分布式并行计算MapReduce
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3319
1.用自己的话阐明Hadoop平台上HDFS和MapReduce的功能、工作原理和工作过程。
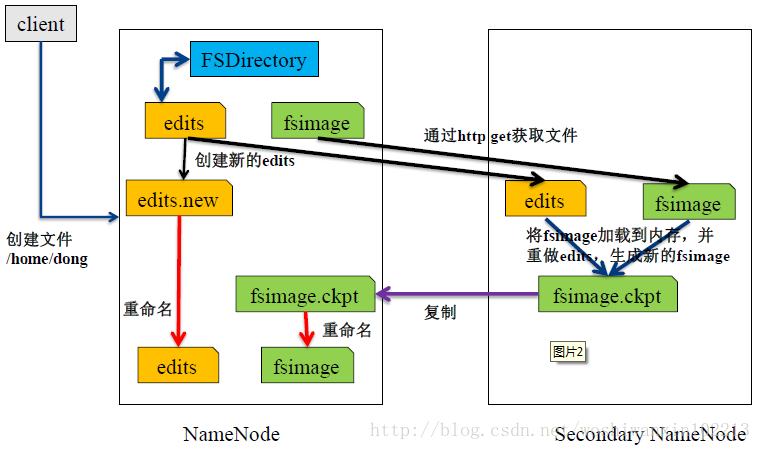
HDFS(Hadoop Distributed File System,Hadoop分布式文件系统),它是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,适合那些有着超大数据集(large data set)的应用程序。
易于扩展的分布式文件系统
运行在大量普通廉价机器上,提供容错机制
为大量用户提供性能不错的文件存取服务
MapReduce是并行处理框架,实现任务分解和调度。
其实原理说通俗一点就是分而治之的思想,将一个大任务分解成多个小任务(map),小任务执行完了之后,合并计算结果(reduce)。
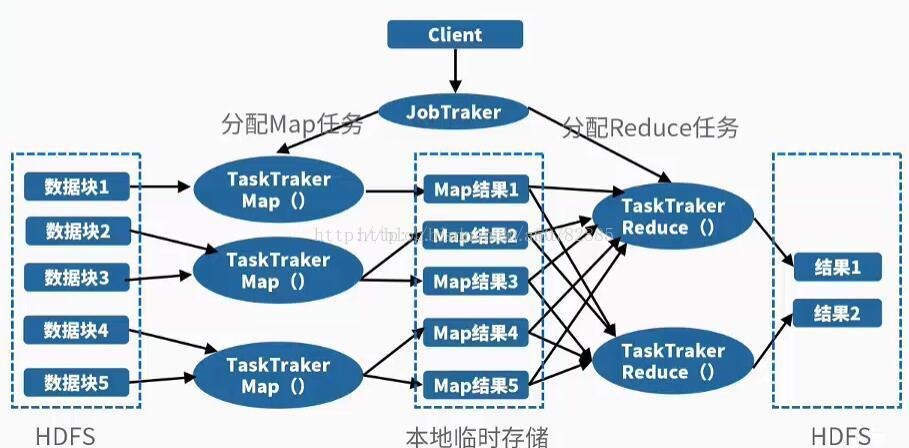
也就是说,JobTracker拿到job之后,会把job分成很多个maptask和reducetask,交给他们执行。 MapTask、ReduceTask函数的输入、输出都是<key,value>的形式。HDFS存储的输入数据经过解析后,以键值对的形式,输入到MapReduce()函数中进行处理,输出一系列键值对作为中间结果,在Reduce阶段,对拥有同样Key值的中间数据进行合并形成最后结果。
2.HDFS上运行MapReduce
1)查看是否已经安装python:
1)准备文本文件,放在本地/home/hadoop/wc

2)编写map函数和reduce函数,在本地运行测试通过


3)启动Hadoop:HDFS, JobTracker, TaskTracker
4)把文本文件上传到hdfs文件系统上 user/hadoop/input

5)streaming的jar文件的路径写入环境变量,让环境变量生效

6)source run.sh来执行mapreduce

分布式并行计算MapReduce的更多相关文章
- 作业——11 分布式并行计算MapReduce
作业的要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3319 1.用自己的话阐明Hadoop平台上HDFS和MapRedu ...
- 【大数据】分布式并行计算MapReduce
作业来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3319 1. 用自己的话阐明Hadoop平台上HDFS和MapReduc ...
- 【大数据作业十一】分布式并行计算MapReduce
作业要求:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3319 1.用自己的话阐明Hadoop平台上HDFS和MapReduce的功 ...
- 【大数据应用技术】作业十一|分布式并行计算MapReduce
本次作业在要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3319 1.用自己的话阐明Hadoop平台上HDFS和MapRe ...
- Hadoop平台K-Means聚类算法分布式实现+MapReduce通俗讲解
Hadoop平台K-Means聚类算法分布式实现+MapReduce通俗讲解 在Hadoop分布式环境下实现K-Means聚类算法的伪代码如下: 输入:参数0--存储样本数据的文本文件inpu ...
- #研发解决方案#分布式并行计算调度和管理系统Summoner
郑昀 创建于2015/11/10 最后更新于2015/11/12 关键词:佣金计算.定时任务.数据抽取.数据清洗.数据计算.Java.Redis.MySQL.Zookeeper.azkaban2.oo ...
- 利用 MessageRPC 和 ShareMemory 来实现 分布式并行计算
可以利用 MessageRPC + ShareMemory 来实现 分布式并行计算 . MessageRPC : https://www.cnblogs.com/KSongKing/p/945541 ...
- hadoop基础----hadoop理论(四)-----hadoop分布式并行计算模型MapReduce具体解释
我们在前一章已经学习了HDFS: hadoop基础----hadoop理论(三)-----hadoop分布式文件系统HDFS详细解释 我们已经知道Hadoop=HDFS(文件系统,数据存储技术相关)+ ...
- cdh版本的hadoop安装及配置(伪分布式模式) MapReduce配置 yarn配置
安装hadoop需要jdk依赖,我这里是用jdk8 jdk版本:jdk1.8.0_151 hadoop版本:hadoop-2.5.0-cdh5.3.6 hadoop下载地址:链接:https://pa ...
随机推荐
- JavaScript原型链以及Object,Function之间的关系
JavaScript里任何东西都是对象,任何一个对象内部都有另一个对象叫__proto__,即原型,它可以包含任何东西让对象继承.当然__proto__本身也是一个对象,它自己也有自己的__proto ...
- 技术圈术语之LDAP
导语:阅读一些程序的文档时经常看到支持ldap,由于对这个协议不太熟悉,平时也没有用过,所以一直也没怎么留意,今天看rabbitmq的文档又发现了ldap相关的介绍,于是想把这个问题搞清楚. 一.LD ...
- SQL Server Profiler 跟踪某个数据库某张表sql语句
点击:事件选择 点击确定 点击确定 关键:选中显示所有事件.显示所有列,然后通过DatabaseName 筛选数据库名称为Ecology的数据库, TextData 筛选文本中包含表名T_Plant2 ...
- sqlserver数据,将一行某一列字符串的值用“_”分割分别填充到这一行的其他列
分割字符到列DECLARE @a VARCHAR(10)SET @a ='00G-2-1102'SELECT CHARINDEX('-',@a,CHARINDEX('-',@a))SELECT CHA ...
- LXC容器
1. LXC简述 Linux container是一种资源隔离机制而非虚拟化技术.VMM(VMM Virtual Machine Monitor)或者叫Hypervisor是标准的虚拟化技术,这 ...
- JAVA设计模式之工厂模式—Factory Pattern
1.工厂模式简介 工厂模式用于对象的创建,使得客户从具体的产品对象中被解耦. 2.工厂模式分类 这里以制造coffee的例子开始工厂模式设计之旅. 我们知道coffee只是一种泛举,在点购咖啡时需要指 ...
- 助教总结---继alpha版本1之后
本周心得: 在项目的开发当中,学生难免会有懈怠的时候,作为助教更应该去督促和激励同学们,但本质上该对自己负责任的是同学们自己.同学们项目的第一版本已经出来了,这个过程他们自己知道付出了多少,相信他们体 ...
- Codeforces G. Bus Number(dfs排列)
题目描述: Bus Number time limit per test 1 second memory limit per test 256 megabytes input standard inp ...
- centos7安装yum安装pip
pip是python中的一个包管理工具,可以对Python包的查找.下载.安装.卸载的作用. yum -y install epel-release yum -y install python-pip ...
- django-安装nginx及fastdfs-nginx-module
安装nginx及fastdfs-nginx-module 1. 解压缩 nginx-1.8.1.tar.gz 2. 解压缩 fastdfs-nginx-module-master.zip 3. 进入n ...