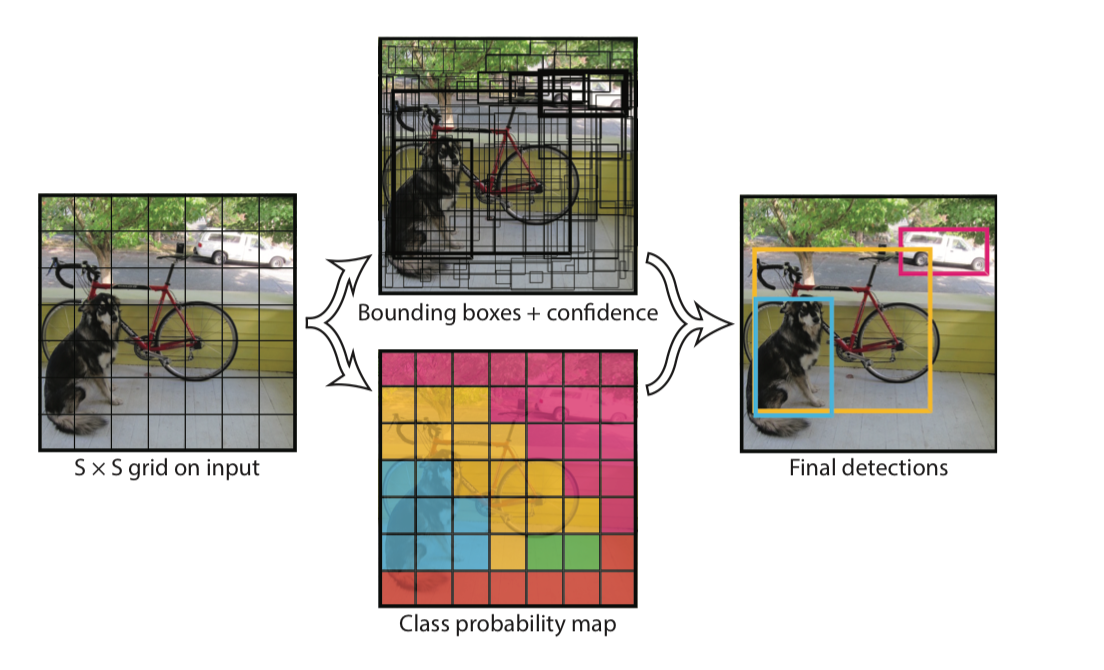 

yolo 算法将输入图片划分为 S×S 个 grid cell, 如果某个物体的中心落入一个 grid cell 中, 那么该 grid cell 就负责预测这个 object. 每个 grid cell 一共预测两个 bbox, 一个类别.
grid cell 预测 B 个 bounding boxes(论文中 B=2); 以及这些 bbox 的 confidence score, confidence score 表明了模型对该 bbox 是否包含物体以及位置预测精确度的自信程度.定义如下
\[\bf P(object)*IOU^{truth}_{pred}\]
如果 grid cell 中不包含物体中心, 那么 confidence score 为 0, 否则 confidence score 为预测的 box 与 ground-truth box 的 IOU.
每个 bbox 包含5个预测值, \((x, y, w, h, confidence)\), \((x, y)\) 表示 box 的中心相对于 grid cell 原点的偏移值(原点, 即每个 grid cell 的 top-left 顶点, yolo 将之设置为(0, 0), bottom-right顶点设置为(1, 1), 所以 \((x, y)\) 取值范围一定在(0,1)之内). \((w, h)\) 为相对于整张图片的宽和高, 即使用图片的宽和高标准化自己, 使之取值范围也在(0, 1)之间. \(confident\) 为预测 box 与 ground-truth box 的 IOU.
关于 yolo 的预测的 bbox 中心坐标是相对于 grid cell 左上角的偏移值, 很有先见之名, 不是直接预测而是预测偏移值, 但是啊, 预测的 x, y 可能为负数啊, 这样 (x, y) 就不在该 cell 中了, yolo v2 通过 (sigmoid(x), sigmoid(y)) 来解决这个问题.
yolo 预测的不是类的概率而是类的条件概率, 即条件为如果这个 cell 中包含物体(条件), 那么这个物体是N 类前景中每一类的概率; 每个 grid cell 也会预测该 grid cell 对应的 bbox 属于 \(class_i\) 条件概率 \(P(class_i|Object)\), C 为要预测的 class 的数量.
测试时, 将 confidence score 与 类条件概率相乘;
\[\bf P(Class_i|Object)*P(object)*IOU^{truth}_{pred
}= P(Class_i)*IOU^{truth}_{pred}\]
\(\color{red}{所得结果的含义为 class_i 出现在该 box 的概率以及预测的 bbox 对这个物体的拟合程度.}\)
Training
使用 image 的宽和高标准化 bbox 的宽和高(w, h), 所以 w, h 落在(0, 1]之间
(x, y) 为 bbox 相对于 grid cell 的偏移, 取值也在(0, 1)之间
sum-square 损失函数
由于每个图片中, 有很多 cell 不包含object, 这会对包含 object 的 grid cell 的影响很大, 导致模型不稳定, 或造成训练开始不久就偏离了. 通过减少不包含 object 的 grid cell 对 loss 函数的贡献来解决这个问题.
由于 sum-square 损失函数中, 同一个损失值对大bbox 的影响和它对小 bbox 的影响是相同的, 这样是不好的, 正常情况下对小的 bbox 的影响应该更大才对, 所以我们通过预测 \(\sqrt w\), \(\sqrt h\) 的平方根代替直接预测 \(w, h\).
 

- gt-box 的中心坐在哪个 cell 中, 就由这个 cell 负责预测该 gt-box; 要具体到 cell 中哪个 bbox 负责预测呢? 所谓 cell 中负责 gt-box 预测的 bbox 指的该 cell 中与 gt-box 具有最高 IOU 的 bbox.
- \(I_i^{obj}\) 为包含 gt-box 中心得 cell, 即只有 gt-box 中心落入的 cell 预测的类标签才会参与损失函数
- \(I_{ij}^{obj}\):(从 gt-box 出发理解) 图片中 gt-box 中心落在哪个 cell 中了, 那么这个 cell就负责预测这个物体, 具体为负责 gt-box 预测的 bbox
由此我们可以看到, 这个损失函数的设计要从 gt-boxes 来考虑, 而不是从 cell 的角度来考虑, 我们知道了 gt-boxes 中心落入到那些 cell 中了, 然后我们就知道了一切
yolo v3
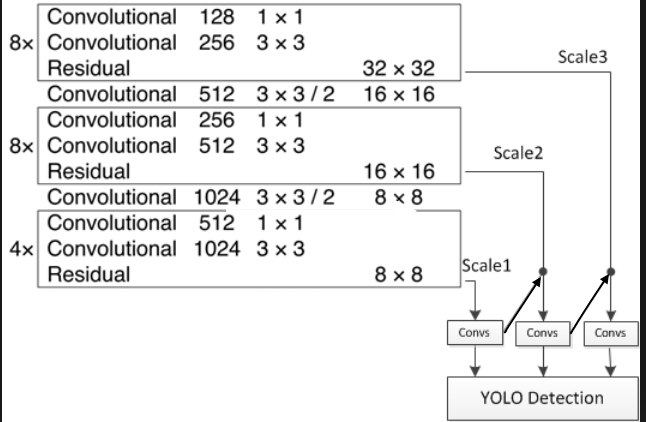 

即 FPN
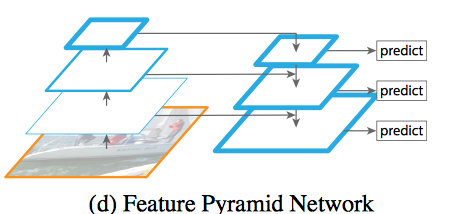 

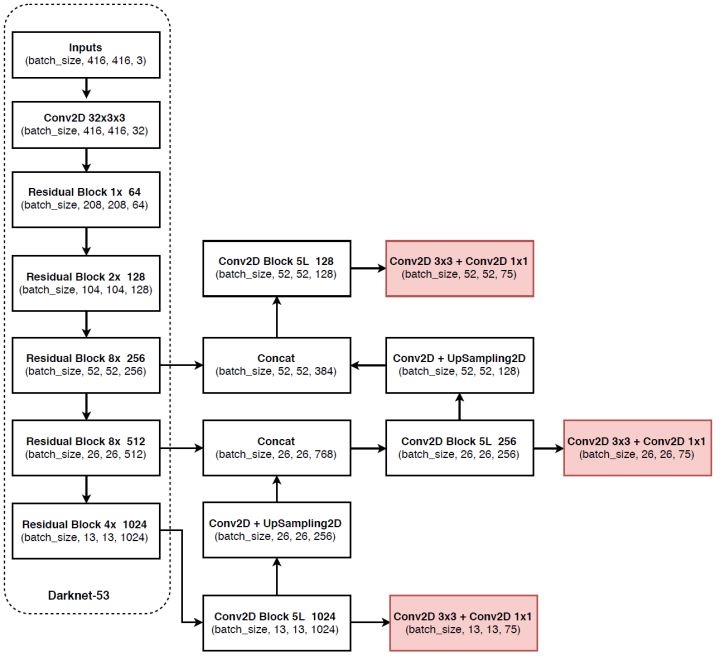 

上采样之后与前一层 concat 之后还需要一个 3x3 卷积来做特征提取(anchor 使用的范式)
上采样方法是双线性差值, 最近邻或者是其他方法? 木看代码, 不清楚, 配置文件也没写, FPN 中使用的是最近邻(nearest neighbor)
yolo的更多相关文章
- YOLO: Real-Time Object Detection
YOLO detection darknet框架使用 YOLO 训练自己的数据步骤,宁广涵详细步骤说明
- paper 111:图像分类物体目标检测 from RCNN to YOLO
参考列表 Selective Search for Object Recognition Selective Search for Object Recognition(菜菜鸟小Q的专栏) Selec ...
- YOLO: Real-Time Object Detection 安装和测试
1.下载darknet git clone https://github.com/pjreddie/darknet.git 2.修改make GPU= CUDNN= OPENCV= DEBUG= 3. ...
- [目标检测]YOLO原理
1 YOLO 创新点: 端到端训练及推断 + 改革区域建议框式目标检测框架 + 实时目标检测 1.1 创新点 (1) 改革了区域建议框式检测框架: RCNN系列均需要生成建议框,在建议框上进行分类与回 ...
- YOLO 算法框架的使用一(初级)
YOLO官方框架使用C写的,性能杠杠的,YOLO算法,我就不做过多介绍了.先简单介绍一下这个框架如何使用.这里默认是yolo2,yolo1接近过时.环境 推荐ubuntu 或者centos YOLO是 ...
- 读论文系列:Object Detection CVPR2016 YOLO
CVPR2016: You Only Look Once:Unified, Real-Time Object Detection 转载请注明作者:梦里茶 YOLO,You Only Look Once ...
- 目标检测算法YOLO算法介绍
YOLO算法(You Only Look Once) 比如你输入图像是100x100,然后在图像上放一个网络,为了方便讲述,此处使用3x3网格,实际实现时会用更精细的网格(如19x19).基本思想是, ...
- TensorFlow + Keras 实战 YOLO v3 目标检测图文并茂教程
运行步骤 1.从 YOLO 官网下载 YOLOv3 权重 wget https://pjreddie.com/media/files/yolov3.weights 下载过程如图: 2.转换 Darkn ...
- YOLO: 3 步实时目标检测安装运行教程 [你看那条狗,好像一条狗!]
封面图是作者运行图,我在 ubuntu 环境下只有文字预测结果. Detection Using A Pre-Trained Model 使用训练好的模型来检测物体 运行一下命令来下载和编译模型 gi ...
- 【深度学习】目标检测算法总结(R-CNN、Fast R-CNN、Faster R-CNN、FPN、YOLO、SSD、RetinaNet)
目标检测是很多计算机视觉任务的基础,不论我们需要实现图像与文字的交互还是需要识别精细类别,它都提供了可靠的信息.本文对目标检测进行了整体回顾,第一部分从RCNN开始介绍基于候选区域的目标检测器,包括F ...
随机推荐
- [DUBBO] Unexpected error occur at send statistic, cause: Forbid consumer 192.168.3.151 access servic
[DUBBO] Unexpected error occur at send statistic, cause: Forbid consumer 192.168.3.151 access servic ...
- 访问内网(https,udp)
安装teamview 客户端. 安装vpn驱动(这里的VPN应该是A主机与B客户端分别连接上了teamview的服务器,但是本身不是局域 网,所以不能直接访问A的局域网的其他主机) 主机端A,安装主机 ...
- Spring Boot项目中的字体文件问题_Failed to decode downloaded font
1.问题:字体文件加载失败,本来应该是“X”号,现在只有一个小方块 2.原因:问题是Maven正在过滤字体文件并破坏它们. <resource> <filtering>true ...
- 网络编程基础【day10】:多线程效果演示(二)
本节内容 1.引子 2.并发多线程效果演示 一.引子 我们说单核的cpu只能同时执行一个任务,但是给我们的一个幻觉是可以执行多个,因为cpu太快了.它是怎么实现的呢?就是上下文切换,它不是轮询着切换的 ...
- JVM jinfo命令(Java Configuration Info) 用法小结
简介 jinfo是jdk自带的命令,可以用来查看正在运行的Java应用程序的扩展参数,甚至支持在运行时,修改部分参数. 通常会先使用jps查看java进程的id,然后使用jinfo查看指定pid的jv ...
- 使用rvm安装与切换Ruby
列出已知的 Ruby 版本 rvm list known安装一个 Ruby 版本 rvm install 2.3.1 --disable-binary这里安装了最新的 2.2.0, rvm list ...
- appcms SSRF 绕过漏洞[转载]
漏洞 <?php if(isset($_GET['url']) && trim($_GET['url']) != '' && isset($_GET['type' ...
- Arrays.asList() 的使用注意
Sometimes it is needed to convert a Java array to List or Collection because the latter is a more po ...
- vue-cli脚手架笔记
vue不支持IE8,因为vue使用了IE8无法模拟的 ECMAScript 5特性 使用vue-cli脚手架会让我们的工作非常方便 比如想编译一下es6的语法就使用 babel loader 和 ba ...
- 自定义CRM系统
写在前面 之前在windows上写代码逻辑.搞前端等花了很长时间,跑通之后一直没往centos上部署, 昨天尝试部署下,结果发现静态文件找不到 =='' 由于写了2个组件: - arya model的 ...