NLP之概率图模型
1.概率图模型
概率图模型是一类用图来表达变量相关关系的概率模型,它以图为表示工具,最常见的是用一个结点表示一个或一组随机变量,结点之间的边表示变量间的概率相关关系。概率图模型可大致分为两类:第一类是使用有向无环图表示变量间的依赖关系,称为有向图模型或贝叶斯网,第二类是使用无向图表示变量间的相关关系,称为无向图模型或马尔科夫网。
2.马尔科夫系列
马尔科夫过程和马尔科夫链:
马尔科夫过程:随机过程中,有一类具有“无后效性性质”,即当随机过程在某一时刻to所处的状态已知的条件下,过程在时刻t>to时所处的状态只和to时刻有关,而与to以前的状态无关,(此性质称为马尔可夫性)则这种随机过程称为马尔科夫过程. 即是:ito为已知,it(t>to)只与ito有关,这种性质为无后效性,又叫马尔科夫假设.
马尔科夫链:时间和状态都是离散的马尔科夫过程称为马尔科夫链。
马尔科夫链(注意它是一种随机过程)实际上就是一个随机变量随时间按照Markov性进行变化的过程。马尔可夫链就是这样一个任性的过程,它将来的状态分布只取决于现在,跟过去无关!
HMM中说到的马尔可夫链其实是指隐含状态链:系统下一刻的隐转态仅由当前隐状态决定,不依赖于以往的任何隐状态。
。(或者说系统的当前状态只依赖于它的前一个状态而与其它任何状态无关。)
总结:具备马尔科夫性的随机过程称为马尔科夫过程,时间和状态都是离散的马尔科夫过程是马尔科夫链。在马尔科夫过程中的无后效性(即为下一时刻的状态只与当前时刻相关,而与以往的任何状态无关)这个性质是马尔科夫性。同时提炼出的(当前时刻的状态只与前一时刻相关,而与以往的任何状态无关)称为马尔科夫假设(也叫齐次马尔科夫假设)。
3.联合概率P(X,Y)以及条件概率P(Y|X)
联合概率P(X,Y)是值x,y同时发生的概率

X=1,y=0同时发生的事件为2,占总事件4的1/2
4.生成式模型和判别式模型
具体可参考:
https://zhuanlan.zhihu.com/p/30941701
判别模型就是不学习数据的联合分布P(X,Y),直接判断求解P(Y|X)。而生成模型是需要求解数据的联合分布的,即先求出P(X,Y),进而生成要求解的P(Y|X)
判别模型是直接对P(Y|X)建模,就是说,直接根据X特征来对Y建模训练。
具体地,我的训练过程是确定构件P(Y|X)模型里面“复杂映射关系”中的参数,完了再去inference一批新的sample。
所以判别式模型的特征总结如下:
1)对P(Y|X)建模
2)对所有的样本只构建一个模型,确认总体判别边界
3)观测到输入什么特征,就预测最可能的label
4)另外,判别式的优点是:对数据量要求没生成式的严格,速度也会快,小数据量下准确率也会好些。
生成式模型是在训练阶段只对P(X,Y)建模,我需要确定维护这个联合概率分布的所有的信息参数。完了之后在inference再对新的sample计算P(Y|X),导出Y,但这已经不属于建模阶段了。
结合NB过一遍生成式模型的工作流程。学习阶段,建模:P(X,Y)=P(X|Y)P(Y),然后P(Y|X)=P(X,Y)/P(X)。
另外,LDA也是这样,只是他更过分,需要确定很多个概率分布,而且建模抽样都蛮复杂的。
所以生成式总结下有如下特点:
1)对P(X,Y)建模
2)这里我们主要讲分类问题,所以是要对每个label(yi)都需要建模,最终选择最优概率的label为结果,所以没有什么判别边界。(对于序列标注问题,那只需要构件一个model)
3)中间生成联合分布,并可生成采样数据。
4)生成式模型的优点在于,所包含的信息非常齐全,我称之为“上帝信息”,所以不仅可以用来输入label,还可以干其他的事情。生成式模型关注结果是如何产生的。但是生成式模型需要非常充足的数据量以保证采样到了数据本来的面目,所以速度相比之下,慢。
5.HMM模型简介
对于HMM的讲解推荐:https://www.cnblogs.com/skyme/p/4651331.html 结合案例讲解的很详细
隐马尔科夫模型(Hidden Markov Model,简称HMM):它是结构最简单的动态贝叶斯网,这是一种著名的有向图模型,同时它属于生成式模型,它是一个含有隐含未知参数的马尔可夫过程。主要用于时序分析,在语音识别,自然语言处理等领域应用广泛。
什么样的问题需要HMM模型?要具备如下特征。第一:我们的问题是基于序列的,比如时间序列,或状态序列。第二:我们的问题中有两类数据,一类序列数据是可以观测到的,即观测序列。另一类数据是不能观测到的,即隐藏状态序列,简称状态序列。
隐马尔科夫模型中的变量可分为两组,第一组是状态变量,通常假定状态变量是隐藏的、不可观测的,因此状态变量亦称隐变量,另一组是观测变量,xi表示第i时刻的观测值,隐马尔科夫模型中的箭头表示变量间的依赖关系。在任一时刻,观测变量的取值仅依赖于状态变量(即xt仅由yt确定)与其它状态变量及观测变量的取值无关。同时t时刻的状态yt仅依赖于t-1时刻的状态yt-1,与此前的t-2个状态无关。
HMM模型做了两个基本假设:
(1)齐次马尔可夫性假设:它假设任一时刻的隐状态只与其前一时刻的隐状态相关,而与其它任何时刻的隐状态以及观测状态无关。
(2)观测独立性假设:它假设任一时刻的观测状态只与当前时刻的隐状态相关,而与其它观测状态以及隐状态无关。
生成式模型要从训练数据中学到数据的各种分布,那么有哪些分布呢以及是什么呢?直接正面回答的话,正是HMM的5要素,其中有3个就是整个数据的不同角度的概率分布:

对于联合概率分布的求解转换为了两个条件概率的乘积(参考朴素贝叶斯模型,它也是基于联合概率分布的生成式模型,但是它根据条件概率分布P(Y|X)=P(X,Y)/P(X),把联合概率分布P(X,Y)转换为了求P(X|Y)*P(Y))
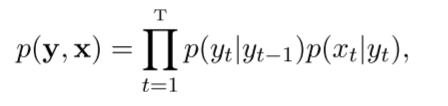
HMM需要确定初始状态概率向量,状态转移概率矩阵以及观测概率矩阵。例如jieba分词,这些向量都是基于大的语料库得到的。
6.HMM模型解决的三个问题
(1)概率计算问题:给定模型 和观测序列O=(o1,o2,..o3)计算在模型
和观测序列O=(o1,o2,..o3)计算在模型 下观测序列O出现的概率P(O|
下观测序列O出现的概率P(O| )
)
(2)学习问题:已知观测序列O=(o1,o2,..o3).,估计模型 参数,使得在该模型下观测序列概率P(O|
参数,使得在该模型下观测序列概率P(O| )最大.即用极大似然估计的方法估计参数
)最大.即用极大似然估计的方法估计参数
(3)解码问题:即给定观测序列,求最有可能的对应的状态序列。
7.CRF模型解析
详细可参考:https://www.cnblogs.com/pinard/category/894695.html
CRF模型是根据概率无向图模型的分解得来的。在序列标注任务中所用的CRF是指线性链CRF,它是一种无向图模型,属于一种马尔科夫网络(适合实体之间互相依赖的建模)。同时它是一种基于条件概率分布的判别式模型。它直接学习条件概率(直接学习给定一个观测序列X条件下Y发生的概率)。
在linear-CRF模型参数学习问题中,我们给定训练数据集X和对应的标记序列Y,K个特征函数fk(x,y),我们优化的目标是最大化条件概率Pw(y|x),以对数似然函数作为损失函数,通过梯度下降法求解模型参数wk。线性链CRF的参数化形式有特征函数和权重系数组成,得到了权重系数,这样在解码的时候,给定了观察数据就能通过维特比算法求得条件概率最大的标注序列。
定义:设X与Y是随机变量,P(Y|X)是给定条件X的条件下Y的条件概率分布,若随机变量Y构成一个由无向图G=(V,E)表示的马尔科夫随机场。则称条件概率分布P(Y|X)为条件随机场。
8、什么是随机场?什么是马尔科夫随机场?什么是条件随机场?
随机场是由若干个位置组成的整体,当给每一个位置中按照某种分布随机赋予一个值之后,其全体就叫做随机场。还是举词性标注的例子:假如我们有一个十个词形成的句子需要做词性标注。这十个词每个词的词性可以在我们已知的词性集合(名词,动词...)中去选择。当我们为每个词选择完词性后,这就形成了一个随机场。
马尔科夫随机场(Markov Random Field,简称MRF)是随机场的特例,它是一种典型的马尔科夫网,这是一种著名的无向图模型,图中的每一个结点表示一个或一组变量,结点之间的边表示两个变量之间的依赖关系。它假设随机场中某一个位置的赋值仅仅与和它相邻的位置的赋值有关,和与其不相邻的位置的赋值无关。继续举十个词的句子词性标注的例子:如果我们假设所有词的词性只和它相邻的词的词性有关时,这个随机场就特化成一个马尔科夫随机场。比如第三个词的词性除了与自己本身的位置有关外,只与第二个词和第四个词的词性有关。
CRF是马尔科夫随机场的特例,它假设马尔科夫随机场中只有X和Y两种变量,X一般是给定的,而Y一般是在给定X的条件下我们的输出。这样马尔科夫随机场就特化成了条件随机场。在我们十个词的句子词性标注的例子中,X是词,Y是词性。因此,如果我们假设它是一个马尔科夫随机场,那么它也就是一个CRF。
对于CRF,我们给出准确的数学语言描述:
设X与Y是随机变量,P(Y|X)是给定X时Y的条件概率分布,若随机变量Y构成的是一个马尔科夫随机场,则称条件概率分布P(Y|X)是条件随机场。
9.CRF解决的三个问题

第一个问题是用于对我们的建模是否正确给一个正确的评价。
10、HMM和CRF的区别
CRF并没有假定X,Y的结构相同,因此HMM和CRF的对比一般是HMM和线性CRF的对比。
HMM模型是一种有向图模型,liner-CRF是一种无向图模型。HMM是一种生成式模型,而CRF是一种判别式模型,也就是说HMM是基于X,Y的联合概率分布进行建模,而CRF是直接对X,Y的条件概率分布进行建模。CRF相比于HMM的优势在于HMM做出了观测独立性假设,这在现实中往往是不成立,而CRF并没有做出这种假设,使得CRFs能够使用复杂、有重叠性和非独立的特征进行训练和推理,能够充分地利用上下文信息作为特征,还可以任意地添加其他外部特征,使得模型能够获取的信息非常丰富。
11、维特比算法思路
维特比算法是通过动态规划来求解概率最大路径,已知观察序列,目的是求得整体概率最大的标记序列,所求得的为全局最优解。根据动态规划其最优子结构性质,求得整体概率最大的标记序列,那么每个部分的序列标注也必然最优。
维特比算法利用动态规划思想求解概率最大路径(可理解为求图最短路径问题), 其时间复杂度为O(N*L*L),其中N为观察者序列长度,L为隐含状态大小(对于每一个观察序列需要求其为每个隐含状态的概率为N*L,而在求其为各个隐含状态时需要求它从上一隐含状态转移过来的最大概率故为O(N*L*L))。该算法的核心思想是:通过综合状态之间的转移概率和前一个状态的情况计算出概率最大的状态转换路径,从而推断出隐含状态的序列的情况,即在每一步的所有选择都保存了前继所有步骤到当前步骤当前选择的最小总代价(或者最大价值)以及当前代价的情况下后续步骤的选择。依次计算完所有步骤后,通过回溯的方法找到最优选择路径。
NLP之概率图模型的更多相关文章
- 概率图模型学习笔记:HMM、MEMM、CRF
作者:Scofield链接:https://www.zhihu.com/question/35866596/answer/236886066来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商 ...
- 机器学习 —— 概率图模型(Homework: CRF Learning)
概率图模型的作业越往后变得越来越有趣了.当然,难度也是指数级别的上涨啊,以至于我用了两个周末才完成秋名山神秘车牌的寻找,啊不,CRF模型的训练. 条件随机场是一种强大的PGM,其可以对各种特征进行建模 ...
- 机器学习 —— 概率图模型(Homework: MCMC)
除了精确推理之外,我们还有非精确推理的手段来对概率图单个变量的分布进行求解.在很多情况下,概率图无法简化成团树,或者简化成团树后单个团中随机变量数目较多,会导致团树标定的效率低下.以图像分割为例,如果 ...
- 机器学习 —— 概率图模型(Homework: Exact Inference)
在前三周的作业中,我构造了概率图模型并调用第三方的求解器对器进行了求解,最终获得了每个随机变量的分布(有向图),最大后验分布(双向图).本周作业的主要内容就是自行编写概率图模型的求解器.实际上,从根本 ...
- 机器学习 —— 概率图模型(Homework: Representation)
前两周的作业主要是关于Factor以及有向图的构造,但是概率图模型中还有一种更强大的武器——双向图(无向图.Markov Network).与有向图不同,双向图可以描述两个var之间相互作用以及联系. ...
- 机器学习 —— 概率图模型(Homework: StructuredCPD)
Week2的作业主要是关于概率图模型的构造,主要任务可以分为两个部分:1.构造CPD;2.构造Graph.对于有向图而言,在获得单个节点的CPD之后就可依据图对Combine CPD进行构造.在获得C ...
- 机器学习 —— 概率图模型(Homework: Factors)
Talk is cheap, I show you the code 第一章的作业主要是关于PGM的因子操作.实际上,因子是整个概率图的核心.对于有向图而言,因子对应的是CPD(条件分布):对无向图而 ...
- 机器学习 —— 概率图模型(学习:CRF与MRF)
在概率图模型中,有一类很重要的模型称为条件随机场.这种模型广泛的应用于标签—样本(特征)对应问题.与MRF不同,CRF计算的是“条件概率”.故其表达式与MRF在分母上是不一样的. 如图所示,CRF只对 ...
- 概率图模型(PGM)学习笔记(四)-贝叶斯网络-伯努利贝叶斯-多项式贝叶斯
之前忘记强调了一个重要差别:条件概率链式法则和贝叶斯网络链式法则的差别 条件概率链式法则 贝叶斯网络链式法则,如图1 图1 乍一看非常easy认为贝叶斯网络链式法则不就是大家曾经学的链式法则么,事实上 ...
随机推荐
- Eureka服务注册中心错误:com.sun.jersey.api.client.ClientHandlerException: java.net.ConnectException: Connection refused: connect
报错信息 14:43:45.484 [main] INFO com.netflix.discovery.DiscoveryClient - Getting all instance registry ...
- TP5 使用验证码功能
工作中后台开发使用的是 TP5,但是对语法不是很熟悉,总是看着手册写代码.当时做 Java 的时候也是这样,很多语法需要靠百度.不是不能写代码,但是这样的效率感觉不高,没有行云流水的感觉,要是能有聊天 ...
- Algorithm: Permutation & Combination
组合计数 组合数学主要是研究一组离散对象满足一定条件的安排的存在性.构造及计数问题.计数理论是狭义组合数学中最基本的一个研究方向,主要研究的是满足一定条件的排列组合及计数问题.组合计数包含计数原理.计 ...
- Oracle数据库rownum用法集锦
Oracle中rownum可以用来限制查询 具体用法: 1.返回查询集合中的第1行 select * from tableName where rownum = 1 2.返回查询集合中的第2行 错误示 ...
- 基于 K8s 做应用发布的工具那么多, 阿里为啥选择灰姑娘般的 Tekton ?
作者 | 邓洪超,阿里云容器平台工程师, Kubernetes Operator 第二人,云原生应用标准交付与管理领域知名技术专家 导读:近年来,越来越多专门给 Kubernetes 做应用发布的 ...
- JVM的监控工具之jps
jps的功能和ps命令相似:可列出正在运行的虚拟机进程,并显示虚拟机执行主类(Main Class,main()函数所在的类)名称以及这些进程的本地虚拟机唯一ID(Local Virtual Mach ...
- Neo4j 第九篇:查询数据(Match)
Cypher使用match子句查询数据,是Cypher最基本的查询子句.在查询数据时,使用Match子句指定搜索的模式,这是从Neo4j数据库查询数据的最主要的方法.match子句之后通常会跟着whe ...
- centos ftp服务器搭建 vsftpd 匿名访问配置方法 ftp 550 Failed to open file 错误处理
vsftpd是linux下常用的ftp服务软件,配置起来其实不复杂,只是网上很多文章,配置后都无法成功.我使用它是用于局域网内部分享文件的,所以使用匿名的方式. ftp本身密码是明文传输的,如果需要安 ...
- OpenGL入门1.2:渲染管线简介,画三角形
每一个小步骤的源码都放在了Github 的内容为插入注释,可以先跳过 图形渲染管线简介 在OpenGL的世界里,任何事物是处于3D空间中的,而屏幕和窗口显示的却是2D,所以OpenGL干的事情基本就是 ...
- PHP获得毫秒数
因为前端需要写函数处理时间戳,比较麻烦,所以我们有的时候,需要接口传递毫秒数给前端. 下面可以通过这个函数来获得毫秒数 <?php function getMillisecond() { lis ...