face recognition[MobiFace]
本文来自《MobiFace: A Lightweight Deep Learning Face Recognition on Mobile Devices》,时间线为2018年11月。是作者分别来自CMU和uark学校。
0 引言
随着DCNN的普及,在目标检测,目标分割等领域都有不小的进步,然而其较高准确度背后却是大量的参数和计算量。如AlexNet需要61百万参数量,VGG16需要138百万参数量,Resnet-50需要25百万参数量。Densenet190(k=40)需要40百万参数量。虽然这些网络现在看来都不算很深的网络,可是还是需要200MB和500MB的内存。因此,这样的模型通常是不能部署在移动端或者嵌入式端的。所以最近在图像分类和目标检测领域中也有不少压缩模型被提出来,如剪枝[13,14,32],逐深度卷积[18,38],二值网络[3,4,22,36],mimic网络[31,44]。这些网络可以在没有损失较多准确度的基础上对inference速度进行加速。然而这些模型没有应用在人脸识别领域上。相对于目标检测和人脸分类,人脸识别问题通常需要一定数量的层去提取够鲁棒的辨识性的人脸特征,毕竟人脸模板都一样(两个眼睛,一个嘴巴)。
本文作者提出一个轻量级但是高性能的深度神经网络,以此让人脸识别能部署在移动设备上。相比于其他网络,MobiNet优势有:
- 让MobileNet架构变得更轻量级,提出的MobiNet模型可以很好的部署在移动设备上;
- 提出的MobiNet可以end-to-end的优化;
- 将MobiNet与基于mobile的网络和大规模深度网络在人脸识别数据上进行对比。
1 MobiNet
目前为止,已经有不少轻量级深度网络的设计方案,如binarized networks, quantized networks, mimicked networks, designed compact modules 和 pruned networks。本文主要关注最后两种设计方案。
Designed compact modules
通过整合小的模型或者紧凑的模块和层,可以减少权重的数量,有助于减少内存使用和inference阶段的时间消耗。MobileNet提出一个逐深度分离的卷积模块来代替传统的卷积层,以此明显减少参数量。逐深度卷积操作首先出现在Sifre[41]论文中,然后用在[2,18,38]网络中。在Mobilenet[18]中,空间输入通过一个3x3空间可分通道滤波器进行卷积生成独立的特征,然后接一个逐点(1x1)卷积操作以此生成新的特征。通过这个策略代替传统的卷积操作,使得MobileNet只有4.2百万的参数量和569百万的MAdds。在Imagenet上获得70.6%的结果(VGG16结果是71.5%)。为了提升MobileNet在多任务和benchmark上的性能。Sandler等人提出一个倒置残差和线性botleneck(inverted residuals and linear bottlenecks),叫MobileNet-v2。倒置残差类似[16]中的残差bottleneck,但是中间特征可以关于输入通道的数量扩展到一个特定比例。线性bottleneck是不带有ReLU层的块。MobileNetv2将之前准确度提升到72%,而只需要3.4百万参数量和300百万MAdds。虽然逐深度可分卷积被证实很有效,[18,38]仍然在iphone和安卓上占用很多内存和计算力。而本文发出的时间上,作者并未找到逐深度卷积在CPU上有很好的框架(tf,pytorch,caffe,mxnet)实现。为了减少MobileNet的计算量,FD-Mobilenet中引入快速下采样策略。受到MobileNet-v2的结构启发,MobileFaceNet通过引入相似的网络结构,并通过将全局平均池化层替换成全局逐深度卷积层来减少参数量。
Pruned networks
DNN一直受到参数量巨大和内存消耗很多的困扰。[14]提出一个深度压缩模型通过绝对值去剪枝那些不重要的连接,在Alexnet和VGG16上获得了9x和13x的加速,且并未有多少准确度损失。[32]使用BN中的缩放因子(而不是权重的绝对值)对网络进行瘦身。这些缩放因子通过L1-惩罚进行稀疏训练。在VGG16,DenseNet,ResNet中Slimming networks [32]基于CIFAR数据集获得比原始网络更好的准确度。然而,每个剪枝后的连接索引需要存在内存中,这拉低了训练和测试的速度。
1.1 网络设计策略
带有扩展层的bottleneck残差块(Bottleneck Residual block with the expansion layers)
[37]中引入bottlenect残差块,该块包含三个主要的变换操作,两个线性变换和一个非线性逐通道变换:
- 非线性变换学习复杂的映射函数;
- 在内层中增加了feature map的数量;
- 通过shortcut连接去学习残差。
给定一个输入\(\mathbf{x}\)和对应size为\(h\times w\times k\),一个bottleneck残差块可以表示为:
\[F(\mathbf{x})=[F_1\cdot F_2 \cdot F_3](\mathbf{x})\]
其中,\(F_1:R^{w\times h\times k}\mapsto R^{w\times h\times tk}\),\(F_3:R^{w\times h\times k}\mapsto R^{\frac{w}{s}\times \frac{h}{s}\times k_1}\)都是通过1x1卷积实现的线性函数,t表示扩展因子。\(F_2:R^{w\times h \times tk}\mapsto R^{\frac{w}{s}\times \frac{h}{s}\times tk}\)是非线性映射函数,通过三个操作组合实现的:ReLU,3x3逐深度卷积(stride=s),和ReLU。
在bottleneck块中采用了残差学习连接,以此阻止变换中的流行塌陷和增加特征embedding的表征能力[37]>
快速下采样
基于有限的计算资源,紧凑的网络应该最大化输入图像转换到输出特征中的信息变换,同时避免高代价的计算,如较大的feature map空间维度(分辨率)。在大规模深度网络中,信息流是通过较慢的下采样策略实现的,如空间维度在层之间是缓慢变小的。而轻量级网络不能这样。
所谓快速下采样,就是在特征embedding过程的最初阶段连续使用下采样步骤,以避免feature map的大空间维度,然后在后面的阶段上,增加更多feature map来保证信息流的传递。要注意的是,虽然增加更多feature map,会导致通道数量的上升,但是因为本身feature map的分辨率够小,所以增加的计算代价不大。
1.2 MobiFace
MobiFace网络,给定输入人脸图像size为112x112x3,该轻量级网络意在最大化信息流变换同时减少计算量。基于上述分析,带有扩展层的参数botteneck块(Residual Bottleneck block with expansion layers)可以作为MobiFace的构建块。表1给出了MobiFace的主要结构。
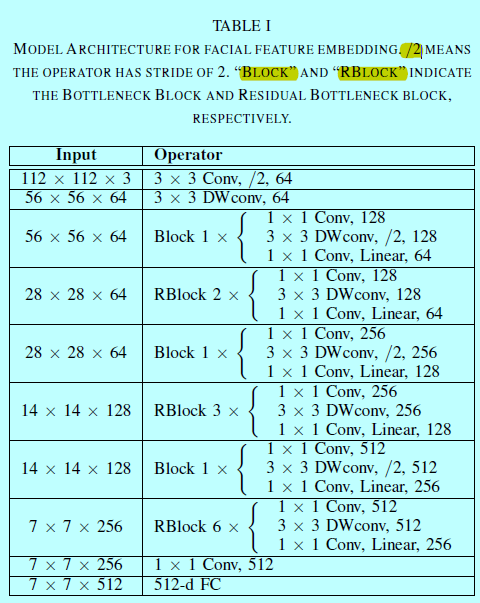
其中DWConv为depthwise conv。如表1所示,MobiFace主要结构包含:
- 一个3x3的卷积层;
- 一个3x3的逐深度分离卷积层(depthwise separable convolutional layer);
- 一系列bottleneck块和残差bottleneck块;
- 一个1x1卷积层;
- 一个全连接层。
其中残差bottleneck块和bottleneck块很像,除了残差bottleneck块会添加shortcut方式以连接1×1卷积层的输入和输出。而且在bottleneck 块中stride=2,而在残差bottleneck块中每层stride=1。
MobiFace通过引入快速下采样策略,快速减少层/块的空间维度。可以发现本来输入大小为112x112x3,在前两层就减少了一半,并且在后面7个bottleneck块中就减少了8x之多。扩展因子保持为2,而通道数在每个bottleneck块后就翻倍了。
除了标记为“linear”的卷积层之外,在每个卷积层之后应用BN和非线性激活函数。本文中,主要用PReLU而不是ReLU。在Mobiface最后一层,不采用全局平均池化层,而是采用全连接层。因为全局平均池化是无差别对待每个神经元(而中间区域神经元的重要性要大于边缘区域神经元),FC层可以针对不同神经元学到不同权重,从而将此类信息嵌入到最后的特征向量中。
2 实验
先基于提炼后的MS-Celeb-1M数据集(3.8百万张图片,85个ID)进行训练,然后在LFW和MegaFace数据集上进行评估结果。
2.1 实现细节
在预处理阶段,采用MTCNN模型进行人脸检测和5个关键点检测。然后将其对齐到112x112x3上。然后通过减去127.5并除以128进行归一化。在训练阶段,通过SGD进行训练,batchsize为1024,动量为0.9.学习率在40K,60K,80K处分别除以10。一共迭代100K次。
2.2 人脸验证准确度
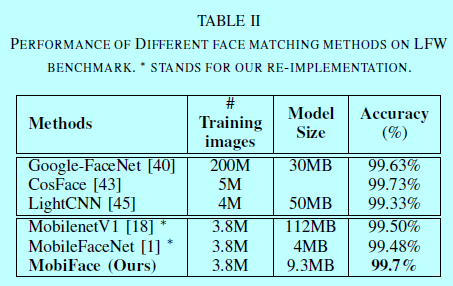
表2给出了在LFW上的benckmark。
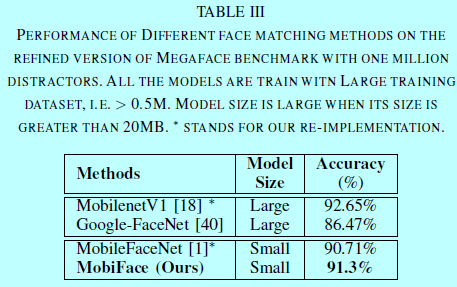
表3给出了MegaFace数据集上的验证结果。
reference:
[1] S. Chen, Y. Liu, X. Gao, and Z. Han. Mobilefacenets: Efficient cnns for accurate real-time face verification on mobile devices. arXiv preprint arXiv:1804.07573, 2018.
[2] F. Chollet. Xception: Deep learning with depthwise separable convolutions. In CVPR, pages 1800–1807. IEEE Computer Society, 2017.
[3] M. Courbariaux and Y. Bengio. Binarynet: Training deep neural networks with weights and activations constrained to +1 or -1. CoRR, abs/1602.02830, 2016.
[4] M. Courbariaux, Y. Bengio, and J. David. Binaryconnect: Training deep neural networks with binary weights during propagations. In NIPS, pages 3123–3131, 2015.
[5] J. Deng, W. Dong, R. Socher, L. jia Li, K. Li, and L. Fei-fei. Imagenet: A large-scale hierarchical image database. In In CVPR, 2009.
[6] C. N. Duong, K. Luu, K. Quach, and T. Bui. Beyond principal components: Deep boltzmann machines for face modeling. In CVPR, 2015.
[7] C. N. Duong, K. Luu, K. Quach, and T. Bui. Longitudinal face modeling via temporal deep restricted boltzmann machines. In CVPR, 2016.
[8] C. N. Duong, K. Luu, K. Quach, and T. Bui. Deep appearance models: A deep boltzmann machine approach for face modeling. Intl Journal of Computer Vision (IJCV), 2018.
[9] C. N. Duong, K. G. Quach, K. Luu, T. H. N. Le, and M. Savvides. Temporal non-volume preserving approach to facial age-progression and age-invariant face recognition. In ICCV, 2017.
[10] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. 2014.
[11] Y. Guo, L. Zhang, Y. Hu, X. He, and J. Gao. Ms-celeb-1m: A dataset and benchmark for large-scale face recognition. In European Conference on Computer Vision, pages 87–102. Springer, 2016.
[12] M. S. H. N. Le, R. Gummadi. Deep recurrent level set for segmenting brain tumors. In Medical Image Computing and Computer Assisted Intervention (MICCAI), pages 646–653. Springer, 2018.
[13] S. Han, H. Mao, and W. J. Dally. Deep compression: Compressing deep neural network with pruning, trained quantization and huffman coding. CoRR, abs/1510.00149, 2015.
[14] S. Han, J. Pool, J. Tran, and W. J. Dally. Learning both weights and connections for efficient neural networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems - Volume 1, NIPS’15, pages 1135–1143, Cambridge, MA, USA, 2015. MIT Press.
[15] K. He, G. Gkioxari, P. Doll´ar, and R. Girshick. Mask R-CNN. In Proceedings of the International Conference on Computer Vision (ICCV), 2017.
[16] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In CVPR, pages 770–778, 2016.
[17] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
[18] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam. Mobilenets: Efficient convolutional neural networks for mobile vision applications. CoRR, abs/1704.04861, 2017.
[19] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861, 2017.
[20] G. Huang, Z. Liu, L. van der Maaten, and K. Q. Weinberger. Densely connected convolutional networks. In CVPR, pages 2261–2269, 2017.
[21] G. B. Huang, M. Mattar, T. Berg, and E. Learned-Miller. Labeled faces in the wild: A database forstudying face recognition in unconstrained environments. In Workshop on faces in’Real-Life’Images: detection, alignment, and recognition, 2008.
[22] I. Hubara, M. Courbariaux, D. Soudry, R. El-Yaniv, and Y. Bengio. Binarized neural networks. In NIPS, pages 4107–4115, 2016.
[23] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In ICML, volume 37, pages 448–456. JMLR.org, 2015.
[24] Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. B. Girshick, S. Guadarrama, and T. Darrell. Caffe: Convolutional architecture for fast feature embedding. In ACM Multimedia, pages 675–678. ACM, 2014.
[25] I. Kemelmacher-Shlizerman, S. M. Seitz, D. Miller, and E. Brossard. The megaface benchmark: 1 million faces for recognition at scale. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4873–4882, 2016.
[26] A. Krizhevsky and G. Hinton. Learning multiple layers of features from tiny images. Master’s thesis, Department of Computer Science, University of Toronto, 2009.
[27] A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In F. Pereira, C. J. C. Burges, L. Bottou, and K. Q. Weinberger, editors, Advances in Neural Information Processing Systems 25, pages 1097–1105. Curran Associates, Inc., 2012.
[28] H. N. Le, C. N. Duong, K. Luu, and M. Savvides. Deep contextual recurrent residual networks for scene labeling. In Journal of Pattern Recognition, 2018.
[29] H. N. Le, K. G. Quach, K. Luu, and M. Savvides. Reformulating level sets as deep recurrent neural network approach to semantic segmentation. In Trans. on Image Processing (TIP), 2018.
[30] H. N. Le, C. Zhu, Y. Zheng, K. Luu, and M. Savvides. Robust hand detection in vehicles. In Intl. Conf. on Pattern Recognition (ICPR), 2016.
[31] Q. Li, S. Jin, and J. Yan. Mimicking very efficient network for object detection. 2017 IEEE Conference on CVPR, pages 7341–7349, 2017.
[32] Z. Liu, J. Li, Z. Shen, G. Huang, S. Yan, and C. Zhang. Learning efficient convolutional networks through network slimming. 2017 IEEE International Conference on Computer Vision (ICCV), pages 2755–2763, 2017.
[33] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In CVPR.
[34] A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Yang, Z. DeVito, Z. Lin, A. Desmaison, L. Antiga, and A. Lerer. Automatic differentiation in pytorch. 2017.
[35] Z. Qin, Z. Zhang, X. Chen, C. Wang, and Y. Peng. Fd-mobilenet: Improved mobilenet with a fast downsampling strategy. In 2018 25th IEEE International Conference on Image Processing (ICIP), pages 1363–1367. IEEE, 2018.
[36] M. Rastegari, V. Ordonez, J. Redmon, and A. Farhadi. Xnor-net: Imagenet classification using binary convolutional neural networks. In ECCV (4), volume 9908 of Lecture Notes in Computer Science, pages 525–542. Springer, 2016.
[37] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4510–4520, 2018.
[38] M. Sandler, A. G. Howard, M. Zhu, A. Zhmoginov, and L. Chen. Inverted residuals and linear bottlenecks: Mobile networks for classification, detection and segmentation. CoRR, abs/1801.04381, 2018.
[39] M. W. Schmidt, G. Fung, and R. Rosales. Fast optimization methods for l1 regularization: A comparative study and two new approaches. In ECML, 2007.
[40] F. Schroff, D. Kalenichenko, and J. Philbin. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 815–823, 2015.
[41] L. Sifre. Rigid-motion scattering for image classification, 2014.
[42] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition, 2014.
[43] H. Wang, Y. Wang, Z. Zhou, X. Ji, D. Gong, J. Zhou, Z. Li, and W. Liu. Cosface: Large margin cosine loss for deep face recognition. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
[44] Y. Wei, X. Pan, H. Qin, and J. Yan. Quantization mimic: Towards very tiny cnn for object detection. CoRR, abs/1805.02152, 2018.
[45] X. Wu, R. He, Z. Sun, and T. Tan. A light cnn for deep face representation with noisy labels. IEEE Transactions on Information Forensics and Security, 13(11):2884–2896, 2018.
[46] K. Zhang, Z. Zhang, Z. Li, and Y. Qiao. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Processing Letters, 23(10):1499–1503, 2016.
[47] Y. Zheng, C. Zhu, K. Luu, H. N. Le, C. Bhagavatula, and M. Savvides. Towards a deep learning framework for unconstrained face detection. In BTAS, 2016.
[48] C. Zhu, Y. Ran, K. Luu, and M. Savvides. Seeing small faces from robust anchor’s perspective. In CVPR, 2018.
[49] C. Zhu, Y. Zheng, K. Luu, H. N. Le, C. Bhagavatula, and M. Savvides. Weakly supervised facial analysis with dense hyper-column features. In IEEE Conference on Computer Vision and Pattern Recognition Workshop (CVPRW), 2016.
[50] C. Zhu, Y. Zheng, K. Luu, and M. Savvides. Enhancing interior and exterior deep facial features for face detection in the wild. In Intl Conf. on Automatic Face and Gesture Recognition (FG), 2018.
face recognition[MobiFace]的更多相关文章
- One-Time Project Recognition
Please indicate the source if you need to repost. After implementing NetSutie for serveral companies ...
- 论文阅读(Xiang Bai——【TIP2014】A Unified Framework for Multi-Oriented Text Detection and Recognition)
Xiang Bai--[TIP2014]A Unified Framework for Multi-Oriented Text Detection and Recognition 目录 作者和相关链接 ...
- 论文阅读(Lukas Neuman——【ICDAR2015】Efficient Scene Text Localization and Recognition with Local Character Refinement)
Lukas Neuman--[ICDAR2015]Efficient Scene Text Localization and Recognition with Local Character Refi ...
- 论文阅读(Xiang Bai——【PAMI2017】An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition)
白翔的CRNN论文阅读 1. 论文题目 Xiang Bai--[PAMI2017]An End-to-End Trainable Neural Network for Image-based Seq ...
- VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION 这篇论文
由Andrew Zisserman 教授主导的 VGG 的 ILSVRC 的大赛中的卷积神经网络取得了很好的成绩,这篇文章详细说明了网络相关事宜. 文章主要干了点什么事呢?它就是在在用卷积神经网络下, ...
- Pattern Recognition And Machine Learning读书会前言
读书会成立属于偶然,一次群里无聊到极点,有人说Pattern Recognition And Machine Learning这本书不错,加之有好友之前推荐过,便发了封群邮件组织这个读书会,采用轮流讲 ...
- Notes on 'Selective Search For Object Recognition'
UijlingsIJCV2013, Selective Search For Object Recognition code 算法思想 利用分割算法将图片细分成很多region, 或超像素. 在这个基 ...
- 自然语言18.1_Named Entity Recognition with NLTK
QQ:231469242 欢迎nltk爱好者交流 https://www.pythonprogramming.net/named-entity-recognition-nltk-tutorial/?c ...
- 自然语言18_Named-entity recognition
https://en.wikipedia.org/wiki/Named-entity_recognition http://book.51cto.com/art/201107/276852.htm 命 ...
随机推荐
- python地理处理包——Shapely介绍及用户手册
本文主要是基于shapely官方文档翻译而成 shapely主要是在笛卡尔平面对几何对象进行操作和分析. 性能 Shapely中所有的操作都是使用GEOS库.GEOS是用C++写的,也被用在许多应用程 ...
- 7.Odoo产品分析 (二) – 商业板块(3) –CRM(1)
查看Odoo产品分析系列--目录 CMR:Customer Relationship Management.企业为提高核心竞争力,利用相应的信息技术以及互联网技术协调企业与顾客间在销售.营销和服务上的 ...
- SSIS 包部署错误 0xC0010014
SSIS 包部署错误 0xC0010014 Reinhard 在部署 SSIS 包时,提示如下错误. 由于错误 0xC0010014"发生了一个或多个错误.在此消息之前应有更为具体的错误消息 ...
- 小程序实践(三):九宫格实现及item跳转
效果图: 实现效果图红色线包含部分的九宫格效果,并附带item点击时间. --------------------------------------------------------------- ...
- svn状态与常见错误
TortoiseSVN 1.6.16是最后一个目录独立管理自身cache的svn版本(每个目录下都有一个隐藏的.svn文件夹) 之后的版本会则会根目录上统一进行管理(只有根目录下有一个隐藏的.svn文 ...
- sql server 通用修改表数据存储过程
ALTER PROC [dbo].[UpdateTableData] ), ), ), ), ) AS BEGIN ) SET @sql ='UPDATE '+@TableName; --获取SqlS ...
- EOS智能合约开发(一):EOS环境搭建和启动节点
EOS和以太坊很像,EOS很明确的说明它就是一个区块链的操作系统,BM在博客中也是说过的. 可以这样比喻,EOS就相当于内置激励系统的Windows/Linux/MacOS,这是它的一个定位. 包括以 ...
- Linux唤醒抢占----Linux进程的管理与调度(二十三)
1. 唤醒抢占 当在try_to_wake_up/wake_up_process和wake_up_new_task中唤醒进程时, 内核使用全局check_preempt_curr看看是否进程可以抢占当 ...
- Linux补充
1.从国内豆瓣源安装软件 pip install -i https://pypi.doubanio.com/simple paramiko --trusted-host pypi.douban.com
- 《Java大学教程》—第22章 多线程程序
22.2 进程(process):P551时间切片(time-slicing):处理器只是完成了一个任务的一部分工作,然后完成下一个任务的一部分工作,因为处理吕每次完成工作的时间都非常短,因此看起来这 ...