Elasticsearch实战 | 必要的时候,还得空间换时间!
1、应用场景
实时数据流通过kafka后,根据业务需求,一部分直接借助kafka-connector入Elasticsearch不同的索引中。
另外一部分,则需要先做聚类、分类处理,将聚合出的分类结果存入ES集群的聚类索引中。如下图所示:
业务系统的分层结构可分为:接入层、数据处理层、数据存储层、接口层。
那么问题来了?
我们需要基于聚合(数据处理层)的结果实现检索和聚合分析操作,如何实现更快的检索和更高效的聚合分析效果呢?

2、方案选型
方案一:
只建立一个索引,aggs_index。
数据处理层的聚合结果存入ES中的指定索引,同时将每个聚合主题相关的数据存入每个document下面的某个field下。如下示意图所示:
 方案一示意图
方案一示意图
方案二:
新建两个索引:aggs_index以及aggs_detail_index。
其中:
1)aggs_index存储事件列表信息。
2)aggs_detail_index存储事件关联的文章内容信息。
如下图所示:
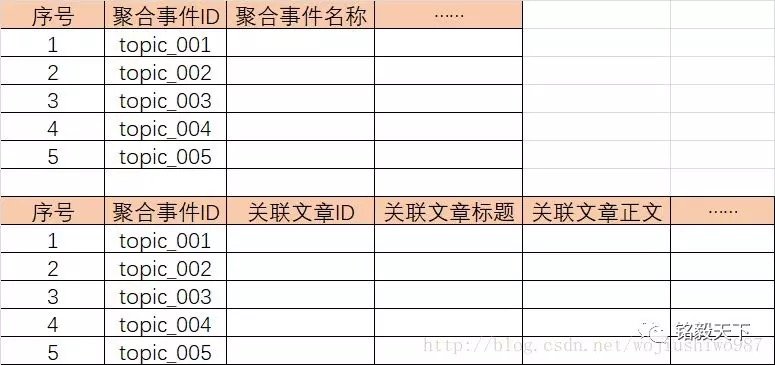 方案二示意图
方案二示意图
3、方案对比
方案一优点:节省存储空间,只存储关联文章id,数据没有重复存储。
方案一缺点:检索、聚合慢,性能不能达标。
方案一后续的所有操作,都需要先遍历检索这一堆IDs,然后再进行检索、聚合分析操作。
操作实例如下(实际比这要复杂):
第一步:通过事件id,获取关联文章id列表;
第二步:基于关联文章id列表,进行检索和聚合操作。
POST aggs_index/_search
{
"_source": {
"includes":[
"title",
"abstract",
"publish_time",
"author"
]},
"query":{
"terms":{
"_id":"["789b4cb872be00a04560d95bf13ec8f42c",
"792d9610b03676dc5644c2ff4db372dec4",
"817f5cff3dd0ec3564d45615f940cb7437",
"....."]
}
}
}
步骤2当id数量很多时,会有如下的错误提示:
{
"error": {
"root_cause": [
{
"type": "too_many_clauses",
"reason": "too_many_clauses:
maxClauseCount is set to 1024"
},
。。。
方案二优点:分开存储,便于一个索引中进行检索、聚合分析操作。
空间换时间,极大的提升检索效率、聚合速度。
方案二缺点:同样的数据,多存储了一份。
其对应的检索操作如下:
POST aggs_index/_search
{
"_source": {
"includes":[
"title",
"abstract",
"publish_time",
"author"
]},
"query":{
"term":{
"topic_id":"WIAEgRbI0k9s1D2JrXPC"
}
}
}
是真的吗?
用事实说话:
以下响应时间的单位为:ms。
方案一要在N个(N接近10)索引,每个索引近千万级别的数据中检索。
 两方案对比
两方案对比
 两方案响应时间对比效果图
两方案响应时间对比效果图
4、小结
由以上图示,对比可知,方案二采取了空间换时间的策略,数据量多存储了一份,但是性能提升了10余倍。
在实战开发中,我们要理性的选择存储方案,在磁盘成本日渐低廉的当下,把性能放在第一位,用户才能用的"爽“!
推荐阅读:
为什么选择 Spring 作为 Java 框架?
SpringBoot RocketMQ 整合使用和监控
使用Arthas 获取Spring ApplicationContext还原问题现场
上篇好文:

Elasticsearch实战 | 必要的时候,还得空间换时间!的更多相关文章
- JDK1.8 LongAdder 空间换时间: 比AtomicLong还高效的无锁实现
我们知道,AtomicLong的实现方式是内部有个value 变量,当多线程并发自增,自减时,均通过CAS 指令从机器指令级别操作保证并发的原子性. // setup to use Unsafe.co ...
- Redis学习笔记~关于空间换时间的查询案例
回到目录 空间与时间 空间换时间是在数据库中经常出现的术语,简单说就是把查询需要的条件进行索引的存储,然后查询时为O(1)的时间复杂度来快速获取数据,从而达到了使用空间存储来换快速的时间响应!对于re ...
- Redis基础知识之————空间换时间的查询案例
空间与时间 空间换时间是在数据库中经常出现的术语,简单说就是把查询需要的条件进行索引的存储,然后查询时为O(1)的时间复杂度来快速获取数据,从而达到了使用空间存储来换快速的时间响应!对于redis这个 ...
- 你好,C++(28)用空间换时间 5.2 内联函数 5.3 重载函数
5.2 内联函数 通过5.1节的学习我们知道,系统为了实现函数调用会做很多额外的幕后工作:保存现场.对参数进行赋值.恢复现场等等.如果函数在程序内被多次调用,且其本身比较短小,可以很快执行完毕,那么 ...
- 【C语言学习笔记】空间换时间,查表法的经典例子!知识就是这么学到的~
我们怎么衡量一个函数/代码块/算法的优劣呢?这需要从多个角度看待.本篇笔记我们先不考虑代码可读性.规范性.可移植性那些角度. 在我们嵌入式中,我们需要根据实际资源的情况来设计我们的代码.比如当我们能用 ...
- 计数排序(O(n+k)的排序算法,空间换时间)
计数排序就是利用空间换时间,时间复杂度O(n+k) n是元素个数,k是最大数的个数: 统计每个数比他小的有多少,比如比a[i]小的有x个,那么a[i]应该排在x+1的位置 代码: /* * @Auth ...
- leetcode-383-Ransom Note(以空间换时间)
题目描述: Given an arbitrary ransom note string and another string containing letters from all the magaz ...
- HDU4548美素数——筛选法与空间换时间
对于数论的学习比较的碎片化,所以开了一篇随笔来记录一下学习中遇到的一些坑,主要通过题目来讲解 本题围绕:素数筛选法与空间换时间 HDU4548美素数 题目描述 小明对数的研究比较热爱,一谈到数,脑子里 ...
- 图解Skip List——本质是空间换时间的数据结构,在lucene的倒排列表,bigtable,hbase,cassandra的memtable,redis中sorted set中均用到
Skip List的提出已有二十多年[Pugh, W. (1990)],却依旧应用广泛(Redis.LevelDB等).作为平衡树(AVL.红黑树.伸展树.树堆)的替代方案,虽然它性能不如平衡树稳定, ...
随机推荐
- BZOJ 3289:Mato的文件管理(莫队算法+树状数组)
http://www.lydsy.com/JudgeOnline/problem.php?id=3289 题意:…… 思路:求交换次数即求逆序对数.确定了这个之后,先离散化数组.然后在后面插入元素的话 ...
- MyBatis 基础搭建及架构概述
目录 MyBatis 是什么? MyBatis 项目构建 MyBatis 整体架构 接口层 数据处理层 基础支持层 MyBatis 是什么? MyBatis是第一个支持自定义SQL.存储过程和高级映射 ...
- .Net高级编程-自定义错误页 web.config中<customErrors>节点配置
错误页 1.当页面发生错误的时候,ASP.Net会将错误信息展示出来(Sqlconnection的错误就能暴露连接字符串),这样一来不好看,二来泄露网站的内部实现信息,给网站带来安全隐患,因此需要定制 ...
- Notepad++提升工作效率小技巧
前言 简单的提升工具效率需求可以借助Notepad编辑器实现.以前也用Python/Shell开发过本文中提到的需求,现在发现其实没有必要.本文介绍一些工作中常见的可以通过"Notepad+ ...
- 并发编程之美,带你深入理解java多线程原理
1.什么是多线程? 多线程是为了使得多个线程并行的工作以完成多项任务,以提高系统的效率.线程是在同一时间需要完成多项任务的时候被实现的. 2.了解多线程 了解多线程之前我们先搞清楚几个重要的概念! 如 ...
- Java是如何实现平台无关性的
相信对于很多Java开发来说,在刚刚接触Java语言的时候,就听说过Java是一门跨平台的语言,Java是平台无关性的,这也是Java语言可以迅速崛起并风光无限的一个重要原因.那么,到底什么是平台无关 ...
- ZIP:ZipEntry
ZipEntry: /* 此类用于表示 ZIP 文件条目. */ ZipEntry(String name) :使用指定名称创建新的 ZIP 条目. ZipEntry(ZipEntry e) :使用从 ...
- VS2012-SSAS 表格模型安全性
模型安全性与AD域账户结合之后,浏览模型出现的问题: 当对在表“Products”中定义的行级别安全性表达式求值时遇到了错误.错误消息: 当对在表“Products”中定义的行级别安全性表达式求值时遇 ...
- Docker 环境下搭建nexus私服
一.安装docker 1.脚本安装 本机环境CentOS7,用户为root 下载脚本到工作目录 curl -fsSL https://get.docker.com -o get-docker.sh 执 ...
- 个人永久性免费-Excel催化剂功能第36波-新增序列函数用于生成规律性的循环重复或间隔序列
啃过Excel函数的表哥表姐们,一定对函数的嵌套.数组公式等高级的应用有很深的体会,威力是大,但也烧死不少脑细胞,不少人就在这样的绕函数中光荣地牺牲了,走向从入门到放弃.Excel催化剂的创立,初衷就 ...