Hive入门(三)分桶
1 什么是分桶
上一篇说到了分区,分区中的数据可以被进一步拆分成桶,bucket。不同于分区对列直接进行拆分,桶往往使用列的哈希值进行数据采样。在分区数量过于庞大以至于可能导致文件系统崩溃时,建议使用桶。
hive使用对分桶所用的值进行hash,并用hash结果除以桶的个数做取余运算的方式来分桶,保证了每个桶中都有数据,但每个桶中的数据条数不一定相等。
2 如何分桶
首先,在建立桶之前,需要设置hive.enforce.bucketing属性为true,使得hive能识别桶。
然后,创建带有桶的表:
CREATE TABLE bucketed_user(
id INT,
name String
)
CLUSTERED BY (id) INTO 5 BUCKETS;
向桶中插入数据,这里按照用户id分成了5个桶
此时查看文件系统中的目录结构如下:
/usr/hive/warehouse/bucketed_user/000000_0
/usr/hive/warehouse/bucketed_user/000001_0
/usr/hive/warehouse/bucketed_user/000002_0
/usr/hive/warehouse/bucketed_user/000003_0
/usr/hive/warehouse/bucketed_user/000004_0
5个桶就是将数据表存储分为5个文件存储
注:cluster by不会影响数据的导入,这意味着,用户必须自己负责数据如何导入,包括数据的分桶和排序。
3 分区与分桶比较
- 桶的数量是固定的;
- 分区可以再分子区,桶不行;
- 分区或表组织成桶,Hive在处理有些查询时能利用桶的结构,获得更高的查询处理效率
- 分桶使取样(sampling)更高效
- 物理存储方式不同
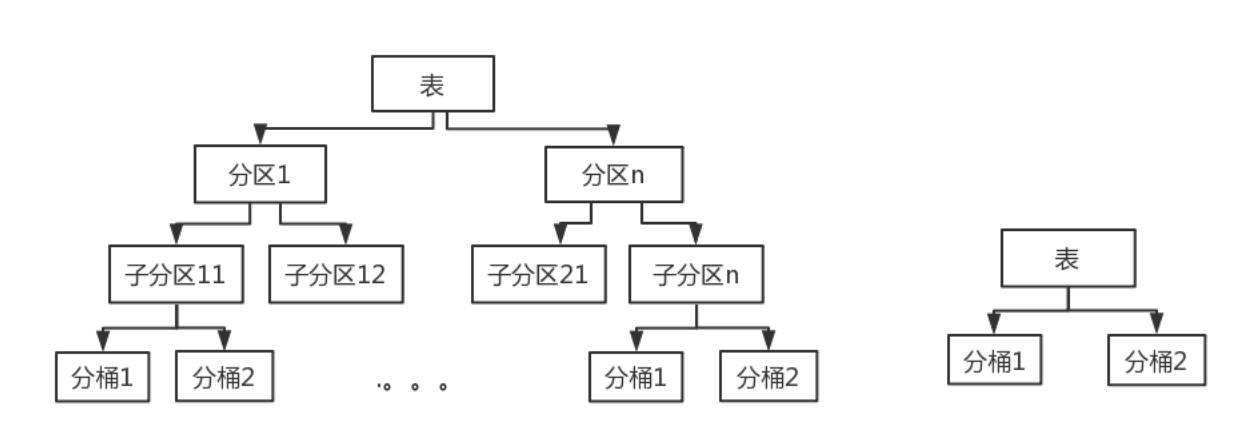
如下图,分区又分桶和只分桶的图:
注:
抽样语法:TABLESAMPLE(BUCKET x OUT OF y)
y必须是table总bucket数的倍数或者因子。hive根据y的大小,决定抽样的比例。例如,table总共分了64份,当y=32时,抽取(64/32=)2个bucket的数据,当y=128时,抽取(64/128=)1/2个bucket的数据。x表示从哪个bucket开始抽取。例如,table总bucket数为32,tablesample(bucket 3 out of 16),表示总共抽取(32/16=)2个bucket的数据,分别为第3个bucket和第(3+16=)19个bucket的数据。
Hive入门(三)分桶的更多相关文章
- 入门大数据---Hive分区表和分桶表
一.分区表 1.1 概念 Hive 中的表对应为 HDFS 上的指定目录,在查询数据时候,默认会对全表进行扫描,这样时间和性能的消耗都非常大. 分区为 HDFS 上表目录的子目录,数据按照分区存储在子 ...
- Hive 学习之路(五)—— Hive 分区表和分桶表
一.分区表 1.1 概念 Hive中的表对应为HDFS上的指定目录,在查询数据时候,默认会对全表进行扫描,这样时间和性能的消耗都非常大. 分区为HDFS上表目录的子目录,数据按照分区存储在子目录中.如 ...
- Hive 系列(五)—— Hive 分区表和分桶表
一.分区表 1.1 概念 Hive 中的表对应为 HDFS 上的指定目录,在查询数据时候,默认会对全表进行扫描,这样时间和性能的消耗都非常大. 分区为 HDFS 上表目录的子目录,数据按照分区存储在子 ...
- hive -- 分区,分桶(创建,修改,删除)
hive -- 分区,分桶(创建,修改,删除) 分区: 静态创建分区: 1. 数据: john doe 10000.0 mary smith 8000.0 todd jones 7000.0 boss ...
- Hive为什么要分桶
对于每一个表(table)或者分区, Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分.Hive也是针对某一列进行桶的组织.Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记 ...
- hive 分区表和分桶表
1.创建分区表 hive> create table weather_list(year int,data int) partitioned by (createtime string,area ...
- Hive学习笔记——Hive中的分桶
对于每一个表(table)或者分区, Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分.Hive也是针对某一列进行桶的组织.Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记 ...
- Hive分区表与分桶
分区表 在Hive Select查询中.通常会扫描整个表内容,会消耗非常多时间做不是必需的工作. 分区表指的是在创建表时,指定partition的分区空间. 分区语法 create table tab ...
- hive中的分桶表
桶表也是一种用于优化查询而设计的表类型.创建通表时,指定桶的个数.分桶的依据字段,hive就可以自动将数据分桶存储.查询时只需要遍历一个桶里的数据,或者遍历部分桶,这样就提高了查询效率 ------创 ...
- 第2节 hive基本操作:11、hive当中的分桶表以及修改表删除表数据加载数据导出等
分桶表 将数据按照指定的字段进行分成多个桶中去,说白了就是将数据按照字段进行划分,可以将数据按照字段划分到多个文件当中去 开启hive的桶表功能 set hive.enforce.bucketing= ...
随机推荐
- android 玩愤怒的小鸟等游戏的时候全屏TP失败
1.tp driver的tpd_down()和tpd_up()函数不需要进行报告id号码.自己主动顶级赛: 2.tpd_up()功能只需要报告BTN_TOUCH和mt_sync信息,其他信息未报告,如 ...
- WPF媒体资源和图片资源寻址方式的杂谈
WPF提供一个封装和存取资源(resource)的机制,我们可将资源建立在应用程序的不同范围上.WPF中,资源定义的位置决定了该资源的可用范围.资源可以定义在如下范围中: (1)控件级:此时,资源只能 ...
- 手把手教你学会 基于JWT的单点登录
最近我们组要给负责的一个管理系统 A 集成另外一个系统 B,为了让用户使用更加便捷,避免多个系统重复登录,希望能够达到这样的效果--用户只需登录一次就能够在这两个系统中进行操作.很明显这就是单点登 ...
- Android零基础入门第46节:下拉框Spinner
原文:Android零基础入门第46节:下拉框Spinner 上一期学习了GridView的使用,你已经掌握了吗?本期一起来学习Spinner的使用. 一.认识Spinner Spinner其实就是一 ...
- 关于 Apache 2.4 配置PHP时的错误记录
1. 访问虚拟配置的站点抛出 Forbidden 403 错误 解决办法: <Directory E:/Xingzhi/Php/xingzhi.xingzhi.com/> Opti ...
- eval 未将对象引用到对象实例
1.Eval("No") == null ? "" : Convert.ToString(Eval("NO"))
- Qt5.5以来对Network的改进(包括对SSL的功能支持,HTTP的重定向等等)
Qt Network New SSL back-end for iOS and OS X based on Secure Transport. Note that in Qt 5.6 this wil ...
- OpenGL与Directx的区别
OpenGL 只是图形函数库. DirectX 包含图形, 声音, 输入, 网络等模块. 单就图形而论, DirectX 的图形库性能不如 OpenGL OpenGL稳定,可跨平台使用.但 OpenG ...
- 使用VS2010再装VS2013不用再烦恼不兼容
某些同事有时在开发过程中出现这么个问题,在使用js直接异步调用类库时,弹出错误类库不存在或者没有定义等,类似问题,这个时候可能你正在绞尽脑汁的去解决问题,明明问题不大,为什么安装VS2013后就不能打 ...
- 只言片语 - cell 图片复用问题
一. 今日做项目遇到图片复用问题,返回cell高度相同,由于网络不好出现图片复用,发现问题 Cell 图片加载方法如下: - (void)sd_setImageWithURL:(NSURL *)u ...