图解Elasticsearch的核心概念
本文讲解大纲,分8个核心概念讲解说明:
- NRT
- Cluster
- Node
- Document&Field
- Index
- Type
- Shard
- Replica
Near Realtime(NRT)近实时
Elasticsearch的核心优势就是(Near Real Time NRT)近乎实时,我们称之为近实时。
NRT有两个意思,下面举例说明下:
- 从写入索引数据到数据可以被搜索到有一个小延迟(大概1秒);
举个例子:电商平台新上架一个新商品,1秒后用户就可搜索到这个商品信息,这就是近实时。
- 基于Elasticsearch执行搜索和分析可以达到秒级查询
也举个例子说明,比如我现在想查询我在淘宝,最近一年都买过几件商品,总共花了多少钱,最贵的商品多少钱,哪个月买到东西最多,什么类型的商品买的最多这样的信息,如果淘宝说,你要等待10分钟才能出结果,你是不是很崩溃,这个延迟的时间就不是近实时,如果淘宝可以秒级别返回给你,就是近实时了。
下面画一个图,解释下三个基本概念的

Cluster:集群
包含多个节点,每个节点属于哪个集群是通过一个配置(集群名称,默认是elasticsearch)来决定的,对于中小型应用来说,刚开始一个集群就一个节点很正常。集群的目的为了提供高可用和海量数据的存储以及更快的跨节点查询能力。
Node:节点
集群中的一个节点,节点也有一个名称(默认是随机分配的),节点名称很重要(在执行运维管理操作的时候),默认节点会去加入一个名称为“elasticsearch”的集群,如果直接启动一堆节点,那么它们会自动组成一个elasticsearch集群,当然一个节点也可以组成一个elasticsearch集群
Document&field:文档和字段
document 是es中的最小数据单元,一个document可以是一条客户数据,一条商品分类数据,一条订单数据,通常用JSON数据结构表示,每个index下的type中,都可以去存储多个document。一个document里面有多个field,每个field就是一个数据字段。
相当于mysql里的行,可以简单这么理解,举个例子。一个商品的文档数据一条如下:
product document
{
"product_id": "1000",
"product_name": "mac pro 2019 款笔记本",
"product_desc": "高性能,高分辨率,编程必备神器",
"category_id": "2",
"category_name": "电子产品"
}
Index:索引
包含一堆有相似结构的文档数据,比如可以有一个客户索引,商品分类索引,订单索引,索引有一个名称。
一个index包含很多document,一个index就代表了一类类似的或者相同的document。比如说建立一个product index,商品索引,里面可能就存放了所有的商品数据,所有的商品document。
Type:类型
每个索引里都可以有一个或多个type,type是index中的一个逻辑数据分类,一个type下的document,都有相同的field,比如博客系统,有一个索引,可以定义用户数据type,博客数据type,评论数据type。
商品index,里面存放了所有的商品数据,商品document
但是商品分很多种类,每个种类的document的field可能不太一样,比如说电器商品,可能还包含一些诸如售后时间范围这样的特殊field;生鲜商品,还包含一些诸如生鲜保质期之类的特殊field
type,日化商品type,电器商品type,生鲜商品type
日化商品type:product_id,product_name,product_desc,category_id,category_name
电器商品type:product_id,product_name,product_desc,category_id,category_name,service_period
生鲜商品type:product_id,product_name,product_desc,category_id,category_name,eat_period
每一个type里面,都会包含一堆document
{
"product_id": "2",
"product_name": "长虹电视机",
"product_desc": "4k高清",
"category_id": "3",
"category_name": "电器",
"service_period": "1年"
}
{
"product_id": "3",
"product_name": "基围虾",
"product_desc": "纯天然,冰岛产",
"category_id": "4",
"category_name": "生鲜",
"eat_period": "7天"
}
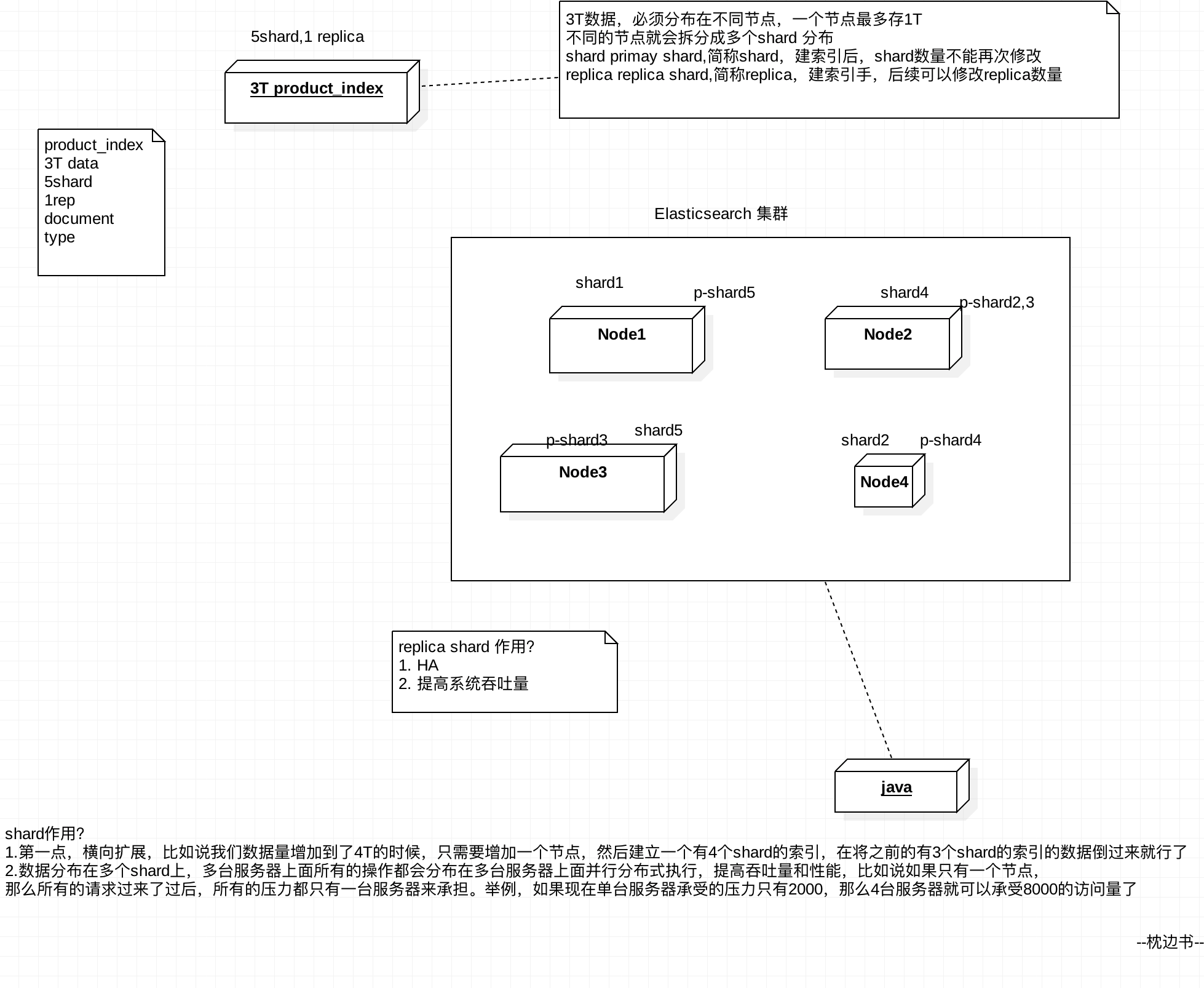
Shard 分片,也称 Primary Shard
单台机器无法存储大量数据,es可以将一个索引中的数据切分为多个shard,分布在多台服务器上存储。有了shard就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞吐量和性能。
每个shard都是一个lucene index。
Replica 副本,也称 Replica Shard
任何一个服务器随时可能故障或宕机,此时shard可能就会丢失,因此可以为每个shard创建多个replica副本。replica可以在shard故障时提供备用服务,保证数据不丢失,多个replica还可以提升搜索操作的吞吐量和性能。
primary shard(建立索引时一次设置,不能修改,默认5个),
replica shard(随时修改数量,默认1个),
默认每个索引10个shard,5个primary shard,5个replica shard,最小的高可用配置,是2台服务器。
相关索引解释说明:
- index包含多个shard
- 每个shard都是一个最小工作单元,承载部分数据,lucene实例,完整的建立索引和处理请求的能力
- 增减节点时,shard会自动在nodes中负载均衡
- primary shard和replica shard,每个document肯定只存在于某一个primary shard以及其对应的replica shard中,不可能存在于多个primary shard
- replica shard是primary shard的副本,负责容错,以及承担读请求负载
- primary shard的数量在创建索引的时候就固定了,replica shard的数量可以随时修改
- primary shard的默认数量是5,replica默认是1,默认有10个shard,5个primary shard,5个replica shard
- primary shard不能和自己的replica shard放在同一个节点上(否则节点宕机,primary shard和副本都丢失,起不到容错的作用),但是可以和其他primary shard的replica shard放在同一个节点上
索引在集群中分配图:
本文由博客一文多发平台 OpenWrite 发布!
图解Elasticsearch的核心概念的更多相关文章
- elasticsearch的核心概念
1.elasticsearch的核心概念 (1)Near Realtime(NRT):近实时,两个意思,从写入数据到数据可以被搜索到有一个小延迟(大概1秒):基于es执行搜索和分析可以达到秒级 (2) ...
- 剖析ElasticSearch核心概念,NRT,索引,分片,副本等
ElasticSearch 的核心概念 Near RealTime(NRT) 近实时 近实时有两种意思,一种是从写入数据到可以被搜索到有一个小延迟(大概一秒),还有一种就是基于ElasticSearc ...
- 轻松理解 Kubernetes 的核心概念
Kubernetes 迅速成为云环境中软件部署和管理的新标准. 与强大的功能相对应的是陡峭的学习曲线. 本文将提供 Kubernetes 的简化视图,从高处观察其中的重要组件,以及他们的关联. 硬件 ...
- ElasticSearch学习笔记-01 简介、安装、配置与核心概念
一.简介 ElasticSearch是一个基于Lucene构建的开源,分布式,RESTful搜索引擎.设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便.支持通过HTTP使用JSON进 ...
- Elasticsearch笔记四之配置参数与核心概念
在es根目录下有一个config目录,在此目录下有两个文件分别是elasticsearch.yml和logging.yml. logging.yml是日志文件,es也是使用log4j来记录日志的,我在 ...
- Elasticsearch学习笔记(六)核心概念和分片shard机制
一.核心概念 1.近实时(Near Realtime NRT) (1)从写入数据到数据可以被搜索到有一个小延迟(大概1秒): (2)基于es执行搜索和分析可以达到秒级 2.集群(Cluster) 一个 ...
- ElasticSearch 核心概念
ElasticSearch核心概念-Cluster ElasticSearch核心概念-shards ElasticSearch核心概念-replicas ElasticSearch核心概念-reco ...
- Elasticsearch学习之基本核心概念
在Elasticsearch中有许多术语和概念 1. 核心概念 Elasticsearch集群可以包含多个索引(indices)(数据库),每一个索引可以包含多个类型(types)(表),每一个类型包 ...
- ElasticSearch 全文检索— ElasticSearch 核心概念
ElasticSearch核心概念-Cluster 1)代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的.es的一个概念就是去中心化,字 ...
随机推荐
- Topaz ReMask 5抠图神器
Topaz ReMask 5抠图神器 与Photoshop相比,ReMask不需要繁琐的刷子工作来获得高质量的面膜.您只需粗略勾勒出主题并按"计算"即可. 在Photoshop中制 ...
- 12.Linux重定向与管道|
1.重定向概述 1.1什么是重定向 将原本要输出到屏幕的数据信息,重新定向到某个指定的文件中 名称 文件描述符 作用 标准输入(STDIN) 0 默认是键盘,也可以是文件或其他命令的输出. 标准输出( ...
- Python网络爬虫——Appuim+夜神模拟器爬取得到APP课程数据
一.背景介绍 随着生产力和经济社会的发展,温饱问题基本解决,人们开始追求更高层次的精神文明,开始愿意为知识和内容付费.从2016年开始,内容付费渐渐成为时尚. 罗辑思维创始人罗振宇全力打造" ...
- Java基础(三十二)JDBC(2)连接数据库
一.连接数据库的过程 连接数据库的过程:加载数据库驱动程序,不过只需在第一次访问数据库时加载一次,然后在每次访问数据库时创建一个Connection实例,然后执行操作数据库的SQL语句,并返回执行结果 ...
- day3-02 python入门之基本的数据类型
目录 一.整型(int) 二.浮点型(float) 三.字符串类型(str) 字符串在python2和python3中的细微区别 四.复数 五.列表(list) 六.数据字典(dict) 定义方式 七 ...
- Navicate12激活教程(完整详细版)
写在前面 最近身边的小伙伴苦于没有Navicat12的激活工具,不能使用最新版的Navicat,鉴于此,遂将自己整理的文章贴出来,供大家参考,不过个人还是主张维护正版的意愿,如果经济实力允许的话,还是 ...
- 回话技术-Cookie-记录上一次访问时间
效果: 第一次访问: 再次访问: <%@ page import="java.util.Date" %> <%@ page import="java.t ...
- Python+requests+unittest+excel实现接口自动化测试框架(摘录)
一.框架结构: 工程目录 二.Case文件设计 三.基础包 base 3.1 封装get/post请求(runmethon.py) 1 import requests 2 import json 3 ...
- Java 高并发之魂
前置知识 了解Java基本语法 了解多线程基本知识 知识介绍 Synchronized简介:作用.地位.不控制并发的后果 两种用法:对象锁和类锁 多线程访问同步方法的7种情况:是否是static.Sy ...
- MATLAB实例:聚类初始化方法与数据归一化方法
MATLAB实例:聚类初始化方法与数据归一化方法 作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 1. 聚类初始化方法:init_methods.m f ...