Python爬虫教程-实现百度翻译
使用python爬虫实现百度翻译功能
python爬虫实现百度翻译: python解释器【模拟浏览器】,发送【post请求】,传入待【翻译的内容】作为参数,获取【百度翻译的结果】
通过开发者工具,获取发送请求的地址
提示: 翻译内容发送的请求地址,绝对不是打开百度翻译的那个地址,想要抓取地址,就要借助【浏览器的开发者工具】,或者其他抓包工具
下面介绍获取请求地址的具体方法
以Chrome为例
打开百度翻译:http://fanyi.baidu.com/
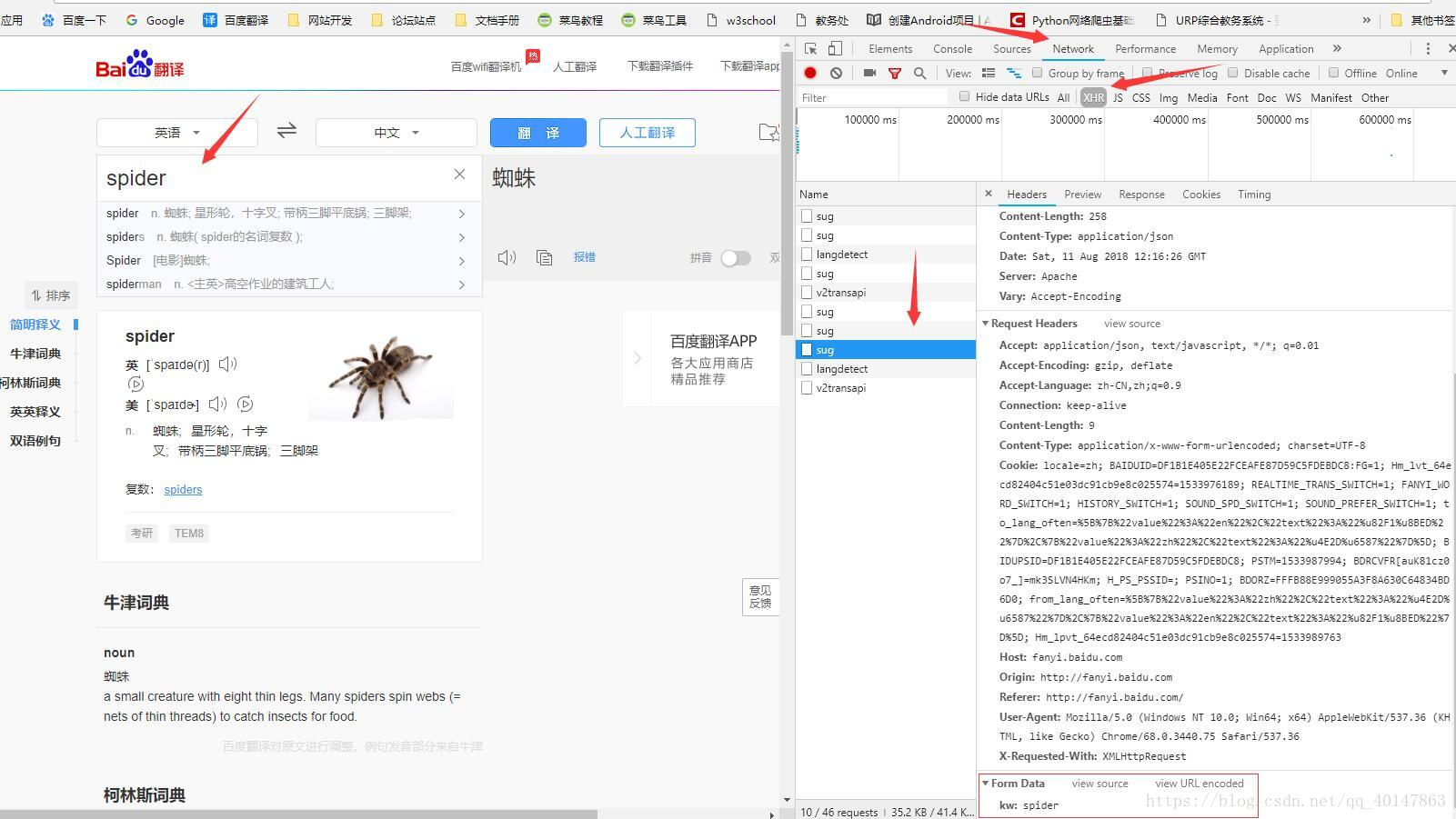
【点击右键】>【检查】>【network】(如果是火狐浏览器,点击【网络】)
点击【XHR】项,(有些需要刷新,有些异步的请求不需要刷新)
在页面【输入翻译的词汇】
在XHR项下,查找包含【输入需要翻译的词汇】的请求
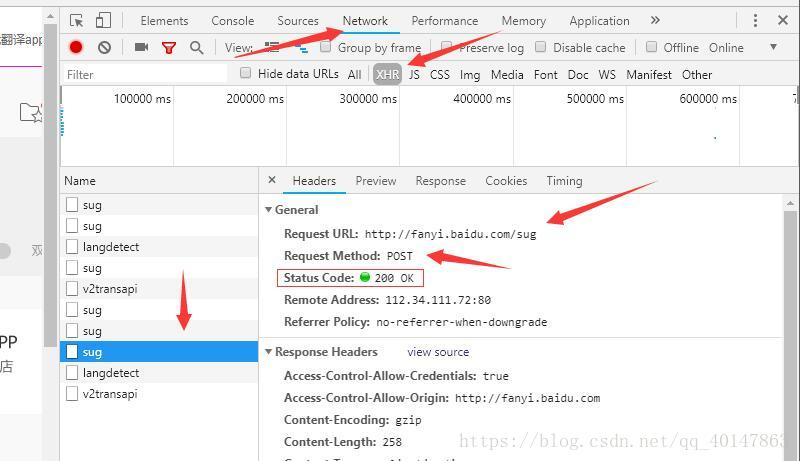
查看请求的参数,需要【点击请求】>【Headers】>最下面的【Form Data】
(这里有一个坑:我们会发现有多个sug项,其实是因为百度翻译只要每输入一个字母就会发送一次请求,所以虽然多个请求的地址都是一样的,但是只有最后一个sug项的参数才是最后的词汇)
操作截图 :
请求地址在这里
献上实现的代码
直接上代码,具体步骤下载注释上了
不会配置环境,安装python的包,请参考下一篇:
https://i-beta.cnblogs.com/posts/edit-done;postId=11945465
py05bdfanyi.py文件:https://xpwi.github.io/py/py%E7%88%AC%E8%99%AB/py05bdfanyi.py
# python爬虫实现百度翻译
# urllib和request POST参数提交
# 缺少包请自行查看之前的笔记 from urllib import request,parse
import json def fanyi(keyword):
base_url = 'http://fanyi.baidu.com/sug' # 构建请求对象
data = {
'kw': keyword
}
data = parse.urlencode(data) # 模拟浏览器
header = {"User-Agent": "mozilla/4.0 (compatible; MSIE 5.5; Windows NT)"} req = request.Request(url=base_url,data=bytes(data,encoding='utf-8'),headers=header)
res = request.urlopen(req) # 获取响应的json字符串
str_json = res.read().decode('utf-8')
# 把json转换成字典
myjson = json.loads(str_json)
info = myjson['data'][0]['v']
print(info) if __name__=='__main__':
while True:
keyword = input('请输入翻译的单词:')
if keyword == 'q':
break
fanyi(keyword)
代码运行

如果还有问题未能得到解决,搜索887934385交流群,进入后下载资料工具安装包等。最后,感谢观看!
Python爬虫教程-实现百度翻译的更多相关文章
- Python爬虫爬取百度翻译之数据提取方法json
工具:Python 3.6.5.PyCharm开发工具.Windows 10 操作系统 说明:本例为实现输入中文翻译为英文的小程序,适合Python爬虫的初学者一起学习,感兴趣的可以做英文翻译为中文的 ...
- python --爬虫--爬取百度翻译
import requestsimport json class baidufanyi: def __init__(self, trans_str): self.lang_detect_url = ' ...
- Python爬虫教程-08-post介绍(百度翻译)(下)
Python爬虫教程-08-post介绍(下) 为了更多的设置请求信息,单纯的通过urlopen已经不太能满足需求,此时需要使用request.Request类 构造Request 实例 req = ...
- Python爬虫教程-07-post介绍(百度翻译)(上)
Python爬虫教程-07-post介绍(百度翻译)(上) 访问网络两种方法 get: 利用参数给服务器传递信息 参数为dict,使用parse编码 post :(今天给大家介绍的post) 一般向服 ...
- Python爬虫教程-06-爬虫实现百度翻译(requests)
使用python爬虫实现百度翻译(requests) python爬虫 上一篇介绍了怎么使用浏览器的[开发者工具]获取请求的[地址.状态.参数]以及使用python爬虫实现百度翻译功能[urllib] ...
- Python爬虫教程-16-破解js加密实例(有道在线翻译)
python爬虫教程-16-破解js加密实例(有道在线翻译) 在爬虫爬取网站的时候,经常遇到一些反爬虫技术,比如: 加cookie,身份验证UserAgent 图形验证,还有很难破解的滑动验证 js签 ...
- Python爬虫教程-01-爬虫介绍
Spider-01-爬虫介绍 Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所以对应变能力有些要求 爬虫准备工作 参考资料 精通Python爬虫框架Scrap ...
- Python爬虫教程-00-写在前面
鉴于好多人想学Python爬虫,缺没有简单易学的教程,我将在CSDN和大家分享Python爬虫的学习笔记,不定期更新 基础要求 Python 基础知识 Python 的基础知识,大家可以去菜鸟教程进行 ...
- 简单的python爬虫教程:批量爬取图片
python编程语言,可以说是新型语言,也是这两年来发展比较快的一种语言,而且不管是少儿还是成年人都可以学习这个新型编程语言,今天南京小码王python培训机构变为大家分享了一个python爬虫教程. ...
随机推荐
- 腾讯,华为,阿里…7家Java后端面试经验大公开!
感觉面试还是主要围绕简历来问的,所以不熟悉的东西最好不要随便写上去.项目和基础都很重要,整体的基础知识的框架可以参考GitHub 上 CYC2018的博客,分类很全,但是深入的学习还是要自己去看书,写 ...
- LeetCode刷题-最长公共前缀(简单)
题目描述 编写一个函数来查找字符串数组中的最长公共前缀. 如果不存在公共前缀,返回空字符串 "". 示例 1: 输入: ["flower","flow ...
- Keystone安装与配置
一.实验目的: 1.掌握OpenStack环境搭建的基础工作 2.掌握keystone的安装与配置方法 3.掌握keystone基础接口的调用方法 二.实验步骤: 1.利用最初创建的快照克隆两台Cen ...
- Markdown数学公式语法
详细网址:Markdown数学公式语法
- 集合系列 Set(七):LinkedHashSet
LinkedHashSet 继承了 HashSet,在此基础上维护了元素的插入顺序. public class LinkedHashSet<E> extends HashSet<E& ...
- 微信小程序的坑(持续更新中)
参与微信小程序开发有一段时间了,先后完成信息查询类和交易类的两个不同性质的小程序产品的开发:期间遇到各种各样的小程序开发的坑,有的是小程序基础功能不断改进完善而需要业务持续的适配,有的是小程序使用上的 ...
- 【第二章】Zabbix3.4监控SQLServer数据库和H3C交换机思科Cisco防火墙交换机教程笔记
监控SQLServer数据库 SSMS执行相关SQL SQL模板命名规则 Zabbix客户端导入模板 添加SQLServer监控图形 SQLServer服务器关联模板 监控思科Cisco防火墙交换机 ...
- (五十七)c#Winform自定义控件-传送带(工业)-HZHControls
官网 http://www.hzhcontrols.com 前提 入行已经7,8年了,一直想做一套漂亮点的自定义控件,于是就有了本系列文章. GitHub:https://github.com/kww ...
- Add an Item to the New Action 在新建按钮中增加一个条目
In this lesson, you will learn how to add an item to the New Action (NewObjectViewController.NewObje ...
- Comprehensive Tutorial 综合教程(MainDemo应用程序)
Follow this tutorial to create a simple application used to store contacts and other related objects ...