Python学习之旅:使用Python实现Linux中的ls命令
一、写在前面
前几天在微信上看到这样一篇文章,链接为:https://mp.weixin.qq.com/s/rl6Sgv3uk_IpoFAx6cWa8w,在这篇文章中,有这样一段话,吸引了我的注意:

在 Linux 中 ls 是一个使用频率非常高的命令了,可选的参数也有很多, 算是一条不得不掌握的命令。Python 作为一门简单易学的语言,被很多人认为是不需要认真学的,或者只是随便调个库就行了,那可就真是小瞧 Python 了。那这次我就要试着用 Python 来实现一下 Linux 中的 ls 命令, 小小地证明下 Python 的不简单!
二、ls简介
Linux ls 命令用于显示指定工作目录下的内容。语法如下:
ls [-alkrt] [name]
这里只列举了几个常用的参数,ls 命令的可选参数还是很多的,可以使用 man ls 来进行查看具体信息。这里列出的几个参数对应含义如下:
1)-a:显示所有文件及目录;
2)-l:除文件名称外,亦将文件大小、创建时间等信息列出;
3)-k:将文件大小以 KB 形式表示;
4)-r:将文件以相反次序排列;
5)-t:将文件以修改时间次序排列。
三、具体思路
主要使用的模块是 argparse 和 os,其中 argparse 模块能设置和接收命令行参数,也就使得 Python 对命令行的操作变得简单,而 os 模块则用于文件操作,对 argparse 模块不熟悉的可以在这里查看官方文档。
既然要用 Python 实现 ls.py, 也就要在命令行中进行操作,比如 python ls.py -a 这样的命令,而对 Python 比较熟悉的人可能会想到使用 sys 模块来接收输入的命令,但使用 argparse 能让命令行操作变得更加简单!首先要导入模块并创建一个 ArgumentParser 对象,可以理解为一个解析器,然后就可以通过使用 add_argument() 方法为这个解析器添加参数了。示例如下:
# test.py
import argparse parser = argparse.ArgumentParser(description='Find the maximum number.')
parser.add_argument("integers", type=int, nargs="+", help="The input integers.")
parser.add_argument("-min", nargs="?", required=False, dest="find_num", default=max, const=min,
help="Find the minimum number(Default: find the maximum number).") args = parser.parse_args()
print(args)
print(args.find_num(args.Nums))
这段代码的功能是输入一到多个整数,默认求其中的最大值,若有 -min 参数则是求其中的最小值。可以看到在创建解析器和添加命令行参数的时候都设置了 description 描述信息,这个信息会在我们使用 --help 命令的时候显示出来,例如:
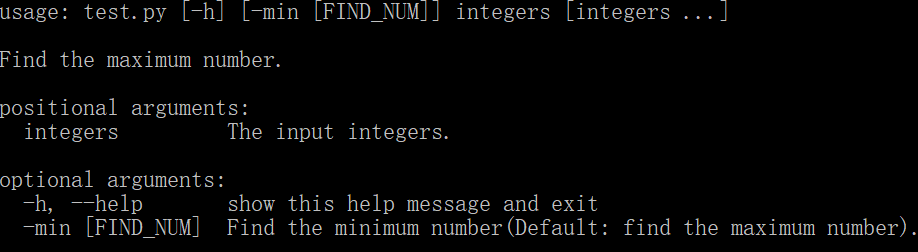
在上面的代码中,需要注意的是其中使用 add_argument() 添加了一个位置参数 "integers" 和一个可选参数 "-min",位置参数在命令行中必须存在,不可遗漏,也就不能设置 required 参数了,而可选参数就不是必须要有的了,因而还可以使用 default 参数设置默认值。nargs 参数用于设置命令行参数的数量,"+" 表示一个或多个,"?" 表示零个或一个,这里由于输入的数字可能有多个,所以要设置为 "+"。最终运行示例如下:
> python test.py 1 3 5
Namespace(find_num=<built-in function max>, integers=[1, 3, 5])
5> python test.py 1 3 5 -min
Namespace(find_num=<built-in function min>, integers=[1, 3, 5])
1
关于 argparse 的介绍就到此为止了,下面简单介绍下 os 模块, os 模块提供了便捷的使用操作系统相关功能的方式,实现 ls.py 所用到的该模块下的方法包括:
1)os.path.isdir(path):若 path 是一个存在的目录,返回 True。
2)os.listdir(path):返回一个列表,其中包括 path 对应的目录下的内容,不包含“.”和“..”,即使它们存在。
3)os.stat(path):获取文件或文件描述符的状态,返回一个 stat_result 对象,其中包含了各种状态信息。
四、主要代码
ls.py 中的主函数如下,主要功能为创建解析器,设置可选参数和位置参数,然后接收命令行参数信息,并根据输入的参数调用相应的方法,这里设置了一个 "-V" 参数用于显示版本信息,可以使用 "-V" 或者 "-Version" 进行查看。
def main():
"""
主函数,设置和接收命令行参数,并根据参数调用相应方法
:return:
"""
# 创建解析器
parse = argparse.ArgumentParser(description="Python_ls")
# 可选参数
parse.add_argument("-a", "-all", help="Show all files", action="store_true", required=False)
parse.add_argument("-l", "-long", help="View in long format", action="store_true", required=False)
parse.add_argument("-k", help="Expressed in bytes", action="store_true", required=False)
parse.add_argument("-r", "-reverse", help="In reverse order", action="store_true", required=False)
parse.add_argument("-t", help="Sort by modified time", action="store_true", required=False)
parse.add_argument("-V", "-Version", help="Get the version", action="store_true", required=False)
# 位置参数
parse.add_argument("path", type=str, help="The path", nargs="?") # 命令行参数信息
data = vars(parse.parse_args())
assert type(data) == dict
if data["V"]:
print("Python_ls version: 1.0")
return
else:
check_arg(data)
然后是一个获取指定路径下的内容信息的函数,要做的就是判断路径是否存在,若存在就返回一个文件列表,若不存在则显示错误信息,并退出程序。
def get_all(path):
"""
获取指定路径下的全部内容
:param path: 路径
:return:
"""
if os.path.isdir(path):
files = [".", ".."] + os.listdir(path)
return files
else:
print("No such file or directory")
exit()
五、运行结果
下面是 ls.py 运行后的部分结果截图。
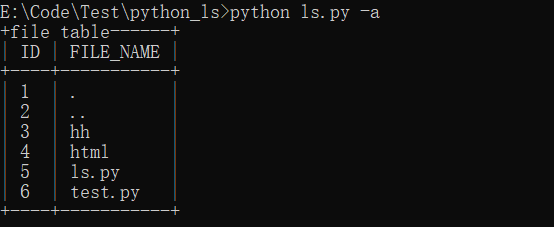
首先是 python ls.py -a,这里并没有输入路径,就会使用默认路径即当前目录,如下图:
然后是 python ls.py -a -t .,使用该命令会显示当前目录下的所有内容,并按照创建的时间进行排序,如下图:

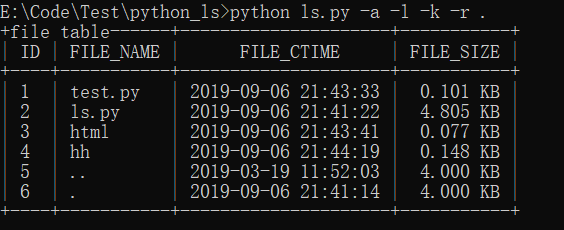
最后是 python ls.py -a -l -k -r .,也是显示当前目录下的所有内容并按照创建名称排序,不过这次文件大小会以 KB 为单位来显示,如下图:
到这里为止,ls.py 就算是基本实现了,当然还是有很多可以去实现的功能的,比如更多的参数等等,如果你感兴趣的话可以自己尝试一下==
完整代码已上传到GitHub!
Python学习之旅:使用Python实现Linux中的ls命令的更多相关文章
- Linux中的ls命令详细使用
ls命令是linux下最常用的命令之一,ls跟dos下的dir命令是一样的都是用来列出目录下的文件,下面我们就来一起看看ls的用法 英文全名:List即列表的意思,当我们学习某种东西的时候要做到知其所 ...
- 我的python学习之旅——安装python
windows下载安装: 1.下载安装包: 访问官方网站:https://www.python.org/downloads/ 下载自己想要的版本安装,这里下载当前最新版3.8: 选择64位的Windo ...
- 180分钟的python学习之旅
最近在很多地方都可以看到Python的身影,尤其在人工智能等科学领域,其丰富的科学计算等方面类库无比强大.很多身边的哥们也提到Python非常的简洁方便,比如用Django搭建一个见得网站只需要半天时 ...
- python学习第八讲,python中的数据类型,列表,元祖,字典,之字典使用与介绍
目录 python学习第八讲,python中的数据类型,列表,元祖,字典,之字典使用与介绍.md 一丶字典 1.字典的定义 2.字典的使用. 3.字典的常用方法. python学习第八讲,python ...
- python学习第七讲,python中的数据类型,列表,元祖,字典,之元祖使用与介绍
目录 python学习第七讲,python中的数据类型,列表,元祖,字典,之元祖使用与介绍 一丶元祖 1.元祖简介 2.元祖变量的定义 3.元祖变量的常用操作. 4.元祖的遍历 5.元祖的应用场景 p ...
- python学习第六讲,python中的数据类型,列表,元祖,字典,之列表使用与介绍
目录 python学习第六讲,python中的数据类型,列表,元祖,字典,之列表使用与介绍. 二丶列表,其它语言称为数组 1.列表的定义,以及语法 2.列表的使用,以及常用方法. 3.列表的常用操作 ...
- python学习第四讲,python基础语法之判断语句,循环语句
目录 python学习第四讲,python基础语法之判断语句,选择语句,循环语句 一丶判断语句 if 1.if 语法 2. if else 语法 3. if 进阶 if elif else 二丶运算符 ...
- linux中神奇的命令alias
在linux中大家应该都知道,有些命令和参数特别繁琐,而且还是大量输入这些命令,这个时候我们就可以使用linux中的alias命令来给这些繁琐的命令起别名,但是,alias 命令只对当前终端有效,当终 ...
- Linux中的历史命令
Linux中的历史命令一般保存在用户 /root/.bash_history history 选项 历史命令保存文件夹 选项 -c:清空历史命令 -w :把缓存中的历史命令写入历 ...
随机推荐
- 【JDK】JDK源码分析-AbstractQueuedSynchronizer(2)
概述 前文「JDK源码分析-AbstractQueuedSynchronizer(1)」初步分析了 AQS,其中提到了 Node 节点的「独占模式」和「共享模式」,其实 AQS 也主要是围绕对这两种模 ...
- 记录eclipse中文出现空格宽度不一致的bug
起因 不久前更新了 eclipse(2019-03) 版本:突然发现出现了,使用注释使用中出现的空格的间隔大小不一致的问题,具体可以看下图: 遇到这种问题简直逼不能忍,在网上搜一下解决方式: 谷歌 搜 ...
- Android buildType混淆代码
[话题引入] ①在Android开发完成,我们会将代码打包成APK文件.选择 菜单栏 Build --> Build APK ②将查看视图切换到 Project 模式,文件夹下有一个debug模 ...
- Python 四大主流 Web 编程框架
Python 四大主流 Web 编程框架 目前Python的网络编程框架已经多达几十个,逐个学习它们显然不现实.但这些框架在系统架构和运行环境中有很多共通之处,本文带领读者学习基于Python网络框架 ...
- react学习(二)--元素渲染
元素用来描述你在屏幕上看到的内容: const element = <h1>Hello, world</h1>; 与浏览器的 DOM 元素不同,React 当中的元素事实上是普 ...
- java中的异常 try catch
1.学习异常的原因? 如果没有异常处理机制,那么程序的一点小问题,都会导致[程序终止运行].实际开发中显然是不可能的,所以异常对于程序来说是非常重要的. 2.处理异常的方式: A ...
- 【KakaJSON手册】02_JSON转Model_02_数据类型
由于JSON格式的能表达的数据类型是比较有限的,所以服务器返回的JSON数据有时无法自动转换成客户端想要的数据类型. 比如服务器返回的时间可能是个毫秒数1565480696,但客户端想要的是Date类 ...
- Spring入门(九):运行时值注入
Spring提供了2种方式在运行时注入值: 属性占位符(Property placeholder) Spring表达式语言(SpEL) 1. 属性占位符 1.1 注入外部的值 1.1.1 使用Envi ...
- win10文件备份、文件同步方案
用个人版onedrive同步重要数据,数据安全有保障,但免费版只有15G空间,需要合理分配.(201907与别人合租家庭版,空间1T充足) google-drive可以同步指定的文件夹,但空间也只有1 ...
- 重学计算机组成原理(十)- "烫烫烫"乱码的由来
程序 = 算法 + 数据结构 对应到计算机的组成原理(硬件层面) 算法 --- 各种计算机指令 数据结构 --- 二进制数据 计算机用0/1组成的二进制,来表示所有信息 程序指令用到的机器码,是使用二 ...