实战Netty集群
疯狂创客圈 Java 分布式聊天室【 亿级流量】实战系列之 -25【 博客园 总入口 】
1.写在前面
1.1 实战Netty集群的理由
Java基础练习中,一个重要的实战练习是: java的聊天程序。基本上,每一个java工程师,都有写过自己的聊天程序。
实现一个Java的分布式的聊天程序的分布式练习,同样非常重要的是。有以下几个方面的最重要作用:
1 体验高并发的程序的开发:从研究承载千、万QPS级的流量,拓展能够承载百万级、千万级、亿万级流量
2 有分布式、高并发的实战经验,面试谈薪水的时候,能提升不少
3 Netty集群的分布式原理,和大数据的分布式原理,elasticsearch 的分布式原理,和redis集群的分布式原理,和mongodb的分布式原理,很大程度上,都是想通。 Netty集群作为一个实战开发, 是一个非常好的分布式基础练习
4 更多的理由,请参考机械工业出版社的书籍 《Netty Zookeeper Redis 高并发实战》
1.2 Netty 集群 实战源码
本文的代码,来自于开源项目CrazyIm , 项目的地址为
https://gitee.com/crazymaker/crazy_tourist_circle__im.git源码 目前已经完成了基本的通信,在不断迭代中,不少的群友,通过疯狂创客圈的QQ群,沟通迭代过程中的问题。
2 Netty 集群中,服务节点的注册和发现
2.1 服务节点的注册和发现
zookeeper作为注册中心,每一个netty服务启动的时候,把节点的信息比如ip地址+端口号注册到zookeeper上。
具体的原理,请参见书籍《Netty Zookeeper Redis 高并发实战》。
2.2 节点的POJO
package com.crazymakercircle.entity;
import lombok.Data;
import java.io.Serializable;
import java.util.Objects;
/**
* IM节点的POJO类
* create by 尼恩 @ 疯狂创客圈
**/
@Data
public class ImNode implements Comparable<ImNode>, Serializable {
private static final long serialVersionUID = -499010884211304846L;
//worker 的Id,zookeeper负责生成
private long id;
//Netty 服务 的连接数
private Integer balance = 0;
//Netty 服务 IP
private String host;
//Netty 服务 端口
private Integer port;
public ImNode() {
}
public ImNode(String host, Integer port) {
this.host = host;
this.port = port;
}
@Override
public String toString() {
return "ImNode{" +
"id='" + id + '\'' +
"host='" + host + '\'' +
", port='" + port + '\'' +
",balance=" + balance +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
ImNode node = (ImNode) o;
// return id == node.id &&
return Objects.equals(host, node.host) &&
Objects.equals(port, node.port);
}
@Override
public int hashCode() {
return Objects.hash(id, host, port);
}
/**
* 升序排列
*/
public int compareTo(ImNode o) {
int weight1 = this.balance;
int weight2 = o.balance;
if (weight1 > weight2) {
return 1;
} else if (weight1 < weight2) {
return -1;
}
return 0;
}
public void incrementBalance() {
balance++;
}
public void decrementBalance() {
balance--;
}
}
2.3 服务的发现
利用zk有一个监听机制,就是针对某个节点进行监听,一点这个节点发生了变化就会收到zk的通知。我们就是利用zk的这个watch来进行服务的上线和下线的通知,也就是我们的服务发现功能。
package com.crazymakercircle.imServer.distributed;
import com.crazymakercircle.constants.ServerConstants;
import com.crazymakercircle.entity.ImNode;
import com.crazymakercircle.im.common.bean.msg.ProtoMsg;
import com.crazymakercircle.imServer.protoBuilder.NotificationMsgBuilder;
import com.crazymakercircle.util.JsonUtil;
import com.crazymakercircle.util.ObjectUtil;
import com.crazymakercircle.zk.ZKclient;
import lombok.extern.slf4j.Slf4j;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.recipes.cache.ChildData;
import org.apache.curator.framework.recipes.cache.PathChildrenCache;
import org.apache.curator.framework.recipes.cache.PathChildrenCacheEvent;
import org.apache.curator.framework.recipes.cache.PathChildrenCacheListener;
import java.util.concurrent.ConcurrentHashMap;
/**
* create by 尼恩 @ 疯狂创客圈
**/
@Slf4j
public class PeerManager {
//Zk客户端
private CuratorFramework client = null;
private String pathRegistered = null;
private ImNode node = null;
private static PeerManager singleInstance = null;
private static final String path = ServerConstants.MANAGE_PATH;
private ConcurrentHashMap<Long, PeerSender> peerMap =
new ConcurrentHashMap<>();
public static PeerManager getInst() {
if (null == singleInstance) {
singleInstance = new PeerManager();
singleInstance.client = ZKclient.instance.getClient();
}
return singleInstance;
}
private PeerManager() {
}
/**
* 初始化节点管理
*/
public void init() {
try {
//订阅节点的增加和删除事件
PathChildrenCache childrenCache = new PathChildrenCache(client, path, true);
PathChildrenCacheListener childrenCacheListener = new PathChildrenCacheListener() {
@Override
public void childEvent(CuratorFramework client,
PathChildrenCacheEvent event) throws Exception {
log.info("开始监听其他的ImWorker子节点:-----");
ChildData data = event.getData();
switch (event.getType()) {
case CHILD_ADDED:
log.info("CHILD_ADDED : " + data.getPath() + " 数据:" + data.getData());
processNodeAdded(data);
break;
case CHILD_REMOVED:
log.info("CHILD_REMOVED : " + data.getPath() + " 数据:" + data.getData());
processNodeRemoved(data);
break;
case CHILD_UPDATED:
log.info("CHILD_UPDATED : " + data.getPath() + " 数据:" + new String(data.getData()));
break;
default:
log.debug("[PathChildrenCache]节点数据为空, path={}", data == null ? "null" : data.getPath());
break;
}
}
};
childrenCache.getListenable().addListener(childrenCacheListener);
System.out.println("Register zk watcher successfully!");
childrenCache.start(PathChildrenCache.StartMode.POST_INITIALIZED_EVENT);
} catch (Exception e) {
e.printStackTrace();
}
}
private void processNodeRemoved(ChildData data) {
byte[] payload = data.getData();
ImNode n = ObjectUtil.JsonBytes2Object(payload, ImNode.class);
long id = ImWorker.getInst().getIdByPath(data.getPath());
n.setId(id);
log.info("[TreeCache]节点删除, path={}, data={}",
data.getPath(), JsonUtil.pojoToJson(n));
PeerSender peerSender = peerMap.get(n.getId());
if (null != peerSender) {
peerSender.stopConnecting();
peerMap.remove(n.getId());
}
}
private void processNodeAdded(ChildData data) {
byte[] payload = data.getData();
ImNode n = ObjectUtil.JsonBytes2Object(payload, ImNode.class);
long id = ImWorker.getInst().getIdByPath(data.getPath());
n.setId(id);
log.info("[TreeCache]节点更新端口, path={}, data={}",
data.getPath(), JsonUtil.pojoToJson(n));
if (n.equals(getLocalNode())) {
log.info("[TreeCache]本地节点, path={}, data={}",
data.getPath(), JsonUtil.pojoToJson(n));
return;
}
PeerSender peerSender = peerMap.get(n.getId());
if (null != peerSender && peerSender.getNode().equals(n)) {
log.info("[TreeCache]节点重复增加, path={}, data={}",
data.getPath(), JsonUtil.pojoToJson(n));
return;
}
if (null != peerSender) {
//关闭老的连接
peerSender.stopConnecting();
}
peerSender = new PeerSender(n);
peerSender.doConnect();
peerMap.put(n.getId(), peerSender);
}
public PeerSender getPeerSender(long id) {
PeerSender peerSender = peerMap.get(id);
if (null != peerSender) {
return peerSender;
}
return null;
}
public void sendNotification(String json) {
peerMap.keySet().stream().forEach(
key -> {
if (!key.equals(getLocalNode().getId())) {
PeerSender peerSender = peerMap.get(key);
ProtoMsg.Message pkg = NotificationMsgBuilder.buildNotification(json);
peerSender.writeAndFlush(pkg);
}
}
);
}
public ImNode getLocalNode() {
return ImWorker.getInst().getLocalNodeInfo();
}
public void remove(ImNode remoteNode) {
peerMap.remove(remoteNode.getId());
log.info("[TreeCache]移除远程节点信息, node={}", JsonUtil.pojoToJson(remoteNode));
}
}
2.4 为什么使用临时节点?
什么是临时节点?服务启动后创建临时节点, 服务断掉后临时节点就不存在了
正常的思路可能是注册的时候,我们像zk注册一个正常的节点,然后在服务下线的时候删除这个节点,但是这样的话会有一个弊端。比如我们的服务挂机,无法去删除临时节点,那么这个节点就会被我们错误的提供给了客户端。
另外我们还要考虑持久化的节点创建之后删除之类的问题,问题会更加的复杂化,所以我们使用了临时节点。
3 负载均衡策略
3.1 负载均衡策略的基本思路
在我们解决了服务的注册和发现问题之后,那么我们究竟提供给客户端那台服务呢,这时候就需要我们做出选择,为了让客户端能够均匀的连接到我们的服务器上(比如有个100个客户端,2台服务器,每台就分配50个),我们需要使用一个负载均衡的策略。
这里我们使用轮询的方式来为每个请求的客户端分配ip。具体的代码实现如下:
3.2 负载均衡实现源码的示意
package com.crazymakercircle.Balance;
import com.crazymakercircle.constants.ServerConstants;
import com.crazymakercircle.entity.ImNode;
import com.crazymakercircle.util.JsonUtil;
import com.crazymakercircle.zk.ZKclient;
import lombok.Data;
import lombok.extern.slf4j.Slf4j;
import org.apache.curator.framework.CuratorFramework;
import org.springframework.stereotype.Service;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
/**
* create by 尼恩 @ 疯狂创客圈
**/
@Data
@Slf4j
@Service
public class ImLoadBalance {
//Zk客户端
private CuratorFramework client = null;
private String managerPath;
public ImLoadBalance() {
this.client = ZKclient.instance.getClient();
// managerPath=ServerConstants.MANAGE_PATH+"/";
managerPath=ServerConstants.MANAGE_PATH;
}
/**
* 获取负载最小的IM节点
*
* @return
*/
public ImNode getBestWorker() {
List<ImNode> workers = getWorkers();
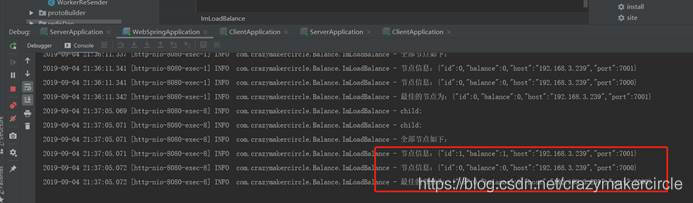
log.info("全部节点如下:");
workers.stream().forEach(node -> {
log.info("节点信息:{}", JsonUtil.pojoToJson(node));
});
ImNode best = balance(workers);
return best;
}
/**
* 按照负载排序
*
* @param items 所有的节点
* @return 负载最小的IM节点
*/
protected ImNode balance(List<ImNode> items) {
if (items.size() > 0) {
// 根据balance值由小到大排序
Collections.sort(items);
// 返回balance值最小的那个
ImNode node = items.get(0);
log.info("最佳的节点为:{}", JsonUtil.pojoToJson(node));
return node;
} else {
return null;
}
}
/**
* 从zookeeper中拿到所有IM节点
*/
protected List<ImNode> getWorkers() {
List<ImNode> workers = new ArrayList<ImNode>();
List<String> children = null;
try {
children = client.getChildren().forPath(managerPath);
} catch (Exception e) {
e.printStackTrace();
return null;
}
for (String child : children) {
log.info("child:", child);
byte[] payload = null;
try {
payload = client.getData().forPath(managerPath+"/"+child);
} catch (Exception e) {
e.printStackTrace();
}
if (null == payload) {
continue;
}
ImNode worker = JsonUtil.jsonBytes2Object(payload, ImNode.class);
workers.add(worker);
}
return workers;
}
/**
* 从zookeeper中删除所有IM节点
*/
public void removeWorkers() {
try {
client.delete().deletingChildrenIfNeeded().forPath(managerPath);
} catch (Exception e) {
e.printStackTrace();
}
}
}
4 环境的启动
4.1 启动Zookeeper
Zookeeper的安装和原理,以及开发的基础知识,请参见书籍《Netty Zookeeper Redis 高并发实战》。
启动zookeeper的两个节点,本来有三个,启动二个即可
客户端连接zookeeper集群。命令如下:
./zkCli.cmd -server localhost:2181
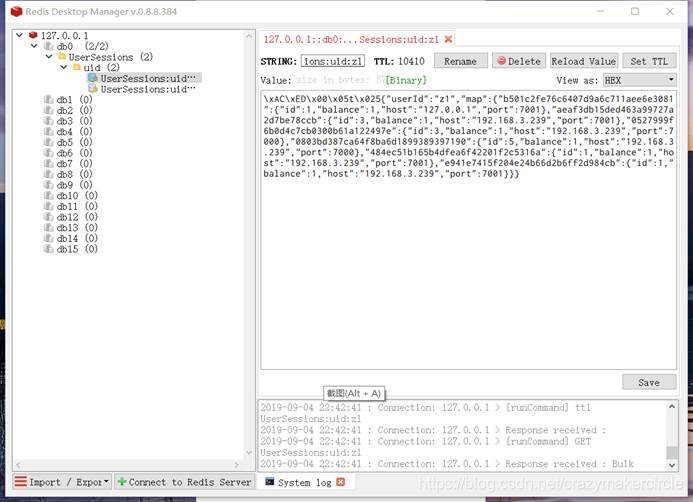
4.2 启动Redis
Redis的安装和原理,以及开发的基础知识,请参见请参见书籍《Netty Zookeeper Redis 高并发实战》。
redis 的客户端界面。
5 Netty集群启动
5.1 启动WEBGate
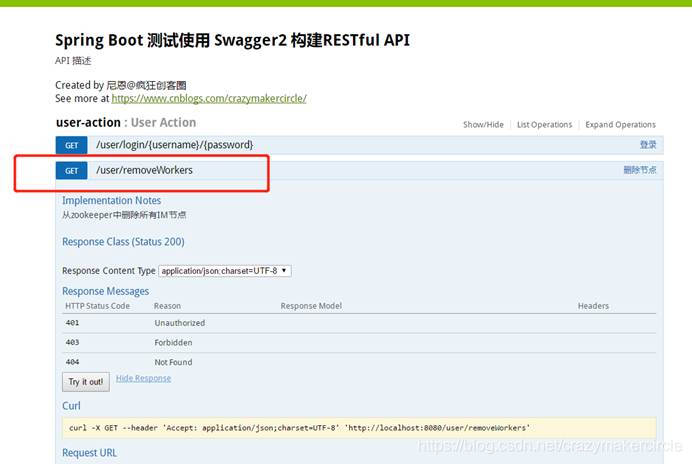
使用一个WEBGate,作为负载均衡的服务器,具体的原理,请参见书籍《Netty Zookeeper Redis 高并发实战》。
除了负载均衡,从WEBGate还可以从 zookeeper中删除所有IM节点
连接为: http://localhost:8080/swagger-ui.html
swagger 的界面如下:
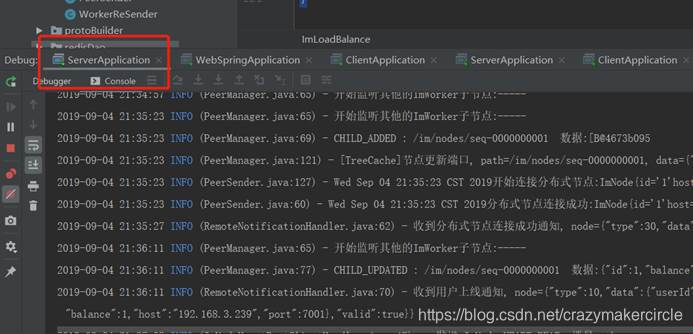
5.2 启动第一个Netty节点
服务端的端口为7000
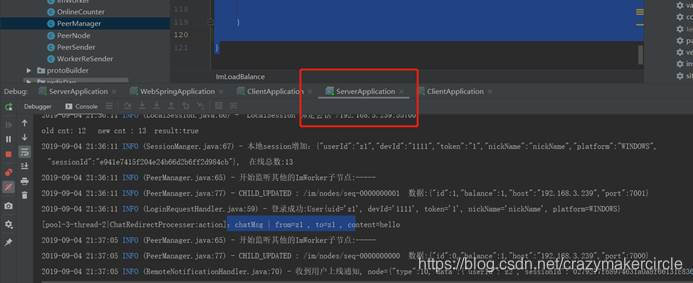
5.3 启动第二个Netty节点
服务端的端口为7001,自动递增的
5.4 启动第一个客户端
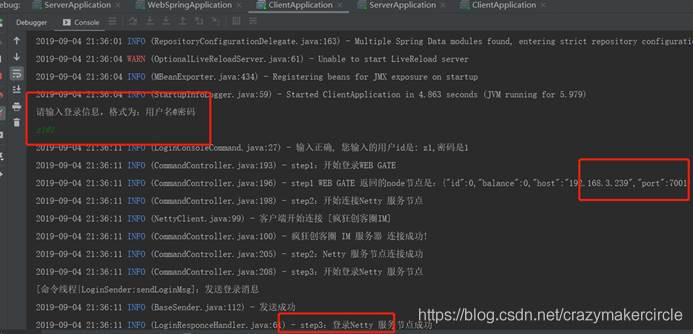
启动后输入登录的信息
请输入登录信息,格式为:用户名@密码
z1@1
启动客户端后,并且登录后,会自动连接一个netty节点, 这里为7001,第二个Netty服务节点。
5.5 启动第二个客户端
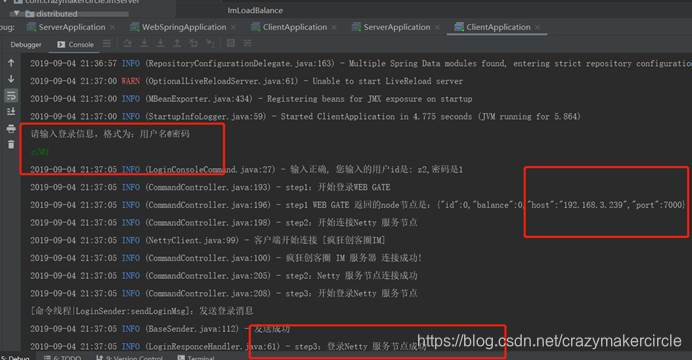
启动后输入登录的信息
请输入登录信息,格式为:用户名@密码
z2@1
启动客户端后,并且登录后,按照负载均衡的机制,会自动连接一个netty节点, 这里为7000,第一个Netty服务节点。
6 不同服务器直接进行IM通信
下面演示,不同的客户端,通过各自的服务器节点,进行通信。
6.1 发送聊天消息
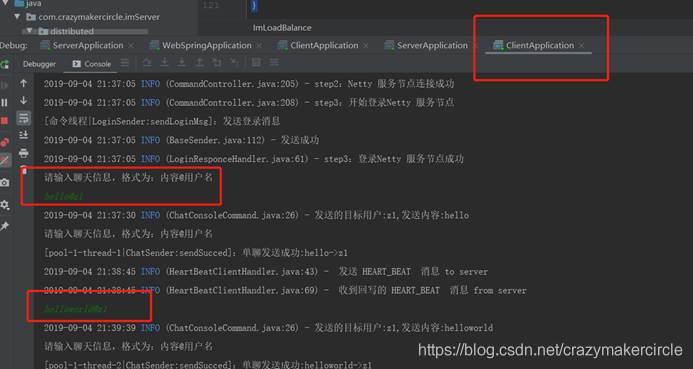
在第二个客户端(用户为z2),发送消息给第一个客户端(用户为z1),消息的格式为 :“ 内容@用户名”
请输入聊天信息,格式为:内容@用户名
hello@z1
请输入聊天信息,格式为:内容@用户名
helloworld@z1
6.2 远程客户端接收消息
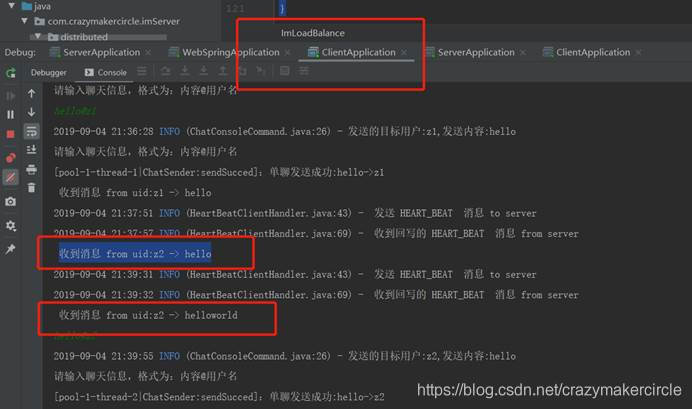
通过Netty服务节点的转发,第一个客户端收到的消息如下:
收到消息 from uid:z2 -> hello
收到消息 from uid:z2 -> helloworld
7 总结
7.1 开发的难度
通过Netty+Zookeep+Redis的架构,整个Netty的集群,具备了服务节点的自动发现,节点之间的消息路由的能力。
说明一下,整个程序,还是比较复杂的,如果看不懂,建议不要捉急,慢慢来。
如果能从0到1的自己实现一版,开发的水平,也就不一般了。
全面的理论基础,请参见 《Netty Zookeeper Redis 高并发实战》 一书
7.2 Netty集群的最全理论基础
《Netty Zookeeper Redis 高并发实战》 一书,对Netty 集群的基本原理,进行了详尽的介绍,大致的目录如下:
12.1 【面试必备】如何支撑亿级流量的高并发IM架构的理论基础
12.1.1 亿级流量的系统架构的开发实践 338
12.1.2 高并发架构的技术选型 338
12.1.3 详解IM消息的序列化协议选型 339
12.1.4 详解长连接和短连接 339
12.2 分布式IM的命名服务的实践案例 340
12.2.1 IM节点的POJO类 341
12.2.2 IM节点的ImWorker类 342
12.3 Worker集群的负载均衡之实践案例 345
12.3.1 ImLoadBalance负载均衡器 346
12.3.2 与WebGate的整合 348
12.4 即时通信消息的路由和转发的实践案例 349
12.4.1 IM路由器WorkerRouter 349
12.4.2 IM转发器WorkerReSender 352
12.5 Feign短连接RESTful调用 354
12.5.1 短连接API的接口准备 355
12.5.2 声明远程接口的本地代理 355
12.5.3 远程API的本地调用 356
12.6 分布式的在线用户统计的实践案例 358
12.6.1 Curator的分布式计数器 358
12.6.2 用户上线和下线的统计 360
疯狂创客圈 Java 死磕系列
- Java (Netty) 聊天程序【 亿级流量】实战 开源项目实战
- Netty 源码、原理、JAVA NIO 原理
- Java 面试题 一网打尽
- 疯狂创客圈 【 博客园 总入口 】
实战Netty集群的更多相关文章
- netty集群(一)-服务注册发现
上篇文章介绍了如何搭建一个单机版本的netty聊天室:https://www.jianshu.com/p/f786c70eeccc. 一.需要解决什么问题: 当连接数超过单机的极限时,需要将netty ...
- redis3.0 集群实战2 - 集群功能实战
1 集群基本操作 1.1 查看当前集群状态 使用redis-trib.rb check功能查看对应的节点的状态: [root@bogon bin]# ./redis-trib.rb check 1 ...
- 实战MySQL集群,试用CentOS 6下的MariaDB-Galera集成版
说起mysql的集群估计很多人会首先想起mysql自带的replication或者mysql-mmm.mysql-mmm其实也是基于mysql自带的replication的,不过封装的更好用一些,但是 ...
- 实战weblogic集群之应用部署
一.创建应用发布目录,上传应用包. 1.在10.70.52.11-14的/app/sinova目录下建立applications目录(名称可以自定义),作为我们应用的发布目录. $ mkdir /ap ...
- 实战weblogic集群之创建节点和集群
一.启动weblogic,访问控制台 weblogic的domain创建完成后,接下来就可以启动它,步骤如下: $ cd /app/sinova/domains/base_domain/bin $ . ...
- 实战weblogic集群之创建domain,AdminServer
在weblogic安装完后,接下来就可以创建domain,AdminSever了. 第1步: $ cd /app/sinova/Oracle/wlserver_10./common/bin $ ./c ...
- 实战weblogic集群之安装weblogic
一.系统及软件版本 OS版本:Red Hat Enterprise Linux Server release 6.6WebLogic Server 版本: 10.3.3.0JDK版本:1.7.0_79 ...
- Apache ActiveMQ实战(2)-集群
ActiveMQ的集群 内嵌代理所引发的问题: 消息过载 管理混乱 如何解决这些问题--集群的两种方式: Master slave Broker clusters ActiveMQ的集群有两种方式: ...
- JBOSS EAP实战(2)-集群、NGINX集成、队列与安全
JBOSS HTTP的Thread Group概念 JBOSS是一个企业级的J2EE APP Container,因此它和任何一种成熟的企业级中间件一样具有Thread Group的概念.所谓Thre ...
随机推荐
- surfer白化
surfer白化的方法: 方法一: 1.griddata需白化的文件(surfer处理成grd格式,也就是surfer绘图的基本数据格式) 注意:用surfer转换格式时,插值间距(spacing)大 ...
- div水平垂直居中的六种方法
在平时,我们经常会碰到让一个div框针对某个模块上下左右都居中(水平垂直居中),其实针对这种情况,我们有多种方法实现. 方法一: 绝对定位方法:不确定当前div的宽度和高度,采用 transform: ...
- shell特殊符号及cut、sort_wc_uniq、tee_tr_split命令 使用介绍
第6周第2次课(4月24日) 课程内容: 8.10 shell特殊符号cut命令8.11 sort_wc_uniq命令8.12 tee_tr_split命令8.13 shell特殊符号下 扩展1. s ...
- 错误 找不到Xcode No such file or directory
- Python之HTTP静态服务器-面向对象版开发
利用面向对象的思想完成HTTP静态Web服务器的开发. 主要思路如下: 1.抽象出一个服务器类 1.1 编写类的对象属性 1.2 编写类的方法 注意: 在进行请求资源路径判断时,需要确认请求路径中是否 ...
- docker的安装及常用命令
一:概述 Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的Linux机器或Windows 机器上,也可以实现虚拟化,容器是完全使用 ...
- 蓝牙5.0芯片NRF52810和NRF52832可进行mesh组网
提供智能化mesh照明解决方案,在现有传统灯具的基础上,插入NRF52832/52810的照明Mesh模块,可以迅速升级现有的传统灯具,配合手机APP和服务器系统,使每一盏灯成为物联网的一个智能节点, ...
- Python入门(一个有趣的画图例子实战)你肯定不会
前言本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理.作者:qiu_fang 画一条可爱的python(蟒蛇): import t ...
- 最高分辨率行间转移CCD图像传感器 - KAI-47051 演示视频
http://www.onsemi.cn/PowerSolutions/supportVideo.do?docId=1002912
- 【JS】395-重温基础:事件
本文是 重温基础 系列文章的第二十篇. 这是第三个基础系列的第一篇,欢迎持续关注呀!重温基础 系列的[初级]和[中级]的文章,已经统一整理到我的[Cute-JavaScript](http://js. ...