Android-----解析xml文件的三种方式
SAX解析方法介绍:
SAX(Simple API for XML)是一个解析速度快并且占用内存少的XML解析器,非常适合用于Android等移动设备。SAX解析XML文件采用的是事件驱动,也就是说,它并不需要解析完整个文档,在按内容顺序解析文档的过程中,SAX会判断当前读到的字符是否合法XML语法中的某部分,如果符合就会触发事件。所谓事件,其实就是一些回调(callback)方法,这些方法(事件)定义在ContentHandler接口。
Pull解析器:
Pull解析是一个while循环,随时可以跳出。Pull解析器的工作方式为允许你的应用程序代码主动从解析器中获取事件,因此可以在满足了需要的条件后不再获取事件,结束解析工作。
DOM解析:
DOM解析XML文件时,会将XML的所有内容读取到内存中,然后允许您使用DOM API遍历XML树、检索所需的数据。因为DOM需要将所有内容读取到内存中,所以内存的消耗比较大,不建议使用DOM解析XML文件,若文件较小可行。
首先新建一个xml文件,放在res/raw目录下,没有raw目录则新建一个。
要解析的itcase.xml内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<persons>
<person id="">
<name>liming</name>
<age></age>
</person>
<person id="">
<name>lixiang</name>
<age></age>
</person>
</persons>
新建一个类存放解析的内容
Person.java如下:
public class Person {
private int id;
private String name;
private int age;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
以上所需要的准备好了,就开始解析xml工作:
首先是SAX解析:
新建一个 XMLContentHandler.java文件内容如下:
public class XMLContentHandler extends DefaultHandler{
private List<Person> persons = null;
private Person currentPerson;
private String tagName = null;//当前解析的元素标签
public List<Person> getPersons() {
return persons;
}
@Override/**【文档开始时,调用此方法】**/
public void startDocument() throws SAXException {
persons = new ArrayList<>();
}
@Override/**【标签开始时,调用此方法】**/
/**【uri是命名空间|localName是不带命名空间前缀的标签名|qName是带命名空间前缀的标签名|attributes可以得到所有的属性名和对应的值】**/
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
if (localName.equals("person")) {
currentPerson = new Person();
currentPerson.setId(Integer.parseInt(attributes.getValue("id")));
}
this.tagName = localName;
}
@Override/**【接收标签中字符数据时,调用此方法】**/
/**【ch存放标签中的内容,start是起始位置,length是内容长度】**/
public void characters(char[] ch, int start, int length) throws SAXException {
if (tagName != null) {
String data = new String(ch, start, length);
if (tagName.equals("name")) {
this.currentPerson.setName(data);
} else if (tagName.equals("age")) {
this.currentPerson.setAge(Short.parseShort(data));
}
}
}
@Override/**【标签结束时,调用此方法】**/
/**【localName表示元素本地名称(不带前缀),qName表示元素的限定名(带前缀)】**/
public void endElement(String uri, String localName, String qName) throws SAXException {
if (localName.equals("person")) {
persons.add(currentPerson);
currentPerson = null;
}
this.tagName = null;
}
}
新建一个调用XMLContentHandler中方法的XMLParsingMethods.java类,内容如下:
public class XMLParsingMethods {
/**【SAX解析XML文件】**/
public static List<Person> readXmlBySAX(InputStream inputStream) {
try {
/**【创建解析器】**/
SAXParserFactory spf = SAXParserFactory.newInstance();
SAXParser saxParser = spf.newSAXParser();
XMLContentHandler handler = new XMLContentHandler();
saxParser.parse(inputStream, handler);
inputStream.close();
return handler.getPersons();
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}
到这里,SAX解析XML文件工作已经完成了,调用XMLPersingMethods中的readXmlBySAX就可以解析itcase.xml文件。在这里就先不调用,把三种的解析方法讲完再一并调用。
DOM解析XML文件:直接在XMLPersingMethods中添加解析方法
public class XMLParsingMethods {
/**【SAX解析XML文件】**/
public static List<Person> readXmlBySAX(InputStream inputStream) {
......
}
/**【DOM解析XML文件】**/
public static List<Person> readXmlByDOM(InputStream inputStream){
List<Person> persons = new ArrayList<>();
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
try {
DocumentBuilder builder = factory.newDocumentBuilder();
Document dom = builder.parse(inputStream);
Element root = dom.getDocumentElement();
/**【查找所有person节点】**/
NodeList items = root.getElementsByTagName("person");
for (int i = ; i < items.getLength(); i++) {
Person person = new Person();
/**【得到第一个person的节点】**/
Element personNode = (Element) items.item(i);
/**【获取person节点的id属性】**/
person.setId(new Integer(personNode.getAttribute("id")));
/**【获取person节点下的所有子节点(标签之间的空白节点和name/age节点)】**/
NodeList childsNodes = personNode.getChildNodes();
/**【遍历所有子节点】**/
for (int j = ; j < childsNodes.getLength(); j++) {
Node node = (Node) childsNodes.item(j);
/**【判断是否为元素类型】**/
if(node.getNodeType() == Node.ELEMENT_NODE){
Element childNode = (Element) node;
/**【判断是否是name元素】**/
if ("name".equals(childNode.getNodeName())) {
/**【获取name元素下的text节点,然后从text节点获取数据】**/
person.setName(childNode.getFirstChild().getNodeValue());
/**【判断是否是age元素】**/
}else if("age".equals(childNode.getNodeName())){
/**【获取age元素下的text节点,然后从text节点获取数据】**/
person.setAge(new Short(childNode.getFirstChild().getNodeValue()));
}
}
}
persons.add(person);
}
inputStream.close();
} catch (Exception e) {
e.printStackTrace();
}
return persons;
}
}
至此,DOM解析XML文件工作也已经完成了。
Pull解析器解析XML文件:
public class XMLParsingMethods {
/**【SAX解析XML文件】**/
public static List<Person> readXmlBySAX(InputStream inputStream) {
......
}
/**【DOM解析XML文件】**/
public static List<Person> readXmlByDOM(InputStream inputStream){
......
}
/**【Pull解析器解析XML文件】**/
public static List<Person> readXmlByPull(InputStream inputStream){
XmlPullParser parser = Xml.newPullParser();
try {
parser.setInput(inputStream,"UTF-8");
int eventType = parser.getEventType();
Person currenPerson = null;
List<Person> persons = null;
while(eventType != XmlPullParser.END_DOCUMENT){
switch (eventType){
case XmlPullParser.START_DOCUMENT:/**【文档开始事件】**/
persons = new ArrayList<>();
break;
case XmlPullParser.START_TAG:/**【元素(即标签)开始事件】**/
String name = parser.getName();
if(name.equals("person")){
currenPerson = new Person();
currenPerson.setId(new Integer(parser.getAttributeValue(null,"id")));
}else if(currenPerson !=null){
if(name.equals("name")){/**【判断标签名(元素名)是否为name】**/
currenPerson.setName(parser.nextText());/**【如果后面是text元素,即返回它的值】**/
}else if(name.equals("age")){
currenPerson.setAge(new Integer(parser.nextText()));
}
}
break;
case XmlPullParser.END_TAG:/**【元素结束事件】**/
if(parser.getName().equalsIgnoreCase("person") && currenPerson != null){
persons.add(currenPerson);
currenPerson = null;
}
break;
}
eventType = parser.next();
}
inputStream.close();
return persons;
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}
至此,SAX、DOM、Pull三种解析XML文件准备好了,接下来分别调用方法:
布局文件:
<?xml version="1.0" encoding="utf-8"?>
<LinearLayout
xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:orientation="vertical"
tools:context="com.hs.example.exampleapplication.PersonXML"> <TextView
android:id="@+id/data"
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:textSize="20sp"
android:text="Xml数据:"/> <Button
android:id="@+id/btn_read"
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:textSize="25sp"
android:text="解析XML文件"/> </LinearLayout>
方法调用:
public class PersonXML extends AppCompatActivity implements View.OnClickListener{
Button btn_read;
TextView data ;
List<Person> personList = null;
InputStream inputStream;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_personxml);
btn_read = this.findViewById(R.id.btn_read);
btn_read.setOnClickListener(this);
data = this.findViewById(R.id.data);
personList = new ArrayList<>();
}
@Override
public void onClick(View view) {
switch (view.getId()){
case R.id.btn_read:
String result = "";
inputStream = getResources().openRawResource(R.raw.itcase);
if(inputStream == null){
Toast.makeText(this,"InputStream is null",Toast.LENGTH_SHORT).show();
}else{
personList = XMLParsingMethods.readXmlByPull(inputStream); //调用Pull
//personList = XMLParsingMethods.readXmlBySAX(inputStream);//调用SAX
//personList = XMLParsingMethods.readXmlByDOM(inputStream);//调用DOM
if(personList!=null){
for(int i = ;i <personList.size();i++){
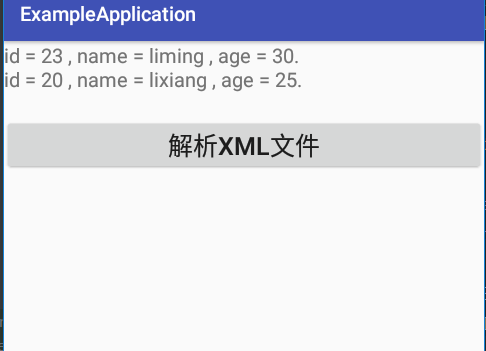
String message = "id = " + personList.get(i).getId() + " , name = " + personList.get(i).getName()
+ " , age = " + personList.get(i).getAge() + ".\n";
result += message;
}
}else{
Toast.makeText(this,"persons is null",Toast.LENGTH_SHORT).show();
}
data.setText(result);
XMLParsingMethods.createXmlFile(personList);//这里是接下来使用Pull解析器生成XML文件的方法调用
}
break;
}
}
}
运行效果:
顺道讲下使用Pull解析器生成XML文件:
public class XMLParsingMethods {
/**【SAX解析XML文件】**/
public static List<Person> readXmlBySAX(InputStream inputStream) {
......
}
/**【DOM解析XML文件】**/
public static List<Person> readXmlByDOM(InputStream inputStream){
......
}
/**【Pull解析器解析XML文件】**/
public static List<Person> readXmlByPull(InputStream inputStream){
......
}
/**【使用Pull解析器生成XML文件内容】**/
public static String WriteXML(List<Person> persons,Writer writer ){
XmlSerializer serializer = Xml.newSerializer();
try {
serializer.setOutput(writer);
serializer.startDocument("UTF-8",true);
/**【第一个参数为命名空间,不使用命名空间可以设置为null】**/
serializer.startTag("","persons");
/**【XML文件中要生成的内容】**/
for(Person person : persons){
serializer.startTag("","person");
serializer.attribute("", "id", String.valueOf(person.getId()) );
serializer.startTag("","name");
serializer.text(person.getName());
serializer.endTag("","name");
serializer.startTag("","age");
serializer.text(String.valueOf(person.getAge()));
serializer.endTag("","age");
serializer.endTag("","person");
}
serializer.endTag("","persons");
serializer.endDocument();
return writer.toString();
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
/**【生成XML文件代码】**/
public static void createXmlFile(List<Person> persons){
if(Environment.getExternalStorageState().equals(Environment.MEDIA_MOUNTED)){
try {
File sdCard = Environment.getExternalStorageDirectory();
File xmlFile = new File(sdCard + File.separator + "testFolder/" + "myitcast.xml");
FileOutputStream outStream = new FileOutputStream(xmlFile);
OutputStreamWriter outputStreamWriter = new OutputStreamWriter(outStream , "UTF-8");
BufferedWriter writerFile = new BufferedWriter(outputStreamWriter);
WriteXML(persons,writerFile);
writerFile.flush();
writerFile.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
运行后:
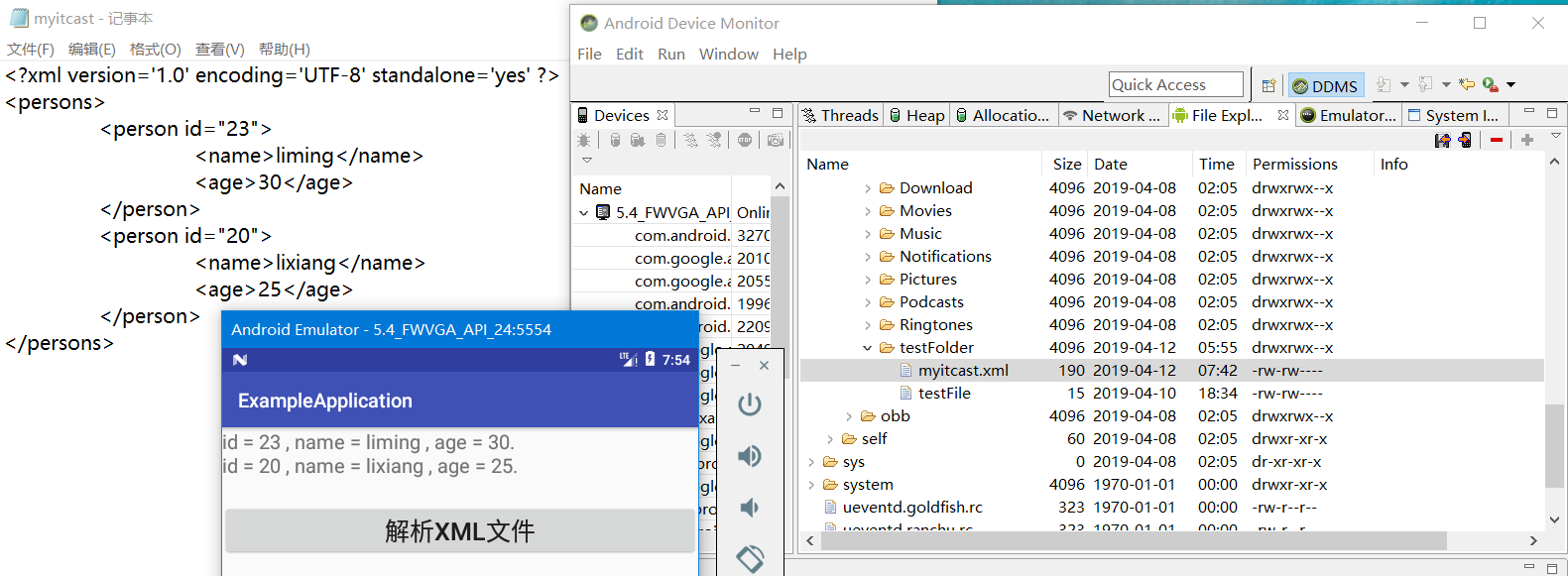
新建文件要先获得文件操作系统权限,推荐文章:https://blog.csdn.net/weixin_44001878/article/details/89520246
以上内容参考于:https://www.open-open.com/lib/view/open1392780226397.html
Android-----解析xml文件的三种方式的更多相关文章
- 解析Xml文件的三种方式及其特点
解析Xml文件的三种方式 1.Sax解析(simple api for xml) 使用流式处理的方式,它并不记录所读内容的相关信息.它是一种以事件为驱动的XML API,解析速度快,占用内存少.使用 ...
- 解析Xml文件的三种方式
1.Sax解析(simple api for xml) 使用流式处理的方式,它并不记录所读内容的相关信息.它是一种以事件为驱动的XML API,解析速度快,占用内存少.使用回调函数来实现. clas ...
- 解析xml文件的四种方式
什么是 XML? XML 指可扩展标记语言(EXtensible Markup Language) XML 是一种标记语言,很类似 HTML XML 的设计宗旨是传输数据,而非显示数据 XML 标签没 ...
- 解析XML文件的几种方式及其比较
解析xml文件目前比较流行的主要有四种方式: 1. DOM(Document Object Model)它把整个XML文档当成一个对象加载到内 存,不管文档有多大.它一般处理小文件 2.SAX(Si ...
- android中解析文件的三种方式
android中解析文件的三种方式 好久没有动手写点东西了,最近在研究android的相关技术,现在就android中解析文件的三种方式做以下总结.其主要有:SAX(Simple API fo ...
- android解析xml文件的方式
android解析xml文件的方式 作者:东子哥 ,发布于2012-11-26,来源:博客园 在androd手机中处理xml数据时很常见的事情,通常在不同平台传输数据的时候,我们就可能使用xm ...
- 解析XML文件的几种常见操作方法—DOM/SAX/DOM4j
解析XML文件的几种常见操作方法—DOM/SAX/DOM4j 一直想学点什么东西,有些浮躁,努力使自己静下心来看点东西,哪怕是回顾一下知识.看到了xml解析,目前我还没用到过.但多了解一下,加深点记忆 ...
- java读取XML文件的四种方式
java读取XML文件的四种方式 Xml代码 <?xml version="1.0" encoding="GB2312"?> <RESULT& ...
- Velocity中加载vm文件的三种方式
Velocity中加载vm文件的三种方式: a. 加载classpath目录下的vm文件 /** * 初始化Velocity引擎 * --VelocityEngine是单例模式,线程安全 * @th ...
随机推荐
- zzulioj - 2558 数字的差值
首先感谢抱抱熊dalao的题解,提供了一种比较简单的思路.[抱抱熊dalao的题解](https://note.youdao.com/ynoteshare1/index.html?id=52f087d ...
- Chrome DevTools的使用
一.Chrome DevTools 简介 Chrome 开发者工具是一套内置于Google Chrome中的Web开发和调试工具,可用来对网站进行迭代.调试和分析 手册:Chrome 开发者工具中文手 ...
- java登录图形界面
编写程序,利用JtextField和JpasswordField分别接收用户输入的用户名和密码,并对用户输入的密码进行检验.对于每个用户名有三次密码输入机会. package beizi; impor ...
- SQL数据同步到ELK(四)- 利用SQL SERVER Track Data相关功能同步数据(上)
一.相关文档 老规矩,为了避免我的解释误导大家,请大家务必通过官网了解一波SQL SERVER的相关功能. 文档地址: 整体介绍文档:https://docs.microsoft.com/en-us/ ...
- eclipse.ini相关问题
一般新装的eclipse,在eclipse.ini文件中,有设置默认的内存信息,如果你要开发一个大的项目或者导入大的项目,那么,eclipse就会时不时报出这样的错误:An internal erro ...
- thinkphp5用了哪些设计模式
一.设计模式简介 首先我们来认识一下什么是设计模式:设计模式是一套被反复使用.容易被他人理解的.可靠的代码设计经验的总结.设计模式不是Java的专利,我们用面向对象的方法在PHP里也能很好的使用23种 ...
- 014 Vue学习笔记2
1.组件化 在大型应用开发的时候,页面可以划分成很多部分.往往不同的页面,也会有相同的部分.例如可能会有相同的头部导航.但是如果每个页面都独自开发,这无疑增加了我们开发的成本.所以我们会把页面的不同部 ...
- 拦截器配置类使用继承写法导致jackson的全局配置失效
问题描述 项目中需要一个拦截器用于拦截请求,在没有请求中生成requestId.然后写了一个配置类,这个类继承了 WebMvcConfigurationSupport类,重写了addIntercept ...
- 【chromium】 渲染显示相关概念
DRM(Direct Rendering Manager) DRM 由两个部分组成:一是 Kernel 的子系统,这个子系统对硬件 GPU 操作进行了一层框架封装.二是提供了一个 libdrm 库,里 ...
- 算法设计与分析(李春保)练习题答案v1
1.1第1 章─概论 1.1.1练习题 1.下列关于算法的说法中正确的有(). Ⅰ.求解某一类问题的算法是唯一的 Ⅱ.算法必须在有限步操作之后停止 Ⅲ.算法的每一步操作必须是明确的,不能有歧义或含义模 ...