HashTable源码
1. 为什么无法创建更大的数组?
Attempts to allocate larger arrays may result in OutOfMemoryError
如果数组长度过大,可能出现的两种错误
OutOfMemoryError: Java heap space 堆区内存不足(这个可以通过设置JVM参数 -Xmx 来指定)。
OutOfMemoryError: Requested array size exceeds VM limit 超过了JVM虚拟机的最大限制,我的window64就是 Integer.MAX_VALUE-1 .
2. 为什么数组长度的最大值是Integer.MAX_VALUE - 8
数组作为一个对象,需要一定的内存存储对象头信息,对象头信息最大占用内存不可超过8字节。
HashMap的方法是非同步的,若要在多线程下使用HashMap,需要我们额外的进行同步处理。对HashMap处理可以使用Collections类提供的synchronizedMap静态方法,或者直接使用JDK5.0之后提供的java.util.concurrent包里的ConcurrentHashMap类。
HashTable几乎所有方法都是同步的,前面都加了synchronized关键字,它支持多线程。
HashTable几乎所有方法都是同步的,前面都加了synchronized关键字,它支持多线程。
HashMap的key和value都可以为null。
HashTable的key和value都不可以为null。
HashMap只支持Iterator遍历。
HashTable支持Iterator和Enumeration两种方式遍历。
HashMap的默认容量是16,,扩容时,每次将容量变为原来的2倍;
HashTable的默认容量是11,扩容时,每次将容量变为原来的2倍+1。
HashMap添加元素时,是使用自定义的哈希算法;
HashTable是直接采用key的hashCode()。
public class testhashtable {
@SuppressWarnings({ "unused", "unchecked", "rawtypes" })
public static void main(String[] args) {
Hashtable1<Integer, Integer> numbers = new Hashtable1<Integer, Integer>();
numbers.put(, );
numbers.put(, );
numbers.put(, );
numbers.put(, );
numbers.put(, );
Hashtable1<Integer, Integer> numbers1 = (Hashtable1<Integer, Integer>) numbers.clone();
Enumerator k1 = numbers.getEnumeration();//返回迭代器
while(k1.hasNext()) {
System.out.println(k1.next());//3 2 23 12 1
}
Enumerator v1 = numbers.getEnumeration();//返回迭代器
while(v1.hasNext()) {
System.out.println(v1.next());//3 2 23 12 1
}
Enumerator e1 = numbers.getEnumeration();//返回迭代器
while(e1.hasNext()) {
System.out.println(e1.next());//3=3 2=2 23=23 12=12 1=1
}
Enumerator k2 = (Enumerator) numbers.getIterator();//返回迭代器
while(k2.hasNext()) {
System.out.println(k2.next());//3 2 23 12 1
}
Enumerator v2 = (Enumerator) numbers.getIterator();//返回迭代器
while(v2.hasNext()) {
System.out.println(v2.next());//3 2 23 12 1
}
v2.remove();
Enumerator e2 = (Enumerator) numbers.getIterator();//返回迭代器
while(e2.hasNext()) {
System.out.println(e2.next());//3=3 2=2 23=23 12=12 1=1
}
Enumerator k3 =(Enumerator) numbers.keys();
Enumerator v3 =(Enumerator) numbers.elements();
Enumerator e3 =(Enumerator) numbers.keys();
Set s1 = numbers.keySet1();//[3, 2, 23, 12, 1]
int 他1 = s1.size();//
boolean b1 = s1.contains();
boolean ss1 = s1.remove();
Iterator l1 = s1.iterator();
while(l1.hasNext()) {
System.out.println(l1.next());
}
Collection kkk = numbers.entrySet1();//[3=3, 2=2, 23=23, 12=12, 1=1]
kkk.add(new Entry<>(, , , null));
Set s = numbers.keySet();//返回SynchronizedSet,都是SynchronizedSet对象的方法。
int 他 = s.size();
boolean b = s.contains();
boolean ss = s.remove();
Object[] a = s.toArray();
boolean ml = s.isEmpty();
// s.add(new Entry<>(4, 4, 4, null));
Iterator l = s.iterator();
while(l.hasNext()) {
System.out.println(l);
}
Collection v = numbers.values();
Set e = numbers.entrySet();
Collection sssv = numbers.entrySet();
System.out.println(Integer.toBinaryString(-));
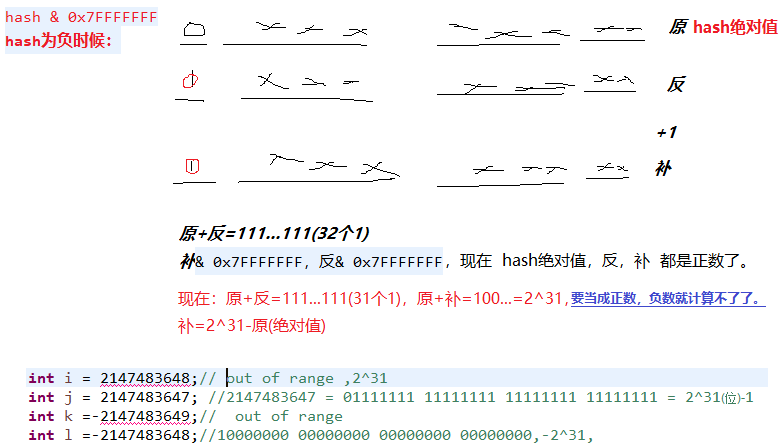
System.out.println(Integer.toBinaryString(- & 0x7FFFFFFF));
System.out.println(- & 0x7FFFFFFF);//2147483645=2^31-3
/*int i = 2147483648;// out of range ,2^31
int j = 2147483647; //2147483647 = 01111111 11111111 11111111 11111111 = 2^31(位)-1
int k =-2147483649;// out of range
int l =-2147483648;//10000000 00000000 00000000 00000000,-2^31, */
}
}
package map;
public class Hashtable1<K,V> extends Dictionary<K,V> implements Map1<K,V>, Cloneable, java.io.Serializable {
public transient Entry<?,?>[] table;
public transient int count;//链表节点个数
public int threshold;//阈值capacity * loadFactor
public float loadFactor;
public transient int modCount = ;
public static final long serialVersionUID = 1421746759512286392L;
public Hashtable1(int initialCapacity, float loadFactor) {
if (initialCapacity < )
throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity);
if (loadFactor <= || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
if (initialCapacity==)
initialCapacity = ;
this.loadFactor = loadFactor;
table = new Entry<?,?>[initialCapacity];
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + );
}
public Hashtable1(int initialCapacity) {
this(initialCapacity, 0.75f);
}
public Hashtable1() {
this(, 0.75f);//默认初始化11个,
}
public Hashtable1(Map1<? extends K, ? extends V> t) {
this(Math.max(*t.size(), ), 0.75f);
putAll(t);
}
public synchronized int size() {//线程安全
return count;
}
public synchronized boolean isEmpty() {//线程安全
return count == ;
}
//线程安全
public synchronized Enumeration<K> keys() {
return this.<K>getEnumeration(KEYS);//
}
//线程安全
public synchronized Enumeration<V> elements() {
return this.<V>getEnumeration(VALUES);//
}
//线程安全
public synchronized boolean contains(Object value) {
if (value == null) {
throw new NullPointerException();
}
Entry<?,?> tab[] = table;
for (int i = tab.length ; i-- > ;) {
for (Entry<?,?> e = tab[i] ; e != null ; e = e.next) {
if (e.value.equals(value)) {//数组加链表
return true;
}
}
}
return false;
}
public boolean containsValue(Object value) {
return contains(value);
}
//线程安全
public synchronized boolean containsKey(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;//hash为负数:2^31 -|hash|。
for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return true;
}
}
return false;
}
//线程安全
public synchronized V get(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return (V)e.value;
}
}
return null;
}
//虚拟机给数组有头信息,8*4个字节=32字节。
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - ;
//线程安全
protected void rehash() {
int oldCapacity = table.length;
Entry<?,?>[] oldMap = table;
int newCapacity = (oldCapacity << ) + ;//2*oldCapacity+1
if (newCapacity - MAX_ARRAY_SIZE > ) {
if (oldCapacity == MAX_ARRAY_SIZE)
return;
newCapacity = MAX_ARRAY_SIZE;
}
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];
modCount++;//遍历时候不能进行rehash操作
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + );
table = newMap;
for (int i = oldCapacity ; i-- > ;) {//遍历数组
for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {//遍历链表
Entry<K,V> e = old;
old = old.next;
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = (Entry<K,V>)newMap[index];//放在最前面
newMap[index] = e;
}
}
}
private void addEntry(int hash, K key, V value, int index) {
modCount++;
Entry<?,?> tab[] = table;
if (count >= threshold) {
rehash();
tab = table;
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;
}
Entry<K,V> e = (Entry<K,V>) tab[index];
tab[index] = new Entry<>(hash, key, value, e);//添加到最前面
count++;
}
//线程安全
public synchronized V put(K key, V value) {
if (value == null) {
throw new NullPointerException();
}
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {//遍历链表
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}
//线程安全
public synchronized V remove(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
Entry<K,V> e = (Entry<K,V>)tab[index];
for(Entry<K,V> prev = null ; e != null ; prev = e, e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
modCount++;
if (prev != null) {
prev.next = e.next;
} else {
tab[index] = e.next;//第一个元素
}
count--;
V oldValue = e.value;
e.value = null;
return oldValue;
}
}
return null;
}
//线程安全
public synchronized void putAll(Map1<? extends K, ? extends V> t) {
for (Map1.Entry<? extends K, ? extends V> e : t.entrySet())
put(e.getKey(), e.getValue());
}
//线程安全
public synchronized void clear() {
Entry<?,?> tab[] = table;
modCount++;
for (int index = tab.length; --index >= ; )
tab[index] = null;
count = ;
}
//线程安全
public synchronized Object clone() {
try {
Hashtable1<?,?> t = (Hashtable1<?,?>)super.clone();
Hashtable1<?,?> tt = this;//2者的地址都是一模一样的。new的地址不一样。
t.table = new Entry<?,?>[table.length];
for (int i = table.length ; i-- > ; ) {//地址不一样了
t.table[i] = (table[i] != null) ? (Entry<?,?>) table[i].clone() : null;
}
t.keySet = null;
t.entrySet = null;
t.values = null;
t.modCount = ;
return t;
} catch (CloneNotSupportedException e) {
throw new InternalError(e);
}
}
//线程安全
public synchronized String toString() {
int max = size() - ;
if (max == -)
return "{}";
StringBuilder sb = new StringBuilder();
Iterator<Map1.Entry<K,V>> it = entrySet().iterator();
sb.append('{');
for (int i = ; ; i++) {
Map1.Entry<K,V> e = it.next();
K key = e.getKey();
V value = e.getValue();
sb.append(key == this ? "(this Map)" : key.toString());
sb.append('=');
sb.append(value == this ? "(this Map)" : value.toString());
if (i == max)
return sb.append('}').toString();
sb.append(", ");
}
}
public <T> Enumerator<T> getEnumeration(int type) {//0是keys,1是values,2是Entry。
if (count == ) {
return (Hashtable1<K, V>.Enumerator<T>) Collections1.emptyEnumeration();
} else {
return new Enumerator<>(type, false);//false返回枚举器
}
}
public <T> Iterator<T> getIterator(int type) {//0是keys,1是values,2是Entry。
if (count == ) {
return Collections1.emptyIterator();
} else {
return new Enumerator<>(type, true);//true返回迭代器Iterator
}
}
private transient volatile Set<K> keySet;
private transient volatile Set<Map1.Entry<K,V>> entrySet;
private transient volatile Collection<V> values;
public Set<K> keySet() {
if (keySet == null) //内部KeySet对象,整个hashtable
keySet = Collections1.synchronizedSet(new KeySet(), this);
return keySet;
}
public Set<K> keySet1() {
if (keySet == null)
keySet = new KeySet() ;//[888, 888, 888, 888, 888],是根据new KeySet()的iterator()返回的Iterator对象的hasNext()和next()方法确定值的。
return keySet;
}
private class KeySet extends AbstractSet<K> {
public Iterator<K> iterator() {
return getIterator(KEYS);
}
public int size() {
return count;//外部属性。外部类的属性不能通过点来访问,只能通过方法来访问。
}
public boolean contains(Object o) {
return containsKey(o);//外部方法
}
public boolean remove(Object o) {
return Hashtable1.this.remove(o) != null;//外部方法
}
public void clear() {
Hashtable1.this.clear();//外部方法
}
}
public Set<Map1.Entry<K,V>> entrySet() {
if (entrySet==null)
entrySet = Collections1.synchronizedSet(new EntrySet(), this);
return entrySet;
}
public Set<Map1.Entry<K,V>> entrySet1() {
if (entrySet==null)
entrySet = new EntrySet() ;//[3=3, 2=2, 23=23, 12=12, 1=1]
return entrySet;
}
private class EntrySet extends AbstractSet<Map1.Entry<K,V>> {
public Iterator<Map1.Entry<K,V>> iterator() {
return getIterator(ENTRIES);
}
public boolean add(Map1.Entry<K,V> o) {
return super.add(o);//不能添加,报错。
}
public boolean contains(Object o) {
if (!(o instanceof Map1.Entry))
return false;
Map1.Entry<?,?> entry = (Map1.Entry<?,?>)o;
Object key = entry.getKey();
Entry<?,?>[] tab = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<?,?> e = tab[index]; e != null; e = e.next)
if (e.hash==hash && e.equals(entry))
return true;
return false;
}
public boolean remove(Object o) {
if (!(o instanceof Map1.Entry))
return false;
Map1.Entry<?,?> entry = (Map1.Entry<?,?>) o;
Object key = entry.getKey();
Entry<?,?>[] tab = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>)tab[index];
for(Entry<K,V> prev = null; e != null; prev = e, e = e.next) {
if (e.hash==hash && e.equals(entry)) {
modCount++;
if (prev != null)
prev.next = e.next;
else
tab[index] = e.next;
count--;
e.value = null;
return true;
}
}
return false;
}
public int size() {
return count;
}
public void clear() {
Hashtable1.this.clear();
}
}
public Collection<V> values() {
if (values==null)
values = Collections1.synchronizedCollection(new ValueCollection(),this);
return values;
}
private class ValueCollection extends AbstractCollection<V> {
public Iterator<V> iterator() {
return getIterator(VALUES);
}
public int size() {
return count;
}
public boolean contains(Object o) {
return containsValue(o);
}
public void clear() {
Hashtable1.this.clear();
}
}
public synchronized boolean equals(Object o) {
if (o == this)
return true;
if (!(o instanceof Map))
return false;
Map1<?,?> t = (Map1<?,?>) o;
if (t.size() != size())//大小相等
return false;
try {
Iterator<Map1.Entry<K,V>> i = entrySet().iterator();
while (i.hasNext()) {
Map1.Entry<K,V> e = i.next();
K key = e.getKey();
V value = e.getValue();
if (value == null) {
if (!(t.get(key)==null && t.containsKey(key)))
return false;
} else {
if (!value.equals(t.get(key)))
return false;
}
}
} catch (ClassCastException unused) {
return false;
} catch (NullPointerException unused) {
return false;
}
return true;
}
public synchronized int hashCode() {
int h = ;
if (count == || loadFactor < )
return h; // 返回 0
loadFactor = -loadFactor; // Mark hashCode computation in progress
Entry<?,?>[] tab = table;
for (Entry<?,?> entry : tab) {
while (entry != null) {
h += entry.hashCode();
entry = entry.next;
}
}
loadFactor = -loadFactor; // Mark hashCode computation complete
return h;
}
@Override
public synchronized V getOrDefault(Object key, V defaultValue) {
V result = get(key);
return (null == result) ? defaultValue : result;
}
@SuppressWarnings("unchecked")
@Override
public synchronized void forEach(BiConsumer<? super K, ? super V> action) {
Objects.requireNonNull(action);
final int expectedModCount = modCount;
Entry<?, ?>[] tab = table;
for (Entry<?, ?> entry : tab) {//全部遍历
while (entry != null) {
action.accept((K)entry.key, (V)entry.value);
entry = entry.next;
if (expectedModCount != modCount) {
throw new ConcurrentModificationException();
}
}
}
}
@SuppressWarnings("unchecked")
@Override
public synchronized void replaceAll(BiFunction<? super K, ? super V, ? extends V> function) {
Objects.requireNonNull(function);
final int expectedModCount = modCount;
Entry<K, V>[] tab = (Entry<K, V>[])table;
for (Entry<K, V> entry : tab) {
while (entry != null) {
entry.value = Objects.requireNonNull(function.apply(entry.key, entry.value));
entry = entry.next;
if (expectedModCount != modCount) {
throw new ConcurrentModificationException();
}
}
}
}
@SuppressWarnings("unchecked")
@Override
public synchronized V putIfAbsent(K key, V value) {
Objects.requireNonNull(value);
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
Entry<K,V> entry = (Entry<K,V>)tab[index];
for (; entry != null; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
if (old == null) {
entry.value = value;
}
return old;
}
}
addEntry(hash, key, value, index);
return null;
}
@Override
public synchronized boolean remove(Object key, Object value) {
Objects.requireNonNull(value);
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>)tab[index];
for (Entry<K,V> prev = null; e != null; prev = e, e = e.next) {
if ((e.hash == hash) && e.key.equals(key) && e.value.equals(value)) {
modCount++;
if (prev != null) {
prev.next = e.next;
} else {
tab[index] = e.next;
}
count--;
e.value = null;
return true;
}
}
return false;
}
@Override
public synchronized boolean replace(K key, V oldValue, V newValue) {
Objects.requireNonNull(oldValue);
Objects.requireNonNull(newValue);
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>)tab[index];
for (; e != null; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
if (e.value.equals(oldValue)) {
e.value = newValue;
return true;
} else {
return false;
}
}
}
return false;
}
@Override
public synchronized V replace(K key, V value) {
Objects.requireNonNull(value);
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>)tab[index];
for (; e != null; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
V oldValue = e.value;
e.value = value;
return oldValue;
}
}
return null;
}
@Override
public synchronized V computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction) {
Objects.requireNonNull(mappingFunction);
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>)tab[index];
for (; e != null; e = e.next) {
if (e.hash == hash && e.key.equals(key)) {
return e.value;
}
}
V newValue = mappingFunction.apply(key);
if (newValue != null) {
addEntry(hash, key, newValue, index);
}
return newValue;
}
@Override
public synchronized V computeIfPresent(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction) {
Objects.requireNonNull(remappingFunction);
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>)tab[index];
for (Entry<K,V> prev = null; e != null; prev = e, e = e.next) {
if (e.hash == hash && e.key.equals(key)) {
V newValue = remappingFunction.apply(key, e.value);
if (newValue == null) {
modCount++;
if (prev != null) {
prev.next = e.next;
} else {
tab[index] = e.next;
}
count--;
} else {
e.value = newValue;
}
return newValue;
}
}
return null;
}
@Override
public synchronized V compute(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction) {
Objects.requireNonNull(remappingFunction);
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>)tab[index];
for (Entry<K,V> prev = null; e != null; prev = e, e = e.next) {
if (e.hash == hash && Objects.equals(e.key, key)) {
V newValue = remappingFunction.apply(key, e.value);
if (newValue == null) {
modCount++;
if (prev != null) {
prev.next = e.next;
} else {
tab[index] = e.next;
}
count--;
} else {
e.value = newValue;
}
return newValue;
}
}
V newValue = remappingFunction.apply(key, null);
if (newValue != null) {
addEntry(hash, key, newValue, index);
}
return newValue;
}
@Override
public synchronized V merge(K key, V value, BiFunction<? super V, ? super V, ? extends V> remappingFunction) {
Objects.requireNonNull(remappingFunction);
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>)tab[index];
for (Entry<K,V> prev = null; e != null; prev = e, e = e.next) {
if (e.hash == hash && e.key.equals(key)) {
V newValue = remappingFunction.apply(e.value, value);
if (newValue == null) {
modCount++;
if (prev != null) {
prev.next = e.next;
} else {
tab[index] = e.next;
}
count--;
} else {
e.value = newValue;
}
return newValue;
}
}
if (value != null) {
addEntry(hash, key, value, index);
}
return value;
}
//链表元素
public static class Entry<K,V> implements Map1.Entry<K,V> {
public final int hash;
public final K key;
public V value;
public Entry<K,V> next;
public Entry(int hash, K key, V value, Entry<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
@SuppressWarnings("unchecked")
public Object clone() {//super.clone()地址是一样的,new就不一样了。
return new Entry<>(hash, key, value, (next==null ? null : (Entry<K,V>) next.clone()));
}
public K getKey() {
return key;
}
public V getValue() {
return value;
}
public V setValue(V value) {
if (value == null)
throw new NullPointerException();
V oldValue = this.value;
this.value = value;
return oldValue;
}
public boolean equals(Object o) {
if (!(o instanceof Map1.Entry))
return false;
Map1.Entry<?,?> e = (Map1.Entry<?,?>)o;
return (key==null ? e.getKey()==null : key.equals(e.getKey())) &&
(value==null ? e.getValue()==null : value.equals(e.getValue()));
}
public int hashCode() {
return hash ^ Objects.hashCode(value);
}
public String toString() {
return key.toString()+"="+value.toString();
}
}
private static final int KEYS = ;
private static final int VALUES = ;
private static final int ENTRIES = ;
public class Enumerator<T> implements Enumeration<T>, Iterator<T> {
Entry<?,?>[] table = Hashtable1.this.table;
int index = table.length;//从后往前
Entry<?,?> entry;//next
Entry<?,?> lastReturned;//prev
int type;//0是keys,1是values,2是Entry。
//true是迭代,false是枚举
boolean iterator;
protected int expectedModCount = modCount;
Enumerator(int type, boolean iterator) {//6种组合
this.type = type;//0是keys,1是values,2是Entry。
this.iterator = iterator;//true返回迭代器Iterator,false返回枚举器
}
public boolean hasMoreElements() {
Entry<?,?> e = entry;//初始化entry=null
int i = index;//index=length
Entry<?,?>[] t = table;
/* 使用局部变量加快循环迭代 */
while (e == null && i > ) {
e = t[--i];//从数组从后往前找,找到第一个不为null的,初始化。到了链表末尾查找下一个不为null的。
}
entry = e;//下次要返回的
index = i;//下次要返回的索引
return e != null;
}
@SuppressWarnings("unchecked")
public T nextElement() {
Entry<?,?> et = entry;
int i = index;
Entry<?,?>[] t = table;
/* 使用局部变量加快循环迭代 */
while (et == null && i > ) {
et = t[--i];//进不来
}
entry = et;
index = i;
if (et != null) {
Entry<?,?> e = lastReturned = entry;
entry = e.next;//链表下一个
return type == KEYS ? (T)e.key : (type == VALUES ? (T)e.value : (T)e);
}
throw new NoSuchElementException("Hashtable Enumerator");
}
int m = ;
public boolean hasNext() {
return /* m-->0; */hasMoreElements();
}
public T next() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
return /* (T) new Integer(888); */nextElement();
}
public void remove() {
if (!iterator)//枚举不能删除,迭代器可以删除。
throw new UnsupportedOperationException();
if (lastReturned == null)
throw new IllegalStateException("Hashtable Enumerator");
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
synchronized(Hashtable1.this) {
Entry<?,?>[] tab = Hashtable1.this.table;
int index = (lastReturned.hash & 0x7FFFFFFF) % tab.length;//删除lastReturned节点
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>)tab[index];
for(Entry<K,V> prev = null; e != null; prev = e, e = e.next) {
if (e == lastReturned) {
modCount++;
expectedModCount++;
if (prev == null)
tab[index] = e.next;
else
prev.next = e.next;
count--;
lastReturned = null;
return;
}
}
throw new ConcurrentModificationException();
}
}
}
}
HashTable源码的更多相关文章
- JAVA的HashTable源码分析
Hashtable简介 Hashtable同样是基于哈希表实现的,同样每个元素是一个key-value对,其内部也是通过单链表解决冲突问题,容量不足(超过了阀值)时,同样会自动增长.Hashtable ...
- 转:【Java集合源码剖析】Hashtable源码剖析
转载请注明出处:http://blog.csdn.net/ns_code/article/details/36191279 Hashtable简介 Hashtable同样是基于哈希表实现的,同样每个元 ...
- [Java] Hashtable 源码简要分析
Hashtable /HashMap / LinkedHashMap 概述 * Hashtable比较早,是线程安全的哈希映射表.内部采用Entry[]数组,每个Entry均可作为链表的头,用来解决冲 ...
- 【Java集合源码剖析】Hashtable源码剖析
转载出处:http://blog.csdn.net/ns_code/article/details/36191279 Hashtable简介 Hashtable同样是基于哈希表实现的,同样每个元素是一 ...
- 并发-HashMap和HashTable源码分析
HashMap和HashTable源码分析 参考: https://blog.csdn.net/luanlouis/article/details/41576373 http://www.cnblog ...
- Hashtable源码剖析
Hashtable简介 Hashtable同样是基于哈希表实现的,同样每个元素是一个key-value对,其内部也是通过单链表解决冲突问题,容量不足(超过了阀值)时,同样会自动增长. Hashtabl ...
- Java入门系列之集合Hashtable源码分析(十一)
前言 上一节我们实现了散列算法并对冲突解决我们使用了开放地址法和链地址法两种方式,本节我们来详细分析源码,看看源码中对于冲突是使用的哪一种方式以及对比我们所实现的,有哪些可以进行改造的地方. Hash ...
- 史上最简单的的HashTable源码分析
HashTable源码分析 1.前言 Hashtable 一个元老级的集合类,早在 JDK 1.0 就诞生了 1.1.摘要 在集合系列的第一章,咱们了解到,Map 的实现类有 HashMap.Link ...
- Java集合专题总结(1):HashMap 和 HashTable 源码学习和面试总结
2017年的秋招彻底结束了,感觉Java上面的最常见的集合相关的问题就是hash--系列和一些常用并发集合和队列,堆等结合算法一起考察,不完全统计,本人经历:先后百度.唯品会.58同城.新浪微博.趣分 ...
- HashTable源码阅读
环境jdk1.8.0_121 与HashMap有几点区别 在HashMap中,冲突的值会在bucket形成链表,当达到8个,会形成红黑树,而在HashTable中,冲突的值就以链表的形式存储 publ ...
随机推荐
- Markdown温故知新(1):Markdown面面观
1.什么是 Markdown? 2.有哪些人在用 Markdown? 3.用 Markdown 的优势是什么? 4.Markdown 的语法标准简介 5.怎么用 Markdown? 6.如何选择 Ma ...
- php xdebug的配置、调试、跟踪、调优、分析
xdebug 的 profiler 是一个强大的工具,它能分析 PHP 代码,探测瓶颈,或者通常意义上来说查看哪部分代码运行缓慢以及可以使用速度提升.Xdebug 2 分析器输出一种兼容 cacheg ...
- Haskell路线
@ 知乎 @ <I wish i have learned haskell> ———— 包括: Ranks, forall, Monad/CPS, monadic parser, FFI ...
- pom.xml管理jar包——安全性框架配置文件
<properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> &l ...
- 基于vue+springboot+docker网站搭建【七】制作后端spring-boot的docker镜像部署
制作spring-boot的docker镜像并部署 一.下载后端项目:https://github.com/macrozheng/mall 二.修改mall-admin项目的配置文件 修改applic ...
- python数据分析三剑客之: matplotlib绘图模块
matplotlib 一.Matplotlib基础知识 Matplotlib中的基本图表包括的元素 - x轴和y轴 axis 水平和垂直的轴线 - x轴和y轴刻度 tick 刻度标示坐标轴的分隔,包括 ...
- Flask中before_request与after_request使用
目录 1.前提,装饰器的弊端 2.before_request与after_request 2.1 before_request分析: 2.2 after_request分析: 3.before_re ...
- postgresql设置max_connections太大无法启动 (转载)
本篇随笔转载自https://my.oschina.net/u/2381678/blog/552346. 在生产环境postgresql中,需要调整最大链接数,但是调整后无法启动 错误的意思就是内核中 ...
- PHP获取当前服务器版本,Ip等详细信息
1. 服务器IP地址 $_SERVER['SERVER_ADDR'] 服务器域名 $_SERVER['SERVER_NAME'] 服务器端口 $_SERVER['SERVER_PORT'] 服务器版本 ...
- linux 挂载磁盘LVM
最近又有个坑逼任务: 在客户给的三台虚拟机上在安装集群环境,,虚拟机没挂载磁盘 要配置成LV卷:大致理解逻辑之后理解为:LV卷后续方便做扩容 理论参考:https://www.cnblogs.com/ ...