Kafka服务端之网络连接源码分析
#### 简介
上次我们通过分析KafkaProducer的源码了解了生产端的主要流程,今天学习下服务端的网络层主要做了什么,先看下 KafkaServer的整体架构图
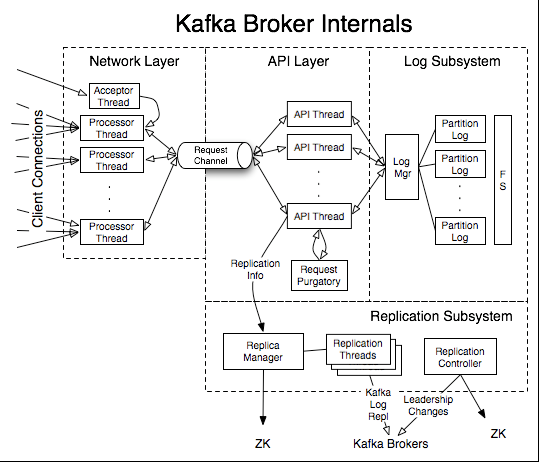
由图可见Kafka的服务端主要包括网络层、API层、日志子系统、副本子系统这几个大模块。当client端发起请求时,网络层会收到请求,并把请求放到共享请求队列中,然后由API层的Handler线程从队列中取出请求,并执行请求。比如是 KafkaProducer发过来的生产消息的请求,会把消息写到磁盘日志中,最后把响应返回给client
#### 网络层
从上面的图中,可以看到Kafka服务端做的事情还是很多的,也有很多优秀的设计,我们后面再慢慢介绍,今天主要学习网络层
网络层主要完成和客户端、其他Broker的网络连接,采用了Reactor模式,一种基于事件驱动的模式,之前写过相关文章,可以参考下(链接)这里不再赘述
网络层的核心类是SocketServer,包含一个Acceptor用来接收新的连接,Acceptor对应多个Processor线程,每个 Processor线程都有自己的Selector,用来从连接中读取请求并写回响应
同时一个Acceptor线程对应多个Handler线程,这才是真正处理请求的线程,Handler线程处理完请求后把响应返回给 Processor线程,其中Processor线程和Handler线程通过RequestChannel传递数据,ReqeustChannel包括共享的RequestQueue和Processor私有的ResponseQueue,下面附上一张图
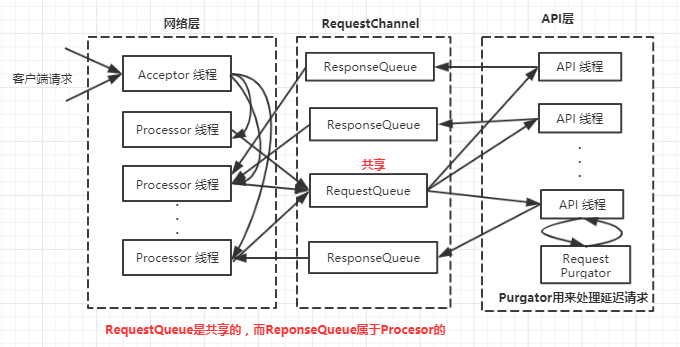
上面说的有些抽象,我们深入到源码中看看Kafka服务端是如何接收请求并把响应返回给客户端的
#### 源码分析
#### KafkaServer
KafkaServer是Kafka服务端的主类,KafkaServer中和网络层相关的组件包括SockerServer、KafkaApis和KafkaRequestHandlerPool。其中KafkaApis和KafkaRequestHandlerPool都是通过SocketServer提供的RequestChannel来处理网络请求,和本次介绍的网络层相关的代码如下所示
```scala
class KafkaServer(...) {
...
var dataPlaneRequestProcessor: KafkaApis = null
...
def startup(): Unit = {
...
// SocketServer主要关注网络层相关事宜
socketServer = new SocketServer(...)
// Processor涉及到权限相关,所以调用SocketServer.startup时,只先启动Acceptor,初始化完权限相关的凭证后,再启动Processor,所以startupProcessors为false
socketServer.startup(startupProcessors = false)
...
// KafkaApis进行真正的业务逻辑处理
dataPlaneRequestProcessor = new KafkaApis(socketServer.dataPlaneRequestChannel ,...)
// 创建KafkaRequestHandler线程池,其中KafkaRequestHandler主要用来从请求通道中取请求
dataPlaneRequestHandlerPool = new KafkaRequestHandlerPool(config.brokerId, socketServer.dataPlaneRequestChannel, dataPlaneRequestProcessor, config.numIoThreadsx,...)
...
// 初始化结束
...
// Processor涉及到权限相关的操作,所以要等初始化完成,再启动Processor
socketServer.startDataPlaneProcessors()
...
}
}
```
我们把KafkaServer网络层再用一张带有具体的类的图展示下
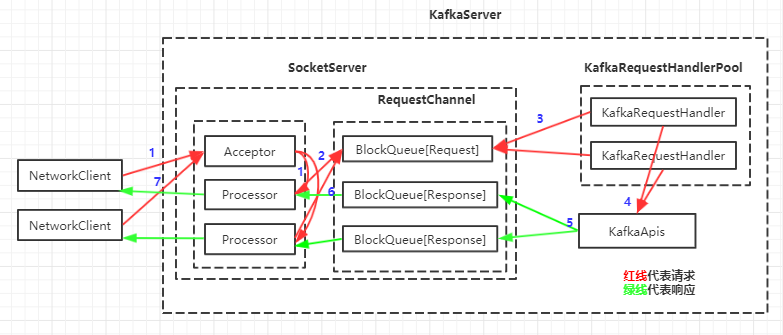
具体步骤
```
1.客户端(NetworkClient)发送请求被接收器(Acceptor)转发给处理器(Processor)处理
2.处理器把请求放到请求通道(RequestChannel)的共享请求队列中
3.请求处理器线程(KafkaRequestHandler)从请求通道的共享请求队列中取出请求
4.业务逻辑处理器(KafkaApis)进行业务逻辑处理
5.业务逻辑处理器把响应发到请求通道中与各个处理器对应的响应队列中
6.处理器从对应的响应队列中取出响应
7.处理器将响应的结果返回给客户端
```
#### SocketServer.startup方法
通过KafkaServer相关源码我们知道了整体的大概处理流程,既然今天主要学习网络连接相关源码,下面我们看下SocketServer.startup都做了什么
```scala
// SocketServer.startup
def startup(startupProcessors: Boolean = true): Unit = {
this.synchronized {
// 初始化控制每个IP上的最大连接数的对象,底层是Map
connectionQuotas = new ConnectionQuotas(config, time)
...
// 创建接收器和处理器
createDataPlaneAcceptorsAndProcessors(config.numNetworkThreads, config.dataPlaneListeners)
// 判断是否需要启动处理器,在KafkaServer初始化代用SocketServer.startup方法时,startipProcessors传
// 的是false,原因请看上面介绍KafkaServer的源码
if (startupProcessors) {
// 启动处理器
startControlPlaneProcessor()
...
}
}
...
}
```
```scala
// 创建接收器和处理器,同时并启动接收器
private def createDataPlaneAcceptorsAndProcessors(dataProcessorsPerListener: Int,endpoints: Seq[EndPoint]): Unit = synchronized {
// 遍历broker节点,为每个broker节点都创建接收器
endpoints.foreach { endpoint =>
connectionQuotas.addListener(config, endpoint.listenerName)
// 创建接收器
val dataPlaneAcceptor = createAcceptor(endpoint, DataPlaneMetricPrefix)
// 创建处理器,并把处理器添加到RequestChannel和Acceptor的处理器列表中
addDataPlaneProcessors(dataPlaneAcceptor, endpoint, dataProcessorsPerListener)
// 启动接收器线程
KafkaThread.nonDaemon(s"data-plane-kafka-socket-acceptor-${endpoint.listenerName}-${endpoint.securityProtocol}-${endpoint.port}", dataPlaneAcceptor).start()
// 等待启动完成
dataPlaneAcceptor.awaitStartup()
// 把启动好的处理器添加到map中,并和broker做好了映射
dataPlaneAcceptors.put(endpoint, dataPlaneAcceptor)
}
}
```
从上面可以总结出SocketServer.startup方法主要创建了接收器和处理器,同时把接收器启动,但并未启动处理器,因为处理器会用到权限,需要等KafkaServer初始化完成,会单独启动处理器。把创建好的处理器添加到请求通道和接收器的处理器列表中
#### Acceptor.run
既然前面创建并启动了接收器,那咱们看下接收器都做了什么?
```scala
def run(): Unit = {
// 将ServerSocketChannel注册到Selector的OP_ACCEPT事件上
serverChannel.register(nioSelector, SelectionKey.OP_ACCEPT)
// 标志启动完成
startupComplete()
try {
var currentProcessorIndex = 0
while (isRunning) {
try {
// 选择器轮训请求
val ready = nioSelector.select(500)
if (ready > 0) {
// 获取所有的选择键
val keys = nioSelector.selectedKeys()
// 遍历选择键
val iter = keys.iterator()
while (iter.hasNext && isRunning) {
try {
val key = iter.next
iter.remove()
if (key.isAcceptable) {
//OP_ACCEPT事件发生,获取注册到选择键上的ServerSocketChannel,然后调用其accept方法,建立一个客户端和服务端的连接通道
accept(key).foreach { socketChannel =>
// 重试的次数=该接收器对应的处理器的个数
var retriesLeft = synchronized(processors.length)
var processor: Processor = null
do {
// 重试次数减一
retriesLeft -= 1
processor = synchronized {
// 采用轮训的方式把客户端的连接通道分配给处理器即每个处理器都会有多个 SocketChannel,对应多个客户端的连接
currentProcessorIndex = currentProcessorIndex % processors.length
// 根据索引获取对应的处理器
processors(currentProcessorIndex)
}
currentProcessorIndex += 1
// 如果新连接的队列满了,一直阻塞直到最后一个处理器可以能够接收连接
} while (!assignNewConnection(socketChannel, processor, retriesLeft == 0))
}
...
```
服务端的接收器主要负责接收客户端的连接,由上面的源码可知,接收器线程启动的时候,就注册了OP_ACCEPT事件,当客户端发起连接时,接收器线程就能监听到OP_ACCEPT事件,然后获取绑定到选择键上的ServerSocketChannel,并调用ServerSocketChannel的accept方法,建立一个客户端和服务端的连接通道,看下面的图
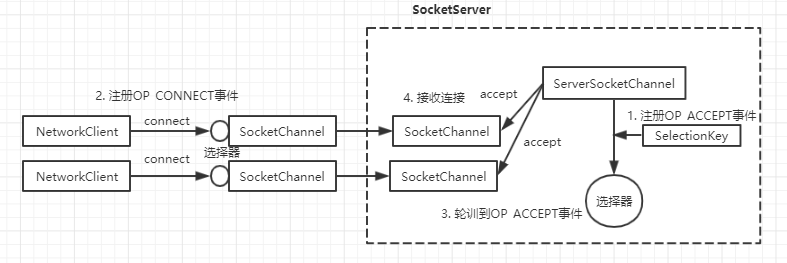
```
1.服务端ServerSocketChannel在选择器上注册OP_ACCEPT事件
2.客户端在选择器上注册OP_CONNECT事件
3.服务端的选择器轮训到OP_ACCEPT事件,接收客户端的连接
4.服务端的ServerSocketChannel调用accept方法创建和客户端的通道SocketChannel
```
#### Processor
通过前面的介绍,我们知道了接收器会通过轮训的方式把客户端的SocketChannel分配给处理器,这样每个处理器会对应多个SocketChannel,从而也就对应多个客户端。处理器会把接收器分配的SocketChannel放到自己的阻塞队列中,然后唤醒其对应的选择器工作,下面是对应的源码
```scala
do {
processor = synchronized {
// 采用轮训的方式把客户端的连接通道分配给处理器即每个处理器都会有多个SocketChannel,对应多个客户端的连接
currentProcessorIndex = currentProcessorIndex % processors.length
// 根据索引获取对应的处理器
processors(currentProcessorIndex)
}
currentProcessorIndex += 1
} while (!assignNewConnection(socketChannel, processor, retriesLeft == 0)) //把SocketChannel分配给处理器
```
```scala
private def assignNewConnection(socketChannel: SocketChannel, processor: Processor, mayBlock: Boolean): Boolean = {
if (processor.accept(socketChannel, mayBlock, blockedPercentMeter)) {
...
}
```
```scala
def accept(socketChannel: SocketChannel, mayBlock: Boolean,
acceptorIdlePercentMeter: com.yammer.metrics.core.Meter): Boolean = {
val accepted = {
// 往处理器的阻塞队列中添加SocketChannel
if (newConnections.offer(socketChannel))
true
...
if (accepted)
// 唤醒选择器线程开始轮询,原来的轮询因为没有事件到来被阻塞
wakeup()
accepted
}
```
下面我们再看下Processor的run方法
```scala
override def run(): Unit = {
startupComplete()
try {
while (isRunning) {
// 把新的SocketChannel注册OP_READ事件到选择器上
configureNewConnections()
// 注册OP_WRITE事件,用来给客户端写回响应
processNewResponses()
// 选择器轮训事件,用来读取请求、发送响应,默认超时时间为300ms
poll()
// 处理已经接收完成的客户端请求
processCompletedReceives()
// 处理已经完成的响应
processCompletedSends()
...
```
#### Processor.configureNewConnections
```scala
private def configureNewConnections(): Unit = {var connectionsProcessed = 0
// 从队列中取出SocketChannel
val channel = newConnections.poll()
// 注册OP_READ事件
// 根据本地的地址和端口、远程客户端的地址和端口构建唯一的connectionId
selector.register(connectionId(channel.socket), channel)
connectionsProcessed += 1
...
```
看下register方法,一直跟到最里面
```scala
public void register(String id, SocketChannel socketChannel) throws IOException {
registerChannel(id, socketChannel, SelectionKey.OP_READ);
}
```
```scala
protected SelectionKey registerChannel(String id, SocketChannel socketChannel, int interestedOps) throws IOException {
// 把SocketChannel注册OP_READ到选择器上,同时绑定SelectionKey
SelectionKey key = socketChannel.register(nioSelector, interestedOps);
// 构建Kafka通道KafkaChannel并将其绑定到选择键上
KafkaChannel channel = buildAndAttachKafkaChannel(socketChannel, id, key);
...
return key;
}
```
```scala
private KafkaChannel buildAndAttachKafkaChannel(SocketChannel socketChannel, String id, SelectionKey key) throws IOException {
// 构建Kafka通道
KafkaChannel channel = channelBuilder.buildChannel(id, key, maxReceiveSize, memoryPool);
// 将Kafka通道绑定到选择键上,这样就可以根据选择键获取到对应的通道
key.attach(channel);
return channel;
...
}
```
到这里configureNewConnections()的任务(把新的SocketChannel注册OP_READ事件到选择器上)已经完成
下面看下处理器如何响应结果的
#### Processor.processNewResponses
```scala
private def processNewResponses(): Unit = {var currentResponse: RequestChannel.Response = null
// 处理器还有响应要发送
while ({currentResponse = dequeueResponse(); currentResponse != null}) {
// KafkaChannel唯一标识
val channelId = currentResponse.request.context.connectionId
try {
currentResponse match {
case response: NoOpResponse =>
...
// 没有响应发送给客户端,需要读取更多请求,注册读事件
tryUnmuteChannel(channelId)
case response: SendResponse =>
// 有响应要发送给客户端,注册写事件
sendResponse(response, response.responseSend)
...
```
```scala
protected[network] def sendResponse(response: RequestChannel.Response, responseSend: Send): Unit = {
val connectionId = response.request.context.connectionId
...
if (openOrClosingChannel(connectionId).isDefined) {
// 将响应通过Selector标记为Send,实际发送通过poll轮询完成
selector.send(responseSend)
// 添加到 inflightResponses 底层是可变的Map key:connectionId value:response
inflightResponses += (connectionId -> response)
}
}
```
configureNewConnections()和processNewResponses()方法结束后,开始执行poll()方法,选择器轮询事件,读取请求,写回响应,然后处理已经完成的接收和响应
#### Processor.processCompletedReceives()
```scala
private def processCompletedReceives(): Unit = {
selector.completedReceives.asScala.foreach { receive =>
try {
openOrClosingChannel(receive.source) match {
case Some(channel) =>
// 解析ByteBuffer 到ReuestHeader
val header = RequestHeader.parse(receive.payload)
val connectionId = receive.source
// 组装RequestContext对象
val context = new RequestContext(header, connectionId, channel.socketAddress,...)
// 构建 RequestChannel.Request对象 包含了处理器的编号,响应对象中可以获取到,这样就能保证请求和响应的处理都是在同一个处理器中完成
val req = new RequestChannel.Request(processor = id, context = context,...)
// 发送给 RequestChannel 处理
requestChannel.sendRequest(req)
// 移除OP_READ读事件,已经接收到请求了,所以就不用再读了
selector.mute(connectionId)
...
```
#### Processor.processCompletedSends()
```scala
private def processCompletedSends(): Unit = {
selector.completedSends.asScala.foreach { send =>
try {
// 结束的写请求要从inflightResponses移出
val response = inflightResponses.remove(send.destination).getOrElse {...}
...
// 添加 OP_READ 读事件,这样就可以继续读取客户端发来的请求
tryUnmuteChannel(send.destination)
...
```
到这里服务端和网络连接相关的源码已经介绍完了,我们知道处理器把请求放到了请求队列里,同时从响应队列里获取响应返回给客户端,那谁去处理另外请求队列里的请求?又是谁把响应放到了处理器的响应队列里呢?
#### Kafaka处理请求线程KafkaRequestHandler
在前面的介绍中,我们知道KafkaServer在初始化时会创建请求处理线程池(KafkaRequestHandlerPool),请求处理线程池会创建并启动请求处理线程(KafkaRequestHandler),每个请求处理线程都能可以访问到共享的请求队列,这样请求处理线程就可以从请求队列里获取请求,然后交给KafkaApis处理。
```scala
// KafkaServer 会创建 KafkaRequestHandlerPool,同时把请求队列传过去
dataPlaneRequestHandlerPool = new KafkaRequestHandlerPool(config.brokerId, socketServer.dataPlaneRequestChannel, dataPlaneRequestProcessor, ...)
```
```scala
// 请求处理线程的数量取决于配置 num.io.threads,默认是8
val runnables = new mutable.ArrayBuffer[KafkaRequestHandler](numThreads)
for (i
try {
// 交给KafkaApis处理
apis.handle(request)
...
```
通过源码分析可以看出请求处理线程任务很简单,就是从共享的请求队列里取出请求,然后调用KafakaApis处理请求
#### 服务端请求处理入口KafkaApis
在KafkaServer初始化时,初始化了真正的服务端请求处理器
```scala
// 全局的服务端入口
dataPlaneRequestProcessor = new KafkaApis(socketServer.dataPlaneRequestChannel,...)
```
请求处理线程调用KafkaApis的handle方法处理业务逻辑
```scala
def request.header.apiKey match {
// 处理客户端生产消息的请求
case ApiKeys.PRODUCE => handleProduceRequest(request)
case ApiKeys.FETCH => handleFetchRequest(request)
...
```
可见Kafka服务端的请求处理入口KafkaApis根据请求的类型选择不同的处理器,至于服务端对这些请求做了什么,我们下次再分享
#### 参考资料
1.《Kafka技术内幕》
2.《Apache Kafka源码剖析》
3.Kafka最新的trunk分支代码

Kafka服务端之网络连接源码分析的更多相关文章
- Netty服务端启动过程相关源码分析
1.Netty 是怎么创建服务端Channel的呢? 我们在使用ServerBootstrap.bind(端口)方法时,最终调用其父类AbstractBootstrap中的doBind方法,相关源码如 ...
- # Volley源码解析(二) 没有缓存的情况下直接走网络请求源码分析#
Volley源码解析(二) 没有缓存的情况下直接走网络请求源码分析 Volley源码一共40多个类和接口.除去一些工具类的实现,核心代码只有20多个类.所以相对来说分析起来没有那么吃力.但是要想分析透 ...
- SpringCloud微服务如何优雅停机及源码分析
目录 方式一:kill -9 java进程id[不建议] 方式二:kill -15 java进程id 或 直接使用/shutdown 端点[不建议] kill 与/shutdown 的含义 Sprin ...
- 微服务架构 | *3.5 Nacos 服务注册与发现的源码分析
目录 前言 1. 客户端注册进 Nacos 注册中心(客户端视角) 1.1 Spring Cloud 提供的规范标准 1.2 Nacos 的自动配置类 1.3 监听服务初始化事件 AbstractAu ...
- Android网络框架源码分析一---Volley
转载自 http://www.jianshu.com/p/9e17727f31a1?utm_campaign=maleskine&utm_content=note&utm_medium ...
- 从壹开始微服务 [ DDD ] 之十一 ║ 基于源码分析,命令分发的过程(二)
缘起 哈喽小伙伴周三好,老张又来啦,DDD领域驱动设计的第二个D也快说完了,下一个系列我也在考虑之中,是 Id4 还是 Dockers 还没有想好,甚至昨天我还想,下一步是不是可以写一个简单的Angu ...
- 客户端与服务端的事件watcher源码阅读
watcher存在的必要性 举个特容易懂的例子: 假如我的项目是基于dubbo+zookeeper搭建的分布式项目, 我有三个功能相同的服务提供者,用zookeeper当成注册中心,我的三个项目得注册 ...
- Netty服务端与客户端(源码一)
首先,整理NIO进行服务端开发的步骤: (1)创建ServerSocketChannel,配置它为非阻塞模式. (2)绑定监听,配置TCP参数,backlog的大小. (3)创建一个独立的I/O线程, ...
- Redis网络库源码分析(1)之介绍篇
一.前言 Redis网络库是一个单线程EPOLL模型的网络库,和Memcached使用的libevent相比,它没有那么庞大,代码一共2000多行,因此比较容易分析.其实网上已经有非常多有关这个网络库 ...
随机推荐
- JAVA基础知识(三):input.nextLine() 和input.next()
next()方法在读取内容时,会过滤掉有效字符前面的无效字符,对输入有效字符之前遇到的空格键.Tab键或Enter键等结束符,next()方法会自动将其过滤掉:只有在读取到有效字符之后,next()方 ...
- 转载 | 一种让超大banner图片不拉伸、全屏宽、居中显示的方法
现在很多网站的Banner图片都是全屏宽度的,这样的网站看起来显得很大气.这种Banner一般都是做一张很大的图片,然后在不同分辨率下都是显示图片的中间部分.实现方法如下: <html> ...
- Docker部署网站之后映射域名
Docker中部署tomcat相信大家也都知道,不知道的可以google 或者bing 一下.这里主要是为了记录在我们启动容器之后,tomcat需要直接定位到网站信息,而不是打开域名之后,还得加个bl ...
- CSS实现三栏布局(5种)
常见的布局方式: float布局.Position定位.table布局.弹性(flex)布局.网格(grid)布局 那么我们就是用以上5种方式完成三栏布局,不过前提是左右宽度(假如左右宽度为300px ...
- python调用支付宝支付接口详细示例—附带Django demo代码
项目演示: 一.输入金额 二.跳转到支付宝付款 三.支付成功 四.跳转回自己网站 在使用支付宝接口的前期准备: 1.支付宝公钥 2.应用公钥 3.应用私钥 4.APPID 5.Django 1.11. ...
- ASP.NET Core on K8S深入学习(4)你必须知道的Service
本篇已加入<.NET Core on K8S学习实践系列文章索引>,可以点击查看更多容器化技术相关系列文章. 前面几篇文章我们都是使用的ClusterIP供集群内部访问,每个Pod都有一个 ...
- git 常规业务场景 使用
一般每个开发者都会有个自己的分支,有个test分支,合并代码用,两条分支相互备份,就算merge的时候被覆盖,也不用担心 建立自己的分支 // 创建本地分支, git checkout -b dev_ ...
- FaceNet人脸识别研究
https://github.com/WindZu/facenet_facerecognition (代码) https://segmentfault.com/a/1190000015917420?u ...
- MySql定时器,亲测可用
1. 查看数据库的event功能是否开启,在MySql中event默认是关闭的,需要查看并且要确保event处于开启状态 sql:show VARIABLES LIKE '%sche%'; 如果eve ...
- 11_for语句的使用
for是一种循环结构 go语言中,for语句结构: for 初始语句; 条件语句; 迭代后语句 { 代码体 } 例子: package main import "fmt" impo ...