A Node Influence Based Label Propagation Algorithm for Community detection in networks 文章算法实现的疑问
这是我最近看到的一篇论文,思路还是很清晰的,就是改进的LPA算法。改进的地方在两个方面:
(1)结合K-shell算法计算量了节点重重要度NI(node importance),标签更新顺序则按照NI由大到小的顺序更新
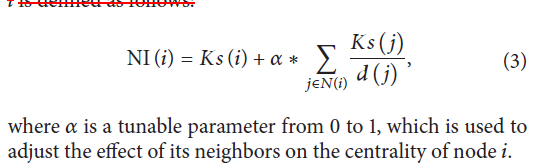
得到ks值后,载计算一下节点邻居ks值和度值d的比值
(2)当出现次数最多的标签不止一个时,再计算一下标签重要度LI(label importance)

其实就是找到节点相同标签的那些令居计算一个合值,看着也不难啊
(3)最后这个算法使用的是异步传播
下面是我实现的代码
function Labelnew=NIBlpa(A,alpha)
% A Node Influence Based Label Propagation Algorithm for
% Community Detection in Networks
% [X,Y,Z] = NIBlpa(A,alpha)
%
% Inputs:
% k - clique size
% A - adjacency matrix
%
% Outputs:
% X - detected communities
% Y - all cliques (i.e. complete subgraphs that are not parts of larger
% complete subgraphs)
% Z - k-clique matrix
%
% Author : Yang Yang
% Email : bethansy@yahoo.com
ks=kshell(A);
n=size(A,1);
D=sum(A,2);
NI=ks;
label = 1:size(A,2);
%%
% calculate NI(node importance)
for i=1:n
Nei=find(A(i,:)==1);
NI(i,2)=ks(i,2)+alpha*sum(ks(Nei,2)./D(Nei));
end
sequence=sortrows(NI,-2);
%%
% Label propagation
Label1 = label;
Labelnew = Label1; while(1)
for i=1:n
% 找到邻居下标对应的标签
nb_lables = Labelnew(A(sequence(i,1),:)==1);
% 只考虑了每个节点至少有一个邻居,如果有孤立节点程序不运行保持原标签
if size(nb_lables,2)>0
x = HistRate(nb_lables);
max_nb_labels = x(x(:,2)==max(x(:,2)),1);
if size(max_nb_labels)==1
Labelnew(sequence(i,1))= max_nb_labels;
else
LI=zeros(length(max_nb_labels),1);
for ma=1:length(max_nb_labels)
Nei=find(A(sequence(i),:));
index=Labelnew(Nei)==max_nb_labels(ma);
LI(ma)=sum(NI(Nei(index),2)./D(Nei(index)));
end
[~,maxx]=max(LI);
Labelnew(sequence(i,1))=max_nb_labels(maxx);
end
end end
% 收敛条件,预防跳跃
if Labelnew==Label1
break;
else
Label1 = Labelnew; end
end
下面是调用K-shell算法的代码
function [kvalue]=kshell(A)
% A :邻接矩阵
% A=load('cdbBA_4000_5_0_.txt');
%
n=size(A,1);
kvalue=zeros(n,2);
kvalue(:,1)=[1:n]';
if find(sum(A,2)==0)
kvalue(sum(A,2)==0,2)=0;
end
a=1;k=1;
% 一层循环主要是叫K-shell中k值,当层层剥掉节点度k的节点后,将这些节点边删除,当网络中不再有小于等于k的节点后,k=k+1
while a
D=sum(A,2);
if sum(D)==0
break;
end
b=1;
% 二层循环主要是找到k层的所有节点
while b
index=find(D<=k&D>0);
if isempty(index)
b=0;continue;
else
A(index,:)=0;
A(:,index)=0;
D=sum(A,2);
kvalue(index,2)=k;
end
end
k=k+1;
end
end
但是后在几个数据集上测试效果都非常不好,例如karate上nmi只有0.2多,但是论文中作者得到的结果却是1,我已经把文章看了几遍还是找不出算法和作者哪里有出入,不过发现改进(2)的公式是错误的源头?抓头???其指教
2017.6.15 更新:用这个代码在人工网络上测试,结果和论文中有是一样的了。但是在实际网络karate、dolphin、football中结果和作者给出的结果相差很大。不知道为什么?
A Node Influence Based Label Propagation Algorithm for Community detection in networks 文章算法实现的疑问的更多相关文章
- LabelRank非重叠社区发现算法介绍及代码实现(A Stabilized Label Propagation Algorithm for Community Detection in Networks)
最近在研究基于标签传播的社区分类,LabelRank算法基于标签传播和马尔科夫随机游走思路上改装的算法,引用率较高,打算将代码实现,便于加深理解. 这个算法和Label Propagation 算法不 ...
- SLAP(Speaker-Listener Label Propagation Algorithm)社区发现算法
其中部分转载的社区发现SLPA算法文章 一.概念 社区(community)定义:同一社区内的节点与节点之间关系紧密,而社区与社区之间的关系稀疏. 设图G=G(V,E),所谓社区发现是指在图G中确定n ...
- 标签传播算法(Label Propagation Algorithm, LPA)初探
0. 社区划分简介 0x1:非重叠社区划分方法 在一个网络里面,每一个样本只能是属于一个社区的,那么这样的问题就称为非重叠社区划分. 在非重叠社区划分算法里面,有很多的方法: 1. 基于模块度优化的社 ...
- Label Propagation Algorithm LPA 标签传播算法解析及matlab代码实现
转载请注明出处:http://www.cnblogs.com/bethansy/p/6953625.html LPA算法的思路: 首先每个节点有一个自己特有的标签,节点会选择自己邻居中出现次数最多的标 ...
- VIPS: a VIsion based Page Segmentation Algorithm
VIPS: a VIsion based Page Segmentation Algorithm VIPS: a VIsion based Page Segmentation Algorithm In ...
- 标签传播算法(Label Propagation)及Python实现
众所周知,机器学习可以大体分为三大类:监督学习.非监督学习和半监督学习.监督学习可以认为是我们有非常多的labeled标注数据来train一个模型,期待这个模型能学习到数据的分布,以期对未来没有见到的 ...
- Affinity Propagation Algorithm
The principle of Affinity Propagation Algorithm is discribed at above. It is widly applied in many f ...
- 论文笔记之:Dynamic Label Propagation for Semi-supervised Multi-class Multi-label Classification ICCV 2013
Dynamic Label Propagation for Semi-supervised Multi-class Multi-label Classification ICCV 2013 在基于Gr ...
- TOTP:Time-based One-time Password Algorithm(基于时间的一次性密码算法)
TOTP:Time-based One-time Password Algorithm(基于时间的一次性密码算法) TOTP - Time-based One-time Password Algori ...
随机推荐
- 2018.10.02 NOIP模拟 序列维护(线段树+广义欧拉定理)
传送门 一道比较好的线段树. 考试时线性筛打错了于是弃疗. 60分暴力中有20分的快速幂乘爆了于是最后40分滚粗. 正解并不难想. 每次区间加打懒标记就行了. 区间查询要用到广义欧拉定理. 我们会发现 ...
- 着重基础之—Spring Boot 编写自己的过滤器
Spring Boot 编写自己的"过滤器" 又好久没有写博客进行总结了,说实话,就是 "懒",懒得总结,懒得动.之所以写这篇博客,是因为最近对接公司SSO服务的时候,需要自定义拦 ...
- win7-64bit下安装Scipy
一直用MAC写python,但京东给的本装的是win7系统,在安装scipy时各种报错,最后错误提示为: no lapack/blas resources found 开始一顿搜,爆栈给出的解决方案是 ...
- SPSS--回归-多元线性回归模型案例解析
多元线性回归,主要是研究一个因变量与多个自变量之间的相关关系,跟一元回归原理差不多,区别在于影响因素(自变量)更多些而已,例如:一元线性回归方程 为: 毫无疑问,多元线性回归方程应该为: 上图中的 x ...
- 删除重复的feature vba VS 删除重复的feature python
VBA: Sub deleteDuplicatedFeature() Dim app As IApplication Set app = Application Dim pMxDocument As ...
- 关于RabbitMQ一点
RabbitMQ是AMQP(高级消息队列协议)的标准实现,理论上可以保证消息发送的准确性 RabbitMQ是用Erlang语言编写的,而Erlang语言具有以下特点: 并发性--Erlang支持超大量 ...
- hdu 5882 Balanced Game 2016-09-21 21:22 80人阅读 评论(0) 收藏
Balanced Game Time Limit: 3000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) To ...
- 几个经典的数学库之一学习---VCGlib(1)
1. VCG Libary是Visulization and Computer Graphics Libary(可视化与计算机图形学库)的缩写,是一个开源的C++模板库,用于三角网格和四面体网格的控制 ...
- SoC开发板设置网口IP为固定IP
vi /etc/network/interfaces 编辑这个文件 #iface eth0 inet dhcp 找到修改这个,前面加# iface eth0 inet static 改为静态分配i ...
- hdu 2086 A1 = ?(数学题)
转载链接 因为:Ai=(Ai-1+Ai+1)/2 - Ci, A1=(A0 +A2 )/2 - C1; A2=(A1 + A3)/2 - C2 , ... => ...