【面试突击】- sql语句的优化分析
开门见山,问题所在
原文地址:http://www.cnblogs.com/knowledgesea/p/3686105.html
sql语句性能达不到你的要求,执行效率让你忍无可忍,一般会时下面几种情况。
- 网速不给力,不稳定。
- 服务器内存不够,或者SQL 被分配的内存不够。
- sql语句设计不合理
- 没有相应的索引,索引不合理
- 没有有效的索引视图
- 表数据过大没有有效的分区设计
- 数据库设计太2,存在大量的数据冗余
- 索引列上缺少相应的统计信息,或者统计信息过期
- ....
那么我们如何给找出来导致性能慢的的原因呢?
- 首先你要知道是否跟sql语句有关,确保不是机器开不开机,服务器硬件配置太差,没网你说p啊
- 接着你使用我上一篇文章中提到的2柯南sql性能检测工具--sql server profiler,分析出sql慢的相关语句,就是执行时间过长,占用系统资源,cpu过多的
- 然后是这篇文章要说的,sql优化方法跟技巧,避免一些不合理的sql语句,取暂优sql
- 再然后判断是否使用啦,合理的统计信息。sql server中可以自动统计表中的数据分布信息,定时根据数据情况,更新统计信息,是很有必要的
- 确认表中使用啦合理的索引,这个索引我前面博客中也有提过,不过那篇博客之后,还要进一步对索引写篇文章
- 数据太多的表,要分区,缩小查找范围
分析比较执行时间计划读取情况
- select * from dbo.Product
执行上面语句一般情况下只给你返回结果和执行行数,那么你怎么分析呢,怎么知道你优化之后跟没有优化的区别呢。
下面给你说几种方法。
1.查看执行时间和cpu占用时间
- set statistics time on
- select * from dbo.Product
- set statistics time off
打开你查询之后的消息里面就能看到啦。

2.查看查询对I/0的操作情况
- set statistics io on
- select * from dbo.Product
- set statistics io off
执行之后


扫描计数:索引或表扫描次数
逻辑读取:数据缓存中读取的页数
物理读取:从磁盘中读取的页数
预读:查询过程中,从磁盘放入缓存的页数
lob逻辑读取:从数据缓存中读取,image,text,ntext或大型数据的页数
lob物理读取:从磁盘中读取,image,text,ntext或大型数据的页数
lob预读:查询过程中,从磁盘放入缓存的image,text,ntext或大型数据的页数
如果物理读取次数和预读次说比较多,可以使用索引进行优化。
如果你不想使用sql语句命令来查看这些内容,方法也是有的,哥教你更简单的。
查询--->>查询选项--->>高级
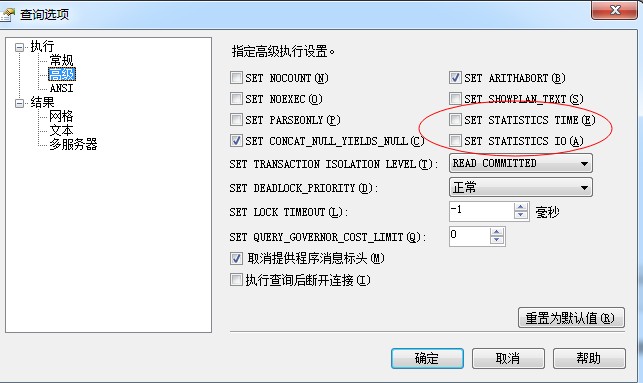

被红圈套上的2个选上,去掉sql语句中的set statistics io/time on/off 试试效果。哦也,你成功啦。。
3.查看执行计划,执行计划详解
选中查询语句,点击
 然后看消息里面,会出现下面的图例
然后看消息里面,会出现下面的图例
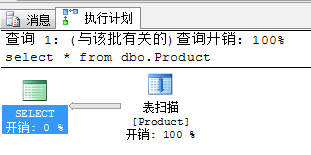

首先我这个例子的语句太过简单,你整个复杂的,包涵啊。
分析:鼠 标放在图标上会显示此步骤执行的详细内容,每个表下面都显示一个开销百分比,分析站百分比多的的一块,可以根据重新设计数据结构,或这重写sql语句,来 对此进行优化。如果存在扫描表,或者扫描聚集索引,这表示在当前查询中你的索引是不合适的,是没有起到作用的,那么你就要修改完善优化你的索引,具体怎么 做,你可以根据我上一篇文章中的sql优化利器--数据库引擎优化顾问对索引进行分析优化。
select查询艺术
1.保证不查询多余的列与行。
- 尽量避免select * 的存在,使用具体的列代替*,避免多余的列
- 使用where限定具体要查询的数据,避免多余的行
- 使用top,distinct关键字减少多余重复的行
2.慎用distinct关键字
distinct在查询一个字段或者很少字段的情况下使用,会避免重复数据的出现,给查询带来优化效果。
但是查询字段很多的情况下使用,则会大大降低查询效率。
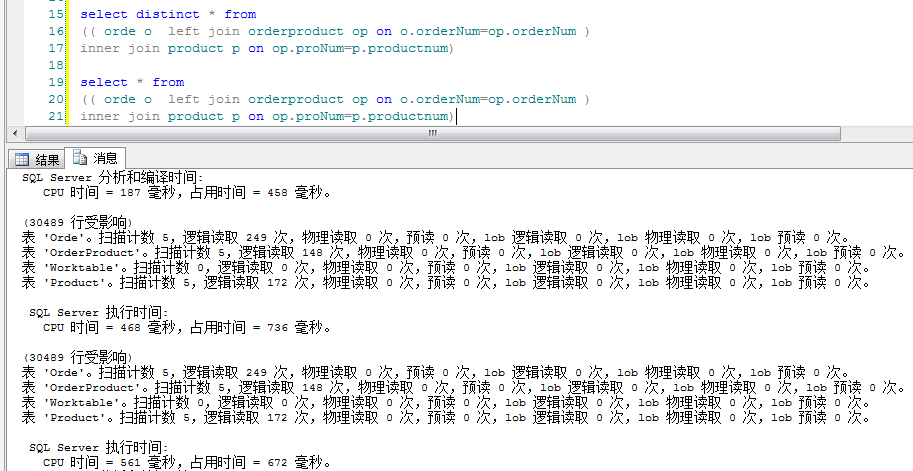

由这个图,分析下:
很明显带distinct的语句cpu时间和占用时间都高于不带distinct的语句。原因是当查询很多字段时,如果使用distinct,数据库引擎就会对数据进行比较,过滤掉重复数据,然而这个比较,过滤的过程则会毫不客气的占用系统资源,cpu时间。
3.慎用union关键字
此关键字主要功能是把各个查询语句的结果集合并到一个结果集中返回给你。用法
- <select 语句1>
- union
- <select 语句2>
- union
- <select 语句3>
- ...
满足union的语句必须满足:1.列数相同。 2.对应列数的数据类型要保持兼容。
执行过程:
依次执行select语句-->>合并结果集--->>对结果集进行排序,过滤重复记录。
- select * from
- (( orde o left join orderproduct op on o.orderNum=op.orderNum )
- inner join product p on op.proNum=p.productnum) where p.id<10000
- union
- select * from
- (( orde o left join orderproduct op on o.orderNum=op.orderNum )
- inner join product p on op.proNum=p.productnum) where p.id<20000 and p.id>=10000
- union
- select * from
- (( orde o left join orderproduct op on o.orderNum=op.orderNum )
- inner join product p on op.proNum=p.productnum) where p.id>20000 ---这里可以写p.id>100 结果一样,因为他筛选过啦
- ----------------------------------对比上下两个语句-----------------------------------------
- select * from
- (( orde o left join orderproduct op on o.orderNum=op.orderNum )
- inner join product p on op.proNum=p.productnum)


由此可见效率确实低,所以不是在必要情况下避 免使用。其实有他执行的第三部:对结果集进行排序,过滤重复记录。就能看出不是什么好鸟。然而不对结果集排序过滤,显然效率是比union高的,那么不排 序过滤的关键字有吗?答,有,他是union all,使用union all能对union进行一定的优化。。
4.判断表中是否存在数据
- select count(*) from product
- select top(1) id from product
很显然下面完胜
5.连接查询的优化
首先你要弄明白你想要的数据是什么样子的,然后再做出决定使用哪一种连接,这很重要。
各种连接的取值大小为:
- 内连接结果集大小取决于左右表满足条件的数量
- 左连接取决与左表大小,右相反。
- 完全连接和交叉连接取决与左右两个表的数据总数量
- select * from
- ( (select * from orde where OrderId>10000) o left join orderproduct op on o.orderNum=op.orderNum )
- select * from
- ( orde o left join orderproduct op on o.orderNum=op.orderNum )
- where o.OrderId>10000


由此可见减少连接表的数据数量可以提高效率。
insert插入优化
- --创建临时表
- create table #tb1
- (
- id int,
- name nvarchar(30),
- createTime datetime
- )
- declare @i int
- declare @sql varchar(1000)
- set @i=0
- while (@i<100000) --循环插入10w条数据
- begin
- set @i=@i+1
- set @sql=' insert into #tb1 values('+convert(varchar(10),@i)+',''erzi'+convert(nvarchar(30),@i)+''','''+convert(nvarchar(30),getdate())+''')'
- exec(@sql)
- end
我这里运行时间是51秒
- --创建临时表
- create table #tb2
- (
- id int,
- name nvarchar(30),
- createTime datetime
- )
- declare @i int
- declare @sql varchar(8000)
- declare @j int
- set @i=0
- while (@i<10000) --循环插入10w条数据
- begin
- set @j=0
- set @sql=' insert into #tb2 select '+convert(varchar(10),@i*100+@j)+',''erzi'+convert(nvarchar(30),@i*100+@j)+''','''+convert(varchar(50),getdate())+''''
- set @i=@i+1
- while(@j<10)
- begin
- set @sql=@sql+' union all select '+convert(varchar(10),@i*100+@j)+',''erzi'+convert(nvarchar(30),@i*100+@j)+''','''+convert(varchar(50),getdate())+''''
- set @j=@j+1
- end
- exec(@sql)
- end
- drop table #tb2
- select count(1) from #tb2
我这里运行时间大概是20秒
分析说明:insert into select批量插入,明显提升效率。所以以后尽量避免一个个循环插入。
优化修改删除语句
如果你同时修改或删除过多数据,会造成cpu利用率过高从而影响别人对数据库的访问。
如果你删除或修改过多数据,采用单一循环操作,那么会是效率很低,也就是操作时间过程会很漫长。
这样你该怎么做呢?
折中的办法就是,分批操作数据。
- delete product where id<1000
- delete product where id>=1000 and id<2000
- delete product where id>=2000 and id<3000
- .....
当然这样的优化方式不一定是最优的选择,其实这三种方式都是可以的,这要根据你系统的访问热度来定夺,关键你要明白什么样的语句是什么样的效果。
总结:优化,最重要的是在于你平时设计语句,数据库的习惯,方式。如果你平时不在意,汇总到一块再做优化,你就需要耐心的分析,然而分析的过程就看你的悟性,需求,知识水平啦。
【面试突击】- sql语句的优化分析的更多相关文章
- sql语句的优化分析
开门见山,问题所在 sql语句性能达不到你的要求,执行效率让你忍无可忍,一般会时下面几种情况. 网速不给力,不稳定. 服务器内存不够,或者SQL 被分配的内存不够. sql语句设计不合理 没有相应的索 ...
- 【转】sql语句的优化分析
开门见山,问题所在 sql语句性能达不到你的要求,执行效率让你忍无可忍,一般会时下面几种情况. 网速不给力,不稳定. 服务器内存不够,或者SQL 被分配的内存不够. sql语句设计不合理 没有相应的索 ...
- 戈多编程-小谈sql语句的优化分析
在sqlserver大数据查询中,避免不了查询效率减慢,暂且抛弃硬件原因和版本原因,仅从sql语句角度分析. 一. sql 语句性能不达标,主要原因有一下几点: 1. 未建索引,检索导致全表扫描 2. ...
- 谈谈SQL 语句的优化技术
https://blogs.msdn.microsoft.com/apgcdsd/2011/01/10/sql-1/ 一.引言 一个凸现在很多开发者或数据库管理员面前的问题是数据库系统的性能问题.性能 ...
- Oracle SQL语句性能优化方法大全
Oracle SQL语句性能优化方法大全 下面列举一些工作中常常会碰到的Oracle的SQL语句优化方法: 1.SQL语句尽量用大写的: 因为oracle总是先解析SQL语句,把小写的字母转换成大写的 ...
- Oracle数据库的sql语句性能优化
在应用系统开发初期,由于开发数据库数据比较少,对于查询sql语句,复杂试图的编写等体会不出sql语句各种写法的性能优劣,但是如果将应用系统提交实际应用后,随着数据库中数据的增加,系统的响应速度就成为目 ...
- 解决死锁之路3 - 常见 SQL 语句的加锁分析 (转)
出处:https://www.aneasystone.com/archives/2017/12/solving-dead-locks-three.html 这篇博客将对一些常见的 SQL 语句进行加锁 ...
- 52 条 SQL 语句性能优化策略,建议收藏
本文会提到 52 条 SQL 语句性能优化策略. 1.对查询进行优化,应尽量避免全表扫描,首先应考虑在where及order by涉及的列上建立索引. 2.应尽量避免在where子句中对字段进行nul ...
- oracle中sql语句的优化
oracle中sql语句的优化 一.执行顺序及优化细则 1.表名顺序优化 (1) 基础表放下面,当两表进行关联时数据量少的表的表名放右边表或视图: Student_info (30000条数据)D ...
随机推荐
- VIM 命令速查表
今天整理一份 VIM 常用命令速查表,当做给自己备忘. 进入VIM 相关 命令 描述 vim filename 打开或者新建文件 vim +n filename 打开文件并将光标置于第n行行首 vim ...
- 解决window的bat脚本执行出现中文乱码的问题
window下通过新建txt文件然后改成.bat的文件,输入内容后,执行出现中文乱码?原因: 批处理文件,是以ANSI编码方式.若以别的方式(如UTF-8)编辑了批处理,转换成ANSI格式即可,正常创 ...
- 部署一个fc网站需要注意的地方
1. php环境 必须5.3 2. yum install nodejs 3. yum install v8-devel 3. 下载v8js php扩展, 版本是 v8js-0.1.3 tar -zx ...
- django入门5使用xadmin搭建管理后台
环境搭建: pip install django==1.9.8 pip install MySQL_python-1.2.5-cp27-none-win_amd64.whl pip install f ...
- 【原】QuickTime安装时,提示CAB文件"QuickTime.cab"中找不到此文件
卸载安装程序:apple software updateapple mobile device supportapple 应用程序支持32apple 应用程序支持64 再重新安装quicktime
- fashion MNIST识别(Tensorflow + Keras + NN)
Fashion MNIST https://www.kaggle.com/zalando-research/fashionmnist Fashion-MNIST is a dataset of Zal ...
- 将pip源设置国内源
windows (1)打开文件资源管理器(文件夹地址栏中) (2)地址栏上面输入 %appdata% (3)在这里面新建一个文件夹 pip (4)在pip文件夹里面新建一个文件叫做 pip.ini , ...
- MySQL5.7的sql脚本导入到MySQL5.5出错解决
今晚有人让我将他的数据库导入到我的mysql里,执行导入后发现有报错 想了下可能是版本的问题,询问了下,他的数据库是5.7而我的是5.5 他给我提议升级mysql版本,但是我就是不想换版本 那怎么在不 ...
- 视频质量诊断----PTZ云台运动检测
一.PTZ云台运动检测是通过配合云台运动的功能检测云台运动是否正常. 二.原理 取云台运动前N帧图像,进行背景建模,得到运动前背景A. 设备发送云台运动指令,让云台进行运动,改变场景. 取云台运动后N ...
- 【视频开发】用GStreamer实现摄像头的采集和保存
GStreamer是流媒体软件的开发框架.可以这样说,在该框架的支持下,你可以非常简单地为很多格式的流媒体写出自已需要的程序. 现在,GStreamer已经内置对MP3.Ogg/Vorbis.MPEG ...