论文翻译:Data mining with big data
原文:
Wu X, Zhu X, Wu G Q, et al. Data mining with big data[J]. IEEE transactions on knowledge and data engineering, 2013, 26(1): 97-107.
大数据中的数据挖掘
Xindong Wu, Fellow, IEEE, Xingquan Zhu, Senior Member, IEEE,
Gong-Qing Wu, and Wei Ding, Senior Member, IEEE
摘要 大数据主要研究大容量、复杂、不断生长的数据集,这些数据集来自多样、自主的数据源。随着网络技术、数据存储和数据收集水平的快速进步,大数据正在各种科学和工程领域中快速发展,包括物理学、生物学和生物医学。本文提出了HACE原理来描述大数据革新过程中的特征,从数据挖掘的视角提出了一种大数据处理模型。这种数据驱动的模型涉及信息源、数据挖掘与分析、用户兴趣建模、安全隐私问题之间的需求驱动聚合。我们分析了这一数据驱动模型和大数据革命中的挑战性问题。
关键词 大数据,数据挖掘,异构性,自主来源,复杂演进的关联
一、绪论
莫言先生获得了2012年度诺贝尔文学奖。这大概是该领域最具争议的诺贝尔奖。在谷歌上搜索"莫言诺贝尔奖",可以得到1,050,000项结果(2013年1月3日)。"对于所有的赞扬和批评,"莫言近日说,"我是很感激的。"在莫言31年的写作生涯中,他究竟受到了何种赞扬和批评?随着网络和各种新闻媒体上的持续评论,我们能否以实时的形式来总结不同媒体上所有类型的观点,并包括评论者的更新和交叉引用?这种总结程序是大数据处理的一个出色的例子,其信息来自于多样、异构且自发的信息来源,具有复杂且不断发展的关系,并保持增长。
正如上述例子所示,大数据时代已经来临[37],[34],[29]。每天,有2.5EB的数据产生,而且今天世界上90%的数据是在过去两年内产生的[26]。自19世纪初期信息技术被创造以来,我们的数据生成能力从未如此强大。作为另一个例子,2012年10月4日,贝拉克·奥巴马和米特·罗姆尼之间的第一场总统竞选辩论,在2小时内引发了1000万条以上的推特消息[46]。在这些推特消息中,大多数讨论确实揭露了公众的关注热点,例如关于医疗保障和学券制的讨论。这种线上的讨论为了解公众利益并实时作出反馈提供了新的方式,与广播、电视等传统媒体相比更具吸引力。另一个例子如Flickr,一个公众图片共享网站,在2012年2月到3月,它平均每天收到180万幅照片。假设每幅图片的大小为2MB,则每天需要3.6TB的存储空间。事实上,正所谓:"一图胜千言",Flickr(译者注:此处原文拼写错误,"Flicker"应为"Flickr",下同)上的数十亿幅图片,对于我们而言,是探索人类社会、社交活动、公共事务、灾难等的巨大宝藏,只需要我们拥有利用海量数据的能力。
上述实例描述了大数据应用的兴起,其数据集大小发生了惊人增长,使用传统的常用软件工具,已经无法在"可容忍的时间范围"内来进行获取、管理和分析。大数据应用最基本的挑战,在于探索大容量数据,并为未来的活动提取有用信息或知识[40]。在很多场合下,知识发现过程必须高效且接近实时,因为对所有的已观测数据进行存储近乎不可能。例如,下一代"平方公里阵列"射电望远镜(SKA)在中央五公里区域内包含1000到1,500个碟形天线。它可以提供比任何现有射电望远镜灵敏度高百倍以上的图像,回答关于宇宙的基本问题。然而,这种"平方公里阵列"射电望远镜产生的数据量格外巨大,达到40GB/秒。虽然研究者们表示,需要关注的图样,例如瞬态射频异常[41]可以从上述数据中发掘,但是现有方法只能以离线方式工作,无法实时处理这种大数据应用场景。因此,这种空前的数据量需要一种有效的数据分析和预测平台,来达到针对这种大数据的快速响应和实时分类。
本文的余下部分分为如下几部分:在第二部分,我们提出了HACE理论来建模大数据特征。第三部分总结了大数据挖掘的主要挑战。在此领域的一些主要研究方案和作者们的国家研究项目列出在第四部分。第五部分讨论了相关工作,第六部分对本文做出总结。
二、大数据特征:HACE原理
HACE原理:大数据源于大容量的、异构的(H)、自发的(A)来源,使用分布式、去中心化的控制,寻求探索数据之间复杂的(C)、演进中的(E)关系。
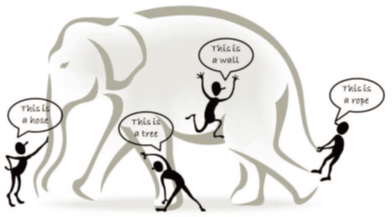
图1
这些特征使得从大数据中发现有用知识变得极具挑战。简而言之,我们可以想象一群盲人在试图估计一头大象的大小(如图1所示),大象在本文中可以代表大数据。每一位盲人的目的是根据他所收集到的信息来得出大象的形象(即结论)。由于每一个人的感知范围局限在一个部分区域,盲人们各自总结得出大象感觉起来像绳子、向软管、像墙壁也不足为奇,这取决于他们被局限在了哪个区域。为了使问题更加复杂,我们假设:(1)大象在快速长大,且姿势不断变化,(2)每个盲人也许有其自身的信息来源(可能不可靠或不准确),提供了关于大象的偏颇性知识(例如,一个盲人也许会与另一个盲人共享其对大象的感觉,而这种感觉具有固有的片面性)。在这种场景下探索大数据,相当于从不同的来源(盲人)聚合异构的信息,从而辅助我们以实时的方式最好地描绘出大象的真实姿态。的确,这项任务并非仅仅询问每个盲人来描述他对大象的感知,然后找专家根据综合的观点来画出一幅画,关于这一点,每个人可能说不同的语言(异构多样的信息源)而且他们在信息交换过程中也许有隐私上的顾虑。
2.1 异构多维度的海量数据
大数据的基本特征之一是以异构多维度方式展现的海量数据。这是由于不同的信息收集者倾向于以他们自己的模式和协议来进行数据记录,并且不同应用的自然属性也导致了不同的数据表示。例如,在生物医学领域里,每个个人可以由人口统计学信息来表示,如性别、年龄、家庭病史等。对于X光检查和CT扫描,图像或视频可以用于表示结果,因为它们为医生进行进一步诊断提供了可视化信息。对于DNA或基因检测,微阵列表示图和序列用于代表基因序列信息,因为这是我们当前的技术所需要的数据形式。在这些情况下,异构性特征代表对同一个体的不同类型的表示,而多样性特征代表描述每一次观察涉及的多种多样的特点。想象不同组织(或保健医生)也许会有他们自己的模式来代表每个病人,当我们试图通过综合所有数据源的数据来实现数据聚合时,数据异构和多维度问题成为一项主要挑战。
2.2自发来源和分布式去中心化控制
自发数据源和分布式去中心化控制是大数据应用的主要特点。自发性使数据源可以在不涉及(或不依赖于)任何中心控制的情况下生成和收集信息。这类似于万维网,每一个网页服务器提供一定数量的信息,每台服务器可以不依赖其他服务器而完成全部功能。另一方面,如果整个系统必须依赖于中心化控制单元,巨大容量的数据也使得应用易于遭受攻击或发生故障。对于大多数大数据相关的应用,例如谷歌、Flickr、脸书、沃尔玛,大量服务器群被部署于全世界,来保证本地市场的不间断服务和快速响应。这种自发性数据源不仅是技术设计的解决方案,而且是不同国家或地区立法和监管规则的结果。例如,沃尔玛的亚洲市场与其北美市场在季节性促销、热销产品和顾客消费习惯上具有固有的差异。具体来说,地区政府的管理也影响了批发市场管理的过程,进而导致了本地市场数据表示和数据库的结构重组。
2.3 复杂的、演进中的关系
随着大数据的容量的增大,数据背后的复杂程度和相互关系也在增加。在早期的数据中心化的信息系统中,目标在于如何寻找最好的特征值来代表每次观测。这类似于使用一些数据域,如年龄、性别、收入、教育背景等,来表示每个个人。这种类型的样本特征表示方法把每个个体视为独立的实体,而不考虑其社交联系,而社交联系是人类社会最重要的因素之一。我们的朋友圈也许是基于共同爱好或者生物学关系而建立起来的。这种社交联系通常不仅存在于我们的日常活动中,而且在网络世界也很流行。例如,大多数社交网站,如脸书、推特,都以朋友关系和关注者(在推特中)等社会功能为主要特征。人类个体之间的相关性,内在地使得整个数据表示和数据推理过程变得复杂。在样本-特征表示方式中,如果个体之间有共同特征值,则被认为是相似的,而在样本-特征-关系表示方法中,两个人可以通过社交关系被联系在一起,即使他们在特征上没有共同点。在动态的世界里,用于表示人类个体和其社会关联的特征也许还涉及时间、空间等其他因素。这种复杂性正在成为大数据应用现实的一部分,其关键在于考虑复杂的(非线性、多对多)数据关系及其演进中的变化,来发现大数据集中的有用特征。
三、大数据中的数据挖掘挑战

图2
对于一个处理大数据的智能学习数据库系统,关键在于适应巨大容量的数据,为此前提到的HACE原理所描述的特征提供应对方案。图2提供了大数据处理架构的一个概念模型,从里向外包括三层,依次是数据获取和计算(第一层),数据隐私和行业知识(第二层),大数据挖掘算法(第三层)。
第一层的挑战在于数据的获取和算术运算过程。由于大数据通常存储在不同位置,数据量可能在持续增长,因此一个有效的计算平台必须考虑计算中的分布式大规模数据存储。例如,典型的数据挖掘算法要求所有数据加载到内存中,然而,这成为大数据的一大技术屏障,因为即使我们确实拥有一个超大内存,来存储用于计算的所有数据,但是在不同地点之间移动数据的开销也是昂贵的(例如,受限于密集的网络通信和其他输入输出开销)。
第二层的难点集中于不同大数据应用中的语义和专业领域知识。这些信息可以为数据挖掘过程提供额外的帮助,却也为大数据获取(第一层)和挖掘算法(第三层)增添了技术屏障。例如,根据不同领域的应用,数据生成方和数据消费者之间的数据隐私和信息共享机制会有很大不同。分享像水质监控系统等传感器网络应用的数据也许不会受到反对,然而发布并共享移动用户的地理位置信息对大多数应用而言显然无法接受。除上述隐私问题外,应用的所属领域也会为促进或指导大数据挖掘算法的设计提供额外信息。例如,在市场交易数据中,可以认为每笔交易是独立的,发掘出来的知识通常以寻找高度相关项来呈现,可能受到不同时间和/或空间的限制。另一方面,在一个社交网络中,用户相互关联,具有依存结构。知识则要以用户群体、群组领导和社会影响模型等来表征。因此,理解语义和应用知识对于低层数据获取和高层挖掘算法设计而言都很重要。
在第三层,数据挖掘的难点在于,针对由大数据容量、分布式数据和复杂动态的数据特征产生的问题,来进行算法设计。第三层的环包括三个阶段。第一,稀疏、异构、不确定、不完整且来源多样的数据通过数据融合技术来预处理。第二,对预处理后的复杂动态数据进行挖掘。第三,通过局部学习和模型融合获得的全局知识接受测试,相关信息反馈给预处理阶段。接下来,模型和参数根据反馈进行调节。在整个过程中,信息共享不仅是每一阶段平稳过度的保障,也是大数据处理的一个目的。
接下来,我们对图2中三层架构的难点进行详细阐述。
3.1 第一层:大数据挖掘平台
在典型数据挖掘系统中,挖掘过程需要计算密集型单元,进行数据分析和比较。因此,一个计算平台至少需要高效地获取两种类型的资源:数据和计算处理器。对于小规模数据挖掘任务,一台包括硬盘和中央处理器的桌面计算机足以完成数据挖掘目标。事实上,许多数据挖掘算法是针对这种类型问题而设计的。对于中等规模数据挖掘任务,数据量通常较大(而且可能分布式存储),无法存入主内存中。常见的解决方案依赖并行处理[43],[33]或集合挖掘[12]来采样并聚合来自不同数据源的数据,然后使用并行计算程序设计(如消息传递接口)来实施挖掘过程。
对于大数据挖掘,由于数据规模已经远远超过一台个人计算机的处理能力,典型的大数据处理框架将依赖高性能计算平台的计算机集群,一个数据挖掘任务将通过运行一些并行程序设计工具来执行,如MapReduce或企业控制语言,它们运行于大量计算节点(即集群)上。软件部分的作用是确保一项数据挖掘任务,例如在一个具有几十亿条记录的数据库中查找与一次查询操作的最佳匹配项,被分成许多小任务,分别运行于一个或多个计算节点。例如,截至本文发稿时,世界上最大的超级计算机泰坦,位于田纳西州橡树岭国家实验室,包括18,688个节点,每个节点拥有一个16核中央处理器。
这样的大数据系统,混合了硬件和软件,没有大工业股东的支持将很难建成。事实上,数十年来,企业一直在利用存储在关系型数据库中的交易数据来做出商业决策。大数据挖掘提供了超越传统关系型数据库的机会,来依靠结构化程度更弱的数据:网络日志、社交媒体、电子邮件、传感器以及照片都可以被挖掘出有用信息。大多数商业智能企业,如IBM、甲骨文、天睿资讯等,都已经开发他们自己的产品,帮助客户获取并管理这些多样的数据源,并与客户已有数据进行整合,来发现新的观点,利用隐藏的关联。
3.2 第二层:大数据语义和应用知识
大数据语义和应用知识涉及到关于法规、政策、用户知识和专业领域信息的众多方面。这一层的两个最主要的问题包括(1)数据分享和隐私;(2)专业领域和应用知识。前者回答了数据如何被维护、获取和共享的问题;而后者主要回答了像"根本应用是什么"和"用户想要从数据中发现什么知识或规律"这样的问题。
3.2.1 信息共享和数据隐私
信息共享是所有涉及多方的系统的一个最终目标[24]。虽然共享的动机很明确,但一个真实存在的顾虑是大数据应用是关于敏感信息的,例如银行交易业务和医疗记录。简单的数据交换和传输不会解决隐私问题[19],[25],[42]。例如,可以根据人们的地址和偏好,来建立一系列有用的基于位置的服务,但是反复向公众暴露个人的位置和运动情况,会产生严重的隐私问题。为了保护隐私,两个常见方法是:(1)严格限制数据访问,如为数据项添加认证或访问控制,则敏感信息只能被一群有限的用户访问;(2)使数据域匿名,则敏感信息不指向某个个体记录[15]。对于第一项措施,通常的挑战是设计一种安全的认证或访问控制机制,以确保信息不会被未授权的个体进行不当处理。至于数据匿名化,其主要目标是向数据加入随机性,来保证一定的隐私目标。例如,最常见的k-匿名隐私策略,保证了数据库中的每个个体都无法区别于其他k-1个个体。通常的匿名方法是压缩、一般化、加扰、置换,以此来生成数据的一个变异的版本,事实上,是一些不确定的数据。
基于数据匿名化的信息共享方法的一个主要优势在于,一旦进行匿名化,数据变可以自由地在各方分发,而无需考虑访问控制限制。这自然引入了另一个研究领域,即隐私保护数据挖掘[30],各自拥有一些敏感数据的多方试图达到一个共同的数据挖掘目标,而不愿分享数据内任何的敏感信息。在实践中,这种隐私保护的挖掘目标,可以通过两种方式来解决,包括:(1)使用特殊的通信协议[54],得到整个数据集的分布,而不是请求每项记录的实际值;(2)设计特殊的数据挖掘方法,从匿名数据中获取知识(这实际上与不确定的数据挖掘方法相似)。
3.2.2 专业领域和应用知识
专业领域和应用知识[28]为设计大数据挖掘算法和系统提供了关键信息。在一个简单案例中,专业领域知识可以帮助建模基础数据识别正确的特征(例如,与体重相比,血糖水平显然是用于诊断Ⅱ型糖尿病的更好特征)。专业领域和应用知识也可以使用大数据分析技术帮助设计可行的商业目标。例如,股票市场数据是一个持续生成大量信息的典型领域,如每一秒的出价、买入价和卖出价。市场在不断演进,受到不同因素的影响,如国内外新闻、政府报告和自然灾害等。一个吸引人的大数据挖掘任务是设计一种大数据挖掘系统来预测下一或两分钟内的市场运动。这种系统,即使其预测准确度仅仅稍高于随机猜测,但也将为开发者带来巨大的商业价值[9]。没有正确的专业领域知识,发现有效的模型来描述市场运动的特征是一个明显的挑战,而这些知识通常超出了数据挖掘者的知识背景,虽然一些最近的研究表明使用推特等社交网络来高准确率地预测股市涨跌趋势是可能的。
3.3 第三层:大数据挖掘算法
3.3.1 多信息源的局部学习和模型聚合
由于大数据应用的自发的来源和去中心化的控制,考虑到潜在的传输成本和隐私问题,将分布式的数据源聚合在一个中心化的网站来用于挖掘是被禁止的。另一方面,虽然我们可以在每个分布式的站点进行挖掘活动,但从每个站点收集到的偏斜的数据通常会导致偏斜的结论或模型,正如盲人摸象的例子。在这种环境下,一个大数据挖掘系统必须信息交换和融合机制,来确保所有的分布式站点(或信息源)可以共同工作,来完成一个全局最优目标。模型挖掘和相关性统计,是保证从多种信息源发现的模型或模式可以被统一起来,满足全局挖掘目标的关键步骤。更特别地,全局挖掘可以描述为一个两步(局部挖掘和全局相关)的过程,分别在数据、模型和知识的层面。在数据层面,每一个本地站点可以根据本地数据源来计算统计数据,并在站点之间交换统计数据,来获得全局数据分布视图。在模型或模式层面,每个站点可以执行本地挖掘活动,根据本地数据发现本地模式。通过在多个信息源之间交换模式,可以通过聚合各个站点的模式来合成新的全局模式[50]。在知识层面,模型相关分析研究了不同数据源产生的模型之间的关联,来决定不同数据源生成的模型之间是如何关联的,和如何基于这些自治数据源建立的模型来形成精准的决策。
3.3.2 针对稀疏、不确定、不完整数据的挖掘
稀疏的、不确定的、不完整的数据是大数据应用的界定特征。稀疏,表示数据点数目稀少,难以得出可靠结论。这通常伴随着数据维度问题,高维度空间的数据(例如大于1,000维)不会显示清晰的趋势或分布。对于大多数机器学习和数据挖掘算法,高维稀疏数据显著恶化了从数据中得出模型的可靠性。通常的方法是使用降维或者特征选取[48]来减少数据维度,或有意引入额外的样本来缓解数据稀缺,例如一般的数据挖掘中的无监督学习方法。
不确定性数据是一种特殊类型的现实数据,它的每个数据域都不再是确定的,而是属于某一个随机或误差分布。这主要是关于特定应用领域的中不精确的数据读取和收集。例如,GPS设备上产生的数据内在地具有不确定性,主要是由于设备的技术屏障在一定程度上限制了数据精度(例如1米)。结果,每条记录的位置都由一个均值加上期望的误差方差来表示。对于涉及数据隐私的应用[36],用户可能有意识地向数据注入随机性或误差,来保持匿名。与此相似的场景是,一个人也许不愿意让你知道其准确收入,但是会愿意提供一个大致区间,如[120k, 160k]。对于不确定的数据,主要挑战是每一数据项都代表一个样本分布,而不是一个值,所以大多数存在的数据挖掘算法无法被直接应用。常见解决方案是考虑数据分布来估计模型参数。例如,误差感知型数据挖掘[49]利用每一数据项的均值和方差来建立朴素贝叶斯模型用于分类。相似方法也用于决策树或数据库查询。不完整的数据涉及到一些样本数据域的丢失值,如传感器节点的故障,或者一些系统策略有意识地跳过一些值(例如,为了及节能或减少传输而舍弃一些传感器读取操作)。虽然大多数现代数据挖掘算法具有内置的方案来处理丢失值(如忽略存在丢失值的数据域),数据重建是一个已经建立的研究领域,致力于缺失数据的重建,以产生改进的模型(与原始数据生成的模型相比)。存在关于这一目的的许多重建方法[20],主要途径是为每个数据域填充频繁观测到的数值或基于某个已知实例的观测值建立学习模型来预测可能取值。
3.3.3 挖掘复杂动态数据
大数据的兴起是由复杂数据的快速增长及其容量和性质的变化驱动的[6]。万维网服务器上的文件、互联网的骨干网、社交网络、通信网络和交通运输网络等,都以复杂数据为特征。虽然数据背后复杂的依赖结构提高了我们学习系统的复杂程度,但它们也提供了单一数据表示无法达到的令人兴奋的机遇。例如,研究人员成功使用推特,一个著名的社交网站,来检测地震和主要社会活动等事件,并具有接近实时的速度和很高的准确率。此外,通过总结遍布全球的用户提交给搜索引擎的查询操作,现在可以建立一个流感发作快速传播的早期预警系统[23]。使用复杂数据是大数据应用的一项主要挑战,因为在一个复杂网络中的任意两方都具有相互之间对社会联系感兴趣的可能。这种联系关于网络节点数目呈平方关系,因此具有百万节点的网络可能涉及到万亿的连接。对于一个大型社交网站,如脸书,活跃用户数已达10亿,分析如此庞大的网络对于大数据挖掘而言是一项巨大挑战。如果我们考虑日常用户活动和交互,困难的规模将会令人震惊。
在以上挑战的促进下,发展出了许多数据挖掘方法,用于从具有复杂关系和动态变化容量的大数据中发现感兴趣的知识。例如,发现社区并跟踪他们的动态演进关系,对于理解和管理复杂系统至关重要[3][10]。发现社交网络中的离群值[8]是识别垃圾邮件来源并为我们的社会提供安全网络环境的第一步。
如果仅仅面临大规模的结构化数据,则用户可以简单地通过购买更多存储设备或提高存储效率来解决这一问题。然而,大数据的复杂性表现在许多方面,包括复杂的异构数据类型、复杂的数据内在语义关联,以及复杂的数据关系网络。即,大数据的价值正在于它的复杂性。
复杂的异构数据类型。在大数据中,数据类型包括结构化数据、非结构化数据和半结构化数据等。具体而言,有扁平数据(关系型数据库)、文本、超文本、图像、音频和视频等数据。已有的数据模型包括键-值存储、BigTable克隆、文件数据库以及图形数据库,以上数据模型按照复杂程度递增的顺序列出。传统数据模型在大数据的背景下无法处理复杂的数据。当前,没有用于处理大数据的公认的可行高效数据模型。
复杂的数据内在语义关联。网页新闻、推特评论、Flickr图片以及YouTube视频剪辑也许会在同一时间讨论一项学术颁奖活动。毋庸置疑,这些数据之间具有较强的语义联系。从"文本-图像-视频"数据中挖掘复杂的语义关联,对提升应用系统性能具有显著作用,如搜索引擎或推荐系统。然而,大数据环境下,有效地描述语义关系并建立语义关联模型,从而缩小多样异构数据源之间的语义差距,是一项巨大挑战。
复杂的数据关系网络。在大数据环境下,个体之间存在关系。在互联网上,个体代表网页和通过复杂网络间的超级链接互联的页面。也存在形成复杂社会网络的个体之间的社交关联,例如脸书、推特、领英和其他社交媒体上的大型关系数据[5],[13],[56],包括详细通话记录,设备和传感器信息[1],[44],GPS和地理编码的地图数据,通过管理文件传输协议传输的大量图片文件,网络文本和点击流数据[2],科学情报,电子邮件[31]等等。为了应对复杂的关系网络,新兴的研究开始解决结构和演进、人群和互动、以及信息和通信的问题。
大数据的出现,也引起了用于实时数据密集型处理的新计算机架构的出现,例如运行于高性能集群上的开源Apache Hadoop计划。大数据的大小和复杂性,包括事务和交互数据集,使得在合理的成本和时间限制内获取、管理和处理这些数据超过了常规的技术能力。大数据环境下,复杂数据的实时处理是一项十分具有挑战性的任务。
四、研究方案和计划
为了应对大数据的挑战,并"抓住由新的、数据驱动的革新提供的机会",美国国家科学基金会在奥巴马政府的大数据方案支持下,发布了2012大数据征集活动。这样一项联邦政府方案产生了一系列成功计划,用于调研大数据管理创新(由华盛顿大学率领),基于基因组的大数据计算分析方法(布朗大学率领),500,000维量级高维度数据集的大规模机器学习技术(由卡内基梅隆大学率领),大规模科学文献的社会化分析(由罗格斯大学率领),一起一些其他计划。这些计划旨在发展方法、算法、框架和研究架构,来允许我们把大量的数据转换成人类可以处理和说明的规模。在其他国家,例如中国国家自然基金会也在跟进大数据研究的国家补助。
同时,自2009年,作者开始参与领导如下涉及大数据部分的国家项目:
- 从生物网络中的多样来源整合挖掘生物数据,美国国家科学基金会资助,媒体批准号CCF-0905337,2009年10月1日 - 2013年9月30日。
内容和意义:我们整合并挖掘了来自多样数据源的生物数据,来解释和利用生物网络,针对生物系统的功能提出新的见解。我们为整合和挖掘生物网络提出了理论基础和当前以及未来的可行技术。我们扩充并整合了信息网络中信息获取、传输、处理的技术和方法。我们发展了基于语义的数据整合、根据所挖掘数据进行自动化假设、以及自动的可扩展分析工具的方法,来评估仿真结果并改进模型。 - 大数据快速响应。大数据流的实时分类,澳大利亚研究委员会资助,批准号DP130102748,2013年1月1日 – 2015年12月31日。
内容和意义:我们提出建立一种基于流的大数据分析框架,用于快速响应和实时决策。主要挑战和研究内容包括:- 设计大数据采样机制,将数据量减少到易于处理和控制的大小;
- 为大数据流建立预测模型。这种模型可以适应性地调整以适合数据的动态变化,并准确预测数据未来的趋势;
- 一个知识索引框架,用于保证大数据应用的实时数据监控和分类。
- 使用通配符和长度限制的模式识别和挖掘,中国国家自然科学基金资助,批准号60828005(第一阶段,2009年1月1日 – 2010年12月31日),61229301(第二阶段,2013年1月1日 – 2016年12月31日)。
内容和意义:我们系统调查了使用通配符的模式识别和模式挖掘,应用问题如下:- 探索匹配和挖掘问题的NP-难复杂度,
- 使用通配符的多模式匹配,
- 近似模式匹配和挖掘,
- 本研究在普遍的个人化信息处理和生物信息学中的应用。
- 整合和挖掘多样化异构数据源的关键技术,中国国家高技术研究发展计划(863计划)资助,批准号2012AA011005,2012年1月1日 – 2014年12月31日。
内容和意义:我们对多源大量动态信息的可用性和统计规律进行了调研,包括基于信息提取、信息抽样、不确定信息查询、跨领域跨平台信息聚合的跨媒介搜索。为了突破传统数据挖掘方法的限制,我们研究了复杂内联数据的异构信息发现和挖掘,数据流挖掘,大规模多样来源数据的多颗粒度知识发现,大规模知识分布规律,大规模知识质量融合。 - 社交网络的群组影响和交互,中国国家基础研究973计划资助,批准号2013CB329604,2013年1月1日 – 2017年12月31日。
内容和意义:我们研究了社交网络的群组影响和交互,包括:- 使用群组影响和信息扩散模型,使用动态博弈论探讨社交网络的群组交互规则,
- 研究受群组情感影响的社交网络之下的个人选择和影响评估,并分析个人和群组之间的情感交互和影响,
- 为社交网络群组建立一种交互的影响模型及其计算方法,揭示相互影响的效果和社交网络的演进。
五、相关工作
5.1 大数据挖掘平台(第一层)
由于分布式环境的应用数据的多源、海量、异构、动态等特性,大数据的最重要特征之一是对PB甚至EB量级的数据执行复杂的计算过程。因此,利用并行计算框架、相应程序语言支持以及软件模型,高效地分析并挖掘分布式数据,是大数据处理从"数量"转换成"质量"的关键目标。
当前,大数据处理主要依赖并行编程模型,如MapRuduce,而且为公众提供了大数据服务的云计算平台。MapReduce是一个面向批处理的并行计算模型。与关系型数据库在性能上仍然有一定的差距。随着MapReduce并行程序设计被应用到许多机器学习和数据挖掘算法中,提高MapReduce的性能并增强大规模数据处理的实时特性受到了大量关注。数据挖掘算法通常需要扫描训练数据,以获取解决或优化模型参数的统计数据。频繁地访问大规模数据需要密集的计算。为了增强算法效率,Chu等人提出了一种通用目标的并行编程方法,适用于基于多核处理器上简单MapReduce程序设计模型的大量机器学习算法。这一框架实现了十大经典数据挖掘算法,包括局部加权线性回归,k-Means,逻辑回归,朴素贝叶斯,线性支持向量机,独立变量分析,高斯判决分析,最大期望,以及反向传播神经网络[14]。通过分析这些机器学习算法,我们主张算法学习过程的计算性操作可以转化成对一些训练数据集的汇总操作。汇总操作可以容易地在MapReduce程序设计平台上独立地执行于不同的子集上,并实现统计惩罚。从而,一个大规模数据集可以分成几个子集,分配到多个映射节点上。随后,在映射节点上执行多种汇总操作,来收集中间结果。最后,学习算法通过在规约节点上合并汇总,并行执行。Ranger等人[39]提出了一个基于MapReduce的应用编程接口"凤凰",支持多核多处理器系统的并行编程环境,实现了包括k-Means、主成分分析和线性回归等三种数据挖掘算法。Gillick等人[22]改进了Hadoop中MapReduce的实现机制,评估了该算法在MapReduce框架之内在单次学习、迭代学习和基于查询的学习中的性能,研究了并行学习算法和分布式数据存储中所涉及计算节点之间的数据共享,然后通过在中等规模集群上测试一系列标准数据挖掘任务,证明了MapReduce机制适合于大规模数据挖掘。Papadimitriou和Sun[38]提出了一个分布式协作聚合框架(DisCo),使用实用性分布数据预处理和协作聚合技术。通过在一个开源MapReduce项目中的Hadoop上的实现,表明这一框架具有完美的可扩展性,能够处理和分析大规模数据集(上百GB)。
为了改进传统分析软件可扩展性低和Hadoop系统分析能力弱的问题,Das等人[16]对R语言集成软件(开源统计分析软件)和Hadoop进行了研究。深入的集成化推动了并行化处理的数据计算过程,使得Hadoop具有了强大的深度分析能力。Wegener等人[47]完成了Weka(一个开源机器学习和数据挖掘软件工具)和MapReduce之间的集成。标准Weka工具只能在单机运行,内存限制在1GB大小。算法并行化以后,Weka突破了这一限制,通过并行计算的优势改善了性能,在MapReduce集群上可以处理大于100GB的数据。Ghoting等人[21]提出了Hadoop-ML,可以允许开发者通过语言运行时环境下的程序块,轻松地建立并行任务或者并行数据机器学习和数据挖掘算法。
5.2 大数据语义和应用知识(第二层)
在大量数据的隐私保护中,Ye等人[55]提出了一个多层的粗糙集模型,能够精确描述由不同级别的一般化产生的颗粒度变化情况,为匿名化过程提供了衡量数据有效性准则的理论基础,设计了一个平衡隐私和数据效用的动态机制,以解决分类问题中的最优泛化或细化顺序问题。最近一篇关于大数据机密性保护的论文[4]总结了一些用于保护公开发布数据方法,包括聚类(例如k-匿名、I-多样性等)、压缩(即删除敏感数值)、数据交换(即交换敏感数据记录的值从而避免用户匹配)、添加随机噪声、或简单地把处于较高暴露危险中的原始数据值整体替换成根据模拟分布合成的数值。
对于涉及大数据和巨大数据体量的应用,数据在物理上分布在不同位置的情况时有发生,这意味着用户不再拥有他们数据的物理存储。为了进行大数据挖掘,拥有一种高效可行的数据访问机制是至关重要的,尤其是对于想要雇佣第三方(如数据矿工或数据审计)来处理数据的用户。在这种环境下,用户的隐私限制可能包括:(1)不允许本地数据备份或下载,(2)所有的分析必须基于已有数据存储系统来执行,而不违反现存隐私设定,以及许多其他限制。Wang等人[48]提出了一种针对大规模数据存储(例如云计算系统)的隐私保护公共审计机制。这种基于密钥的公共机制用来保证第三方审计,让用户得以安全地允许第三方来分析他们的数据,而不破坏安全规则或在数据隐私上做出妥协。
对于大多数大数据应用,隐私问题关注于拒绝第三方(例如数据矿工)直接访问原始数据。通用解决方案是依赖于一些隐私保护方法或加密机制来保护数据。Lorch等人[32]最近的一项成果表明用户的"数据访问模式"也可能具有一些数据隐私问题,引起地理位置相同的用户或者有共同兴趣的用户(例如,两个搜索同一地图位置的用户可能地理位置相同)的暴露。在他们的系统,即Shround,中,来自服务器的用户数据接入模式通过虚拟磁盘来隐藏起来。因此,它可以支持许多大数据应用,例如微博搜索和社交网络查询,无需考虑妥协用户隐私。
5.3 大数据挖掘算法(第三层)
为了适应多源、海量、动态的大数据,研究人员已经通过许多途径扩展了现存的数据挖掘方法,包括单一来源的知识发现方法[11]的效率改进,从多源的角度设计一种数据挖掘机制[50],[51],以及针对动态数据挖掘方法的研究和流数据的分析[18],[12]。从大量数据中发现知识的主要动机,在于提高单一来源挖掘方法的效率。基于计算机硬件功能的逐渐提升,研究人员继续探索提高知识发现算法效率的方式,来使他们更适于海量数据。由于海量数据通常是从不同数据源收集而来的,因此海量数据的知识发现必须使用多源挖掘机制来执行。因为现实世界的数据经常作为数据流或者特性流出现,需要一种固定的机制来发现知识和控制动态数据源的知识演进。因此,多源数据海量、异构、实时的特性在单一来源知识发现和多源数据挖掘之间产生了本质不同。
Wu等人[50],[51],[45]提出并建立了局部模式分析理论,为多源数据挖掘中的全局知识发现奠定了基础。这一理论不仅为全文搜索问题提供了解决方案,而且找到了一种传统挖掘算法无法发现的全局模型。数据处理的局部模式分析可以避免将不同数据源放在一起来执行中心化计算。
数据流广泛应用于财务分析、线上交易、医学检测等。静态知识发现方法无法适应动态数据流的特征,例如连续性、可变性、快速性和无穷性,而且易于引起有用信息的丢失。因此,需要有效的理论和技术框架,来支持数据流挖掘[18],[57]。
在现实世界系统中,知识演进是一种常见现象。例如,临床医生的治疗方案应该持续调整以适应患者的状态,例如家庭经济状况、医疗保险、治疗疗程、治疗效果以及心血管分布和过去一段时间的其他慢性流行病学变化。在知识发现过程中,概念漂移旨在分析隐式的目标概念变化或者甚至由动态性和数据流环境引发的根本性改变。根据概念漂移的不同类型,知识演进可以具有突变漂移、渐进漂移和数据分布漂移等形式,基于单一特征、多特征和流特征。
六、结论
受到现实世界应用和主要产业利益相关方的驱动,由国家资助机构发起,大数据的管理和挖掘已经成为一项具有挑战性而引人注目的任务。虽然大数据一词字面上是关于数据体量的,我们的HACE理论提出大数据的关键特征在于:(1)大量的、异构的(H)、数据源多样化的,(2)自发(A)的分布式去中心化控制,(3)复杂(C)且数据和知识关联处于演进(E)之中。这种联合特征表明大数据需要"大胸襟"来联合数据,发挥其最大价值[27]。
为了探索大数据,我们在数据、模型和系统层面分析了几项挑战。为了支持大数据挖掘,需要高性能计算平台,实施系统的设计来释放大数据的全部功能。在数据层面,自发的信息来源和多样的数据收集环境,通常导致数据具有复杂的情况,例如缺失或不确定的值。在其他情况下,隐私问题、噪声、误差会被引入到数据中,产生变化的数据副本。发展一种安全成熟的信息共享协议是一项主要挑战。在模型层面,主要挑战是通过结合局部发现的模式来形成同一视图,生成全局模型。这需要认真设计的算法来分析分布式站点模型的相关性,并融合来自多个数据源的决定,获取大数据的最佳模型。在系统层面,关键的挑战是大数据挖掘框架需要考虑样本、模型和数据源之间的复杂关系,以及它们随时间和其他可能因素的演进和变化。一个系统需要被仔细设计,从而非结构化数据可以通过它们复杂的关系来连接,形成有用的模式,并且数据量的增长和数据项的关系应该辅助生成预测未来趋势的合理模型。
我们把大数据视为一种新兴趋势,对大数据挖掘的需求正在所有科学工程领域产生。使用大数据技术,我们有望能够提供最贴切和最精准的社会感知反馈,来更好地对我们的社会进行实时地了解。进一步,我们可以刺激公众参与社会和经济事件中的数据生产循环。大数据时代已经到来。
致谢
本工作受到中国国家863计划(2012AA011005)、中国国家973计划(2013CB329604)、中国国家自然科学基金(NSFC 61229301,61273297,61273292)、美国国家科学基金会(NSF CCF-0905337)、以及澳大利亚研究委员会未来研究员(FT100100971)和发现计划(DP130102748)的支持。作者感谢那些匿名评审员们在改进本文上提出的具有价值和建设性意义的评论。
参考文献
[1] R. Ahmed and G. Karypis, "Algorithms for Mining the Evolution of Conserved Relational States in Dynamic Networks," Knowledge and Information Systems, vol. 33, no. 3, pp. 603-630, Dec. 2012.
[2] M.H. Alam, J.W. Ha, and S.K. Lee, "Novel Approaches to Crawling Important Pages Early," Knowledge and Information Systems, vol. 33, no. 3, pp 707-734, Dec. 2012.
[3] S. Aral and D. Walker, "Identifying Influential and Susceptible Members of Social Networks," Science, vol. 337, pp. 337-341, 2012.
[4] A. Machanavajjhala and J.P. Reiter, "Big Privacy: Protecting Confidentiality in Big Data," ACM Crossroads, vol. 19, no. 1, pp. 20-23, 2012.
[5] S. Banerjee and N. Agarwal, "Analyzing Collective Behavior from Blogs Using Swarm Intelligence," Knowledge and Information Systems, vol. 33, no. 3, pp. 523-547, Dec. 2012.
[6] E. Birney, "The Making of ENCODE: Lessons for Big-Data Projects," Nature, vol. 489, pp. 49-51, 2012.
[7] J. Bollen, H. Mao, and X. Zeng, "Twitter Mood Predicts the Stock Market," J. Computational Science, vol. 2, no. 1, pp. 1-8, 2011.
[8] S. Borgatti, A. Mehra, D. Brass, and G. Labianca, "Network Analysis in the Social Sciences," Science, vol. 323, pp. 892-895, 2009.
[9] J. Bughin, M. Chui, and J. Manyika, Clouds, Big Data, and Smart Assets: Ten Tech-Enabled Business Trends to Watch. McKinSey Quarterly, 2010.
[10] D. Centola, "The Spread of Behavior in an Online Social Network Experiment," Science, vol. 329, pp. 1194-1197, 2010.
[11] E.Y. Chang, H. Bai, and K. Zhu, "Parallel Algorithms for Mining Large-Scale Rich-Media Data," Proc. 17th ACM Int'l Conf. Multimedia, (MM '09,) pp. 917-918, 2009.
[12] R. Chen, K. Sivakumar, and H. Kargupta, "Collective Mining of Bayesian Networks from Distributed Heterogeneous Data," Knowledge and Information Systems, vol. 6, no. 2, pp. 164-187, 2004.
[13] Y.-C. Chen, W.-C. Peng, and S.-Y. Lee, "Efficient Algorithms for Influence Maximization in Social Networks," Knowledge and Information Systems, vol. 33, no. 3, pp. 577-601, Dec. 2012.
[14] C.T. Chu, S.K. Kim, Y.A. Lin, Y. Yu, G.R. Bradski, A.Y. Ng, and K. Olukotun, "Map-Reduce for Machine Learning on Multicore," Proc. 20th Ann. Conf. Neural Information Processing Systems (NIPS '06), pp. 281-288, 2006.
[15] G. Cormode and D. Srivastava, "Anonymized Data: Generation, Models, Usage," Proc. ACM SIGMOD Int'l Conf. Management Data, pp. 1015-1018, 2009.
[16] S. Das, Y. Sismanis, K.S. Beyer, R. Gemulla, P.J. Haas, and J. McPherson, "Ricardo: Integrating R and Hadoop," Proc. ACM SIGMOD Int'l Conf. Management Data (SIGMOD '10), pp. 987-998. 2010.
[17] P. Dewdney, P. Hall, R. Schilizzi, and J. Lazio, "The Square Kilometre Array," Proc. IEEE, vol. 97, no. 8, pp. 1482-1496, Aug. 2009.
[18] P. Domingos and G. Hulten, "Mining High-Speed Data Streams," Proc. Sixth ACM SIGKDD Int'l Conf. Knowledge Discovery and Data Mining (KDD '00), pp. 71-80, 2000.
[19] G. Duncan, "Privacy by Design," Science, vol. 317, pp. 1178-1179, 2007.
[20] B. Efron, "Missing Data, Imputation, and the Bootstrap," J. Am. Statistical Assoc., vol. 89, no. 426, pp. 463-475, 1994.
[21] A. Ghoting and E. Pednault, "Hadoop-ML: An Infrastructure for the Rapid Implementation of Parallel Reusable Analytics," Proc. Large-Scale Machine Learning: Parallelism and Massive Data Sets Workshop (NIPS '09), 2009.
[22] D. Gillick, A. Faria, and J. DeNero, MapReduce: Distributed Computing for Machine Learning, Berkley, Dec. 2006.
[23] M. Helft, "Google Uses Searches to Track Flu's Spread," The New York Times, http://www.nytimes.com/2008/11/12/technology/ internet/12flu.html. 2008.
[24] D. Howe et al., "Big Data: The Future of Biocuration," Nature, vol. 455, pp. 47-50, Sept. 2008.
[25] B. Huberman, "Sociology of Science: Big Data Deserve a Bigger Audience," Nature, vol. 482, p. 308, 2012.
[26] "IBM What Is Big Data: Bring Big Data to the Enterprise," http:// www-01.ibm.com/software/data/bigdata/, IBM, 2012.
[27] A. Jacobs, "The Pathologies of Big Data," Comm. ACM, vol. 52, no. 8, pp. 36-44, 2009.
[28] I. Kopanas, N. Avouris, and S. Daskalaki, "The Role of Domain Knowledge in a Large Scale Data Mining Project," Proc. Second Hellenic Conf. AI: Methods and Applications of Artificial Intelligence, I.P. Vlahavas, C.D. Spyropoulos, eds., pp. 288-299, 2002.
[29] A. Labrinidis and H. Jagadish, "Challenges and Opportunities with Big Data," Proc. VLDB Endowment, vol. 5, no. 12, 2032-2033, 2012.
[30] Y. Lindell and B. Pinkas, "Privacy Preserving Data Mining," J. Cryptology, vol. 15, no. 3, pp. 177-206, 2002.
[31] W. Liu and T. Wang, "Online Active Multi-Field Learning for Efficient Email Spam Filtering," Knowledge and Information Systems, vol. 33, no. 1, pp. 117-136, Oct. 2012.
[32] J. Lorch, B. Parno, J. Mickens, M. Raykova, and J. Schiffman, "Shoroud: Ensuring Private Access to Large-Scale Data in the Data Center," Proc. 11th USENIX Conf. File and Storage Technologies (FAST '13), 2013.
[33] D. Luo, C. Ding, and H. Huang, "Parallelization with Multiplicative Algorithms for Big Data Mining," Proc. IEEE 12th Int'l Conf. Data Mining, pp. 489-498, 2012.
[34] J. Mervis, "U.S. Science Policy: Agencies Rally to Tackle Big Data," Science, vol. 336, no. 6077, p. 22, 2012.
[35] F. Michel, "How Many Photos Are Uploaded to Flickr Every Day and Month?" http://www.flickr.com/photos/franckmichel/ 6855169886/, 2012.
[36] T. Mitchell, "Mining our Reality," Science, vol. 326, pp. 1644-1645, 2009.
[37] Nature Editorial, "Community Cleverness Required," Nature, vol. 455, no. 7209, p. 1, Sept. 2008.
[38] S. Papadimitriou and J. Sun, "Disco: Distributed Co-Clustering with Map-Reduce: A Case Study Towards Petabyte-Scale End-to- End Mining," Proc. IEEE Eighth Int'l Conf. Data Mining (ICDM '08), pp. 512-521, 2008.
[39] C. Ranger, R. Raghuraman, A. Penmetsa, G. Bradski, and C. Kozyrakis, "Evaluating MapReduce for Multi-Core and Multiprocessor Systems," Proc. IEEE 13th Int'l Symp. High Performance Computer Architecture (HPCA '07), pp. 13-24, 2007.
[40] A. Rajaraman and J. Ullman, Mining of Massive Data Sets. Cambridge Univ. Press, 2011.
[41] C. Reed, D. Thompson, W. Majid, and K. Wagstaff, "Real Time Machine Learning to Find Fast Transient Radio Anomalies: A Semi-Supervised Approach Combining Detection and RFI Excision," Proc. Int'l Astronomical Union Symp. Time Domain Astronomy, Sept. 2011.
[42] E. Schadt, "The Changing Privacy Landscape in the Era of Big Data," Molecular Systems, vol. 8, article 612, 2012.
[43] J. Shafer, R. Agrawal, and M. Mehta, "SPRINT: A Scalable Parallel Classifier for Data Mining," Proc. 22nd VLDB Conf., 1996.
[44] A. da Silva, R. Chiky, and G. He´brail, "A Clustering Approach for Sampling Data Streams in Sensor Networks," Knowledge and Information Systems, vol. 32, no. 1, pp. 1-23, July 2012.
[45] K. Su, H. Huang, X. Wu, and S. Zhang, "A Logical Framework for Identifying Quality Knowledge from Different Data Sources," Decision Support Systems, vol. 42, no. 3, pp. 1673-1683, 2006.
[46] "Twitter Blog, Dispatch from the Denver Debate," http:// blog.twitter.com/2012/10/dispatch-from-denver-debate.html, Oct. 2012.
[47] D. Wegener, M. Mock, D. Adranale, and S. Wrobel, "Toolkit-Based High-Performance Data Mining of Large Data on MapReduce Clusters," Proc. Int'l Conf. Data Mining Workshops (ICDMW '09), pp. 296-301, 2009.
[48] C. Wang, S.S.M. Chow, Q. Wang, K. Ren, and W. Lou, "Privacy- Preserving Public Auditing for Secure Cloud Storage" IEEE Trans. Computers, vol. 62, no. 2, pp. 362-375, Feb. 2013.
[49] X. Wu and X. Zhu, "Mining with Noise Knowledge: Error-Aware Data Mining," IEEE Trans. Systems, Man and Cybernetics, Part A, vol. 38, no. 4, pp. 917-932, July 2008.
[50] X. Wu and S. Zhang, "Synthesizing High-Frequency Rules from Different Data Sources," IEEE Trans. Knowledge and Data Eng., vol. 15, no. 2, pp. 353-367, Mar./Apr. 2003.
[51] X. Wu, C. Zhang, and S. Zhang, "Database Classification for Multi-Database Mining," Information Systems, vol. 30, no. 1, pp. 71- 88, 2005.
[52] X. Wu, "Building Intelligent Learning Database Systems," AI Magazine, vol. 21, no. 3, pp. 61-67, 2000.
[53] X. Wu, K. Yu, W. Ding, H. Wang, and X. Zhu, "Online Feature Selection with Streaming Features," IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 35, no. 5, pp. 1178-1192, May 2013.
[54] A. Yao, "How to Generate and Exchange Secretes," Proc. 27th Ann. Symp. Foundations Computer Science (FOCS) Conf., pp. 162-167, 1986.
[55] M. Ye, X. Wu, X. Hu, and D. Hu, "Anonymizing Classification Data Using Rough Set Theory," Knowledge-Based Systems, vol. 43, pp. 82-94, 2013.
[56] J. Zhao, J. Wu, X. Feng, H. Xiong, and K. Xu, "Information Propagation in Online Social Networks: A Tie-Strength Perspective," Knowledge and Information Systems, vol. 32, no. 3, pp. 589-608, Sept. 2012.
[57] X. Zhu, P. Zhang, X. Lin, and Y. Shi, "Active Learning From Stream Data Using Optimal Weight Classifier Ensemble," IEEE Trans. Systems, Man, and Cybernetics, Part B, vol. 40, no. 6, pp. 1607- 1621, Dec. 2010.
stardsd [译]
于南湖湖畔
论文翻译:Data mining with big data的更多相关文章
- data Mining with Weka: Trailer More Data Mining with Weka 用weka 进行数据挖掘 Weka 用weka 进行更多数据挖掘
https://www.youtube.com/user/WekaMOOC 大学公开课 视频教程 weka 入门教程 data Mining with Weka: Trailer More Dat ...
- data mining,machine learning,AI,data science,data science,business analytics
数据挖掘(data mining),机器学习(machine learning),和人工智能(AI)的区别是什么? 数据科学(data science)和商业分析(business analytics ...
- 数据挖掘(data mining),机器学习(machine learning),和人工智能(AI)的区别是什么? 数据科学(data science)和商业分析(business analytics)之间有什么关系?
本来我以为不需要解释这个问题的,到底数据挖掘(data mining),机器学习(machine learning),和人工智能(AI)有什么区别,但是前几天因为有个学弟问我,我想了想发现我竟然也回答 ...
- Conference-Web Search and Data Mining
Conference WSDM(Web Search and Data Mining)The ACM WSDM Conference Series 不像KDD.WWW或者SIGIR,WSDM因为从最开 ...
- Time series data mining
from here 论文Timeseries data mining(2012)中提出:时间序列数据挖掘包括7个基本任务和3个基础问题: 7 tasks: query by content clust ...
- Distributed Databases and Data Mining: Class timetable
Course textbooks Text 1: M. T. Oszu and P. Valduriez, Principles of Distributed Database Systems, 2n ...
- What is the most common software of data mining? (整理中)
What is the most common software of data mining? 1 Orange? 2 Weka? 3 Apache mahout? 4 Rapidminer? 5 ...
- What’s the difference between data mining and data warehousing?
Data mining is the process of finding patterns in a given data set. These patterns can often provide ...
- A web crawler design for data mining
Abstract The content of the web has increasingly become a focus for academic research. Computer prog ...
随机推荐
- 利用pandas映射替换两个字典中的映射值
在公司处理报表,中英文映射表与数值表替换 import pandas as pd data = { "a":"值一", "b":" ...
- python基础语法17 面向对象4 多态,抽象类,鸭子类型,绑定方法classmethod与staticmethod,isinstance与issubclass,反射
多态 1.什么是多态? 多态指的是同一种类型的事物,不同的形态. 2.多态的目的: “多态” 也称之为 “多态性”,目的是为了 在不知道对象具体类型的情况下,统一对象调用方法的规范(比如:名字). 多 ...
- PassArrayByCopy_test.php
<?php //PassArrayByCopy_test.php $a=array("a","b","c"); function te ...
- 4.通过HttpMethod执行不同的服务方法
package Services import ( "context" "fmt" "github.com/go-kit/kit/endpoint&q ...
- iptables 常用命令示例
一.常用命令示例: 1.命令 -A, --append 范例:iptables -A INPUT -p tcp --dport 80 -j ACCEPT 说明 :新增规则到INPUT规则链中,规则时接 ...
- log4net按级别写到不同文件
<?xml version="1.0" encoding="utf-8"?> <configuration> <configSec ...
- 安装-consul服务发现集群
centos 7.4.x consul 1.2.2 list: 172.16.16.103 172.16.16.112 172.16.16.115 下载: #cd /usr/local/ #wget ...
- 【Gamma】Scrum Meeting 9
目录 写在前面 进度情况 任务进度表 燃尽图 照片 写在前面 例会时间:6.7 22:30-23.00 例会地点:微信群语音通话 代码进度记录github在这里 进度情况 任务进度表 注:点击链接跳转 ...
- [Gamma]Scrum Meeting#10
github 本次会议项目由PM召开,时间为6月5日晚上10点30分 时长15分钟 任务表格 人员 昨日工作 下一步工作 木鬼 撰写博客,组织例会 撰写博客,组织例会 swoip 前端显示屏幕,翻译坐 ...
- centos7.5 搭建上FTP服务
1.安装FTP # 查看ftp 是否安装 rpm -qa | grep vftpd # 安装vsftp yum install -y vsftpd # 设置ftp 开机启动 systemctl ena ...