工作中遇到的99%SQL优化,这里都能给你解决方案(三)
-- 示例表
CREATE TABLE `employees` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(24) NOT NULL DEFAULT '' COMMENT '姓名',
`age` int(20) NOT NULL DEFAULT '0' COMMENT '年龄',
`position` varchar(20) NOT NULL DEFAULT '' COMMENT '职位',
`hire_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '入职时间',
PRIMARY KEY (`id`),
KEY `idx_name_age_position` (`name`,`age`,`position`) USING BTREE,
KEY `idx_age` (`age`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=136326 DEFAULT CHARSET=utf8 COMMENT='员工表'
--创建100000条记录
drop procedure if EXISTS insert_emp;
delimiter ;;
create procedure insert_emp()
BEGIN
declare i int;
set i=1;
while(i < 100000)DO
INSERT INTO employees(name,age,position) values(CONCAT('xiaoqiang',i),i,'coder');
SET i=i+1;
end WHILE;
end;;
delimiter ;
call insert_emp();
根据自增且连续的主键排序的分页查询
select * from employees LIMIT 9999 ,5;
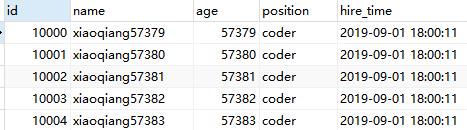

表示从表employees 中取出从10000行开始的5行记录。看似只查询5条记录,实际这条SQL是先读取10005条记录,然后抛弃前10000条记录,然后读到后面5条想要的数据。没有添加单独的order by,表示通过主键排序。
因此要查询一张大表比较靠后的数据,执行效率是非常低的。
因为主键是自增且连续的,所以可以改写成按照主键查询从第10001开始的五行数据,如下:
select * from employees WHERE id > 9999 limit 5;
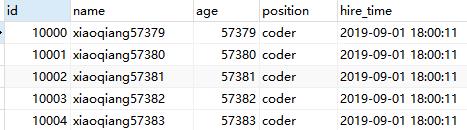

可以看到两个sql的执行计划,显然改写后的sql走了索引,而且扫描的行数大大减少,执行效率会更高。但是,这条改写的sql在很多场景下并不实用,因为表中可能某些记录被删除后,主键空缺,导致结果不一致。
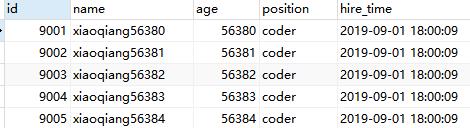
先删除一条记录,然后测试下原来sql和优化后的sql:
select * from employees LIMIT 9999 ,5;
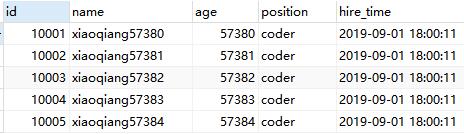
select * from employees where id> 9999 limit 5;

两条sql的结果不一样,因此,如果主键不连续,不能使用上面描述的方法。
另外由于原来sql是order by非主键字段,按照上面的方法改写sql的结果不一致。所以这种改写得满足以下两个条件:
- 主键自增且连续
- 结果是按照主键排序的
根据非主键字段排序的分页查询
select * from employees order by name limit 9000, 5;
explain select * from employees order by name limit 9000, 5;

key字段对应的值为null,发现并没有使用name字段的索引。因为扫描整个索引并查找到没有索引的行,可能要便利多个索引树,其成本比扫描全表的成本更高,索引优化器放弃使用索引。
优化的关键是:让排序时返回的字段尽可能的少,所以可以让排序和分页操作先查出主键,然后根据主键查到对应的记录。
改下如下:
select * from employees as e inner join(select id from employees order by name limit 9000,5) as ed on e.id=ed.id;
可以看到结果与原来的sql结果是一致的,执行时间减少了一般以上,再对比下执行计划:

原来的sql使用的是filesort排序,而优化后的sql使用的是索引排序。
in和exists优化
原则:小表驱动大表,即小表的数据集驱动大表的数据集
in:当B表的数据集小于A表的数据集时,in由于exists
select * from A where id in(select id from B)
等价于
for(select id from B){
select * from A where A.id=B.id
}
exists:当A表的数据集小于B表的数据集时,exitsts优于in
当著查询A的数据,放到子查询B中做条件验证,根据验证结果(true或false)来决定著查询的数据是否保留。
select * from A exists(select 1 from B where A.id=B.id)
等价于
for(select * from A){
select * from B where A.id=B.id
}
count(*)查询优化
explain select count(1) from employees;
explain select count(id) from employees;
explain select count(name) from employees;
explain select count(*) from employees;

四个sql的执行计划几乎一样的,count(name)使用的是联合索引, 主要区别根据某个字段做count操作不会统计字段为null的值的数据行。
除了count(name)的其他count操作,都是用的辅助索引而不是主键索引, 因为二级索引存储数据更少,检索性能更高。
还没关注我的公众号?
- 扫文末二维码关注公众号【小强的进阶之路】可领取如下:
- 学习资料: 1T视频教程:涵盖Javaweb前后端教学视频、机器学习/人工智能教学视频、Linux系统教程视频、雅思考试视频教程;
- 100多本书:包含C/C++、Java、Python三门编程语言的经典必看图书、LeetCode题解大全;
- 软件工具:几乎包括你在编程道路上的可能会用到的大部分软件;
- 项目源码:20个JavaWeb项目源码。

工作中遇到的99%SQL优化,这里都能给你解决方案(三)的更多相关文章
- 工作中遇到的99%SQL优化,这里都能给你解决方案
前几篇文章介绍了mysql的底层数据结构和mysql优化的神器explain.后台有些朋友说小强只介绍概念,平时使用还是一脸懵,强烈要求小强来一篇实战sql优化,经过周末两天的整理和总结,sql优化实 ...
- 工作中遇到的99%SQL优化,这里都能给你解决方案(二)
-- 示例表 CREATE TABLE `employees` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(24) NOT NULL ...
- 收集一些工作中常用的经典SQL语句
作为一枚程序员来说和数据库打交道是不可避免的,现收集一下工作中常用的SQL语句,希望能给大家带来一些帮助,当然不全面,欢迎补充! 1.执行插入语句,获取自动生成的递增的ID值 INSERT INTO ...
- 在工作中常用到的SQL
前言 只有光头才能变强. 文本已收录至我的GitHub仓库,欢迎Star:https://github.com/ZhongFuCheng3y/3y 最近在公司做了几张报表,还记得刚开始要做报表的时候都 ...
- 工作中常用到的sql命令!!!
一.mysql数据库日常操作. 1.启动mysql:/etc/init.d/mysql start (前面为mysql的安装路径) 2.重启mysql: /etc/init.d/my ...
- 工作中遇到的一道SQL应用题
登录日志表 CREATE TABLE [dbo].[LoginLog]([Seq] [int] NOT NULL IDENTITY(1, 1), --Seq[UserId] [varchar] (2 ...
- 分享一个工作中遇得到的sql(按每天每人统计拖车次数与小修次数)
查询每人每天的数据 首先先建表 CREATE TABLE `user` ( `name` ) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8; CR ...
- 《高性能SQL调优精要与案例解析》一书谈SQL调优(SQL TUNING或SQL优化)学习
<高性能SQL调优精要与案例解析>一书上市发售以来,很多热心读者就该书内容及一些具体问题提出了疑问,因读者众多外加本人日常工作的繁忙 ,在这里就SQL调优学习进行讨论并对热点问题统一作答. ...
- Oracle SQl优化总结
对数据库技术的热爱是我唯一的安慰,毕竟这是自己喜欢的事情,还可以做下去. 因为客户项目的需要,我又开始接触Oracle,大部分工作在工作流的优化和业务数据的排查上.为了更好的做这份工作,我有参考过or ...
随机推荐
- html的一些基本语法学习与实战
其实在学校前端开始之前,问过自己为什么要学,因为自己学的比较杂,直到现在刚刚毕业出来工作了,才明确了方向了,要往嵌入式方向走,但是随着时代的发展,在编程和智能硬件结合的越来越紧密,特别是物联网这一块, ...
- 干货 |《从Lucene到Elasticsearch全文检索实战》拆解实践
1.题记 2018年3月初,萌生了一个想法:对Elasticsearch相关的技术书籍做拆解阅读,该想法源自非计算机领域红火已久的[樊登读书会].得到的每天听本书.XX拆书帮等. 目前市面上Elast ...
- 【POJ - 2229】Sumsets(完全背包)
Sumsets 直接翻译了 Descriptions Farmer John 让奶牛们找一些数加起来等于一个给出的数N.但是奶牛们只会用2的整数幂.下面是凑出7的方式 1) 1+1+1+1+1+1+1 ...
- idea+Spring+Mybatis+jersey+jetty构建一个简单的web项目
一.先使用idea创建一个maven项目. 二.引入jar包,修改pom.xml <dependencies> <dependency> <groupId>org. ...
- SpringBoot:Mybatis + Druid 数据访问
西部开源-秦疆老师:基于SpringBoot 2.1.7 的博客教程 秦老师交流Q群号: 664386224 未授权禁止转载!编辑不易 , 转发请注明出处!防君子不防小人,共勉! 简介 对于数据访问层 ...
- .net core + mvc 手撸一个代码生成器
最近闲来无事,总想倒腾点什么,索性弄下代码生成器,这里感谢叶老板FreeSql的强大支持. 以前也用过两款不错的代码生成器,这里说说我的看法 1.动软代码生成器,优点很明显,免费,简单,但是没法高度自 ...
- Mac 安装 homebrew 流程 以及 停在 Updating Homebrew等 常见错误解决方法
懒人操作顺序:S_01>>>S_02>>>S_03 首先这是homebrew的官网 https://brew.sh/index_zh-cn 安装方法是在终端中输入 ...
- MYSQL--表与表之间的关系、修改表的相关操作
表与表之间的操作: 如果所有信息都在一张表中: 1.表的结构不清晰 2.浪费硬盘空间 3.表的扩展性变得极差(致命的缺点) 确立表与表之间的关系.一定要换位思考(必须在两者考虑清楚之后才能得出结论) ...
- Oracle中的日期函数
(一)查询系统的当前日期用sysdate,用法如下: select sysdate from dual 日期操作的三个格式: 日期-数字=日期 日期+=日期 日期-日期=数字(天数) (二)常用的日期 ...
- 给定n个十六进制正整数,输出它们对应的八进制数。
问题描述 给定n个十六进制正整数,输出它们对应的八进制数. 输入格式 输入的第一行为一个正整数n (1<=n<=10). 接下来n行,每行一个由0~9.大写字母A~F组成的字符串,表示要转 ...