scrapy爬虫案例:问政平台
问政平台
http://wz.sun0769.com/index.php/question/questionType?type=4
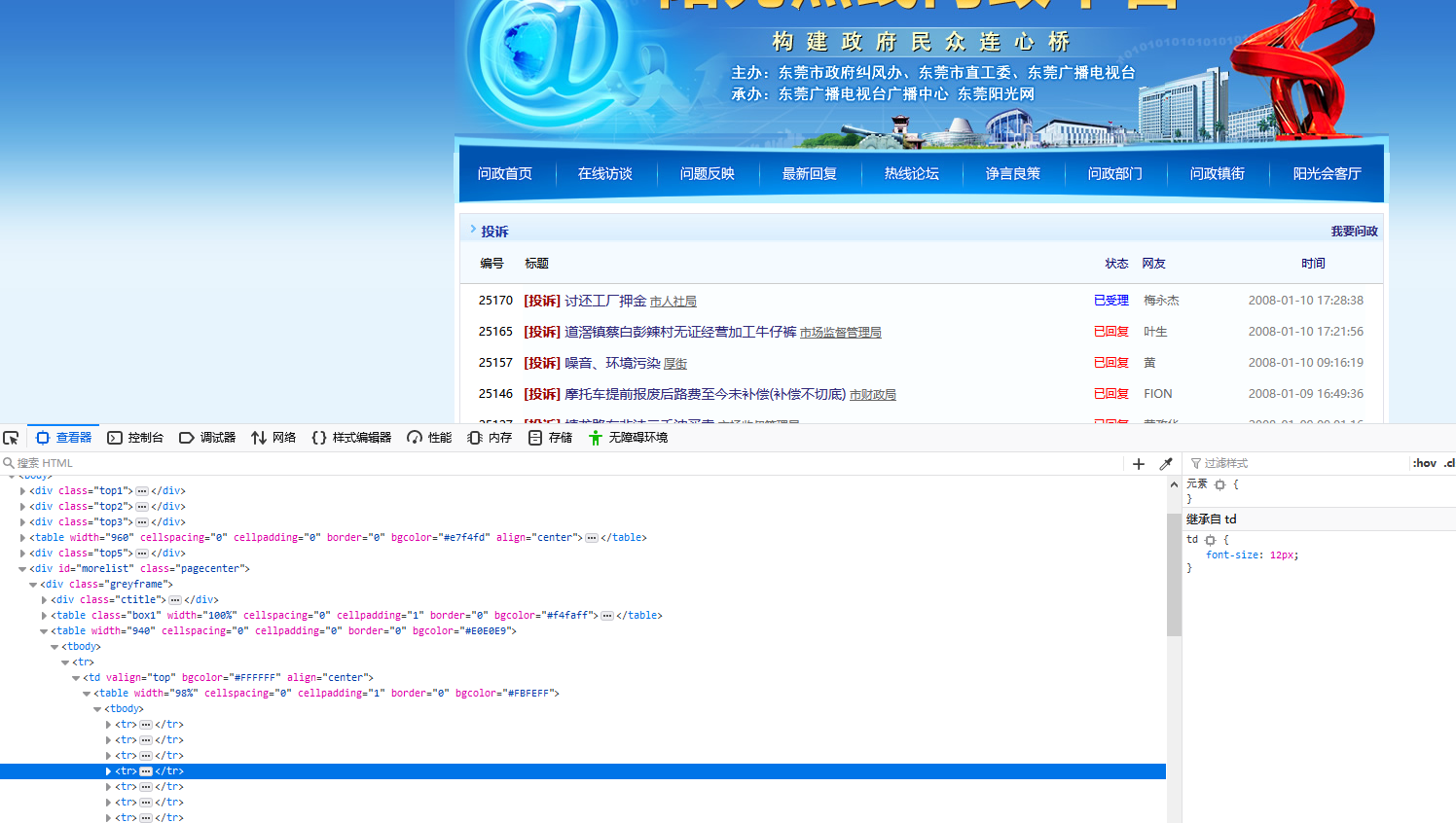
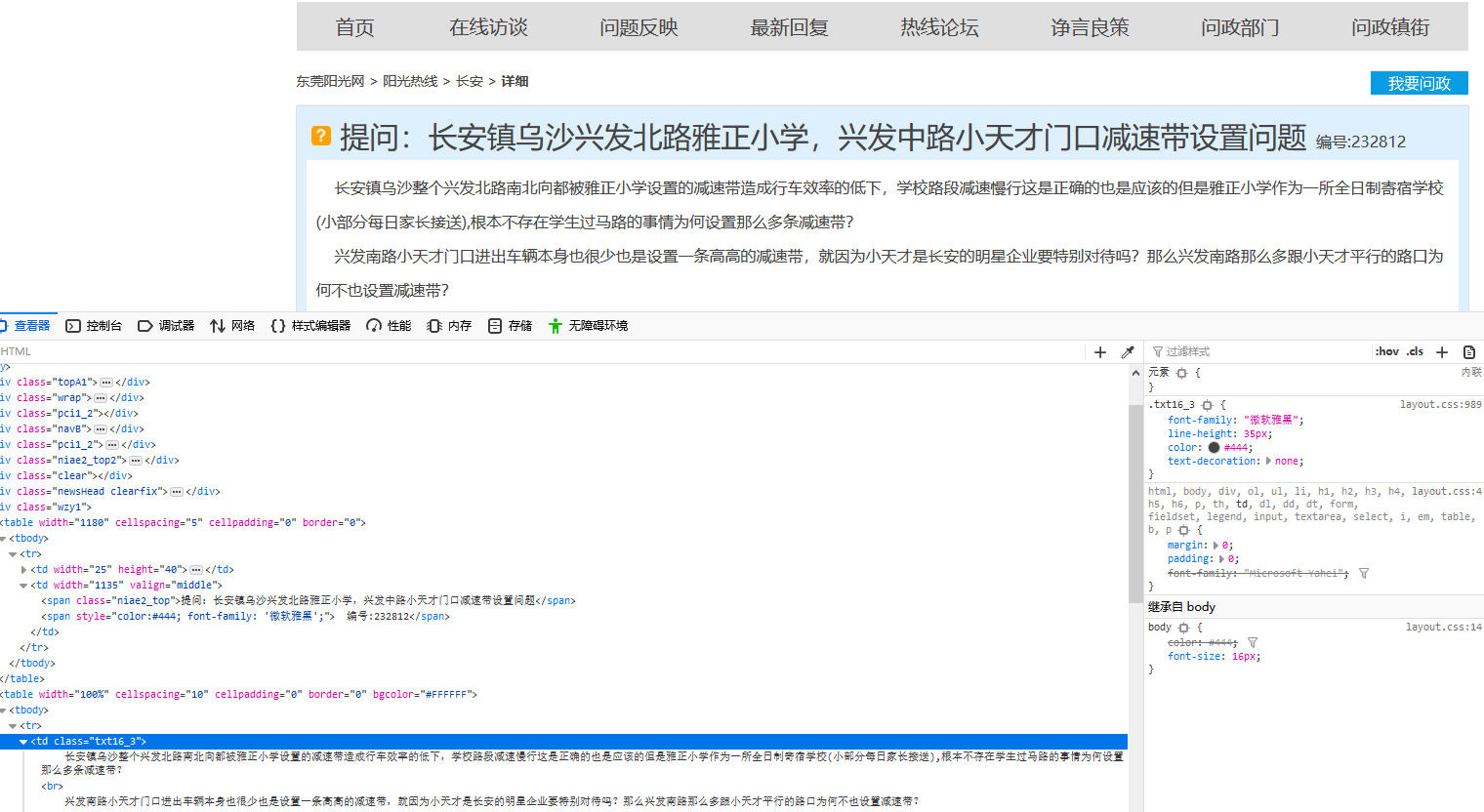
爬取投诉帖子的编号、帖子的url、帖子的标题,和帖子里的内容。
items.py
import scrapy class DongguanItem(scrapy.Item):
# 每个帖子的标题
title = scrapy.Field()
# 每个帖子的编号
number = scrapy.Field()
# 每个帖子的文字内容
content = scrapy.Field()
# 每个帖子的url
url = scrapy.Field()
spiders/sunwz.py
# -*- coding: utf-8 -*- import scrapy
from scrapy.spiders import CrawlSpider from scrapyDemo.items import DongguanItem class SunSpider(CrawlSpider):
name = 'sun'
allowed_domains = ['wz.sun0769.com']
url = 'http://wz.sun0769.com/index.php/question/questionType?type=4&page='
offset = 0
start_urls = [url + str(offset)] def parse(self, response):
# 取出每个页面里帖子链接列表
links = response.xpath("//div[@class='greyframe']/table//td/a[@class='news14']/@href").extract()
# 迭代发送每个帖子的请求,调用parse_item方法处理
for link in links:
yield scrapy.Request(link, callback=self.parse_item)
# 设置页码终止条件,并且每次发送新的页面请求调用parse方法处理
if self.offset <= 3876:
self.offset += 30
yield scrapy.Request(self.url + str(self.offset), callback=self.parse) # 处理每个帖子里
def parse_item(self, response):
item = DongguanItem()
# 标题
item['title'] = response.xpath('//span[contains(@class, "niae2_top")]/text()').extract()[0]
# 编号
item['number'] = response.xpath('//div[contains(@class, "wzy1")]//td//span/text()').extract()[1]
# 文字内容,默认先取出有图片情况下的文字内容列表
content = response.xpath('//td[@class="txt16_3"]/text()').extract()
# 如果没有内容,则取出没有图片情况下的文字内容列表
if len(content) == 0:
content = response.xpath('//div[@class="c1 text14_2"]/text()').extract()
# content为列表,通过join方法拼接为字符串,并去除首尾空格
item['content'] = "".join(content).strip()
else:
item['content'] = "".join(content).strip() # 链接
item['url'] = response.url
yield item
pipelines.py
# -*- coding: utf-8 -*- # 文件处理类库,可以指定编码格式
import codecs
import json class DongguanPipeline(object): def __init__(self):
# 创建一个只写文件,指定文本编码格式为utf-8
self.filename = codecs.open('sunwz.json', 'w', encoding='utf-8') def process_item(self, item, spider):
content = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.filename.write(content)
return item def spider_closed(self, spider):
self.file.close()
settings.py
ITEM_PIPELINES = {
'dongguan.pipelines.DongguanPipeline': 300,
}
# 日志文件名和处理等级
LOG_FILE = "dg.log"
LOG_LEVEL = "DEBUG"
在项目根目录下新建main.py文件,用于调试
from scrapy import cmdline
cmdline.execute('scrapy crawl sunwz'.split())
执行程序
py2 main.py
效果:

scrapy爬虫案例:问政平台的更多相关文章
- scrapy爬虫案例--爬取阳关热线问政平台
阳光热线问政平台:http://wz.sun0769.com/political/index/politicsNewest?id=1&page=1 爬取最新问政帖子的编号.投诉标题.投诉内容以 ...
- Scrapy爬虫案例 | 数据存储至MySQL
首先,MySQL创建好数据库和表 然后编写各个模块 item.py import scrapy class JianliItem(scrapy.Item): name = scrapy.Field() ...
- Scrapy爬虫案例 | 数据存储至MongoDB
豆瓣电影TOP 250网址 要求: 1.爬取豆瓣top 250电影名字.演员列表.评分和简介 2.设置随机UserAgent和Proxy 3.爬取到的数据保存到MongoDB数据库 items.py ...
- scrapy爬虫案例:用MongoDB保存数据
用Pymongo保存数据 爬取豆瓣电影top250movie.douban.com/top250的电影数据,并保存在MongoDB中. items.py class DoubanspiderItem( ...
- 爬虫——Scrapy框架案例二:阳光问政平台
阳光热线问政平台 URL地址:http://wz.sun0769.com/index.php/question/questionType?type=4&page= 爬取字段:帖子的编号.投诉类 ...
- Scrapy项目_阳光热线问政平台
目的: 爬取阳光热线问政平台问题中每个帖子的标题.详情URL.详情内容.图片以及发布时间 步骤: 1.创建爬虫项目 1 scrapy startproject yangguang 2 cd yangg ...
- 如何让你的scrapy爬虫不再被ban之二(利用第三方平台crawlera做scrapy爬虫防屏蔽)
我们在做scrapy爬虫的时候,爬虫经常被ban是常态.然而前面的文章如何让你的scrapy爬虫不再被ban,介绍了scrapy爬虫防屏蔽的各种策略组合.前面采用的是禁用cookies.动态设置use ...
- 爬虫框架Scrapy之案例一
阳光热线问政平台 http://wz.sun0769.com/index.php/question/questionType?type=4 爬取投诉帖子的编号.帖子的url.帖子的标题,和帖子里的内容 ...
- Scrapy爬虫及案例剖析
由于互联网的极速发展,所有现在的信息处于大量堆积的状态,我们既要向外界获取大量数据,又要在大量数据中过滤无用的数据.针对我们有益的数据需要我们进行指定抓取,从而出现了现在的爬虫技术,通过爬虫技术我们可 ...
随机推荐
- 如何在macOS下调整磁盘分区大小?
可以在“macOS”下利用磁盘工具并且不抹掉主分区的情况下,随意更改磁盘分区大小的方法.“OS X”经过几次大版本升级以后,也改名为“macOS”,而且系统自带的“磁盘工具”无论是功能和界面也有很大的 ...
- IDisposable 接口
提供一种用于释放非托管资源的机制. 地址:https://docs.microsoft.com/zh-cn/dotnet/api/system.idisposable?view=netframewor ...
- js图片转为base64的格式
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Example-based Machine Learning是什么?
参考:https://christophm.github.io/interpretable-ml-book/proto.html EML简介 Example-based Machine Learnin ...
- JAVA之Socket通讯
Server.java: Client.java Server console:(先启动服务器,再启动客户端) 服务器读取了客户端发来的hello server: Client console:客户 ...
- 运行 npm run lint -- --fix,提示:error Use the global form of 'use strict'
运行 npm run lint -- --fix,提示:error Use the global form of 'use strict',使用说明网址:https://eslint.org/docs ...
- Trie Service
Description Build tries from a list of <word, freq> pairs. Save top 10 for each node. Example ...
- SDOI 二轮垫底鸡
SDOI 二轮垫底鸡 day0 准备爆零 没啥好准备考试的,12.00出发,试机敲抄个ntt,在宾馆不知道颓啥. day1 爆零爬山 T1noip的题目也放到省选上. 第一档线段树?肯定不写,直接上1 ...
- Bzoj 1857: [Scoi2010]传送带(三分套三分)
1857: [Scoi2010]传送带 Time Limit: 1 Sec Memory Limit: 64 MB Description 在一个2维平面上有两条传送带,每一条传送带可以看成是一条线段 ...
- 第02组 Alpha冲刺(4/4)
队名:十一个憨批 组长博客 作业博客 组长黄智 过去两天完成的任务:了解整个游戏的流程 GitHub签入记录 接下来的计划:继续完成游戏 还剩下哪些任务:完成游戏 燃尽图 遇到的困难:没有美术比较好的 ...