sklearn 特征选择
1、移除低方差的特征(Removing features with low variance)
VarianceThreshold 是特征选择中的一项基本方法。它会移除所有方差不满足阈值的特征。默认设置下,它将移除所有方差为0的特征,即那些在所有样本中数值完全相同的特征。
这里的方差是特征值的方差,当特征值都是离散型变量的时候这种方法才能用,如果是连续型变量,就需要将连续变量离散化之后才能用,而且实际当中,一般不太会有95%以上都取某个值的特征存在,所以这种方法虽然简单但是不太好用。
如果先对某特征groupby,然后计算对应的label的均值,再计算均值的方差,这样可能比较有用(方差反映同一特征的不同特征值对标签的区分能力)
2、单变量特征选择(Univariate feature selection) (filter方法)
单变量特征选择能够对每一个特征进行测试,衡量该特征和响应变量之间的关系,根据得分扔掉不好的特征。对于回归和分类问题可以采用卡方检验等方式对特征进行测试。
这种方法比较简单,易于运行,易于理解,通常对于理解数据有较好的效果(但对特征优化、提高泛化能力来说不一定有效);这种方法有许多改进的版本、变种。
2.1 皮尔森相关系数
2.2 互信息和最大信息系数
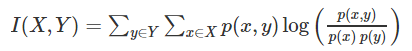
以上就是经典的互信息公式了。想把互信息直接用于特征选择其实不是太方便:1、它不属于度量方式,也没有办法归一化,在不同数据集上的结果无法做比较;2、对于连续变量的计算不是很方便(X和Y都是集合,x,y都是离散的取值,如果是连续变量需要积分),通常变量需要先离散化,而互信息的结果对离散化的方式很敏感。
互信息度量 X 和 Y 共享的信息:它度量知道这两个变量其中一个,对另一个不确定度减少的程度。例如,如果 X 和 Y 相互独立,则知道 X 不对 Y 提供任何信息,反之亦然,所以它们的互信息为零。在另一个极端,如果 X 是 Y 的一个确定性函数,且 Y 也是 X 的一个确定性函数,那么传递的所有信息被 X 和 Y 共享:知道 X决定 Y 的值,反之亦然。因此,在此情形互信息与 Y(或 X)单独包含的不确定度相同,称作 Y(或 X)的熵。而且,这个互信息与 X 的熵和 Y 的熵相同。互信息是非负的.
最大信息系数克服了这两个问题。它首先寻找一种最优的离散化方式,然后把互信息取值转换成一种度量方式,取值区间在[0,1]。http://blog.csdn.net/qtlyx/article/details/50780400 http://www.datamic.com/articles/sf20151126002.html
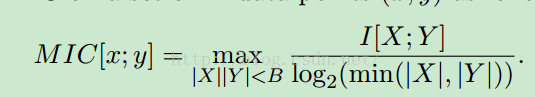
$|X|, |Y|$表示x和y的离散值的数目,B是经验数据,取数据总量的0.6或者0.55次方
3、 使用SelectFromModel选择特征
3.1 基于L1的特征选择(L1-based feature selection)
使用L1范数作为惩罚项的模型会得到稀疏解:大部分特征对应的系数为0。当你希望减少特征的维度以用于其它分类器时,可以通过 feature_selection.SelectFromModel 来选择不为0的系数。特别指出,常用于此目的的稀疏预测模型有 linear_model.Lasso (回归), linear_model.LogisticRegression 和 svm.LinearSVC (分类)
对于SVM和逻辑回归,参数C控制稀疏性:C越小,被选中的特征越少。对于Lasso,参数alpha越大,被选中的特征越少 。
基于L1的稀疏模型的局限在于,当面对一组互相关的特征时,它们只会选择其中一项特征。为了减轻该问题的影响可以使用随机化技术,通过多次重新估计稀疏模型来扰乱设计矩阵,或通过多次下采样数据来统计一个给定的回归量被选中的次数。
RandomizedLasso 实现了使用这项策略的Lasso, RandomizedLogisticRegression 使用逻辑回归,适用于分类任务。要得到整个迭代过程的稳定分数,你可以使用 lasso_stability_path。
3.3 基于树的特征选择(Tree-based feature selection)
基于树的预测模型(见 sklearn.tree 模块,森林见 sklearn.ensemble 模块)能够用来计算特征的重要程度,因此能用来去除不相关的特征(结合 sklearn.feature_selection.SelectFromModel )
随机森林提供了两种特征选择的方法:mean decrease impurity和mean decrease accuracy。
平均不纯度减少 mean decrease impurity
随机森林由多个决策树构成。决策树中的每一个节点都是关于某个特征的条件,为的是将数据集按照不同的响应变量一分为二。利用不纯度可以定义节点,对于分类问题,通常采用基尼指数或者信息增益,对于回归问题,通常采用的是方差或者最小二乘拟合。当训练决策树的时候,可以计算出每个特征减少了多少树的不纯度。对于一个决策树森林来说,可以算出每个特征平均减少了多少不纯度,并把它平均减少的不纯度作为特征选择的值。
使用基于不纯度的方法的时候,要记住:1、这种方法存在偏向,对具有更多类别的变量会更有利(信息增益的缺点);2、对于存在关联的多个特征,其中任意一个都可以作为指示器(优秀的特征),并且一旦某个特征被选择之后,其他特征的重要度就会急剧下降,因为不纯度已经被选中的那个特征降下来了,其他的特征就很难再降低那么多不纯度了,这样一来,只有先被选中的那个特征重要度很高,其他的关联特征重要度往往较低。在理解数据时,这就会造成误解,导致错误的认为先被选中的特征是很重要的,而其余的特征是不重要的,但实际上这些特征对响应变量的作用确实非常接近的(这跟Lasso是很像的)。
平均精确率减少 Mean decrease accuracy
另一种常用的特征选择方法就是直接度量每个特征对模型精确率的影响。主要思路是打乱每个特征的特征值顺序,并且度量顺序变动对模型的精确率的影响。很明显,对于不重要的变量来说,打乱顺序对模型的精确率影响不会太大,但是对于重要的变量来说,打乱顺序就会降低模型的精确率。
http://sklearn.lzjqsdd.com/modules/feature_selection.html
http://blog.csdn.net/bryan__/article/details/51607215
http://www.cnblogs.com/hhh5460/p/5186226.html
sklearn 特征选择的更多相关文章
- sklearn特征选择和分类模型
sklearn特征选择和分类模型 数据格式: 这里.原始特征的输入文件的格式使用libsvm的格式,即每行是label index1:value1 index2:value2这样的稀疏矩阵的格式. s ...
- (数据科学学习手札25)sklearn中的特征选择相关功能
一.简介 在现实的机器学习任务中,自变量往往数量众多,且类型可能由连续型(continuou)和离散型(discrete)混杂组成,因此出于节约计算成本.精简模型.增强模型的泛化性能等角度考虑,我们常 ...
- 【sklearn】特征选择和降维
1.13 特征选择 sklearn.feature_selection模块中的类可以用于样本集上的特征选择/降维,以提高估计器的精度值,或提高其应用在高维数据集上的性能. 1.13.1 删除低方差的特 ...
- 机器学习实战基础(十八):sklearn中的数据预处理和特征工程(十一)特征选择 之 Wrapper包装法
Wrapper包装法 包装法也是一个特征选择和算法训练同时进行的方法,与嵌入法十分相似,它也是依赖于算法自身的选择,比如coef_属性或feature_importances_属性来完成特征选择.但不 ...
- 机器学习实战基础(十七):sklearn中的数据预处理和特征工程(十)特征选择 之 Embedded嵌入法
Embedded嵌入法 嵌入法是一种让算法自己决定使用哪些特征的方法,即特征选择和算法训练同时进行.在使用嵌入法时,我们先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据权值系数从大 ...
- 机器学习实战基础(十五):sklearn中的数据预处理和特征工程(八)特征选择 之 Filter过滤法(二) 相关性过滤
相关性过滤 方差挑选完毕之后,我们就要考虑下一个问题:相关性了. 我们希望选出与标签相关且有意义的特征,因为这样的特征能够为我们提供大量信息.如果特征与标签无关,那只会白白浪费我们的计算内存,可能还会 ...
- 机器学习实战基础(十四):sklearn中的数据预处理和特征工程(七)特征选择 之 Filter过滤法(一) 方差过滤
Filter过滤法 过滤方法通常用作预处理步骤,特征选择完全独立于任何机器学习算法.它是根据各种统计检验中的分数以及相关性的各项指标来选择特征 1 方差过滤 1.1 VarianceThreshold ...
- 机器学习实战基础(十六):sklearn中的数据预处理和特征工程(九)特征选择 之 Filter过滤法(三) 总结
过滤法总结 到这里我们学习了常用的基于过滤法的特征选择,包括方差过滤,基于卡方,F检验和互信息的相关性过滤,讲解了各个过滤的原理和面临的问题,以及怎样调这些过滤类的超参数.通常来说,我会建议,先使用方 ...
- 机器学习实战基础(十三):sklearn中的数据预处理和特征工程(六)特征选择 feature_selection 简介
当数据预处理完成后,我们就要开始进行特征工程了. 在做特征选择之前,有三件非常重要的事:跟数据提供者开会!跟数据提供者开会!跟数据提供者开会!一定要抓住给你提供数据的人,尤其是理解业务和数据含义的人, ...
随机推荐
- scrollTop如何实现click后页面过渡滚动到顶部
用JS操作,body元素的scrollTop var getTop = document.getElementById("get-top"); var head = documen ...
- SQL server的GO用法--巨坑
SQL脚本是一种用SQL语言写的批处理文件(.sql),SQL脚本通常可以由SQL查询分析器来执行. ================================================= ...
- 我的第一个ajax脚本
代码如下 //创建XMLHttpRequest对象 var xmlHttp=null; function creatXMLHttp(){ try{ xmlHttp = new XMLHttpReque ...
- Linux Shell脚本教程:30分钟玩转Shell脚本编程
http://c.biancheng.net/cpp/shell/ Linux在线体验: http://compileonline.com/ Linux命令查询: http://man.linuxde ...
- Atrenta电话面试(C++研发工程师)
1.代码量是多少,你负责哪一块,工作量占%几,改进了什么 2.c++ 和 c 的 区别 3.list 和 vector 的 适用条件 4.hash_map 和 map 的 区别 , 使用h ...
- python基础——14(shelve/shutil/random/logging模块/标准流)
一.标准流 1.1.标准输入流 res = sys.stdin.read(3) 可以设置读取的字节数 print(res) res = sys.stdin.readline() print(res) ...
- 【Oracle】使用dblink+minus方式迁移数据
一.需求说明 1.数据库a104的表syssde.a4_syssde_department中有1000条数据: 2.数据库a230的表syssde.a4_syssde_department中有800条 ...
- git (unable to update local ref )
https://stackoverflow.com/questions/2998832/git-pull-fails-unable-to-resolve-reference-unable-to-upd ...
- 大数据学习——sql练习
1. 现有如下的建表语句和数据: 建表语句 create table student(Sno int,Sname string,Sex string,Sage int,Sdept string)row ...
- 九度oj题目1009:二叉搜索树
题目描述: 判断两序列是否为同一二叉搜索树序列 输入: 开始一个数n,(1<=n<=20) 表示有n个需要判断,n= 0 的时候输入结束. 接 ...