solr配置同义词,停止词,和扩展词库(IK分词器为例)
定义
同义词:搜索结果里出现的同义词。如我们输入”还行”,得到的结果包括同义词”还可以”。
停止词:在搜索时不用出现在结果里的词。比如is 、a 、are 、”的”,“得”,“我” 等,这些词会在句子中多次出现却无意义,所以在分词的时候需要把这些词过滤掉。
扩展词:在搜索结果里额外出现的词。扩展词只能是你输入词的本身或子串。比如我们 输入”重庆开县人”,正常分词得到的结果是“重庆” “开县”“人”;当我们在扩展词里加入“重庆开县”时,分词的结果是“重庆开县”“重庆” “开县”“人”。
配置同义词
1.在solr_home的conf目录下的schema.xml 中配置同义词text_syn:
<!-- 配置IK分词器的同义词 -->
<fieldType name="text_syn" class="solr.TextField">
<analyzer type="query">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="index">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="false" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>2.假定在solr_home的conf目录下的schema.xml 中要对shortName字段进行同义词配置,则我们需要将type属性设为上向配置的”text_syn”
<field name="shortName" type="text_syn" indexed="true" stored="true" />- 1
3.在conf目录下的 synonyms.txt 中增加同义词,如:
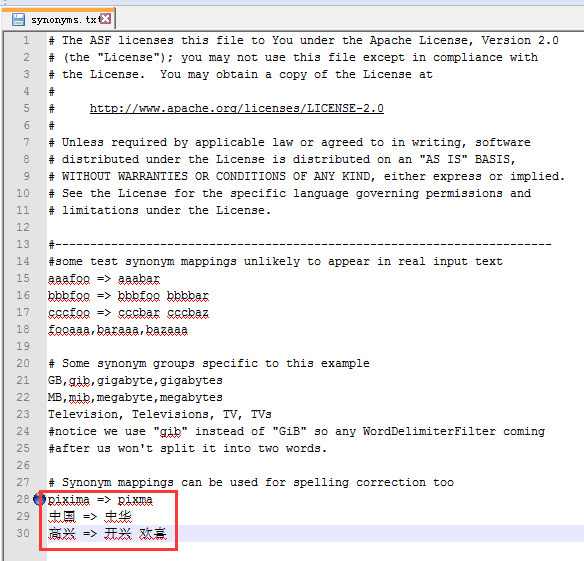
这里我多说两句:上面红框里的 => 右侧的词是左侧词的同义词,多个时用空格隔开。还有就是,最好不要直接打开synonyms.txt这个文件,因为加入的汉字在保存后会查不出来,因为txt不是UTF-8的格式保存的。
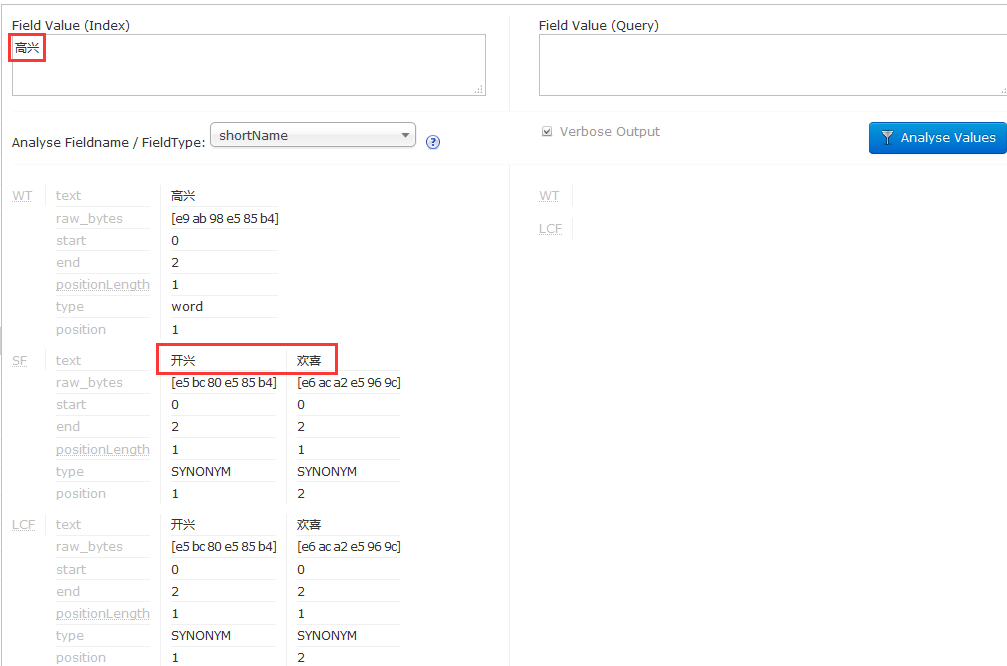
4.测试同义词
输入高兴:
- 1
输入中华:
- 1
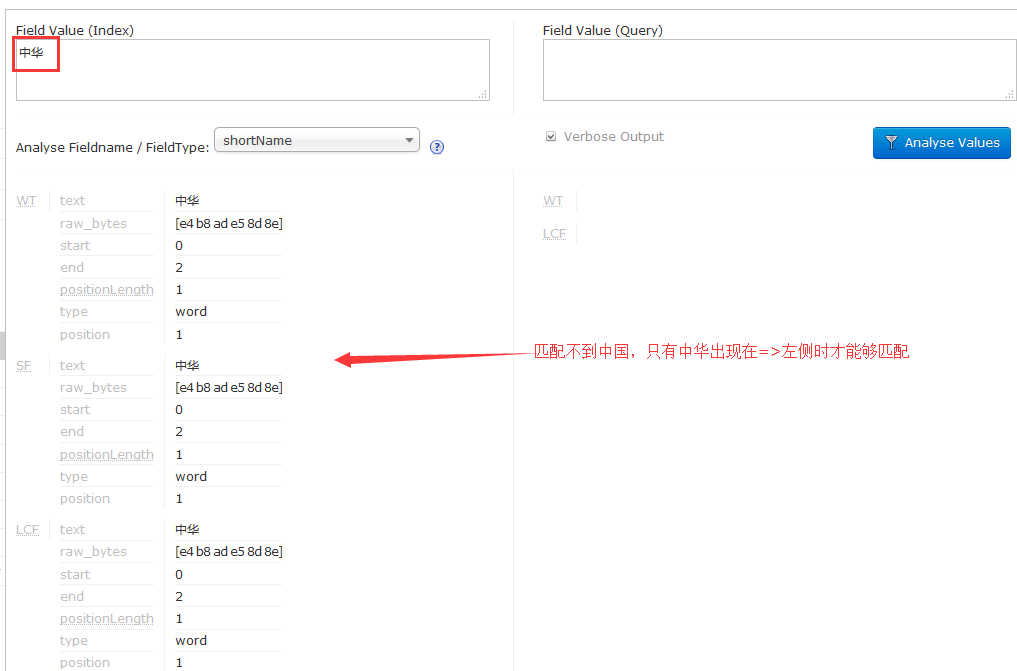
5.基于上面的问题,说下怎么解决,毕竟不论我们输入中华还是中国,都能有对应的同义词结果。
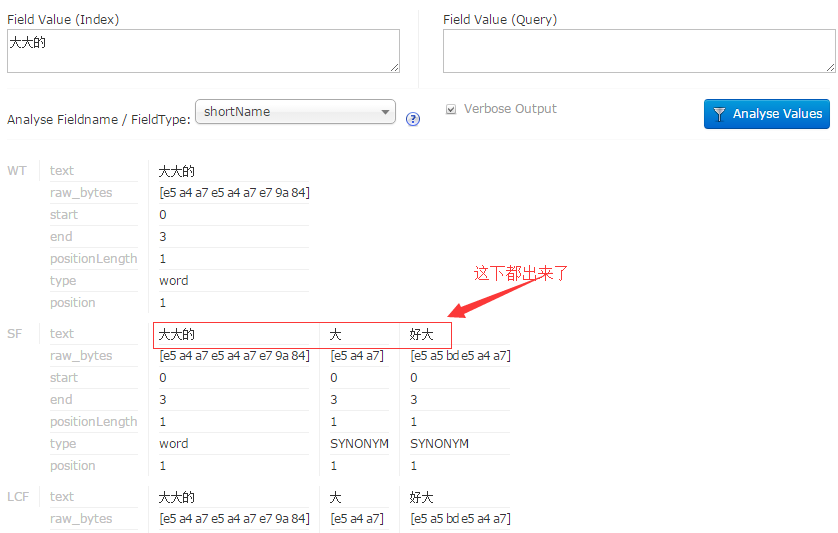
首先,我们将synonyms.txt里的同义词用英文逗号隔开,然后将上面配置IK同义词里的expand属性设为true。

我们输入:大大的,结果如下:
配置停止词和扩展词库。
1.将IKAnalyzer解压文件夹下的stopword.dic和IKAnalyzer.cfg.xml复制到tomcat/webapps/solr/WEB-INF/classes下,再新建一个ext.dic,里面的格式和stopword.dic一致。
2.修改IKAnalyzer.cfg.xml如下面的格式可以配置多个停止词或者扩展词库文件。
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典-->
<entry key="ext_dict">ext.dic;</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">english_stopword.dic;stopword.dic</entry>
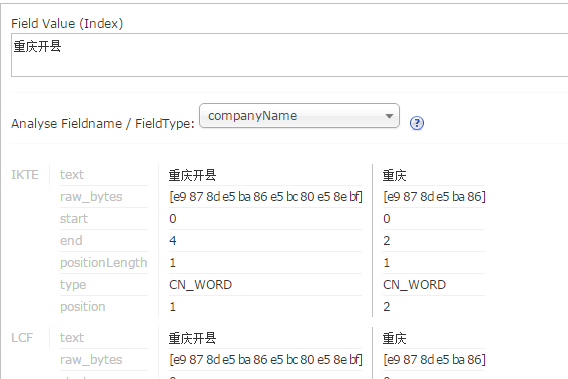
<properties> 输入“重庆开县”时,正常分词是只有”重庆” “开县”的
在ext.dic里添加了”重庆开县”后,测试结果:
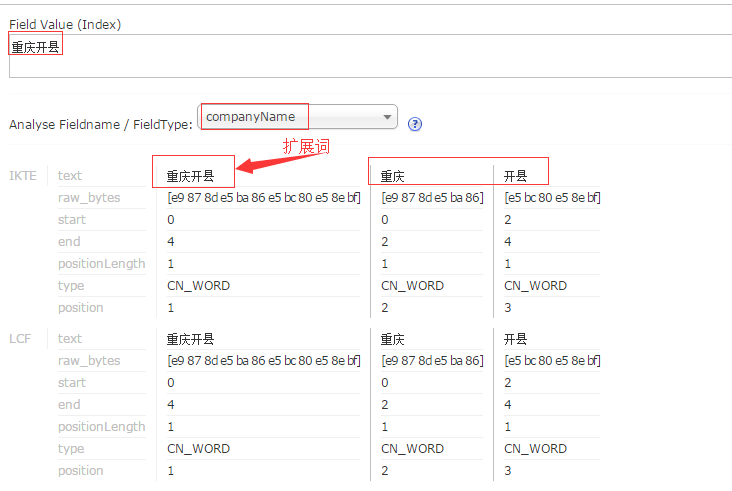
输入“重庆开县”时,正常分词是只有”重庆” “开县”的
在stopword.dic里添加了“开县”之后,测试结果:
注意
字段如果要能被分词,或是停止词,或是扩展词,需要在schema.xml里配置该字段时,给该字段的type属性配成分词类型,我们这里是text_ik,例:
<field name="companyName" type="text_ik" indexed="false" stored="true" multiValued="false" />solr配置同义词,停止词,和扩展词库(IK分词器为例)的更多相关文章
- Solr(四)Solr实现简单的类似百度搜索高亮功能-1.配置Ik分词器
配置Ik分词器 一 效果图 二 实现此功能需要添加分词器,在这里使用比较主流的IK分词器. 1 没有配置IK分词器,用solr自带的text分词它会把一句话分成单个的字. 2 配置IK分词器,的话它会 ...
- IK分词器 整合solr4.7 含同义词、切分词、停止词
转载请注明出处! IK分词器如果配置成 <fieldType name="text_ik" class="solr.TextField"> < ...
- solr添加中文IK分词器,以及配置自定义词库
Solr是一个基于Lucene的Java搜索引擎服务器.Solr 提供了层面搜索.命中醒目显示并且支持多种输出格式(包括 XML/XSLT 和 JSON 格式).它易于安装和配置,而且附带了一个基于H ...
- [Linux]Linux下安装和配置solr/tomcat/IK分词器 详细实例二.
为了更好的排版, 所以将IK分词器的安装重启了一篇博文, 大家可以接上solr的安装一同查看.[Linux]Linux下安装和配置solr/tomcat/IK分词器 详细实例一: http://ww ...
- solr配置相关:约束文件及引入ik分词器
schema.xml: solr约束文件 Solr中会提前对文档中的字段进行定义,并且在schema.xml中对这些字段的属性进行约束,例如:字段数据类型.字段是否索引.是否存储.是否分词等等 < ...
- [Linux]Linux下安装和配置solr/tomcat/IK分词器 详细实例一.
在这里一下讲解着三个的安装和配置, 是因为solr需要使用tomcat和IK分词器, 这里会通过图文教程的形式来详解它们的安装和使用.注: 本文属于原创文章, 如若转载,请注明出处, 谢谢.关于设置I ...
- Solr 06 - Solr中配置使用IK分词器 (配置schema.xml)
目录 1 配置中文分词器 1.1 准备IK中文分词器 1.2 配置schema.xml文件 1.3 重启Tomcat并测试 2 配置业务域 2.1 准备商品数据 2.2 配置商品业务域 2.3 配置s ...
- Solr4.4入门,介绍Solr的安装、IK分词器的配置及高亮查询结果(转)
一.Windows下安装solr-4.4.0 1. 下载solr.4.4 2. 下载绿色版tomcat6.0.18 3. 解压下载的solr到d:\study\solr,将dist目录下的sol ...
- Solr——配置IK分词器
首先需要的准备好jdk1.8和tomcat8以及ik分词器(ik分词器是5.x的版本,和solr4.10搭配的版本不一样,虽然是5.x的版本但是也是能使用在solr7.2版本上的) 分享链接https ...
随机推荐
- [Leetcode] 5279. Subtract the Product and Sum of Digits of an Integer
class Solution { public int subtractProductAndSum(int n) { int productResult = 1; int sumResult = 0; ...
- Git 版本及版本范围表示法
很多 Git 命令都使用 revision(修订版本)作为参数.根据不同的命令,有时候 revision 参 数代表一个特定的提交,有时候代表某一个提交可以追踪到的所有的父提交(比如 git log) ...
- 阿里云 centos 无法执行moodle cron
在阿里云服务器安装moodle时,在执行cron计划任务时,报错sendmail: fatal: parameter inet_interfaces: no local interface found ...
- javascript(六)运算符
运算符概述 JavaScript中的运算符用于算术表达式. 比较表达式. 逻辑表达式. 赋值表达式等.需要注意的是, 大多数运算符都是由标点符号表示的, 比如 "+" 和" ...
- 我用Bash编写了一个扫雷游戏
我在编程教学方面不是专家,但当我想更好掌握某一样东西时,会试着找出让自己乐在其中的方法.比方说,当我想在 shell 编程方面更进一步时,我决定用 Bash 编写一个扫雷游戏来加以练习. 我在编程教学 ...
- 隐马尔科夫模型(Hidden Markov Models) 系列之五
转自:http://blog.csdn.net/eaglex/article/details/6458541 维特比算法(Viterbi Algorithm) 找到可能性最大的隐藏序列 通常我们都有一 ...
- 02篇ELK日志系统——升级版集群之kibana和logstash的搭建整合
[ 前言:01篇LK日志系统已经把es集群搭建好了,接下来02篇搭建kibana和logstash,并整合完成整个ELK日志系统的初步搭建. ] 1.安装kibana 3台服务器: 192.168.2 ...
- Git的下载安装
下载地址:https://git-scm.com/download/win 命令: git add ... ---将资源放到缓存区域 git commit -m "提交说明" ...
- Spark MLlib基本算法【相关性分析、卡方检验、总结器】
一.相关性分析 1.简介 计算两个系列数据之间的相关性是统计中的常见操作.在spark.ml中提供了很多算法用来计算两两的相关性.目前支持的相关性算法是Pearson和Spearman.Correla ...
- Robot Framework常用关键字
虽然通过RIDE提供"填表"一样的写测试用例的方式.但它却支持强大的关键字功能,以及可以开发关键字的扩展能力. Comment 注释功能,也可以使用python中的"#& ...