三大特征提取器(RNN/CNN/Transformer)
目录
三大特征提取器 - RNN、CNN和Transformer
简介
近年来,深度学习在各个NLP任务中都取得了SOTA结果。这一节,我们先了解一下现阶段在自然语言处理领域最常用的特征抽取结构。
本文部分参考张俊林老师的文章《放弃幻想,全面拥抱Transformer:自然语言处理三大特征抽取器(CNN/RNN/TF)比较》(写的非常好,学NLP必看博文),这里一方面对博文进行一定程度上的总结,并加上一些个人理解。
在深度学习流行起来之后,随着我们的网络越做越深,我们的神经网络模型越来越像一个黑箱,我们只要喂给它数据,我们的模型就能够根据我们的给予的目标,自动学习抽取对于该任务最有利的特征(这点在CV中更为明显,比如在卷积神经网络的不同层能够输出图像中不同层面上的细节特征),从而实现了著名的“端到端”模型。在这里,我们可以把我们的CNN、RNN以及Transformer看作抽取数据特征的特征抽取器。下面,本文将为大家简单介绍RNN、CNN及NLP新宠Transformer的基本结构及其优缺点。
循环神经网络RNN
传统RNN
在2018年以前,在NLP各个子领域的State of Art的结果都是RNN(此处包含LSTM、GRU等变种)得到的。为什么RNN在NLP领域能够有如此广泛的应用?我们知道如果将全连接网络运用到NLP任务上,其会面临三个主要问题:
- 对于不同的输入样本,输入和输出可能有不同的长度,因此输入层和输出层的神经元数量无法固定。
- 从输入文本的不同位置学到的同一特征无法共享。
- 模型中的参数太多,计算量太大。
为了解决上述问题,我们就有了熟悉的RNN网络结构。其通过扫描数据输入的方式,使得每一个时间步的所有网络参数是共享的,且每个时间步不仅会接收当前时刻的输入,同时会接收上一个时刻的输出,从而使得其能够成功利用过去输入的信息来辅助当前时刻的判断。
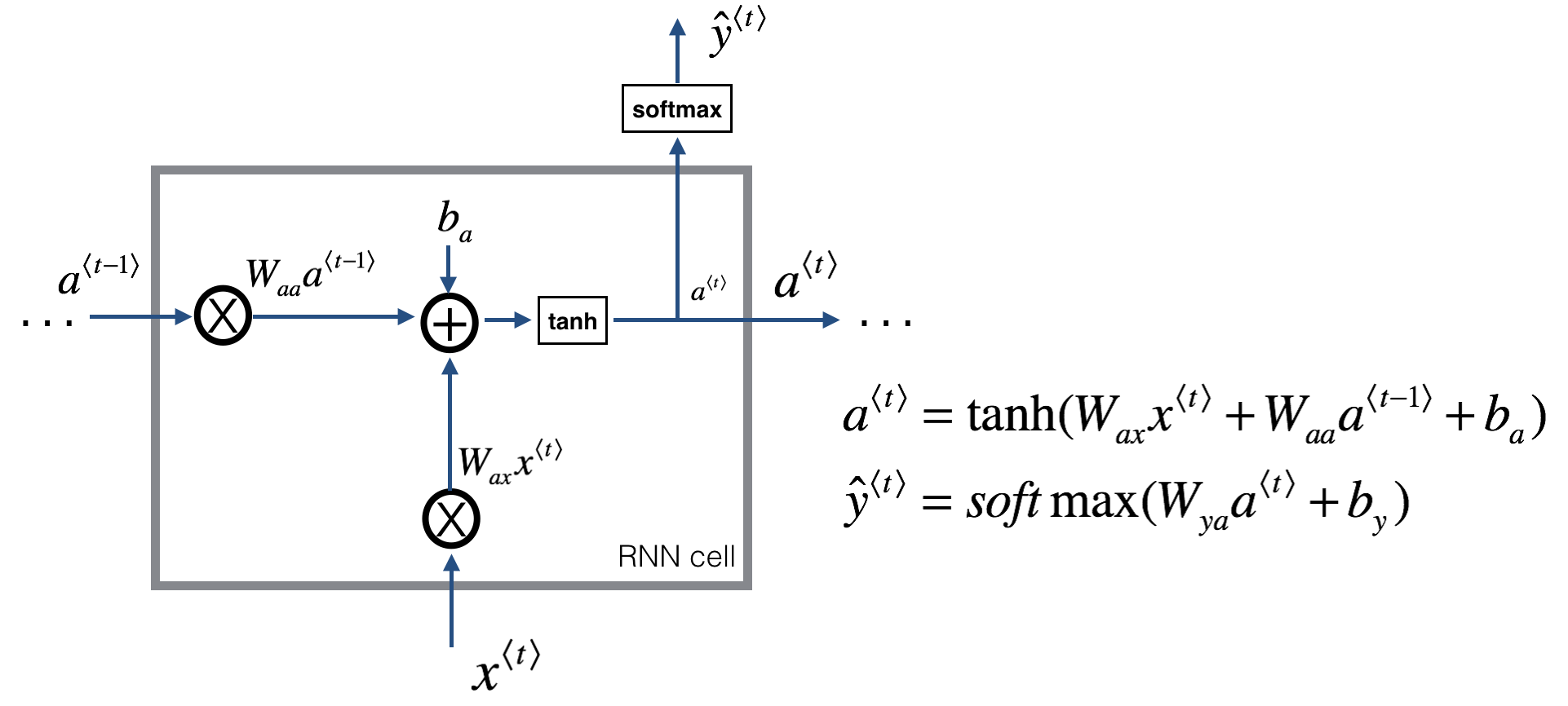
但是,原始的RNN也存在问题,它采取线性序列结构不断从前往后收集输入信息,但这种线性序列结构不擅长捕获文本中的长期依赖关系,如下图所示。这主要是因为反向传播路径太长,从而容易导致严重的梯度消失或梯度爆炸问题。
长短期记忆网络(LSTM)
传统RNN的做法是将的所有知识全部提取出来,不作任何处理的输入到下一个时间步进行迭代。就像参加考试一样,如果希望事先把书本上的所有知识都记住,到了考试的时候,早期的知识恐怕已经被近期的知识完全覆盖了,提取不到长远时间步的信息是很正常的。而人类是这样做的吗?显然不是的,我们通常的做法是对知识有一个理性性判断,重要的知识给予更高的权重,重点记忆,不那么重要的可能没多久就忘了,这样,才能在面对考试的时候有较好的发挥。
在我看来,LSTM的结构更类似于人类对于知识的记忆方式。理解LSTM的关键就在于理解两个状态\(c^{t}\)和\(a^t\)和内部的三个门机制:
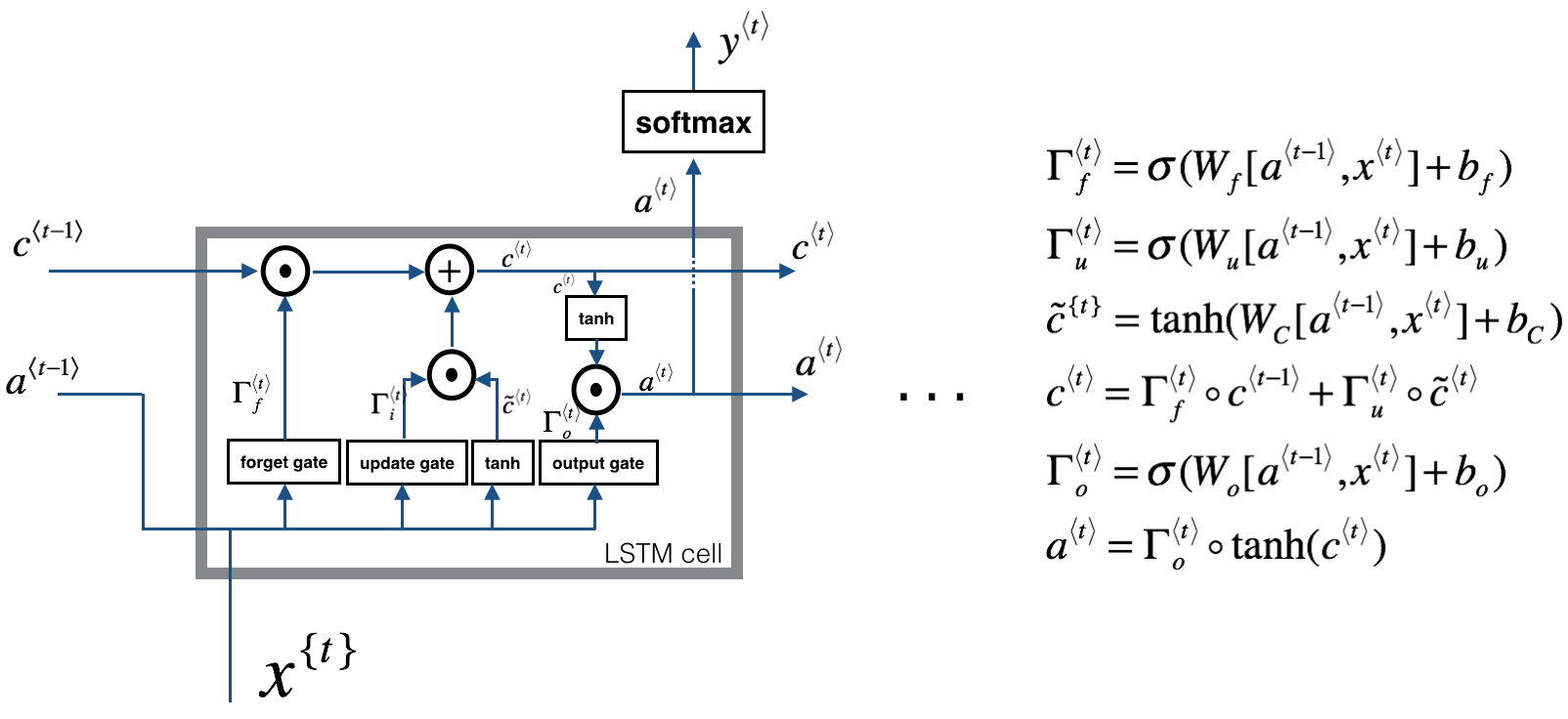
图中我们可以看见,LSTM Cell在每个时间步接收上个时间步的输入有两个,传给下一个时间步的输出也有两个。通常,我们将\(c(t)\)看作全局信息,\(a^t\)看作全局信息对下一个Cell影响的隐藏状态。
遗忘门、输入门(图中的update gate)和输出门分别都是一个激活函数为sigmoid的小型单层神经网络。由于sigmoid在\((0, 1)\)范围内的取值,有效的用于判断是保留还是“遗忘”信息(乘以接近1的值表示保留,乘以接近0的值表示遗忘),为我们提供了信息选择性传输的能力。这样,我们就很好理解门在LSTM是怎样工作的了:
- 遗忘门有两个输入:当前时间步的输入\(x^t\)以及上一层输出的隐藏状态\(a^{t-1}\),遗忘门通过这两个输入训练出一个门函数,注意这个门函数的输出是在\((0, 1)\)之间的,将其与上一层输出的全局信息\(c^{t-1}\)相乘,表示全局信息被选择部分遗忘。
- 对于输入门,我们那同样训练出一个门函数,与此同时,将接收到的\(a^{t-1}\)和\(x^t\)一起通过一个激活函数为tanh的小型神经网络,这一部分与传统RNN无异了,就是将上一时刻得到的信息与该时刻得到的信息进行整合。将整合信息与门函数的输出相乘,相当于同样选择有保留的提取新信息,并将其直接加在全局信息中去。
- 对于输出门,同样的训练出一个门函数,与此同时,将新的隐藏状态\(c^t\)通过一个简单的tanh函数(仅仅是激活函数)后与门函数的输出相乘,则可以得到该时刻全局信息对下一个Cell影响的隐藏状态\(a^t\)
这样看下来,是不是觉得LSTM已经十分"智能"了呢?但实际上,LSTM还是有其局限性:时序性的结构一方面使其很难具备高效的并行计算能力(当前状态的计算不仅要依赖当前的输入,还要依赖上一个状态的输出),另一方面使得整个LSTM模型(包括其他的RNN模型,如GRU)总体上更类似于一个马尔可夫决策过程,较难以提取全局信息。
关于GRU的结构我这里就不细讲了,在参考文献中有很多相关资料,大家想了解的可以去看看,简单来说,GRU可以看作一个LSTM的简化版本,其将\(a^t\)与\(c^t\)两个变量整合在一起,且讲遗忘门和输入门整合为更新门,输出门变更为重制门,大体思路没有太大变化。两者之间的性能往往差别不大,但GRU相对来说参数量更少。收敛速度更快。对于较少的数据集我建议使用GRU就已经足够了,对于较大的数据集,可以试试有较多参数量的LSTM有没有令人意外的效果。
卷积神经网络CNN
CNN是计算机视觉领域的重大突破,也是目前用于处理CV任务模型的核心。CNN同样适用于NLP任务中的特征提取,但其使用场景与RNN略有不同,这部分我会多写一点,因为关于CNN在NLP任务中的应用大家相对来说应该都没那么了解。
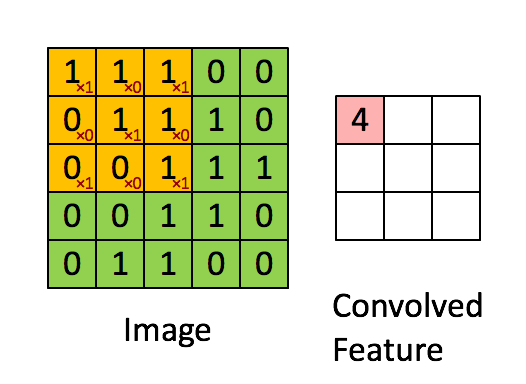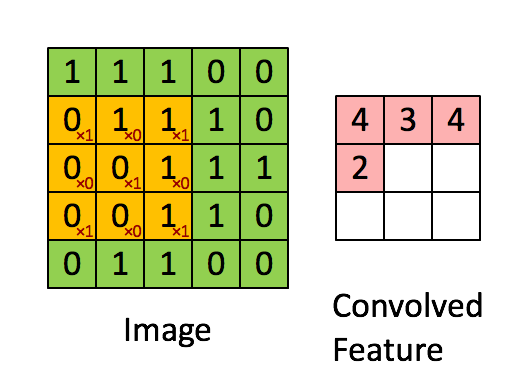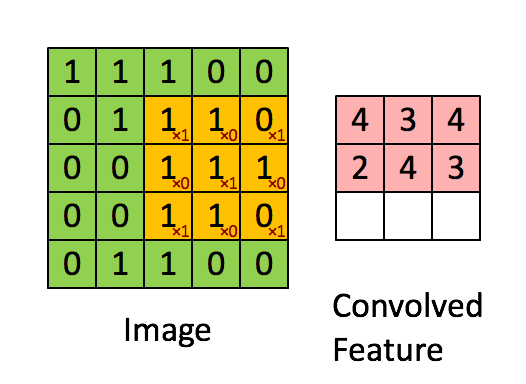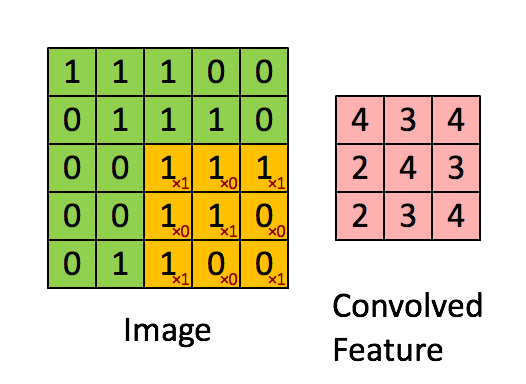
关于二维卷积核的运算如下图所示,我就不赘述了。
从数据结构上来看,CV任务中的输入数据为图像像素矩阵,其各个方向上的像素点之间的相关性基本上是等同的。而NLP任务中的输入数据通常为序列文本,假设句子长度为\(n\),我们词向量的维度为\(d\),我们的输入就成了一个\(n \times d\)的矩阵,显然,该矩阵的行列“像素”之间的相关性是不一样的,矩阵的同一行为一个词的向量表征,而不同行表示不同词。要让卷积网络能够正常的”读“我们的文本,我们在NLP中就需要使用一维卷积。Kim在2014年首次将CNN用于NLP中的文本分类任务,其提出的网络结构如下图所示:
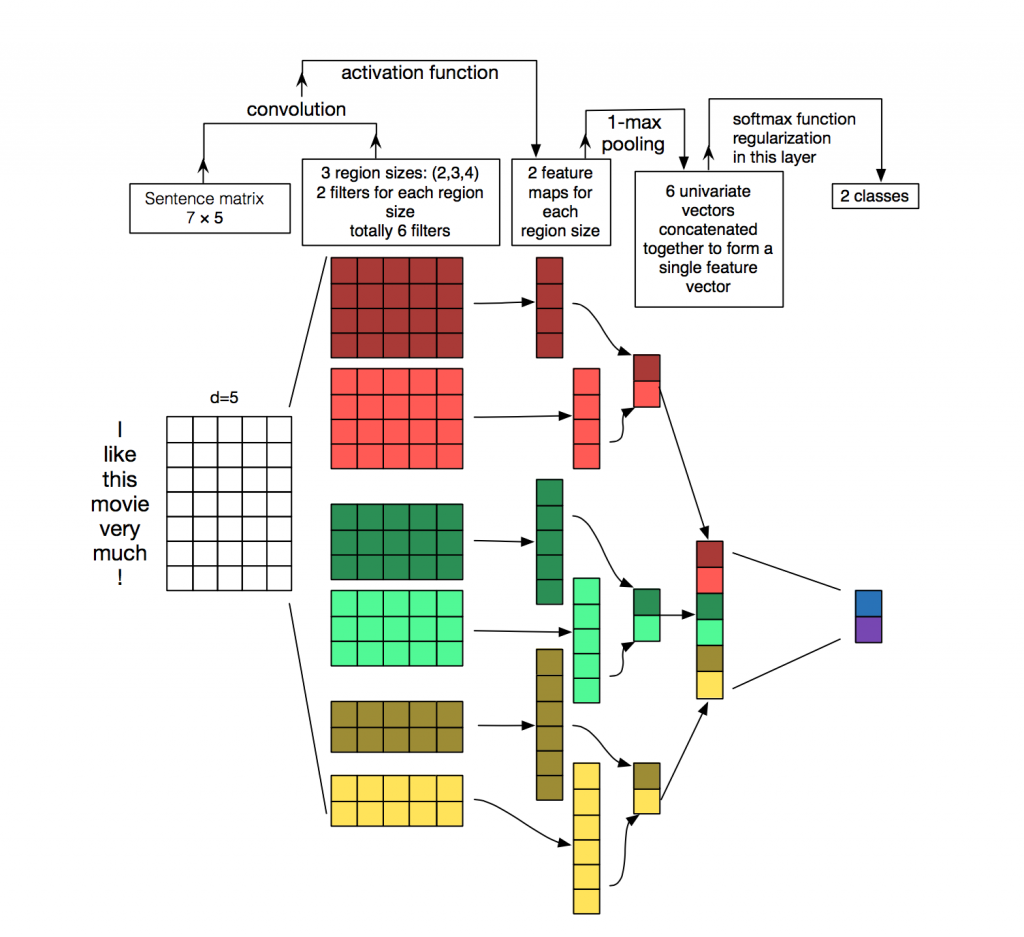
可以看见,一维卷积与二维卷积不同的是,每一个卷积核的宽度与词向量的维度\(d\)是相同的,以保证卷积核每次处理n个词的完整词向量,从上往下依次滑动卷积,这个过程中的输出就成了我们需要的特征向量。这就是CNN抽取特征的过程。在卷积层之后通常接上Max Pooling层(用于抽取最显著的特征),用于对输出的特征向量进行降维提取操作,最后再接一层全连接层实现文本分类。
虽然传统CNN经过简单的改变之后可以成功的应用于NLP任务,且效果还不错,但效果也仅仅是“不错“而已,很多任务还是处于完全被压制的情况。这表明传统的CNN在NLP领域中还是存在一些问题。
NLP界CNN模型的进化史
谈到CNN在NLP界的进化,我们首先来看看Kim版CNN存在哪些问题。
- Kim版CNN实际上类似于一个k-gram模型(k即卷积核的window,表示每次卷积的时候覆盖多少单词),对于一个单层的k-gram模型是难以捕捉到距离\(d \ge k\)的特征的;
- 卷积层输出的特征向量是包含了位置信息的(与卷积核的卷积顺序有关),在卷积层之后接Max Pooling层(仅仅保留提取特征中最大值)将导致特征信息中及其重要的位置编码信息丢失。

为了解决上述问题,研究者们采取了一系列方法对Kim版的CNN进行改进。
- 解决长远距离的信息提取的一个主要方法就是可以把网络做的更深一些,越深的卷积核将会有更大的感受野,从而捕获更远距离的特征。
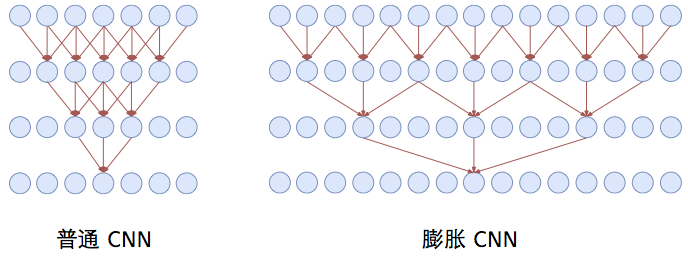
- 另外,我们也可以采用膨胀卷积(Dilated Convolution)的方式,也就是说我们的卷积窗口不再覆盖连续区域,而是跳着覆盖,这样,同样尺寸的卷积核我们就能提取到更远距离的特征了。当然这里的空洞卷积与CV中的还是不一样的,其仅仅在词间存在空洞,在词向量内部是不存在空洞的。在苏神的博客里对比了同样\(window=3\)的卷积核,膨胀卷积和普通卷积在三层网络时每个神经元的感受野大小,如下图所示,可以看见膨胀卷积的神经元感受野的范围是大大增加的。
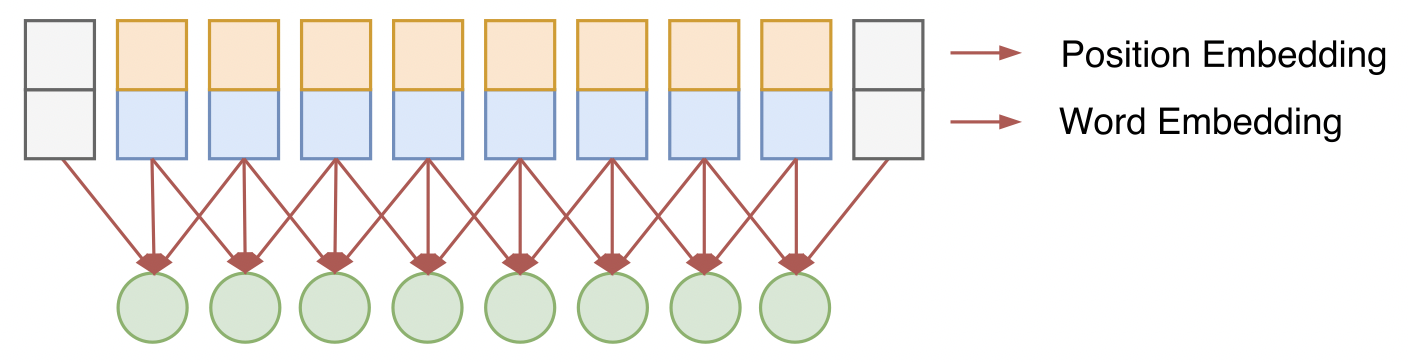
- 为了防止文本中的位置信息丢失,NLP领域里的CNN的发展趋势是抛弃Pooling层,靠全卷积层来叠加网络深度,并且在输入部分加入位置编码,人工将单词的位置特征加入到对应的词向量中。位置编码的方式可以采用《Attention is All You Need》中的方案,在下面介绍Transformer的时候再详细介绍
- 我们知道在CV领域中,网络做深之后将存在一系列问题,因此有了残差网络。在NLP中同样可以使用残差网络,解决梯度消失问题,解决梯度消失问题的本质是能够加速信息流动,使简单的信息传输可以有更简单的路径,从而使得网络做深的同时,能够保证良好的性能。
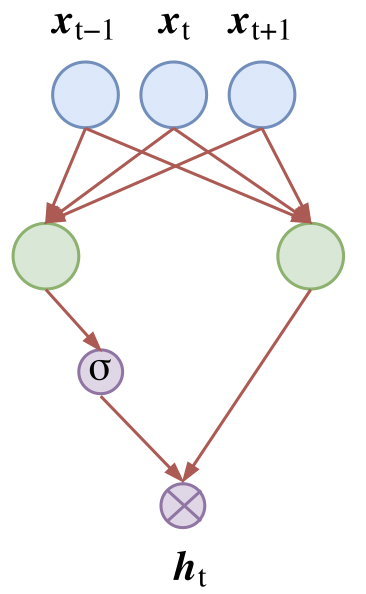
- 激活函数开始采用GLU(Gated Linear Unit),如下图所示,左右两个卷积核的尺寸完全一样,但是权值参数不共享,然后其中一个通过一个sigmoid函数,另一个不通过,将两者相乘。是不是感觉有点熟悉,这其实与LSTM中的门机制是相同的效果,该激活函数可以自行控制输出的特征的强弱大小。
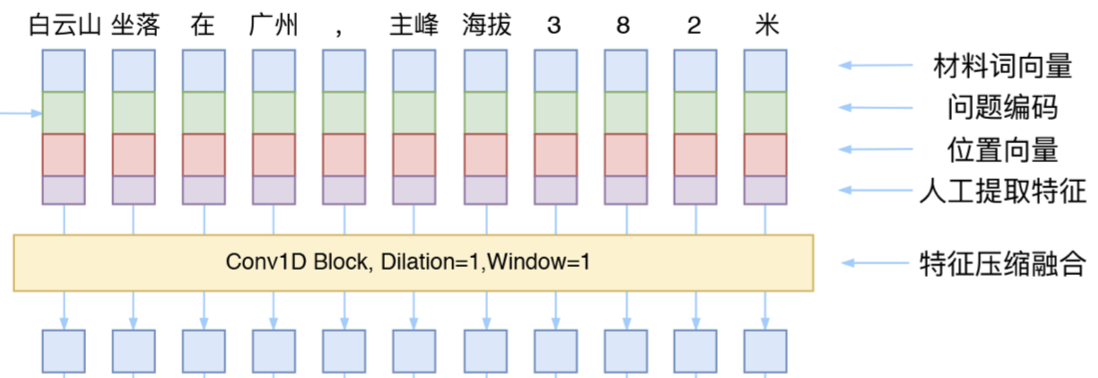
- 在苏神的博客中还学到另一个应用,就是可以用\(window=1\)的一维卷积对人工合成的词嵌入表征进行特征压缩,从而得到一个更有效的词向量表征方法。
在很多地方都看见CNN比较适用于文本分类的任务,事实上,从《Convolutional Sequence to Sequence Learning》、《Fast Reading Comprehension with ConvNets》等论文与实践报告来看,CNN已经发展成为一种成熟的特征提取器,并且,相比于RNN来说,CNN的窗口滑动完全没有先后关系,不同卷积核之前也没有相互影响,因此其具有非常高的并行自由度,这是其非常好的一个优点。
Transformer
Transformer是在论文《Attentnion is all you need》里首次被提出的。
Transformer详解推荐这篇文章:https://zhuanlan.zhihu.com/p/54356280
在介绍Transformer之前,我们先来看看Encoder-Decoder框架。现阶段的深度学习模型,我们通常都将其看作黑箱,而Encoder-Decoder框架则是将这个黑箱分为两个部分,一部分做编码,另一部分做解码。

在不同的NLP任务中,Encoder框架及Decoder框架均是由多个单独的特征提取器堆叠而成,比如说我们之前提到的LSTM结构或CNN结构。由最初的one-hot向量通过Encoder框架,我们将得到一个矩阵(或是一个向量),这就可以看作其对输入序列的一个编码。而对于Decoder结构就比较灵活饿了,我们可以根据任务的不同,对我们得到的“特征”矩阵或“特征”向量进行解码,输出为我们任务需要的输出结果。因此,对于不同的任务,如果我们堆叠的特征抽取器能够提取到更好的特征,那么理论上来说,在所有的NLP任务中我们都能够得到更好的表现。
在2018年谷歌推出BERT,刷新各项记录,引爆了整个NLP界,其取得成功的一个关键因素是新的特征提取结构:Transformer的强大作用。
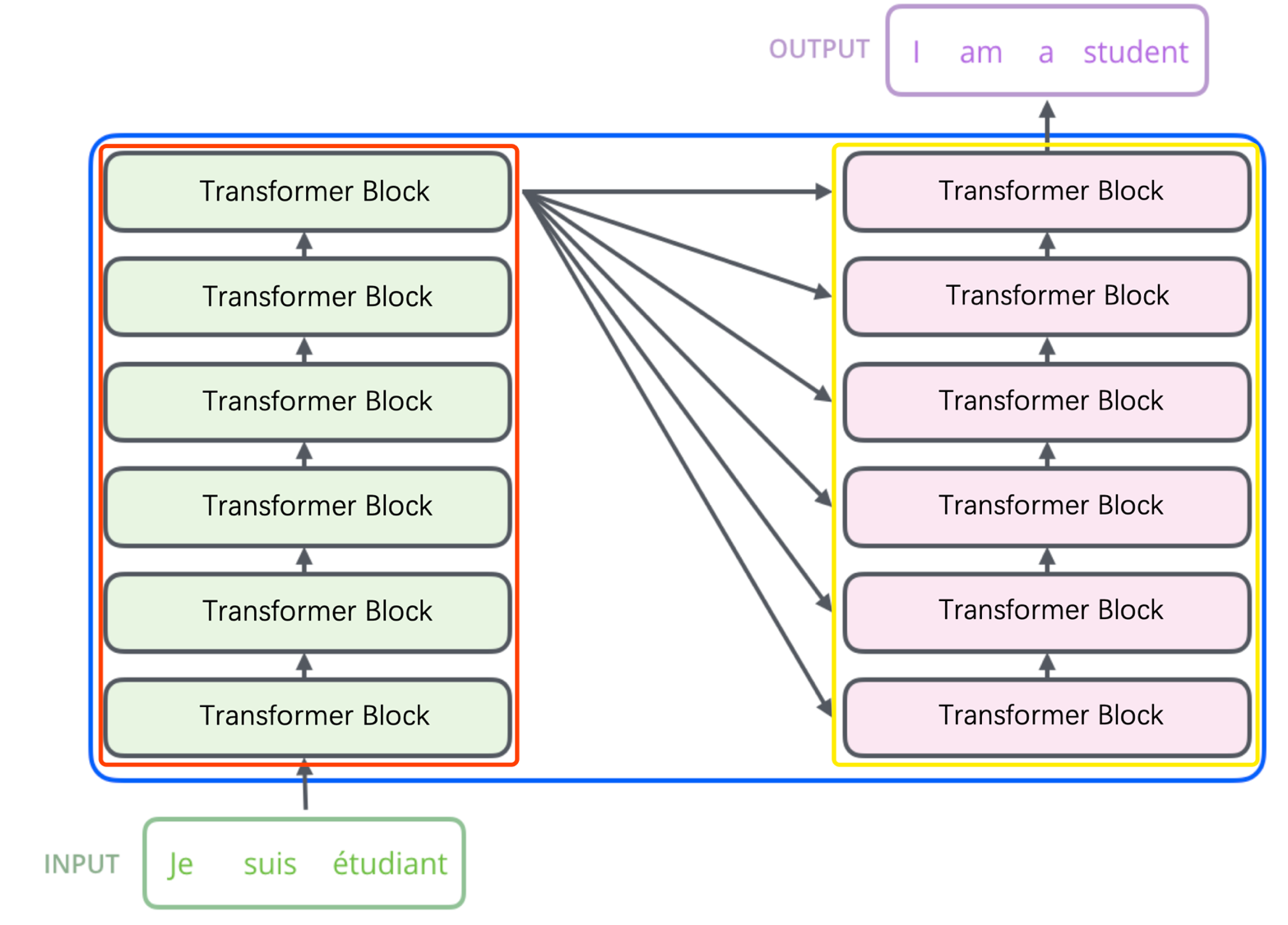
Transformer结构是在论文《Attention is All You Need》中提出的的模型,如上图所示。图中红框内为Encoder框架,黄框内为Decoder框架,其均是由多个Transformer Block堆叠而成的。这里的Transformer Block就代替了我们之前提到的LSTM和CNN结构作为了我们的特征提取器,也是其最关键的部分。更详细的示意图如下图所示。我们可以发现,编码器中的Transformer与解码器中的Transformer是有略微区别的,但我们通常使用的特征提取结构(包括Bert)主要是Encoder中的Transformer,那么我们这里主要理解一下Transformer在Encoder中是怎么工作的。
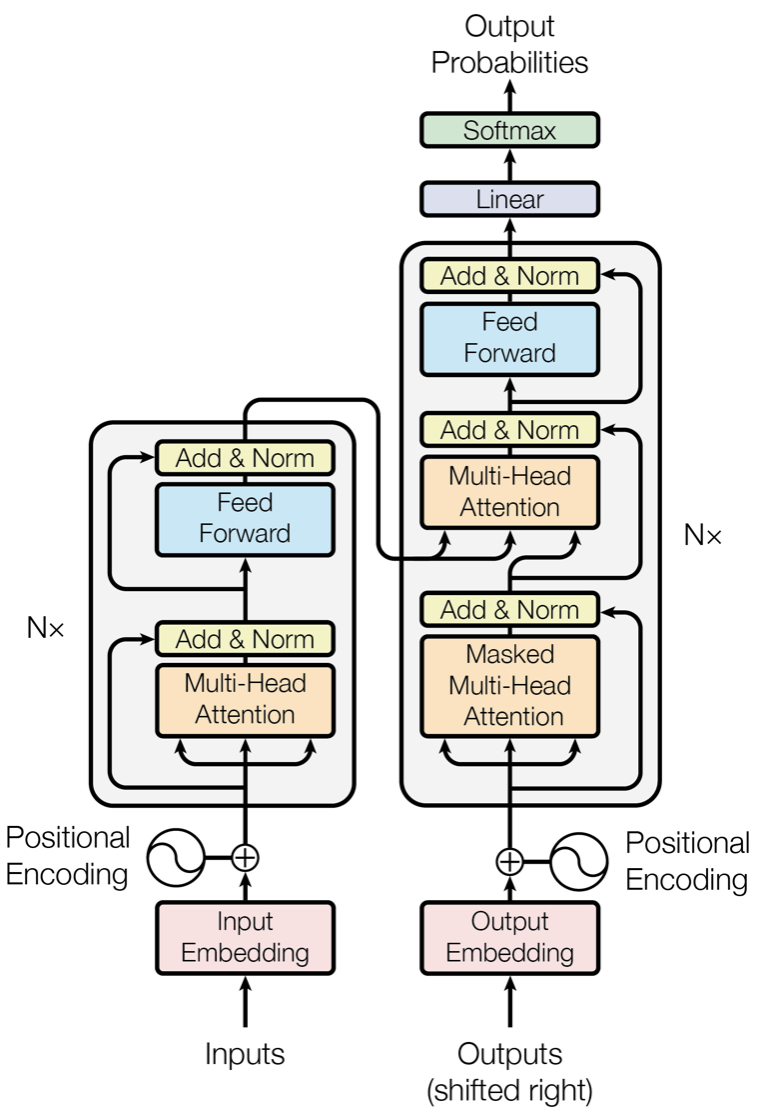
由上图可知,单个的Transformer Block主要由两部分组成:多头注意力机制(Multi-Head Attention)和前馈神经网络(Feed Forward)。
3.1 多头注意力机制(Multi-Head Attention)
Multi-Head Attention模块结构如下图所示:
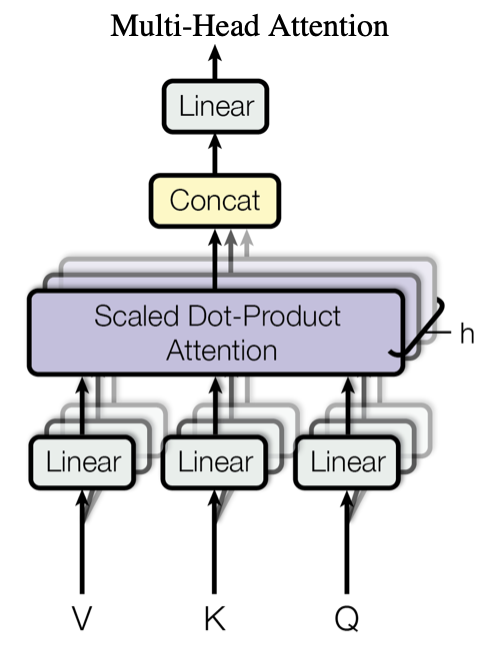
这里,我们就可以明白为什么这一部分被称为Multi-Head了,因为其本身就是由\(h\)个子模块Scaled Dot-Product Attention堆叠而成的,该模块也被称为Self-Attention模块。关于整个Multi-Head Attention,主要有一下几个关键点需要理解:
- Linear可以看作一个没有激活函数的全连接层,其各自维护了一个线性映射矩阵(神经网络的本质就是矩阵相乘)
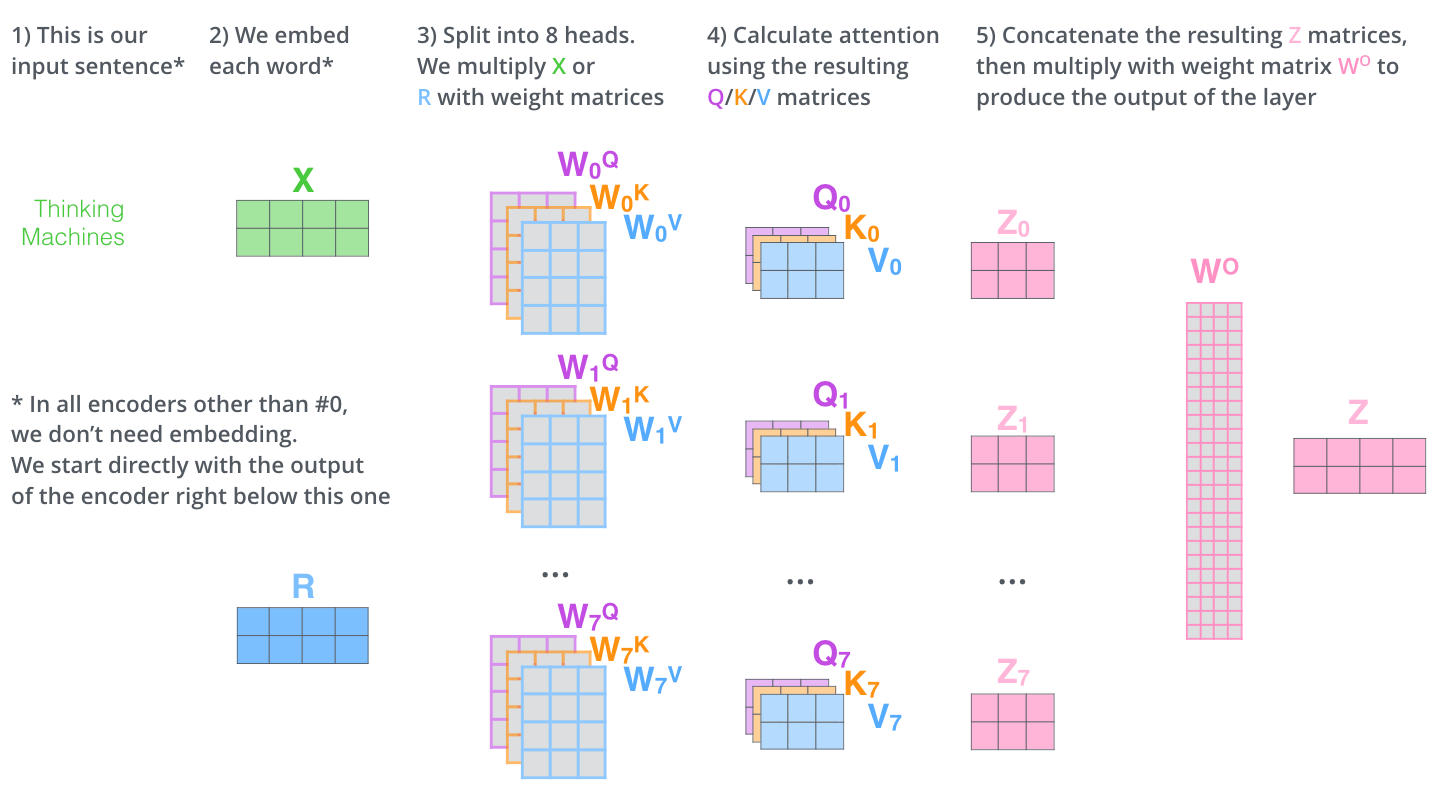
- 对于每一个Self-Attention,均有独立维护的三个线性映射矩阵\(W^V_i\)、\(W^K_i\)及\(W^Q_i\)(不同Self-Attention模块之间的权值不共享),通过将输入的矩阵\(X\)与三个映射矩阵相乘,得到Self-Attetnion的三个输入Queries、Keys和Values。这V, Q, K三个矩阵的输入\(X\)是完全一样的(均为输入句子的Input Embedding + Positional Encoding或是上一层Transformer的输出),这一点从整个的Encoder模型中也可以看出来。
- 在论文中,作者对于8个Self-Attention的输出,进行简单的拼接,并通过与一个映射矩阵\(W^O\)与其相乘(目的是对输出矩阵进行压缩),从而得到整个Multi-Head Attention的输出
在Multi-Head Attention中,最关键的部分就是Self-Attention部分了,这也是整个模型的核心配方,我们将其展开,如下图所示。
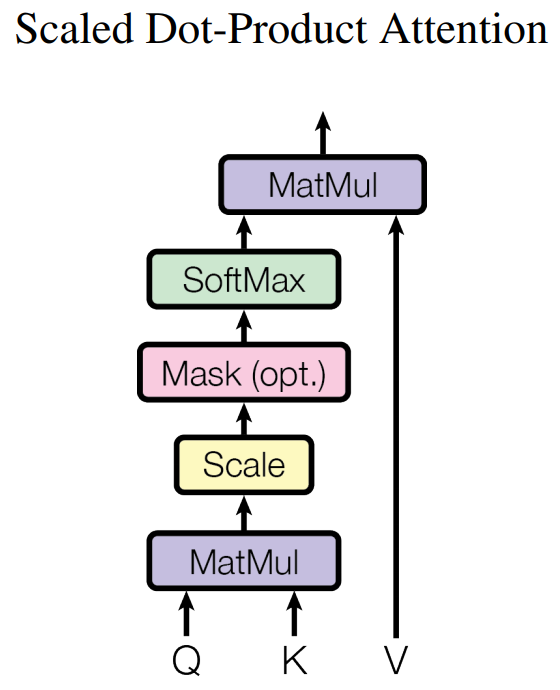
我们之前已经提到过,Self-Attention的输入仅仅是矩阵\(X\)的三个线性映射。那么Self-Attention内部的运算具有什么样的含义呢?我们从单个词编码的过程慢慢理解:
- 首先,我们对于输入单词向量\(X\)生成三个对应的向量: Query, Key 和 Value。注意这三个向量相比于向量\(X\)要小的多(论文中\(X\)的长度是512,三个向量的长度为64,这只是一种基于架构上的选择,因为论文中的Multi-Head Attention有8个Self-Attention模块,8个Self-Attention的输出要拼接,将其恢复成长度为512的向量),这一个部分是对每个单词独立操作的
- 用Queries和Keys的点积计算所有单词相对于当前词(图中为Thinking)的得分Score,该分数决定在编码单词“Thinking”时其他单词给予了多少贡献
- 将Score除以向量维度(64)的平方根(保证Score在一个较小的范围,否则softmax的结果非零即1了),再对其进行Softmax(将所有单词的分数进行归一化,使得所有单词为正值且和为1)。这样对于每个单词都会获得所有单词对该单词编码的贡献分数,当然当前单词将获得最大分数,但也将会关注其他单词的贡献大小
- 对于得到的Softmax分数,我们将其乘以每一个对应的Value向量(弱化了softmax分数较低单词的影响,有点类似于之前的sigmoid门函数的思想)
- 对所得的所有加权向量求和,即得到Self-Attention对于当前词”Thinking“的输出
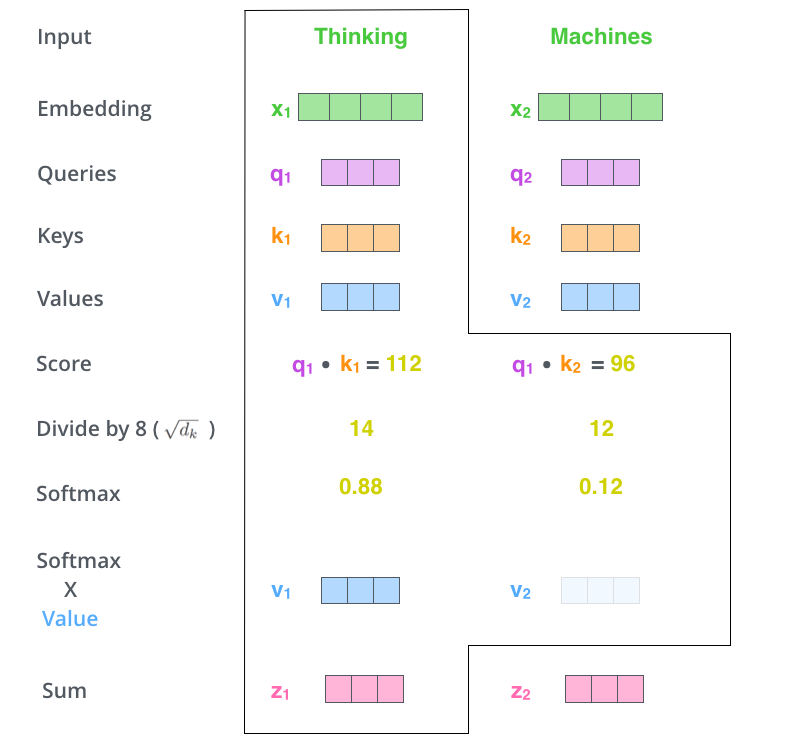
其实仔细思考一下就可以发现,Self-Attention与CNN是十分相似的。CNN通过简单的卷积运算提取特征,虽然有Dilated Convolution以及增加深度等方式来增大感受野,但是其本质上是一个n-gram模型。而在Self-Attention中,\(W^Q\), \(W^K\), \(W^V\)不也能看作三个卷积核吗,但是其通过一种更加巧妙的方式将卷积运算的结果进行整合,实现了直观上所谓的”注意力“,从而使得每一个词的编码结果均是句子中所有词的共同作用结果,其本质上是一个超大的词袋模型(包括句子中所有的词)。显然,上述过程可以用以下的矩阵形式进行并行计算:
\[Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V\]
其中,Q, V, K分别表示输入句子的Queries, Keys, Values矩阵,矩阵的每一行为每一个词对应的向量Query, Key, Value向量,\(d_k\)表示向量长度。因此,Transformer同样也具有十分高效的并行计算能力。
我们再回到Multi-Head Attention,我们将独立维护的8个Self-Attention的输出进行简单的拼接,通过一个先行映射层,就得到了单个多头注意力的输出。其整个过程可以总结为下面这个示意图:
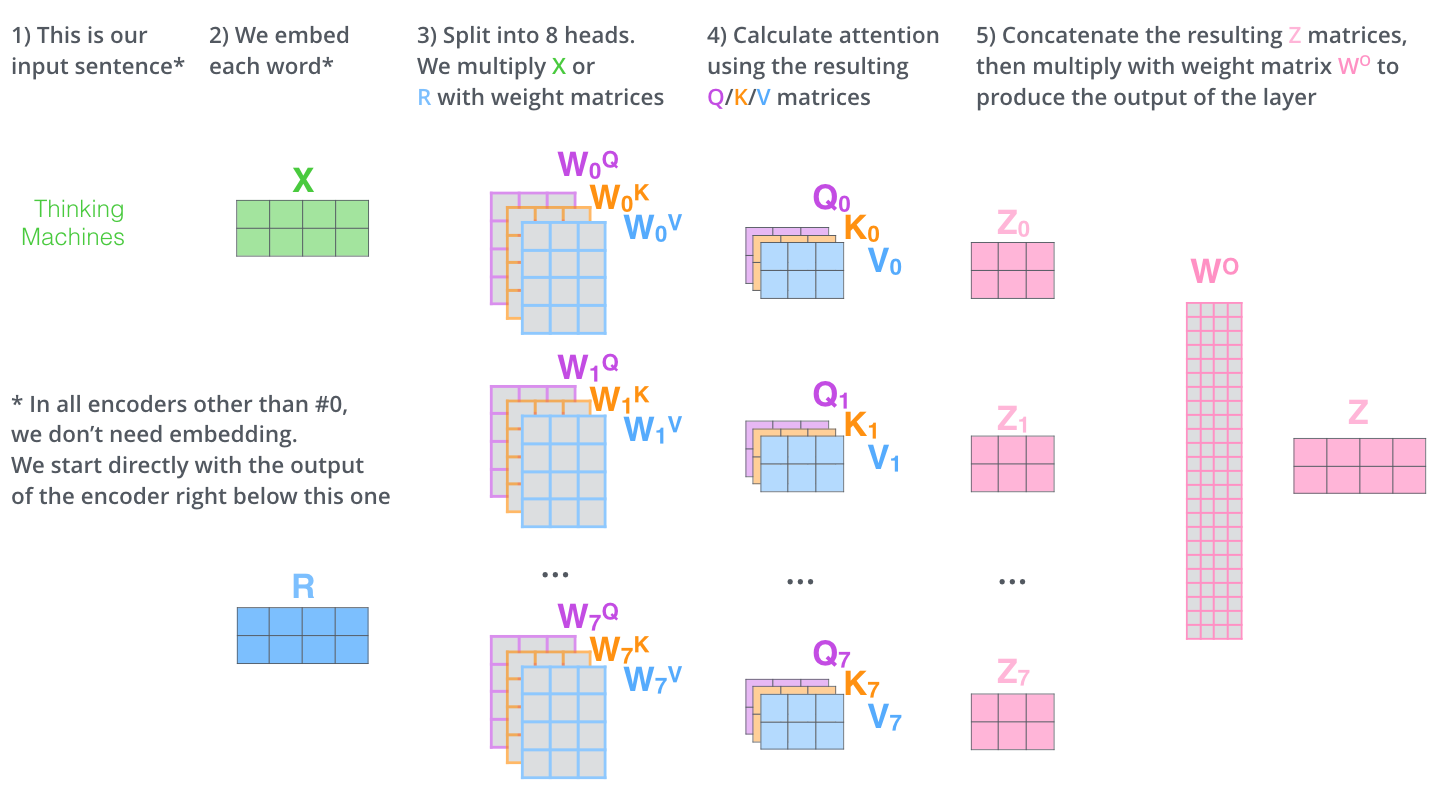
位置编码(Positional Encoding)
我们之前提到过,由于RNN的时序性结构,所以天然就具备位置编码信息。CNN本身其实也能提取一定位置信息,但多层叠加之后,位置信息将减弱,位置编码可以看作是一种辅助手段。Transformer的每一个词的编码过程使得其基本不具备任何的位置信息(将词序打乱之后并不会改变Self-Attention的计算结果),因此位置向量在这里是必须的,使其能够更好的表达词与词之间的距离。构造位置编码的公式如下所示:
\[\begin{cases}
PE_{2i}(p)=sin(p/10000^{2i/d_{pos}}) \\
PE_{2i+1}(p)=cos(p/10000^{2i/d_{pos}})
\end{cases}\]
如果词嵌入的长度\(d_{pos}\),则我们需要构造一个长度同样为\(d_{pos}\)的位置编码向量\(PE\)。其中\(p\)表示词的位置,\(PE_i(p)\)表示第p个词位置向量中的第i个元素的值,然后将词向量与位置向量直接相加。该位置编码不仅仅包含了绝对位置信息,由\(sin(\alpha + \beta) = sin \alpha cos \beta + cos \alpha sin \beta\)以及\(cos(\alpha + \beta) = cos \alpha cos \beta - sin \alpha sin \beta\),这意味着我们可以\(p+k\)的位置向量可表示为位置\(p\)位置向量的线性变换,使得相对位置信息也得到了表达。Transformer论文中提到过他们用该方式得到的位置编码向量与训练得到的位置编码向量效果是十分接近的。
残差模块(Residual Block)
我们之前说到Self-Attention与CNN的相似性。这里的残差运算同样是借鉴了CNN中的思想,其原理基本是一样的,我就不赘述了。在残差连接之后,还需要进行层归一化操作,其具体过程与Layer Normalization一致。
Transformer小结
到这里,整个Transformer的结构基本讲述完毕了。关于其相与RNN和CNN的性能比较,张俊林老师的文章里有详细的数据说明,我仅附上简单的总结:
- 从语义特征提取能力:Transformer显著超过RNN和CNN,RNN和CNN两者能力差不太多。
- 长距离特征捕获能力:CNN极为显著地弱于RNN和Transformer,Transformer微弱优于RNN模型,但在比较远的距离上(主语谓语距离大于13),RNN微弱优于Transformer,所以综合看,可以认为Transformer和RNN在这方面能力差不太多,而CNN则显著弱于前两者。这部分我们之前也提到过,CNN提取长距离特征的能力收到其卷积核感受野的限制,实验证明,增大卷积核的尺寸,增加网络深度,可以增加CNN的长距离特征捕获能力。而对于Transformer来说,其长距离特征捕获能力主要受到Multi-Head数量的影响,Multi-Head的数量越多,Transformer的长距离特征捕获能力越强
- 任务综合特征抽取能力:通常,机器翻译任务是对NLP各项处理能力综合要求最高的任务之一,要想获得高质量的翻译结果,对于两种语言的词法,句法,语义,上下文处理能力,长距离特征捕获等方面的性能要求都是很高的。从综合特征抽取能力角度衡量,Transformer显著强于RNN和CNN,而RNN和CNN的表现差不太多。
- 并行计算能力:对于并行计算能力,上文很多地方都提到过,并行计算是RNN的严重缺陷,而Transformer和CNN差不多。
由于平常科研任务也比较重,代码暂时没有时间上传,等发布序列标注以及文本分类等文章的时候代码会同步上传到Github,RNN/CNN/Transformer的代码也会包含在其中。
参考资料
https://zhuanlan.zhihu.com/p/54743941
http://www.ai-start.com/dl2017/html/lesson5-week1.html#header-n194
https://zhuanlan.zhihu.com/p/46327831
https://zhuanlan.zhihu.com/p/55386469
https://kexue.fm/archives/5409
https://zhuanlan.zhihu.com/p/54356280
http://jalammar.github.io/illustrated-transformer/
https://kexue.fm/archives/4765
三大特征提取器(RNN/CNN/Transformer)的更多相关文章
- seq2seq模型详解及对比(CNN,RNN,Transformer)
一,概述 在自然语言生成的任务中,大部分是基于seq2seq模型实现的(除此之外,还有语言模型,GAN等也能做文本生成),例如生成式对话,机器翻译,文本摘要等等,seq2seq模型是由encoder, ...
- 机器学习之路:python 字典特征提取器 DictVectorizer
python3 学习使用api 将字典类型数据结构的样本,抽取特征,转化成向量形式 源码git: https://github.com/linyi0604/MachineLearning 代码: fr ...
- Hadoop 三大调度器源码分析及编写自己的调度器
如要转载,请注上作者和出处. 由于能力有限,如有错误,请大家指正. 须知: 我们下载的是hadoop-2.7.3-src 源码. 这个版本默认调度器是Capacity调度器. 在2.0.2-alph ...
- FMXUI中的三大杀器:TView、TLinearLayout、TRelativeLayout
好了,今天我们来介绍下FMXUI中的三大杀器:TView.TLinearLayout.TRelativeLayout. [名词定义] 非布局组件: 组件名不是以Layout结尾的组件,Delphi自带 ...
- 放弃幻想,全面拥抱Transformer:自然语言三大特征抽取器CNN/RNN/Transformer比较
参考: https://zhuanlan.zhihu.com/p/54743941
- Deep Learning(深度学习)整理,RNN,CNN,BP
申明:本文非笔者原创,原文转载自:http://www.sigvc.org/bbs/thread-2187-1-3.html 4.2.初级(浅层)特征表示 既然像素级的特征表示方法没有作用,那怎 ...
- (五) Keras Adam优化器以及CNN应用于手写识别
视频学习来源 https://www.bilibili.com/video/av40787141?from=search&seid=17003307842787199553 笔记 Adam,常 ...
- rnn,cnn
http://nikhilbuduma.com/2015/01/11/a-deep-dive-into-recurrent-neural-networks/ 按照这里的介绍,目前比较火的cnn是fee ...
- Shader开发之三大着色器
固定功能管线着色器Fixed Function Shaders 固定功能管线着色器的关键代码一般都在Pass的材质设置Material{}和纹理设置SetTexture{}部分. Shader &qu ...
随机推荐
- unity编辑器扩展_05(删除游戏对象并具有撤回功能)
代码: [MenuItem("Tools/Delete",false,1)] static void Delete() { GameObject[] go ...
- ES5新增数组方法测试和字符串常见API测试
首先是ES5新增数组方法测试: <!DOCTYPE html><html lang="en"><head> <meta charset=& ...
- 【数据结构】10.java源码关于LinkedHashMap
目录 1.LinkedHashMap的内部结构 2.LinkedHashMap构造函数 3.元素新增策略 4.元素删除 5.元素修改和查找 6.特殊操作 7.扩容 8.总结 1.LinkedHashM ...
- xcode删除一个项目
退出xcode. 在Finder中删除项目文件夹.
- ACM-ICPC 2018 徐州赛区(网络赛)
目录 A. Hard to prepare B.BE, GE or NE F.Features Track G.Trace H.Ryuji doesn't want to study I.Charac ...
- 杭电多校第十场 hdu6432 Cyclic 打表找规律
Cyclic Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 524288/524288 K (Java/Others)Total Su ...
- codeforces 821 D. Okabe and City(最短路)
题目链接:http://codeforces.com/contest/821/problem/D 题意:n*m地图,有k个位置是点亮的,有4个移动方向,每次可以移动到相邻的点亮位置,每次站在初始被点亮 ...
- yzoj P2350 逃离洞穴 题解
题意 跑两边spfa的水题,注意判断有人才取最大值 代码 #include<bits/stdc++.h> using namespace std; inline int read(){ i ...
- Requests库整理
一.Requests库的安装 win平台下,直接在命令行使用 pip install requests 即可进行安装 成功后测试如下 >>> import requests > ...
- Spring Boot 多环境如何配置
Spring Boot 开发环境.测试环境.预生产环境.生产环境多环境配置 通常一个公司的应程序可能在开发环境(dev).测试环境(test).生产环境(prod)中运行.那么是不是需要拷贝不同的安装 ...