Spark数据倾斜及解决方案
一.场景
1.绝大多数task执行得都非常快,但个别task执行极慢。比如,总共有100个task,97个task都在1s之内执行完了,但是剩余的task却要一两分钟。这种情况很常见。
2.原本能够正常执行的Spark作业,某天突然报出OOM(内存溢出),观察异常栈,是我们写的业务代码造成的。这种情况比较少见。
二.原理
在进行shuffle的时候,必须将各个节点上相同的key拉取到某个节点上的一个task来进行处理,比如按照key进行group或join等操作。此时如果某个key对应的数据量特别大的话,就会发生数据倾斜。比如大部分key对应1万条数据,但是个别key却对应了100万条数据,那么大部分task可能就只会分配到1万条数据,然后1s就运行完了;但是个别task可能分配到了100万数据,要运行一两分钟。因此,整个Spark作业的运行进度是由运行时间最长的那个task决定的。
因此出现数据倾斜的时候,Spark作业看起来会运行得非常缓慢,甚至可能因为某个task处理的数据量过大导致内存溢出。
比如下面这个例子:
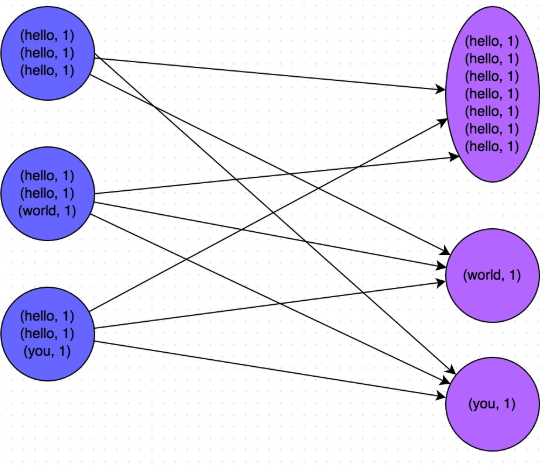
三.代码实现
package big.data.analyse.dataskew import org.apache.spark.sql.SparkSession /**
* Created by zhen on 2019/1/12.
*/
object DataSkew {
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("数据倾斜").master("local[2]").getOrCreate()
val sqlContext = spark.sqlContext
// 数据路径
val dataPath = "./src/big/data/analyse/dataskew/data.csv"
// spark读取csv数据
val data = sqlContext.read.format("com.databricks.spark.csv")
.option("header", "true") // 在csv第一行有属性true,没有就是false
.option("inferSchema", true) // 这是自动推断属性列的数据类型
.load(dataPath)
// 实现wordCount
// 转化data,对data进行扩容
val data_left = data.rdd.flatMap( row =>{
for(i <-0 until 10) yield (i +"_"+ row.getAs("XMMC"), row)
})
// 生成随机数拼接key,避免数据倾斜
val data_right = data.rdd
.map(row => ((Math.random()* 10).toInt +"_"+ row.getAs("XMMC"), row))
// 关联数据
val mid = data_left.join(data_right)
//去掉拼接随机数
val result = mid.map(row => row._2)
// 打印结果
result.foreach(println)
}
}
四.使用数据部分展示
"ROWNUM","XMMC","RWMC","FZR","BMMC","RWCJSJ","RWQSSJ","SJCLSJ"
"1","220kV变电站消防火灾报警系统大修等两个项目","招标方案/招标方案编制","***","继保自动化一班","2017/1/3 9:15:34","2017/1/3 9:15:34","2017/1/17 8:20:45"
"2","220kV变电站消防火灾报警系统大修等两个项目","招标方案/承办单位主管审核","***","生产设备管理部","2017/1/17 8:20:46","2017/1/17 14:37:01","2017/1/17 14:37:18"
"3","220kV变电站消防火灾报警系统大修等两个项目","招标方案/承办单位主要负责人审核","***","领导班子","2017/1/17 14:37:18","2017/1/17 15:03:17","2017/1/17 15:03:26"
"4","220kV变电站消防火灾报警系统大修等两个项目","招标方案/承办人流转","***","继保自动化一班","2017/1/17 15:03:26","2017/1/17 17:19:11","2017/1/19 8:30:09"
"5","220kV变电站消防火灾报警系统大修等两个项目","招标方案/项目管理部门专责审核","***","资产管理部(与生产设备管理部合署)","2017/1/19 8:30:09","2017/1/20 15:26:43","2017/1/20 15:28:05"
"6","220kV变电站消防火灾报警系统大修等两个项目","招标方案/项目管理部门科长审核","***","生产管理科","2017/1/20 15:28:05","2017/1/25 10:23:13","2017/1/25 10:23:33"
"7","220kV变电站消防火灾报警系统大修等两个项目","招标方案/招标专业小组副组长审核","***","资产管理部(与生产设备管理部合署)","2017/1/25 10:23:33","2017/2/8 12:03:01","2017/2/8 12:03:24"
"8","220kV变电站消防火灾报警系统大修等两个项目","招标方案/招标专业小组组长审核","***","资产管理部(与生产设备管理部合署)","2017/2/8 12:03:24","2017/2/8 12:03:24","2017/2/8 12:03:37"
"9","220kV变电站消防火灾报警系统大修等两个项目","招标方案/项目分管局领导审核","***","局领导","2017/2/8 12:03:37","2017/2/17 9:24:25","2017/2/17 9:24:30"
"10","220kV变电站消防火灾报警系统大修等两个项目","招标方案/招标管理小组组长审核","***","局领导","2017/2/17 9:24:30","2017/2/17 13:06:06","2017/2/17 13:06:21"
五.部分结果展示
([22528,2017年普法专项——法治文化宣传片,结果公告/结果公告,***,null,2017/11/16 16:25:59,2017/11/17 13:05:59,2017/11/21 16:21:38],[22528,2017年普法专项——法治文化宣传片,结果公告/结果公告,***,null,2017/11/16 16:25:59,2017/11/17 13:05:59,2017/11/21 16:21:38])
([54441,2018年输变电设备状态评价系统检测,采购方案/承办人流转,***,安全生产部,2017/12/6 19:55:15,2017/12/7 8:00:36,2017/12/7 8:00:44],[54450,2018年输变电设备状态评价系统检测,项目发售/项目发售,***,null,2017/12/11 12:03:25,2017/12/11 12:03:26,2017/12/21 16:32:03])
([22529,2017年普法专项——法治文化宣传片,结果通知/结果通知,***,null,2017/11/21 16:21:38,2017/11/21 16:21:39,2017/11/24 16:21:28],[22506,2017年普法专项——法治文化宣传片,采购方案/承办部门科长审核,***,法务一科,2017/8/18 15:56:08,2017/8/18 15:57:08,2017/8/18 15:57:31])
([54441,2018年输变电设备状态评价系统检测,采购方案/承办人流转,***,安全生产部,2017/12/6 19:55:15,2017/12/7 8:00:36,2017/12/7 8:00:44],[54454,2018年输变电设备状态评价系统检测,结果公示/结果公示,***,null,2017/12/22 10:52:16,2017/12/22 10:52:17,2017/12/22 10:52:21])
([22529,2017年普法专项——法治文化宣传片,结果通知/结果通知,***,null,2017/11/21 16:21:38,2017/11/21 16:21:39,2017/11/24 16:21:28],[22512,2017年普法专项——法治文化宣传片,采购方案/招标专业小组组长审核,***,企业管理部,2017/9/1 10:14:08,2017/9/4 15:30:00,2017/9/4 15:30:16])
([54441,2018年输变电设备状态评价系统检测,采购方案/承办人流转,***,安全生产部,2017/12/6 19:55:15,2017/12/7 8:00:36,2017/12/7 8:00:44],[54455,2018年输变电设备状态评价系统检测,项目定标/项目定标,***,安全生产部,2017/12/22 10:52:21,2017/12/22 11:17:11,2018/1/2 9:48:07])
([22529,2017年普法专项——法治文化宣传片,结果通知/结果通知,***,null,2017/11/21 16:21:38,2017/11/21 16:21:39,2017/11/24 16:21:28],[22515,2017年普法专项——法治文化宣传片,采购文件/招标文件编制,***,null,2017/9/4 16:27:51,2017/10/19 11:03:53,2017/10/23 8:52:32])
([54442,2018年输变电设备状态评价系统检测,采购文件/采购项目负责人指定,****工程监理有限公司,null,2017/12/7 8:00:44,2017/12/7 9:57:47,2017/12/7 9:58:19],[54437,2018年输变电设备状态评价系统检测,采购方案/项目管理部门专责审核,***,资产管理部(与生产设备管理部合署),2017/11/23 16:56:58,2017/11/29 13:11:09,2017/11/29 13:12:06])
([22529,2017年普法专项——法治文化宣传片,结果通知/结果通知,***,null,2017/11/21 16:21:38,2017/11/21 16:21:39,2017/11/24 16:21:28],[22521,2017年普法专项——法治文化宣传片,采购发布/公布发布,***,null,2017/10/27 9:58:58,2017/10/27 11:46:44,2017/10/27 11:46:55])
([54442,2018年输变电设备状态评价系统检测,采购文件/采购项目负责人指定,****工程监理有限公司,null,2017/12/7 8:00:44,2017/12/7 9:57:47,2017/12/7 9:58:19],[54440,2018年输变电设备状态评价系统检测,采购方案/招标专业小组组长审核,***,资产管理部(与生产设备管理部合署),2017/12/5 17:31:46,2017/12/6 19:55:09,2017/12/6 19:55:15])
Spark数据倾斜及解决方案的更多相关文章
- Spark数据倾斜解决方案及shuffle原理
数据倾斜调优与shuffle调优 数据倾斜发生时的现象 1)个别task的执行速度明显慢于绝大多数task(常见情况) 2)spark作业突然报OOM异常(少见情况) 数据倾斜发生的原理 在进行shu ...
- Spark数据倾斜解决方案(转)
本文转发自技术世界,原文链接 http://www.jasongj.com/spark/skew/ Spark性能优化之道——解决Spark数据倾斜(Data Skew)的N种姿势 发表于 2017 ...
- Spark性能优化之道——解决Spark数据倾斜(Data Skew)的N种姿势
原创文章,同步首发自作者个人博客转载请务必在文章开头处注明出处. 摘要 本文结合实例详细阐明了Spark数据倾斜的几种场景以及对应的解决方案,包括避免数据源倾斜,调整并行度,使用自定义Partitio ...
- Spark 数据倾斜
Spark 数据倾斜解决方案 2017年03月29日 17:09:58 阅读数:382 现象 当你的应用程序发生以下情况时你该考虑下数据倾斜的问题了: 绝大多数task都可以愉快的执行,总 ...
- 最详细10招Spark数据倾斜调优
最详细10招Spark数据倾斜调优 数据量大并不可怕,可怕的是数据倾斜 . 数据倾斜发生的现象 绝大多数 task 执行得都非常快,但个别 task 执行极慢. 数据倾斜发生的原理 在进行 shuff ...
- spark 数据倾斜的一些表现
spark 数据倾斜的一些表现 https://yq.aliyun.com/articles/62541
- spark数据倾斜处理
spark数据倾斜处理 危害: 当出现数据倾斜时,小量任务耗时远高于其它任务,从而使得整体耗时过大,未能充分发挥分布式系统的并行计算优势. 当发生数据倾斜时,部分任务处理的数据量过大,可能造成内存不足 ...
- spark数据倾斜
数据倾斜的主要问题在于,某个分区数量很巨大,在做map运算的时候,将会发生别的分区task很快计算完成,但是某几个分区task的计算成为了系统的瓶颈,明显超过其他分区时间: 1.方案:Kafka的 ...
- Spark 数据倾斜调优
一.what is a shuffle? 1.1 shuffle简介 一个stage执行完后,下一个stage开始执行的每个task会从上一个stage执行的task所在的节点,通过网络传输获取tas ...
随机推荐
- .NetCore外国一些高质量博客分享
前言 我之前看.netcore一些问题时候,用bing搜索工具搜到了一些外国人的博客.翻看以下,有学习的价值,就分享在这里了. 个人博客 andrewlock.net 最新几篇如下,一看标题就知道很有 ...
- Linux编程 9 (shell类型,shell父子关系,子shell用法)
一. shell类型 1.1 交互式 bin/ shell程序 当用户登录到某个虚拟控制台终端或是在GUI中启动终端仿真器时,默认的shell程序就会开始运行.系统启动什么样的shell程序取决于你 ...
- 【Android基础】利用Intent在Activity之间传递数据
前言: 上一篇文章给大家聊了Intent的用法,如何用Intent启动Activity和隐式Intent,这一篇文章给大家聊聊如何利用Intent在Activity之间进行沟通. 从一个Activ ...
- Poi 生成xls
来首小诗: 今日不胜昨日寒,我却把那拖鞋穿,脚儿冰冰秋风瑟,抬头一看碧蓝天. ---泥沙砖瓦浆木匠 项目需求: p2p项目中,需要一些数据报表一xls的格式,提供下载.并给主管签名. ...
- Linux常用命令之文件搜索命令
目录 1.最强大的搜索命令:find2.在文件资料库中查找文件命令:locate 一.根据 文件或目录名称 搜索 二.根据 文件大小 搜索 三.根据 所有者和所属组 搜索 四.根据 时间属性 搜索 五 ...
- 消息中间件RabbitMQ(一)
1.消息中间件 消息队列中间件是指利用高效可靠地消息传递机制传递消息.有两种传递模式:点对点模式.发布/订阅模式.流行的消息中间件有RabblitMQ.Kafka.RockerMQ.它们都提供了基于存 ...
- MySQL高可用之组复制技术(3):配置多主模型的组复制
MySQL组复制系列文章: MySQL组复制大纲 MySQL组复制(1):组复制技术简介 MySQL组复制(2):配置单主模型的组复制 MySQL组复制(3):配置多主模型的组复制 MySQL组复制( ...
- word2vec初探
在自然语言处理入门里我们提到了词向量的概念,tf-idf的概念,并且在实际的影评正负面预测项目中使用了tf-idf,取得了还算不错的效果.这一篇,我们来尝试一下使用来自google的大名鼎鼎的word ...
- [转]启动container的时候出现iptables: No chain/target/match by that name
本文转自:https://blog.csdn.net/u013948858/article/details/83115388 问题: Error response from daemon: drive ...
- c#的WebService和调用
WebService: 1.新建一个空白web应用程序 2.在上面建立的web应用程序添加web服务 4.保存发布至 IIS Client: 1.新建一个程序(可以是winform.控制台.web) ...