目标检测算法Faster R-CNN
一:Faster-R-CNN算法组成:
1.PRN候选框提取模块;
2.Fast R-CNN检测模块。
二:Faster-R-CNN框架介绍
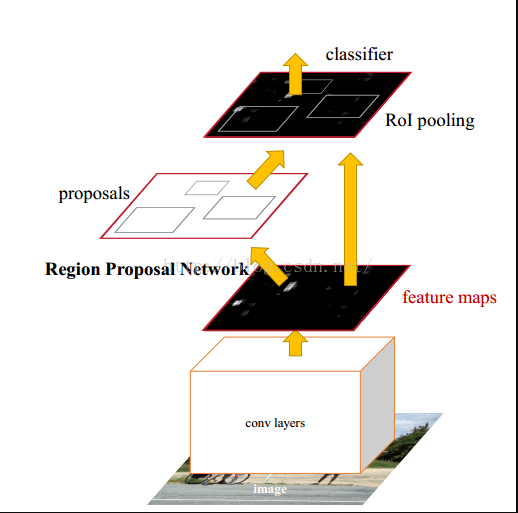
三:RPN介绍
3.1训练步骤:1.将图片输入到VGG或ZF的可共享的卷积层中,得到最后可共享的卷积层的feature map。
2.用一个小网络来卷积这个feature map
2.1在滑动窗口的每个像素点对应的原图片上上设置9个矩形窗口(3种长宽比*3种尺度),称作锚点。
至于这里为什么要在原图上,是因为最后求出来的锚点要跟原图的标定框最小梯度下降。
2.2将卷积的结果和锚点分别输入到两个小的1*1的网络中reg(回归,求目标框的位置)和cls(分类,确定该框中是不是目标)
3.训练集标记好了每个框的位置,和reg输出的框的位置比较,用梯度下降来训练网络
RPN网络把一个任意尺度的图片作为输入,输出一系列的矩形object proposals,每个object proposals都带一个objectness score。我们用一个全卷积网络来模拟这个过程,这一小节描述它。因为我们的最终目标是与Fast R-CNN目标检测网络来共享计算,所以我们假设两个网有一系列相同的卷积层。我们研究了the Zeiler and Fergus model(ZF),它有5个可共享的卷积层,以及the Simonyan and Zisserman model(VGG-16),它有13个可共享的卷积层。
{kind=link}
{kind=link}
为了生成region proposals,我们在卷积的feature map上滑动一个小的网络,这个feature map 是最后一个共享卷积层的输出。这个小网络需要输入卷积feature map的一个n*n窗口。每个滑动窗口都映射到一个低维特征(ZF是256维,VGG是512维,后面跟一个ReLU激活函数)。这个特征被输入到两个兄弟全连接层中(一个box-regression层(reg),一个box-classification层(cls))。我们在这篇论文中使用了n=3,使输入图像上有效的接受域很大(ZF 171个像素,VGG 228个像素)。这个迷你网络在图3(左)的位置上进行了说明。注意,由于迷你网络以滑动窗口的方式运行,所以全连接层在所有空间位置共享。这个体系结构是用一个n*n的卷积层来实现的,后面是两个1*1的兄弟卷积层(分别是reg和cls)。

3.2 Anchors(锚点)
在每个滑动窗口位置,我们同时预测多个region proposals,其中每个位置的最大可能建议的数量表示为k。所以reg层有4 k输出来编码k个box的坐标(可能是一个角的坐 标(x,y)+width+height),cls层输出2 k的分数来估计每个proposal是object的概率或者不是的概率。这k个proposals是k个参考框的参数化,我们把这些proposals叫做Anchors(锚点)。锚点位于问题的滑动窗口中,并与比例和纵横比相关联。默认情况下,我们使用3个尺度和3个纵横比,在每个滑动位置上产生k=9个锚点。对于W *H大小的卷积特性图(通常为2,400),总共有W*H*k个锚点
平移不变性的锚点
我们的方法的一个重要特性是是平移不变性,锚点本身和计算锚点的函数都是平移不变的。如果在图像中平移一个目标,那么proposal也会跟着平移,这时,同一个函数需要能够在任何位置都预测到这个proposal。我们的方法可以保证这种平移不变性。作为比较,the MultiBox method使用k聚类方法生成800个锚点,这不是平移不变的。因此,MultiBox并不保证当一个对象被平移式,会生成相同的proposal。
平移不变性也减少了模型的尺寸,当锚点数k=9时MultiBox有一个(4+1)*800维全连接的输出层,而我们的方法有一个(4+2)*9维的卷积输出层。因此,我们输出层的参数比MultiBox少两个数量级(原文有具体的数,感觉用处不大,没有具体翻译)。如果考虑到feature projection层,我们的建议层仍然比MultiBox的参数少了一个数量级。我们希望我们的方法在像PASCAL VOC这样的小数据集上的风险更小
3.3 损失函数
在计算Loss值之前,作者设置了anchors的标定方法。正样本标定规则:
1) 如果Anchor对应的refrence box 与 ground truth 的 IOU值最大,标记为正样本;
2)如果Anchor对应的refrence box与ground truth的IoU>0.7,标定为正样本。事实上,采用第2个规则基本上可以找到足够的正样本,但是对于一些极端情况,例如所有的Anchor对应的reference box与groud truth的IoU不大于0.7,可以采用第一种规则生成.
3)负样本标定规则:如果Anchor对应的reference box 与 ground truth的IoU<0.3,标记为负样本。
4)剩下的既不是正样本也不是负样本,不用于最终训练。
5)训练RPN的Loss是有classification loss(即softmax loss)和 regression loss(即L1 loss)按一定比重组成的。
在计算Loss值之前,作者设置了anchors的标定方法。正样本标定规则:
1) 如果Anchor对应的refrence box 与 ground truth 的 IOU值最大,标记为正样本;
2)如果Anchor对应的refrence box与ground truth的IoU>0.7,标定为正样本。事实上,采用第2个规则基本上可以找到足够的正样本,但是对于一些极端情况,例如所有的Anchor对应的reference box与groud truth的IoU不大于0.7,可以采用第一种规则生成.
3)负样本标定规则:如果Anchor对应的reference box 与 ground truth的IoU<0.3,标记为负样本。
4)剩下的既不是正样本也不是负样本,不用于最终训练。
5)训练RPN的Loss是有classification loss(即softmax loss)和 regression loss(即L1 loss)按一定比重组成的。
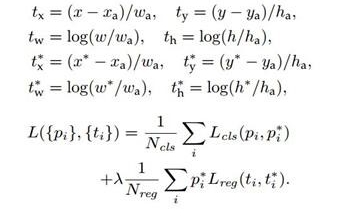
3.4 RPN训练设置
(1)在训练RPN时,一个Mini-batch是由一幅图像中任意选取的256个proposal组成的,其中正负样本的比例为1:1.
(2)如果正样本不足128,则多用一些负样本以满足有256个Proposal可以用于训练,反之亦然.
(3)训练RPN时,与VGG共有的层参数可以直接拷贝经ImageNet训练得到的模型中的参数;剩下没有的层参数用标准差=0.01的高斯分布初始化.
四:.Fast R-CNN 的介绍
4.1 模型的流程图如下
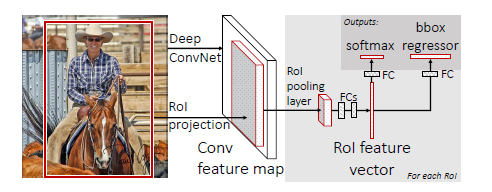
1.1 - 训练
输入是224×224224×224的固定大小图片,经过5个卷积层+2个降采样层(分别跟在第一和第二个卷积层后面),进入ROIPooling层(其输入是conv5层的输出和region proposal,region proposal个数大约为2000个),再经过两个output都为4096维的全连接分别经过output各为21和84维的全连接层(并列的,前者是分类输出,后者是回归输出),最后接上两个损失层(分类是softmax,回归是smoothL1)
4.2 损失函数
多损失融合(分类损失和回归损失融合),分类采用log loss(即对真实分类的概率取负log,分类输出K+1维),回归的loss和R-CNN基本一样。
目标检测算法Faster R-CNN的更多相关文章
- 深度学习笔记之目标检测算法系列(包括RCNN、Fast RCNN、Faster RCNN和SSD)
不多说,直接上干货! 本文一系列目标检测算法:RCNN, Fast RCNN, Faster RCNN代表当下目标检测的前沿水平,在github都给出了基于Caffe的源码. • RCNN RCN ...
- 第三十一节,目标检测算法之 Faster R-CNN算法详解
Ren, Shaoqing, et al. “Faster R-CNN: Towards real-time object detection with region proposal network ...
- 基于候选区域的深度学习目标检测算法R-CNN,Fast R-CNN,Faster R-CNN
参考文献 [1]Rich feature hierarchies for accurate object detection and semantic segmentation [2]Fast R-C ...
- 目标检测算法的总结(R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SSD、FNP、ALEXnet、RetianNet、VGG Net-16)
目标检测解决的是计算机视觉任务的基本问题:即What objects are where?图像中有什么目标,在哪里?这意味着,我们不仅要用算法判断图片中是不是要检测的目标, 还要在图片中标记出它的位置 ...
- (五)目标检测算法之Faster R-CNN
系列博客链接: (一)目标检测概述 https://www.cnblogs.com/kongweisi/p/10894415.html (二)目标检测算法之R-CNN https://www.cnbl ...
- Domain Adaptive Faster R-CNN:经典域自适应目标检测算法,解决现实中痛点,代码开源 | CVPR2018
论文从理论的角度出发,对目标检测的域自适应问题进行了深入的研究,基于H-divergence的对抗训练提出了DA Faster R-CNN,从图片级和实例级两种角度进行域对齐,并且加入一致性正则化来学 ...
- 第二十九节,目标检测算法之R-CNN算法详解
Girshick, Ross, et al. “Rich feature hierarchies for accurate object detection and semantic segmenta ...
- 目标检测算法YOLO算法介绍
YOLO算法(You Only Look Once) 比如你输入图像是100x100,然后在图像上放一个网络,为了方便讲述,此处使用3x3网格,实际实现时会用更精细的网格(如19x19).基本思想是, ...
- FAIR开源Detectron:整合全部顶尖目标检测算法
昨天,Facebook AI 研究院(FAIR)开源了 Detectron,业内最佳水平的目标检测平台. 昨天,Facebook AI 研究院(FAIR)开源了 Detectron,业内最佳水平的目标 ...
随机推荐
- 13-Flutter移动电商实战-ADBanner组件的编写
1.AdBanner组件的编写 我们还是把这部分单独出来,需要说明的是,这个Class你也是可以完全独立成一个dart文件的.代码如下: 广告图片class AdBanner extends Stat ...
- 1129. Shortest Path with Alternating Colors
原题链接在这里:https://leetcode.com/problems/shortest-path-with-alternating-colors/ 题目: Consider a directed ...
- [PA2012]Dwa torty
[PA2012]Dwa torty 题目大意: 给定两个排列\(A_{1\sim n},B_{1\sim n}\),你需要将两个排列用最少的次数消除. 消除只能从头消除,一次消除可以从两个排列的头部取 ...
- linux命令之------Linux文件系统具体目录
Linux文件系统具体目录 (1)/ Linux文件系统的入口,也是处于最高一级的目录 (2)/bin 系统所需要的那些命令处于此目录,比如Is,cp,mkdir等命令:功能和/usr/bin类似 ...
- 第12组 Beta冲刺(3/5)
Header 队名:To Be Done 组长博客 作业博客 团队项目进行情况 燃尽图(组内共享) 展示Git当日代码/文档签入记录(组内共享) 注: 由于GitHub的免费范围内对多人开发存在较多限 ...
- MySQL索引和SQL调优手册
MySQL索引 MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BTree索引,哈希索引,全文索引等等.为了避免混乱,本文将只关注于BTree ...
- hdu5438 Ponds[DFS,STL vector二维数组]
目录 题目地址 题干 代码和解释 参考 题目地址 hdu5438 题干 代码和解释 解答本题时参考了一篇代码较短的博客,比较有意思,使用了STL vector二维数组. 可以结合下面的示例代码理解: ...
- CS224n学习笔记(二)
Global Vectors for Word Representation (GloVe) GloVe 模型包含一个训练在单词-单词的共同出现次数上的加权的最小二乘模型. 什么是Co-occurre ...
- javaagent使用指南
今天打算写一下 Javaagent,一开始我对它的概念也比较陌生,后来在别人口中听到 字节码插桩,bTrace,Arthas后面才逐渐了解到Java还提供了这么个工具. JVM启动前静态Instrum ...
- sql查询最近7天数据(以年-月-日结果展示)
sql代码如下: , 查询结果如下: