mybatis的延迟加载、一级缓存、二级缓存
mybatis的延迟加载、一级缓存、二级缓存
mybatis是什么?
mybatis是一个持久层框架,是apache下的开源项目,前身是itbatis,是一个不完全的ORM框架,mybatis提供输入和输出的映射,需要程序员自己写sql语句,mybatis重点对 sql语句的灵活操作。
适合用于:需求变化频繁, 数据模型不固定的项目,例如:互联网项目。
mybatis架构?
SqlMapConfig.xml(名称不固定),配置内容:数据源、事务、properties、typeAliases、settings、mapper配置。
SqlSessionFactory--会话工厂,作用是创建SqlSession,实际开发中以单例模式管理 SqlSessionFactory。
SqlSession--会话,是一个面向用户(程序员)的接口,使用mapper代理方法开发是不需要程序员直接调用sqlSession的方法。是线程不安全,最佳适用场合方法体内。
mybatis开发dao的方法:
1、原始dao开发方法,需要程序员编写dao接口和实现类,此方法在当前企业中还有使用,因为ibatis使用的就是原始dao开发方法。
2、mapper代理方法,程序员只需要写mapper接口(相当于dao接口),mybatis自动根据mapper接口和mapper接口对应的statement自动生成代理对象(接口实现类对象)。
开发需要遵循规则:
1)mapper.xml中namespace是mapper接口的全限定名
2)mapper.xml中statement的id为mapper接口方法名
3)mapper.xml中statement的输入映射类型(parameterType)和mapper接口方法输入参数类型一致
4) mapper.xml中statement的输出映射类型(resultType)和mapper接口方法返回结果类型一致
resultType和resultMap都可以完成输出映射:
resultType映射要求sql查询的列名和输出映射pojo类型的属性名一致
resultMap映射时对sql查询的列名和输出映射pojo类型的属性名作一个对应关系。
动态sql:
#{}和${}完成输入参数的属性值获取,通过OGNL获取parameterType指定pojo的属性名。
#{}:占位符号,好处防止sql注入
${}:sql拼接符号
if
where
foreach

商品订单数据模型:
注意:分析表与表之间的关系时是要建立在具体 的业务意义基础之上
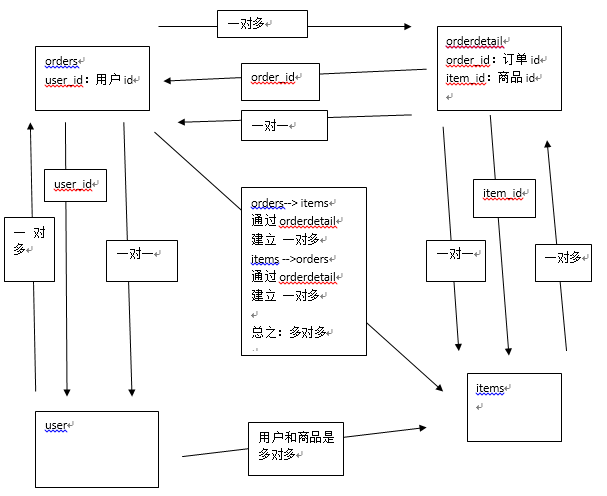
用户表user:记录了购买商品的用户
订单表orders:记录了用户所创建的订单信息
订单明细表orderdetail:记录了用户创建订单的详细信息
商品信息表items:记录了商家提供的商品信息
分析表与表之间的关系:
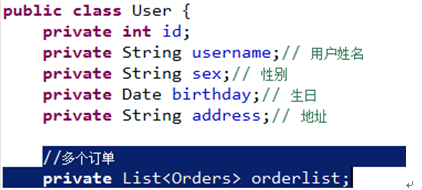
用户user和订单orders:
user---->orders:一个用户可以创建多个订单 一对多
orders-->user:一个订单只能由一个用户创建 一对一
订单orders和订单明细orderdetail:
orders-->orderdetail:一个订单可以包括多个订单明细 一对多
orderdetail-->orders:一个订单明细只属于一个订单 一对一
订单明细orderdetail和商品信息items:
orderdetail-->items:一个订单明细对应一个商品信息 一对一
items--> orderdetail:一个商品对应多个订单明细 一对多
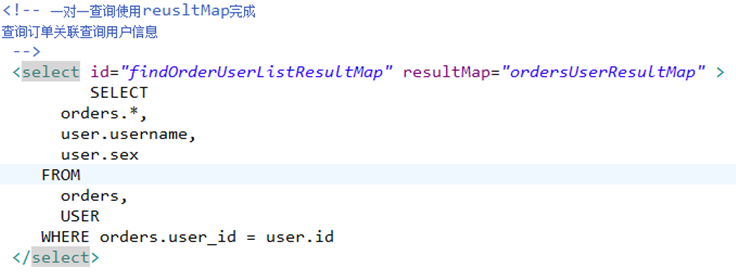
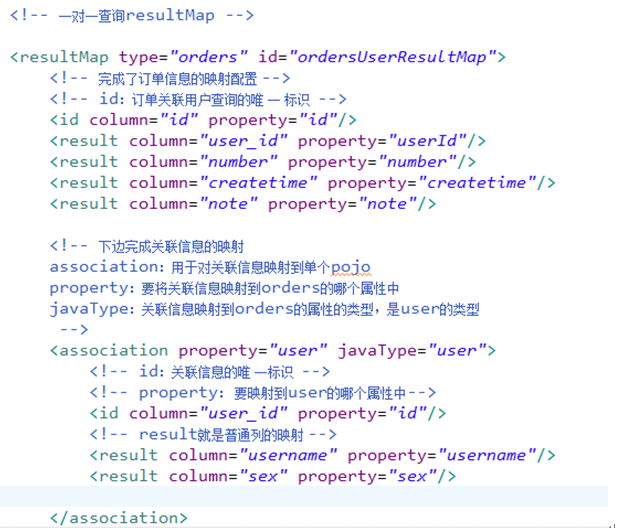
一对一查询:
小结:
resultType:要自定义pojo 保证sql查询列和pojo的属性对应,这种方法相对较简单,所以应用广泛。
resultMap:使用association完成一对一映射需要配置一个resultMap,过程有点复杂,如果要实现延迟加载就只能用resultMap实现 ;如果为了方便对关联信息进行解析,也可以用association将关联信息映射到pojo中方便解析。
一对多查询:
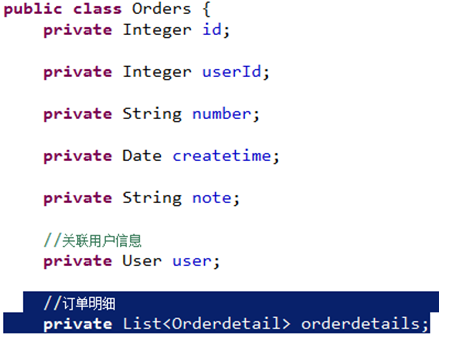
在orders类中创建集合属性:
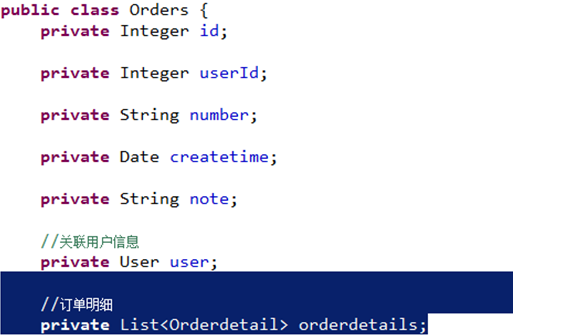
mapper.xml
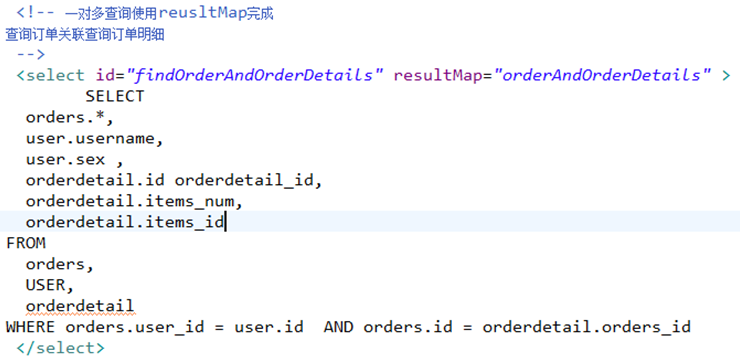
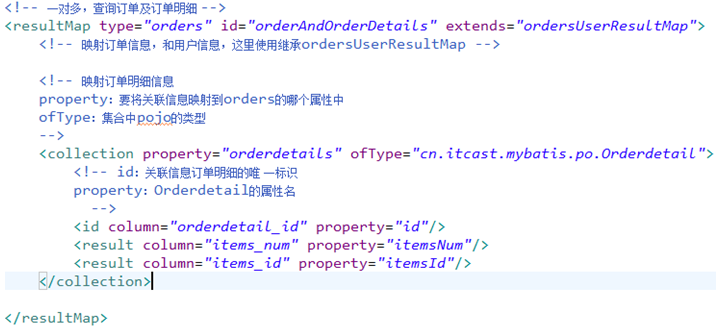
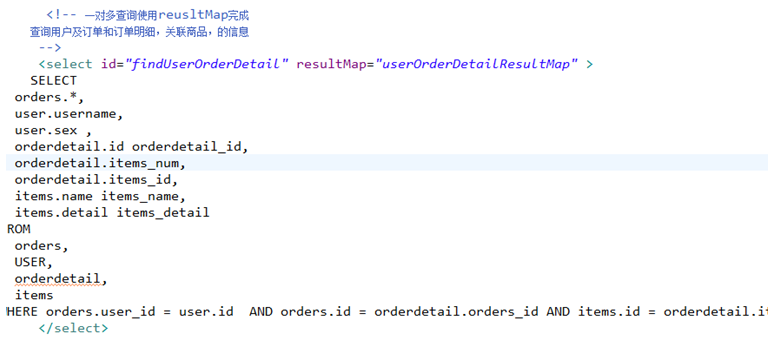
一对多查询(复杂):
主查询表:用户信息
关联查询:订单、订单明细,商品信息
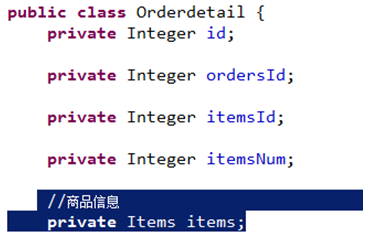
pojo定义:
mapper.xml

1、延迟加载
1.1 使用延迟加载意义
在进行数据查询时,为了提高数据库查询性能,尽量使用单表查询,因为单表查询比多表关联查询速度要快。
如果查询单表就可以满足需求,一开始先查询单表,当需要关联信息时,再关联查询,当需要关联信息再查询这个叫延迟加载。
mybatis中resultMap提供延迟加载功能,通过resultMap配置延迟加载。
1.2 配置mybatis支持延迟加载
|
设置项 |
描述 |
允许值 |
默认值 |
|
lazyLoadingEnabled |
全局性设置懒加载。如果设为‘false’,则所有相关联的都会被初始化加载。 |
true | false |
false |
|
aggressiveLazyLoading |
当设置为‘true’的时候,懒加载的对象可能被任何懒属性全部加载。否则,每个属性都按需加载。 |
true | false |
true |
<!-- 全局配置参数 -->
<settings>
<!-- 延迟加载总开关;lazyLoadingEnabled:延迟加载启动,默认是false -->
<setting name="lazyLoadingEnabled" value="true" />
<!-- 设置按需加载;aggressiveLazyLoading:积极的懒加载,false的话按需加载,默认是true -->
<setting name="aggressiveLazyLoading" value="false" /> <!-- 开启二级缓存,默认是false -->
<setting name="cacheEnabled" value="true"/> </settings>
1.3延迟加载的实现:
需求:
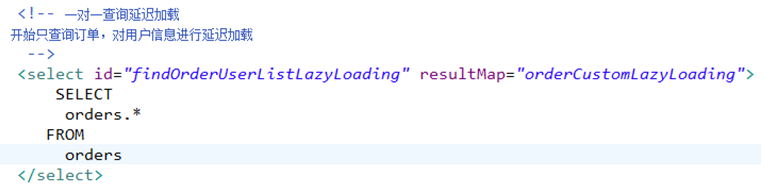
查询订单及用户的信息,一对一查询。
刚开始只查询订单信息
当需要用户时调用 Orders类中的getUser()方法执行延迟加载 ,向数据库发出sql。
mapper.xml
resultMap
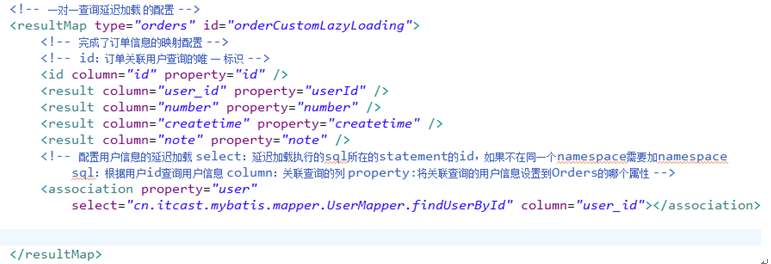
测试代码:

小结:一对多延迟加载的方法同一对一延迟加载,在collection标签中配置select内容。
1.4resultType、resultMap、延迟加载使用场景总结
延迟加载:
延迟加载实现的方法多种多样,在只查询单表就可以满足需求,为了提高数据库查询性能使用延迟加载,再查询关联信息。
mybatis提供延迟加载的功能用于service层。
resultType:
作用: 将查询结果按照sql列名pojo属性名一致性映射到pojo中。
场合: 常见一些明细记录的展示,将关联查询信息全部展示在页面时,此时可直接使用resultType将每一条记录映射到pojo中,在前端页面遍历list(list中是pojo)即可。
resultMap:
使用association和collection完成一对一和一对多高级映射。
association:
作用:将关联查询信息映射到一个pojo类中。
场合:为了方便获取关联信息可以使用association将关联订单映射为pojo,比如:查询订单及关联用户信息。
collection:
作用:将关联查询信息映射到一个list集合中。
场合:为了方便获取关联信息可以使用collection将关联信息映射到list集合中,比如:查询用户权限范围模块和功能,可使用collection将模块和功能列表映射到list中。
2、查询缓存
2.1 缓存的意义:
将用户经常查询的数据放在缓存(内存)中,用户去查询数据就不用从磁盘上(关系型数据库数据文件)查询,从缓存中查询,从而提高查询效率,解决了高并发系统的性能问题。
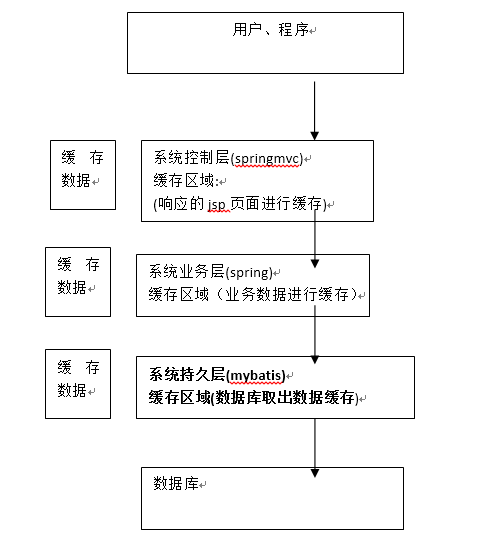
2.2 mybatis持久层缓存
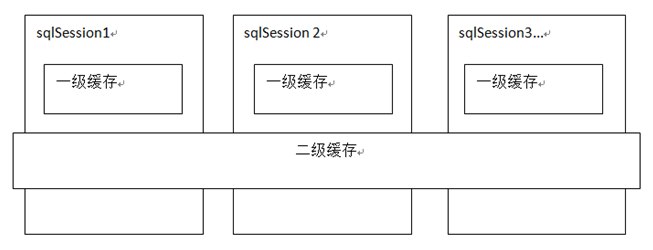
mybatis一级缓存是一个SqlSession级别,sqlsession只能访问自己的一级缓存的数据,二级缓存是跨sqlSession,是mapper级别的缓存,对于mapper级别的缓存不同的sqlsession是可以共享的。
2.3 一级缓存
2.3.1 原理:
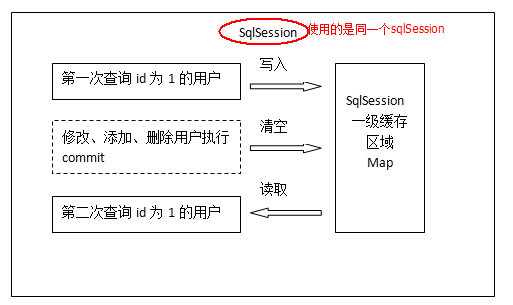
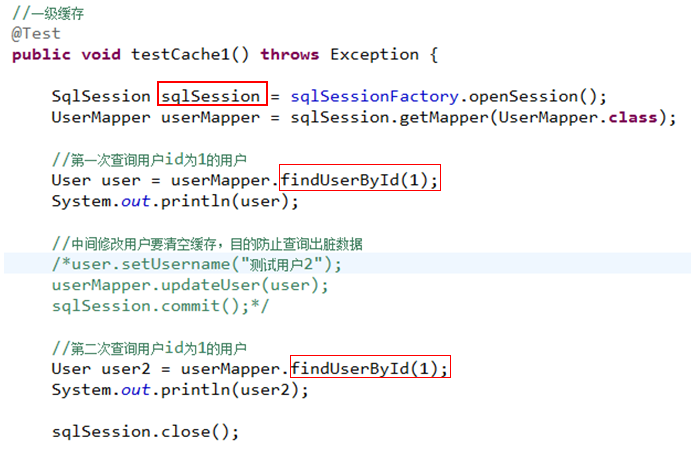
第一次发出一个查询sql,sql查询结果写入sqlsession的一级缓存中,缓存使用的数据结构是一个map<key,value>
key:hashcode+sql+sql输入参数+输出参数(sql的唯一标识)
value:用户信息
,同一个sqlsession再次发出相同的sql,就从缓存中取不走数据库。如果两次中间出现commit操作(修改、添加、删除),本sqlsession中的一级缓存区域全部清空,下次再去缓存中查询不到所以要从数据库查询,从数据库查询到再写入缓存。
2.3.2 一级缓存配置
mybatis默认支持一级缓存不需要配置,默认开启。
注意:mybatis和spring整合后进行mapper代理开发,不支持一级缓存,mybatis和spring整合,spring按照mapper的模板去生成mapper代理对象,模板中在最后统一关闭sqlsession。
2.3.3 一级缓存测试
2.4 二级缓存
2.4.1 原理

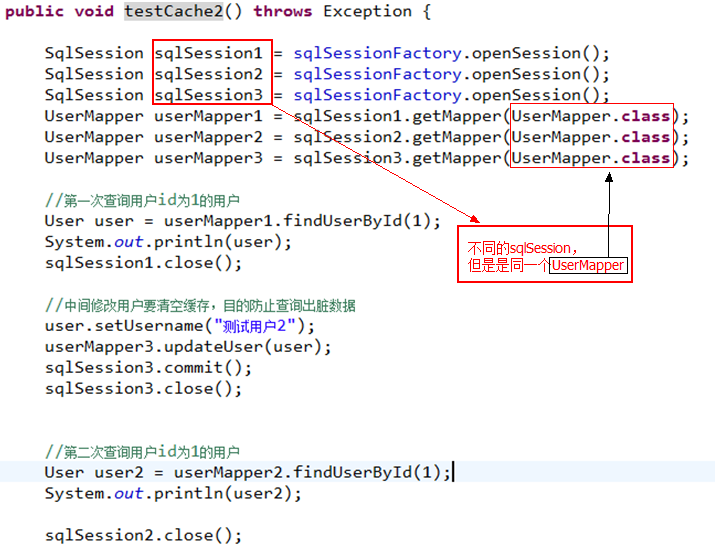
二级缓存的范围是mapper级别(mapper同一个命名空间),mapper以命名空间为单位创建缓存数据结构,结构是map<key、value>。
每次查询先看是否开启二级缓存,如果开启从二级缓存的数据结构中取缓存数据,
如果从二级缓存没有取到,再从一级缓存中找,如果一级缓存也没有,从数据库查询。
2.4.2 二级缓存的配置
在核心配置文件SqlMapConfig.xml中加入
<setting name="cacheEnabled" value="true"/>
|
描述 |
允许值 |
默认值 |
|
|
cacheEnabled |
对在此配置文件下的所有cache 进行全局性开/关设置。 |
true false |
true |
要在你的Mapper映射文件中添加一行: <cache /> ,表示此mapper开启二级缓存。
它将采用默认的行为进行缓存:
a.映射文件中所有的select语句将被缓存
b.映射文件中所有的insert、update和delete语句将刷新缓存
c.缓存将使用LRU(Least Recently Used)最近最少使用策略算法来回收
d.flushInterval:刷新间隔(no Flush Interval,没有刷新间隔),缓存不会以任何时间顺序来刷新
e.size(引用数目):缓存会存储列表集合和对象(无论查询方法返回什么)的1024个引用;可以被设置为任意正整数,要记住你缓存的对象数目和你运行环境的可用内存资源数目。默认值是1024。
f.readOnly(只读):缓存会属性可以被设置为true或false,被视为read/write(可读/可写)的缓存;只读的缓存会给所有调用者返回缓存对象的相同实例,因此这些对象不能被修改,这提供了很重要的性能优势;可读写的缓存会返回缓存对象的拷贝(通过序列化),这会慢一些,但是安全,因此默认是false。这意味着对象检索不是共享的,而且可以安全的被调用者修改,而不干扰其他调用者或者线程所做的潜在修改。
所有这些属性都可以通过缓存元素的属性来修改,比如:
<cache
eviction="FIFO"
flushInterval="60000"
size="512"
readOnly="true"
/>
这个更高级的配置创建了一个FIFO缓存,并每隔60秒(上面自己设置的)刷新缓存,储存结果对象或列表的512个引用,而且返回的对象被认为是只读的,因此在不同线程中的调用者之间修改他们会导致冲突。
可用的收回策略有:
LRU【默认】——最近最少使用的:移除最长时间不被使用的对象
FIFO——先进先出的:按对象进入缓存的顺序来移除他们
SOFT——软引用:移除基于垃圾回收器状态和软引用规则的对象
WEAK——弱引用:更积极地移除基于垃圾收集器状态和弱引用规则的对象。
flushInterval(刷新间隔)可以被设置为任意的正整数(60*60*1000这种形式是不允许的),而且它们代表一个合理的毫秒形式的时间段。默认情况是不设置,也就是没有刷新间隔,缓存仅仅调用语句时刷新。
size(引用数目)可以被设置为任意正整数,要记住你缓存的对象数目和你运行环境的可用内存资源数目。默认值是1024。
readOnly(只读)属性可以被设置为true或false。只读的缓存会给所有调用者返回缓存对象的相同实例,因此这些对象不能被修改,这提供了很重要的性能优势。可读写的缓存会返回缓存对象的拷贝(通过发序列化)。这会慢一些,但是安全,因此默认是false。
配置完<cache/>表示该mapper映射文件中,所有的select语句都将被缓存,所有的insert、update和delete语句都将刷新缓存。但是实际中,我们并是希望这样,有些select不想被缓存时,可以添加select的属性useCache=“false”;有些insert、update和delete不想让他刷新缓存时,添加属性flushCache=”false ”
2.4.3 查询结果映射的POJO序列化
mybatis二级缓存需要将查询结果映射的pojo实现 java.io.serializable接口,如果不实现则抛出异常:org.apache.ibatis.cache.CacheException: Error serializing object. Cause: java.io.NotSerializableException: com.mmzs.mybatis.po.User
二级缓存可以将内存的数据写到磁盘,存在对象的序列化和反序列化,所以要实现java.io.serializable接口。如果结果映射的pojo中还包括了pojo,都要实现java.io.serializable接口。
2.4.4 二级缓存的禁用
对于变化频率较高的sql,需要禁用二级缓存:
在statement中设置useCache=false可以禁用当前select语句的二级缓存,即每次查询都会发出sql去查询,默认情况是true,即该sql使用二级缓存。
<select id="findOrderListResultMap" resultMap="ordersUserMap" useCache="false">
2.4.5 刷新缓存
如果sqlsession操作commit操作,对二级缓存进行刷新(全局清空)。
设置statement的flushCache是否刷新缓存,默认值是true。
2.4.6 二级缓存测试
2.4.7 二级缓存的应用场景
对查询频率高,变化频率低的数据建议使用二级缓存。
对于访问多的查询请求且用户对查询结果实时性要求不高,此时可采用mybatis二级缓存技术降低数据库访问量,提高访问速度,业务场景比如:耗时较高的统计分析sql、电话账单查询sql等。
实现方法如下:通过设置刷新间隔时间,由mybatis每隔一段时间自动清空缓存,根据数据变化频率设置缓存刷新间隔flushInterval,比如设置为30分钟、60分钟、24小时等,根据需求而定。
2.4.8 mybatis的局限性
mybatis二级缓存对细粒度的数据级别的缓存实现不好,比如如下需求:对商品信息进行缓存,由于商品信息查询访问量大,但是要求用户每次都能查询最新的商品信息,此时如果使用mybatis的二级缓存就无法实现当一个商品变化时只刷新该商品的缓存信息而不刷新其它商品的信息,因为mybaits的二级缓存区域以mapper为单位划分,当一个商品信息变化会将所有商品信息的缓存数据全部清空。解决此类问题需要在业务层根据需求对数据有针对性缓存。
mybatis的延迟加载、一级缓存、二级缓存的更多相关文章
- Mybatis一级、二级缓存
Mybatis一级.二级缓存 一级缓存 首先做一个测试,创建一个mapper配置文件和mapper接口,我这里用了最简单的查询来演示. <mapper namespace="c ...
- MyBatis(七):MyBatis缓存详解(一级缓存/二级缓存)
一级缓存 MyBatis一级缓存上SqlSession缓存,即在统一SqlSession中,在不执行增删改操作提交事务的前提下,对同一条数据进行多次查询时,第一次查询从数据库中查询,完成后会存入缓 ...
- Mybatis基于注解开启使用二级缓存
关于Mybatis的一级缓存和二级缓存的概念以及理解可以参照前面文章的介绍.前文连接:https://www.cnblogs.com/hopeofthevillage/p/11427438.html, ...
- Hibernate 再接触 一级缓存 二级缓存 查询缓存
缓存 就是把本来应该放在硬盘里的东西放在内存里 将来存内存里读 一级缓存: session缓存 二级缓存: sessionFactory级别的 (适合经常访问,数据量有限,改动不大) 很多的se ...
- hibernate的获取session的两方法比较,和通过id获取对象的比较,一级缓存二级缓存
opensession与currentsession的联系与区别 在同一个线程中opensession的session是不一样的,而currentsession获取的session是一样的,这就保证了 ...
- mybatis一级缓存二级缓存
一级缓存 Mybatis对缓存提供支持,但是在没有配置的默认情况下,它只开启一级缓存,一级缓存只是相对于同一个SqlSession而言.所以在参数和SQL完全一样的情况下,我们使用同一个SqlSess ...
- mybatis学习--缓存(一级和二级缓存)
声明:学习摘要! MyBatis缓存 我们知道,频繁的数据库操作是非常耗费性能的(主要是因为对于DB而言,数据是持久化在磁盘中的,因此查询操作需要通过IO,IO操作速度相比内存操作速度慢了好几个量级) ...
- mybatis的缓存机制(一级缓存二级缓存和刷新缓存)和mybatis整合ehcache
1.1 什么是查询缓存 mybatis提供查询缓存,用于减轻数据压力,提高数据库性能. mybaits提供一级缓存,和二级缓存. 一级缓存是SqlSession级别的缓存.在操作数据库时需要构造 s ...
- 【mybatis源码学习】mybtias一级,二级缓存
转载:https://www.cnblogs.com/ysocean/p/7342498.html mybatis 为我们提供了一级缓存和二级缓存,可以通过下图来理解: ①.一级缓存是SqlSessi ...
- 170214、mybatis一级和二级缓存
mybatis一级缓存是指在内存中开辟一块区域,用来保存用户对数据库的操作信息(sql)和数据库返回的数据,如果下一次用户再执行相同的请求, 那么直接从内存中读数数据而不是从数据库读取. 其中数据的生 ...
随机推荐
- alfred3配置
搜索功能配置 github https://github.com/search?utf8=%E2%9C%93&q={query} github'{query}' g baidu http:// ...
- Android程序backtrace分析方法
如何分析Android程序的backtrace 最近碰到Android apk crash的问题,单从log很难定位.从tombstone里面得到下面的backtrace. *** *** *** * ...
- 学习Python第七天
进制拾遗: 二进制:01 八进制:01234567 十进制:0123456789 十六进制:0123456789ABCDEF 十进制转换八,十六进制语法 oct()八进制 关于8进制是逢8进一位的,我 ...
- EF学习笔记(七):读取关联数据
总目录:ASP.NET MVC5 及 EF6 学习笔记 - (目录整理) 本篇参考原文链接:Reading Related Data 本章主要讲述加载显示关联数据: 数据加载分为以下三种 Lazy l ...
- ACM计划
原文 :http://027xbc.blog.163.com/blog/static/128159658201141371343475/ ACM主要是考算法的,主要时间是花在思考算法上,不是花在写程序 ...
- 运维工具pssh和pdsh安装和使用
1. pssh安装与使用 1.1 pssh安装 [root@server]# wget http://peak.telecommunity.com/dist/ez_setup.py [root@ser ...
- Java核心技术卷一基础技术-第13章-集合-读书笔记
第13章 集合 本章内容: * 集合接口 * 具体的集合 * 集合框架 * 算法 * 遗留的集合 13.1 集合接口 Enumeration接口提供了一种用于访问任意容器中各个元素的抽象机制. 13. ...
- redis订阅关闭异常解决
redis订阅关闭异常解决 应用程序模块订阅redis运行一段时间出现一直重连Redis服务,日志如下: 2019-04-28 10:06:17,551 ERROR org.springframewo ...
- Shiro基础
Factory<T>接口(org.apache.shiro.util.Factory) 接口的getInstance()方法是泛型方法,可以用来创建SecurityManager接口对象 ...
- Kali学习笔记19:NESSUS安装及使用
Nessus 百度百科:Nessus 是目前全世界最多人使用的系统漏洞扫描与分析软件.总共有超过75,000个机构使用Nessus 作为扫描该机构电脑系统的软件. 就我而言:漏洞扫描方面最强大的工具之 ...