pytorch1.0进行Optimizer 优化器对比
pytorch1.0进行Optimizer 优化器对比
import torch
import torch.utils.data as Data # Torch 中提供了一种帮助整理数据结构的工具, 叫做 DataLoader, 能用它来包装自己的数据, 进行批训练.
import torch.nn.functional as F # 包含激励函数
import matplotlib.pyplot as plt LR = 0.01 # 学习率
BATCH_SIZE = 32
EPOCH = 12 # 伪数据
# fake dataset
x = torch.unsqueeze(torch.linspace(-1, 1, 1000), dim=1)
y = x.pow(2) + 0.1*torch.normal(torch.zeros(*x.size())) # plot dataset
plt.scatter(x.numpy(), y.numpy())
plt.show() # DataLoader 是 torch 用来包装开发者自己的数据的工具.
# 将自己的 (numpy array 或其他) 数据形式装换成 Tensor, 然后再放进这个包装器中.
# 使用 DataLoader 的好处就是他们帮你有效地迭代数据 # 先转换成 torch 能识别的 Dataset
# put dateset into torch dataset
torch_dataset = Data.TensorDataset(x, y)
# 把 dataset 放入 DataLoader
loader = Data.DataLoader(dataset=torch_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2,) # 随机打乱数据 (打乱比较好) # 每个优化器优化一个神经网络 # 默认的 network 形式
# default network
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(1, 20) # hidden layer
self.predict = torch.nn.Linear(20, 1) # output layer def forward(self, x):
x = F.relu(self.hidden(x)) # activation function for hidden layer
x = self.predict(x) # linear output
return x # 创建不同的优化器, 用来训练不同的网络. 并创建一个 loss_func 用来计算误差.
if __name__ == '__main__':
# different nets
net_SGD = Net()
net_Momentum = Net()
net_RMSprop = Net()
net_Adam = Net()
nets = [net_SGD, net_Momentum, net_RMSprop, net_Adam] # different optimizers
opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8)
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
optimizers = [opt_SGD, opt_Momentum, opt_RMSprop, opt_Adam] loss_func = torch.nn.MSELoss()
losses_his = [[], [], [], []] # record loss # 训练/出图
# training
for epoch in range(EPOCH):
print('Epoch: ', epoch)
for step, (b_x, b_y) in enumerate(loader): # for each training step
# 对每个优化器, 优化属于他的神经网络
for net, opt, l_his in zip(nets, optimizers, losses_his):
output = net(b_x) # get output for every net
loss = loss_func(output, b_y) # compute loss for every net
opt.zero_grad() # clear gradients for next train
loss.backward() # backpropagation, compute gradients
opt.step() # apply gradients
l_his.append(loss.data.numpy()) # loss recoder labels = ['SGD', 'Momentum', 'RMSprop', 'Adam']
for i, l_his in enumerate(losses_his):
plt.plot(l_his, label=labels[i])
plt.legend(loc='best')
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.ylim((0, 0.2))
plt.show()
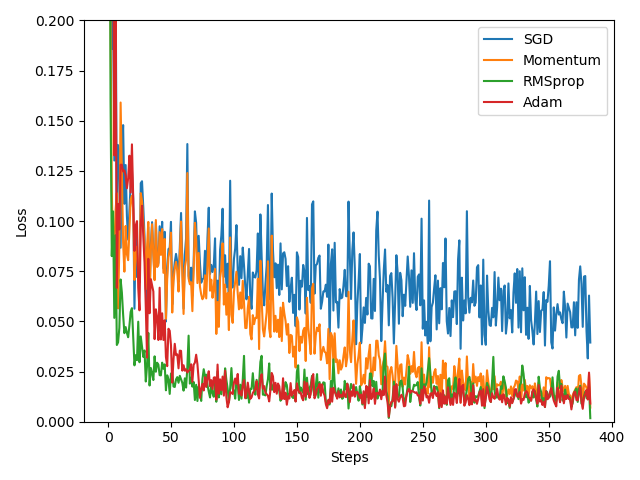
# SGD是最普通的优化器, 也可以说没有加速效果, 而Momentum是SGD的改良版,它加入了动量原则.后面的RMSprop又是Momentum的升级版.
# 而Adam又是RMSprop的升级版.Adam的效果似乎比RMSprop要差一点.所以说并不是越先进的优化器, 结果越佳.
# 在自己的试验中可以尝试不同的优化器, 找到那个最适合你数据网络的优化器.
pytorch1.0进行Optimizer 优化器对比的更多相关文章
- PLSQL_性能优化系列04_Oracle Optimizer优化器
2014-09-25 Created By BaoXinjian
- pytorch 7 optimizer 优化器 加速训练
import torch import torch.utils.data as Data import torch.nn.functional as F import matplotlib.pyplo ...
- 莫烦pytorch学习笔记(七)——Optimizer优化器
各种优化器的比较 莫烦的对各种优化通俗理解的视频 import torch import torch.utils.data as Data import torch.nn.functional as ...
- 各种优化器对比--BGD/SGD/MBGD/MSGD/NAG/Adagrad/Adam
指数加权平均 (exponentially weighted averges) 先说一下指数加权平均, 公式如下: \[v_{t}=\beta v_{t-1}+(1-\beta) \theta_{t} ...
- Tensorflow 2.0 深度学习实战 —— 详细介绍损失函数、优化器、激活函数、多层感知机的实现原理
前言 AI 人工智能包含了机器学习与深度学习,在前几篇文章曾经介绍过机器学习的基础知识,包括了监督学习和无监督学习,有兴趣的朋友可以阅读< Python 机器学习实战 >.而深度学习开始只 ...
- [PyTorch 学习笔记] 4.3 优化器
本章代码: https://github.com/zhangxiann/PyTorch_Practice/blob/master/lesson4/optimizer_methods.py https: ...
- Oracle SQL优化器简介
目录 一.Oracle的优化器 1.1 优化器简介 1.2 SQL执行过程 二.优化器优化方式 2.1 优化器的优化方式 2.2 基于规则的优化器 2.3 基于成本的优化器 三.优化器优化模式 3.1 ...
- 【MySQL】MySQL/MariaDB的优化器对in子查询的处理
参考:http://codingstandards.iteye.com/blog/1344833 上面参考文章中<高性能MySQL>第四章第四节在第三版中我对应章节是第六章第五节 最近分析 ...
- Pytorch1.0深度学习:损失函数、优化器、常见激活函数、批归一化详解
不用相当的独立功夫,不论在哪个严重的问题上都不能找出真理:谁怕用功夫,谁就无法找到真理. —— 列宁 本文主要介绍损失函数.优化器.反向传播.链式求导法则.激活函数.批归一化. 1 经典损失函数 1. ...
随机推荐
- Maven+SSM整合ehcache
- Luogu5348 密码解锁
题面 题解 记\(N = \dfrac nm\) 这道题目就是要求\(a_m = \sum_{i=1}^N \mu(i)\mu(im)\) 因为\(\mu(ij) = \mu(i)\mu(j)[\gc ...
- RabbitMQ入门学习系列(七) 远程调用RPC
快速阅读 生产者和消费者启动以后,都有一个接收事件,消费者是接收事件是处理调用方法以后等待生产者的返回,生产者的接收事件是处理接收生产者发送的消息,进行处理.消费者发送的时候要在回调队列中加入一个标识 ...
- python TypeError: unsupported operand type(s) for +: 'geoprocessing value object' and 'str'
TypeError: unsupported operand type(s) for +: 'geoprocessing value object' and 'str' if self.params[ ...
- vs2017 编译linux项目
官方文档1: https://blogs.msdn.microsoft.com/vcblog/2017/04/11/linux-development-with-c-in-visual-studio/ ...
- Unity制作王者荣耀商业级手游
<王者荣耀>这种现象级手机游戏是如何制作出来的呢?本文以<王者荣耀>MOBO类型的多人在线战术竞技游戏为入口,覆盖Unity游戏制作开发前端与Node.js服务器端的开发必备知 ...
- vue cli 静态资源导入 路径
1.public文件夹 使用绝对路径引入. 2.assets文件夹 使用相对路径引入. https://cli.vuejs.org/zh/guide/html-and-static-assets.ht ...
- CMU Database Systems - Storage and BufferPool
Database Storage 存储分为volatile和non-volatile,越快的越贵越小 那么所以要解决的第一个问题就是,如果尽量在有限的成本下,让读写更快些 意思就是,尽量读写volat ...
- 项目启动时警告 Establishing SSL connection without server's identity verification is not recommended
项目启动时控制台提示警告: Tue May 14 23:16:10 CST 2019 WARN: Establishing SSL connection without server's identi ...
- JDBC DataSource
What is DataSource? 作为 DriverManager 设施的替代项,DataSource 对象是获取连接的首选方法.实现DataSource 接口的对象通常在基于 Java(TM) ...