Linux运维四:文件属性及文件权限
一:文件属性
我们使用ls -lhi命令来查看文件时,会列出一堆的文件属性,如:
[root@Gin day7]# ll -hi
total 7.8M
260674 -rw-r--r-- 1 root root 608 Jan 27 09:44 group
260683 ---------- 1 root root 495 Jan 27 09:44 gshadow
260623 -rw-r--r-- 1 root root 1.2K Jan 27 09:43 passwd
260693 -rw-r--r-- 1 root root 7.8M Jan 27 09:46 policy.24
260625 ---------- 1 root root 964 Jan 27 09:43 shadow
#第一列 #第二列 #第三列 #第四列 #第五列 #第六列 #第七列 #第八列
上面的第x列是笔者手动标记的!那么这八列的文件属性各代表什么意思呢?
第一列:inode(index node)索引节点编号:它是文件或目录,在磁盘里的唯一标识,linux读取文件首先要读取到这个索引节点。相当于书的目录。(详细介绍在下面)
第二列:文件类型及文件权限
第一个字符表示文件类型(如上面代码中第二列的第一个字符 - ) d:表示是一个目录,事实上在ext2fs中,目录是一个特殊的文件。 -:表示这是一个普通的文件。 l: 表示这是一个符号链接文件,实际上它指向另一个文件。 b、c:分别表示区块设备和其他的外围设备,是特殊类型的文件。 s、p:这些文件关系到系统的数据结构和管道,通常很少见到。 从第二个字符到最后共9(第2-10个字符)个字符,三个字符为一段:rw-r--r-- 第11个字符:. 与selinux相关,有这个点表示selinux开启,没有这个点表示selinux关闭
第三列:1 表示文件的硬链接数。硬链接是文件的第二个入口!
第四列:root 文件对应的属主或者用户
第五列:root 文件对应的用户组或属组
第六列:文件大小,后面没带单位的都表示字节
第七列:表示文件最后修改的时间
下面详细介绍这几列:
索引节点 inode
1:inode简介
理解inode,要从文件储存说起。文件储存在硬盘上,硬盘的最小存储单位叫做"扇区"(Sector)。每个扇区储存512字节(相当于0.5KB)。操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个"块"(block)。这种由多个扇区组成的"块",是文件存取的最小单位。"块"的大小,最常见的是4KB,即连续八个 sector组成一个 block。文件数据都储存在"块"中,那么很显然,我们还必须找到一个地方储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做inode,中文译名为"索引节点"。
2:inode的内容
inode包含文件的元信息,具体来说有以下内容:
* 文件的字节数
* 文件拥有者的User ID
* 文件的Group ID
* 文件的读、写、执行权限
* 文件的时间戳,共有三个:ctime指inode上一次变动的时间,mtime指文件内容上一次变动的时间,atime指文件上一次打开的时间。
* 硬链接数,即有多少文件名指向这个inode
* 文件数据block的位置
可以用stat命令,查看某个文件的inode信息:
[root@Gin day7]# stat group
File: `group'
Size: 608 Blocks: 8 IO Block: 4096 regular file
Device: 803h/2051d Inode: 260674 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2017-01-27 09:44:02.846298095 +0800
Modify: 2017-01-27 09:44:02.846298095 +0800
Change: 2017-01-27 09:44:02.846298095 +0800
Access:访问时间 (-atime)
Modify:修改时间,内容发生变化(-mtime)
Change:变化时间,包含Modify,权限,属主,用户组 (-ctime)
总之,除了文件名以外的所有文件信息,都存在inode之中。至于为什么没有文件名,下文会有详细解释。
3:inode的大小
inode也会消耗硬盘空间,所以硬盘格式化的时候,操作系统自动将硬盘分成两个区域。一个是数据区,存放文件数据;另一个是inode区(inode table),存放inode所包含的信息。
一个文件被创建后至少要占用一个inode和一个block。如果一个文件很大,可能占多个block(4k);如果文件很小,也要至少占一个block,并且剩余空间不可以使用!
每个inode节点的大小,一般是128字节或256字节。inode节点的总数,在格式化时就给定,一般是每1KB或每2KB就设置一个inode。假定在一块1GB的硬盘中,每个inode节点的大小为128字节,每1KB就设置一个inode,那么inode table的大小就会达到128MB,占整块硬盘的12.8%。
查看每个硬盘分区的inode总数和已经使用的数量,可以使用df命令。
[root@gin day1]# df -i
Filesystem Inodes IUsed IFree IUse% Mounted on
/dev/sda3 479552 54034 425518 12% /
tmpfs 128584 1 128583 1% /dev/shm
/dev/sda1 51200 38 51162 1% /boot
查看每个inode节点的大小,可以用如下命令:
[root@gin day1]# dumpe2fs -h /dev/sda1 | grep "Inode size"
dumpe2fs 1.41.12 (17-May-2010)
Inode size: 128
由于每个文件都必须有一个inode,因此有可能发生inode已经用光,但是硬盘还未存满的情况。这时,就无法在硬盘上创建新文件。
4:inode号码
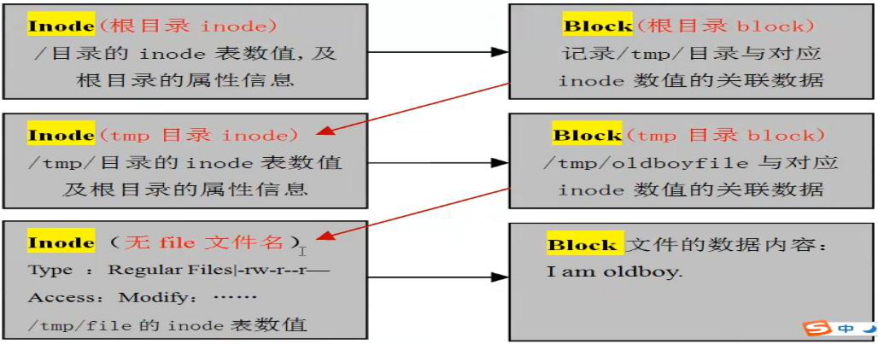
每个inode都有一个号码,操作系统用inode号码来识别不同的文件。这里值得重复一遍,Unix/Linux系统内部不使用文件名,而使用inode号码来识别文件。对于系统来说,文件名只是inode号码便于识别的别称或者绰号。表面上,用户通过文件名,打开文件。实际上,系统内部这个过程分成三步:首先,系统找到这个文件名对应的inode号码;其次,通过inode号码,获取inode信息;最后,根据inode信息,找到文件数据所在的block,读出数据。
使用ls -i命令,可以看到文件名对应的inode号码:
[root@gin day1]# ls -i group
24826 group
5:目录文件
Unix/Linux系统中,目录(directory)也是一种文件。打开目录,实际上就是打开目录文件。目录文件的结构非常简单,就是一系列目录项(dirent)的列表。每个目录项,由两部分组成:所包含文件的文件名,以及该文件名对应的inode号码。
ls命令只列出目录文件中的所有文件名, ls -i命令列出整个目录文件,即文件名和inode号码!
理解了上面这些知识,就能理解目录的权限。目录文件的读权限(r)和写权限(w),都是针对目录文件本身(即不同用户能以什么权限访问操作对该目录文件,例如这里不同用户对tmp目录文件(d可以查出tmp是目录文件,d表示directory,即目录)分别为rwxr-xr-x,第一组的三个字符,即rwx,表示文件拥有者用户的对该文件的读写权限,第二组的三个字符,即r-x,表示文件拥有者用户所在的用户组里的其他用户对该文件的读写权限,第三组的三个字符,即r-x,表示文件拥有者用户所在的用户组以外的用户对该文件的读写权限。一个某个用户下运行的进程访问操作该目录文件只能以该用户所具有的对该目录文件的权限进行操作)。由于目录文件内只有文件名和inode号码,所以如果只有读权限,只能获取文件名,无法获取其他信息,因为其他信息都储存在inode节点中,而读取inode节点内的信息需要目录文件的执行权限(x)。
6:硬链接(hard link)
一般情况下,文件名和inode号码是"一一对应"关系,每个inode号码对应一个文件名。但是,Unix/Linux系统,允许多个文件名指向同一个inode号码。这意味着,可以用不同的文件名访问同样的内容;对文件内容进行修改,会影响到所有文件名;但是,删除一个文件名,不影响另一个文件名的访问。这种情况就被称为"硬链接"(hard link)
ln命令可以创建硬链接:
[root@localhost /]# ln 源文件 目标文件
运行上面这条命令以后,源文件与目标文件的inode号码相同,都指向同一个inode。如:
[root@Gin day7]# ln passwd mypasswd
260623 -rw-r--r-- 2 root root 1184 Jan 28 09:51 mypasswd
260623 -rw-r--r-- 2 root root 1184 Jan 28 09:51 passwd
## inode号码都是260623
inode信息中有一项叫做"链接数",记录指向该inode的文件名总数,这时就会增加1。反过来,删除一个文件名,就会使得inode节点中的"链接数"减1。当这个值减到0,表明没有文件名指向这个inode,系统就会回收这个inode号码,以及其所对应block区域。
这里顺便说一下目录文件的"链接数"。创建目录时,默认会生成两个目录项:"."和".."。前者的inode号码就是当前目录的inode号码,等同于当前目录的"硬链接";后者的inode号码就是当前目录的父目录的inode号码,等同于父目录的"硬链接"。所以,任何一个目录的"硬链接"总数,总是等于2加上它的子目录总数(含隐藏目录),这里的2是父目录对应的“硬链接”和当前目录下的".硬链接“。
7:软链接(soft link)
除了硬链接以外,还有一种特殊情况。文件A和文件B的inode号码虽然不一样,但是文件A的内容是文件B的路径。读取文件A时,系统会自动将访问者导向文件B。因此,无论打开哪一个文件,最终读取的都是文件B。这时,文件A就称为文件B的"软链接"(soft link)或者"符号链接(symbolic link)。
这意味着,文件A依赖于文件B而存在,如果删除了文件B,打开文件A就会报错:"No such file or directory"。这是软链接与硬链接最大的不同:文件A指向文件B的文件名,而不是文件B的inode号码,文件B的inode"链接数"不会因此发生变化。
ln -s命令可以创建软链接:
[root@localhost /]# ln -s 源文文件或目录 目标文件或目录
8:inode的特殊作用
由于inode号码与文件名分离,这种机制导致了一些Unix/Linux系统特有的现象。
1. 有时,文件名包含特殊字符,无法正常删除。这时,直接删除inode节点,就能起到删除文件的作用。
2. 移动文件或重命名文件,只是改变文件名,不影响inode号码。
3. 打开一个文件以后,系统就以inode号码来识别这个文件,不再考虑文件名。因此,通常来说,系统无法从inode号码得知文件名。
第3点使得软件更新变得简单,可以在不关闭软件的情况下进行更新,不需要重启。因为系统通过inode号码,识别运行中的文件,不通过文件名。更新的时候,新版文件以同样的文件名,生成一个新的inode,不会影响到运行中的文件。等到下一次运行这个软件的时候,文件名就自动指向新版文件,旧版文件的inode则被回收。
通过inode号码删除文件举例:
[root@Gin day7]# ll -i
total 4
260623 -rw-r--r-- 1 root root 1184 Jan 28 09:51 passwd
[root@Gin day7]# find ./ -inum 260623|xargs rm -f
[root@Gin day7]# ll
total 0
9:实际问题
在一台配置较低的Linux服务器(内存、硬盘比较小)的/data分区内创建文件时,系统提示磁盘空间不足,用df -h命令查看了一下磁盘使用情况,发现/data分区只使用了66%,还有12G的剩余空间,按理说不会出现这种问题。 后来用df -i查看了一下/data分区的索引节点(inode),发现已经用满(IUsed=100%),导致系统无法创建新目录和文件。
查找原因:
1):可能是/data/cache目录中存在数量非常多的小字节缓存文件,占用的Block不多,但是占用了大量的inode。
2):企业工作中邮件临时队列 /var/spool/clientmquene 这里很容易被大量小文件占满导致 No space left on device错误。clientmquene目录只有安装了sendmail服务,才会有。CentOS5系列的系统会默认安装sendmail服务,因此邮件临时存放地点的路径是:/var/spool/clientmqueue/。CentOS6默认情况下没有安装sendmail服务,而是改装了postfix服务,因此邮件存放地点的路径为 /var/spool/postfix/maildrop/。
3):以上目录被空间垃圾文件占满导致inode数量不够用!
解决方案:
1.删除/data/cache目录中的部分文件,释放出/data分区的一部分inode。
2.用软连接将空闲分区/opt中的newcache目录连接到/data/cache,使用/opt分区的inode来缓解/data分区inode不足的问题:
[root@localhost /]# ln -s /opt/newcache /data/cache
手动清理方法如下:
[root@gin day1]# find /var/spool/clientmqueue/ -type f |xargs rm -f
[root@gin day1]# find /var/spool/postfix/maildrop/ -type f |xargs rm -f
block相关知识
1):磁盘读取数据是按block为单位读取的
2):一个文件可能占用多个block。每读取一个block就会消耗一次磁盘I/O
3):如果要提升磁盘IO属性,那么就要尽可能一次性读取数据尽量的多。
4):一个block只能存放一个文件的内容,无论内容有多小。如果block 4k,存放1K的文件,剩余3K就浪费了。
5):Block并非越大越好。Block太大对于小文件存放就会浪费磁盘空间,例如:1000K的文件,BLOCK为4K,占用250个BLOCK,BLOCK为1K,占用1000个BLOCK。访问效率谁更高?消耗IO分别为250次和1000次。
6):大文件(大于16K)一般设置BLOCK大一点,小文件(小于1K)一般设置BLOCK小一点。
7):BLOCK太大,如4K,文件都是0.1K,大量浪费磁盘空间
8):BLOCK太小,如1K,文件都1000K,消耗磁盘IO
9):BLOCK的设置也是格式化分区的时候,mfs.ext4 -b 2018 -I 256 /dev/sdb
10):文件较大时,block设置大一些会提升磁盘访问效率
11):ext3/ext4文件一般设置为4K
当前的生产环境一般设置为4K。特殊业务,如视频文件可加大block大小
在创建文件系统时,可以使用-b参数改变block大小;-I参数改变inode节点的大小:
[root@Gin day7]# mkfs.ext4 -b 2048 -I 256 /dev/sdb
但实际工作中,一般都不需要去修改,使用默认的即可!
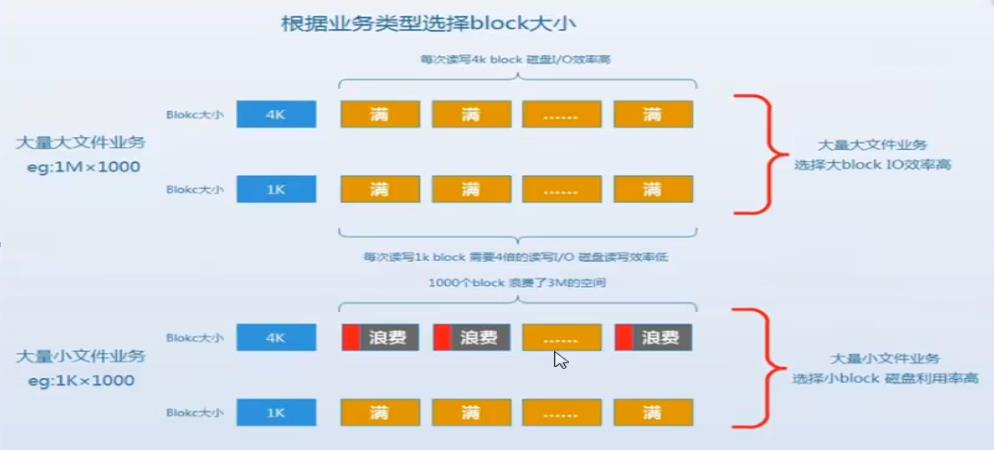
企业面试题:
一个100M(100000K)的磁盘分区,分别写入1K的文件与写入1M的文件,分别可以写多个个?
错误解答:很容易计算1K的个数:100*1000=10000个,1M文件的个数:100/1=100个
假设 B 4K 写入1K文件的数量
假设 inode 数量够多的时候,就是BLOCK的数量。浪费3/4的容量
假设 inode 数量小于block的数量,就是inode的数量。浪费3/4的容量
假设 B 4K 硬盘空间多大,基本上就可以写入100/1M数量,一般情况inode和block都是做够
解答时需要解答下面的知识点:
a:上面的面试题考查的是文件系统inode和block的知识
b:Inode是存放文件属性信息的(也包含指向文件实体的指针),默认大小128byte(c58),256byte(c64)
c:Block是存放文件实际内容的,默认大小1K(boot)或4K(非系统分区默认给4K),一般企业多用4K的block
d:一个文件至少要占用一个inode及一个block
e:默认较大分区常规企业真实场景情况下,inode数量是足够的而block数量会消耗的更快。
正确解答:
1:默认分区常规情况下,对大文件来讲inode是足够的,而block数量消耗的会更快;block为4K的情况,1M的文件不会有磁盘浪费情况,所以文件数量大概为100/1=100个
2:对于小文件0.1K,inode会消耗的更快。默认分区的时候block数量是大于inode数量的,每个小文件都会占用一个inode和一个block。所以最终文件的数量:inode会先消耗完,文件总量是inode的数量。
文件类型与扩展名
基本上,Linux的文件是没有所谓的『扩展名』的,一个Linux文件能不能被执行,与x有关,与文件名根本一点关系也没有。这个观念跟Windows 的情况不相同!在Windows 底下,能被执行的档案扩展名通常是 .com .exe .bat 等,而在Linux下,只要你的权限当中具有 x的话,例如[ -rwx-r-xr-x ] 即代表这个文件可以被执行!但是能执行与能执行成功是不同的。虽然扩展名不起作用但是我们还是希望可以由扩展名了解此文件是什么东西。如:
- .sh : 脚本或者批处理文件(scripts)
- .Z .tar .tar.gz .zip .tgz : 经过打包的压缩文件
- .html .php :网页相关文件
linux的文件类型分为:
b block (buffered) special
c character (unbuffered) special
d directory
p named pipe (FIFO)
f regular file
l symbolic link; this is never true if the -L option or the -follow
option is in effect, unless the symbolic link is broken. If you want
to search for symbolic links when -L is in effect, use -xtype.
s socket
D door (Solaris)
1:普通文件(regular file)
[root@localhost ~]# ls -lh install.log
-rw-r--r-- 1 root root 53K 03-16 08:54 install.log
普通文件包含纯文本文件,二进制文件,数据格式文件;具体是什么类型的普通文件,可通过file命令查看:
[root@Gin day7]# file group
group: ASCII text
2:目录
[root@localhost ~]# ls -lh
总计 14M
-rw-r--r-- 1 root root 2 03-27 02:00 fonts.scale
-rw-r--r-- 1 root root 53K 03-16 08:54 install.log
-rw-r--r-- 1 root root 14M 03-16 07:53 kernel-6.15-1.2025_FC5.i686.rpm
drwxr-xr-x 2 1000 users 4.0K 04-04 23:30 mkuml-2004.07.17
drwxr-xr-x 2 root root 4.0K 04-19 10:53 mydir
drwxr-xr-x 2 root root 4.0K 03-17 04:25 Public
当我们在某个目录下执行ll命令,看到有类似 drwxr-xr-x ,第一个字符以d开头的的文件就是目录,目录在Linux是一个比较特殊的文件。注意它的第一个字符是d。创建目录的命令可以用 mkdir 命令,或cp命令,cp可以把一个目录复制为另一个目录。删除用rm 或rmdir命令。
3:字符设备或块设备文件
如果您进入/dev目录,列一下文件,会看到类似如下的:
[root@localhost ~]# ls -la /dev/tty
crw-rw-rw- 1 root tty 5, 0 04-19 08:29 /dev/tty
[root@localhost ~]# ls -la /dev/hda1
brw-r----- 1 root disk 3, 1 2006-04-19 /dev/hda1
我们看到/dev/tty的属性是 crw-rw-rw- ,注意前面第一个字符是 c ,这表示字符设备文件。比如猫等串口设备
我们看到 /dev/hda1 的属性是 brw-r----- ,注意前面的第一个字符是b,这表示块设备,比如硬盘,光驱等设备;
这个种类型的文件,是用mknode来创建,用rm来删除。目前在最新的Linux发行版本中,我们一般不用自己来创建设备文件。因为这些文件是和内核相关联的。
4:套接口文件
当我们启动MySQL服务时,会产生一个mysql.sock的文件。
[root@localhost ~]# ls -lh /var/lib/mysql/mysql.sock
srwxrwxrwx 1 mysql mysql 0 04-19 11:12 /var/lib/mysql/mysql.sock
注意这个文件的属性的第一个字符是 s。我们了解一下就行了。
5:符号链接文件
[root@localhost ~]# ls -lh setup.log
lrwxrwxrwx 1 root root 11 04-19 11:18 setup.log -> install.log
当我们查看文件属性时,会看到有类似 lrwxrwxrwx,注意第一个字符是l,这类文件是链接文件。是通过ln -s 源文件名 新文件名。上面是一个例子,表示setup.log是install.log的软链接文件。怎么理解呢?这和Windows操作系统中的快捷方式有点相似。
符号链接文件的创建方法举例;
[root@localhost ~]# ls -lh kernel-6.15-1.2025_FC5.i686.rpm
-rw-r--r-- 1 root root 14M 03-16 07:53 kernel-6.15-1.2025_FC5.i686.rpm
[root@localhost ~]# ln -s kernel-6.15-1.2025_FC5.i686.rpm kernel.rpm
[root@localhost ~]# ls -lh kernel*
-rw-r--r-- 1 root root 14M 03-16 07:53 kernel-6.15-1.2025_FC5.i686.rpm
lrwxrwxrwx 1 root root 33 04-19 11:27 kernel.rpm -> kernel-6.15-1.2025_FC5.i686.rpm
硬链接与软链接
硬链接知识小结
1:具有相同的inode节点的多个文件是互为硬链接文件
2:删除硬链接文件或删除源文件任意之一,文件实体并不受影响
3:只有删除了源文件及所有对应的硬链接文件,文件实体才会被删除
4:当所有的硬链接文件及源文件被删除后,再存放新的数据会占用这个文件的空间或者磁盘fsck检查的时候,删除的数据也会被系统回收
5:硬链接文件就是文件的另一个入口(相当于超市的前门后门)
6:可以通过给文件设置硬链接文件,来防止重要文件被误删除
7:通过执行命令“ln 源文件 硬链接文件”,可完成创建硬链接
8:硬链接文件可以用rm命令删除
9:对于静态文件(没有进程正在调用的文件)来讲,当对应硬链接数为0(i_link),文件就被删除。i_link的查看方法:ls -l
软链接知识小结
软链接原理图:

1)软件链接类似windows的快捷方式(可以通过readlink查看其指向)
2)软链接类似一个文本文件,里面存放的是源文件的路径,指向源文件实体
3)删除源文件,软链接依然存在,但是无法访问指向的源文件路径内容
4)失效的时候一般是白字红底闪烁提示

5)执行命令“ln -s 源文件 软链接文件”,即可完成创建软链接
6)软链接和源文件是不同类型的文件,也是不同的文件,inode号也不相同
7)删除软链接文件可以用rm命令。
目录链接知识小结
1)对于目录,不可以创建硬链接,但可以创建软链接
2)对于目录的软链接是生产场景运维中常用技巧(看linux命令关中apache考试题)
3)目录的硬链接不能跨越文件系统(从硬链接原理可以理解)
4)每个目录下面都有一个硬链接“.”号,和对应上级目录的硬链接“..”号
5)在父目录里创建一个子目录,父目录的连接数增加1(因为子目录里都有..来指向父目录);但在父目录里创建文件,父目录的链接不会增加!
企业面试题:描述下linux下软链接和硬链接的区别(记时2分钟)
解答:
在linux系统中,链接分两种:一种为硬链接(Hard Link),另一种为符号链接或软链接(Soft Link)
1)默认不带参数情况下,ln命令创建的是硬链接,带-s参数的创建的是软链接
2)硬链接文件与源文件的inode节点号相同,而软链接文件的inode节点号与源文件不同
3)ln命令不能对目录创建硬链接,但可以创建软链接,对目录的软链接会经常被用到
4)删除软链接文件,对源文件及硬链接文件无任何影响
5)删除硬链接文件,对源文件及软链接文件无任何影响
6)删除链接文件的源文件,对硬链接文件无影响,但会导致其软件失效(红底白字闪烁状)
7)同时删除源文件及其硬链接文件,整个文件才会被真正的删除
8)很多硬件设备中的快照功能,使用的就是类似硬链接的原理
9)软链接可以跨文件系统,硬链接不可以跨文件系统
企业面试答题必胜思路:
1、介绍软硬链接的概念
2、对于文件的软硬链接区别
3、对于目录的软硬链接区别
用户与用户组
用户是能够获取系统资源的权限的集合。用户的角色是通过UID与GID来识别的!
linux用户组的分类:
a.管理员 root :具有使用系统所有权限的用户,其UID 为0.
b.普通用户 : 即一般用户,其使用系统的权限受限,其UID为500-60000之间.
c.虚拟用户 : 保障系统运行的用户,一般不提供密码登录系统,其UID为1-499之间.在/etc/passwd文件中都是以/sbin/nologin结尾的账户
与用户有关的文件
/etc/passwd,/etc/shadow
/etc/passwd:(有关passwd文件中各个字段的详细说明见:http://www.cnblogs.com/ginvip/p/6351740.html)
其格式:account:password:UID:GID:GECOS:diretory:shell
account: 用户名或帐号
password :用户密码占位符
UID:用户的ID号
GID:用户所在组的ID号
GECOS:用户的详细信息(如姓名,年龄,电话等)
diretory:用户所的家目录
shell:用户所在的编程环境
/etc/shadow:
其格式:account:password:最近更改密码的日期:密码不可更该的天数:密码需要重新更改的天数:密码更改前的警告期限:密码过期的宽限时间:帐号失效日期:保留
用户组
用户组分类;
a. 普通用户组:可以加入多个用户
b. 系统组:一般加入一些系统用户
c. 私有组(也称基本组):当创建用户时,如果没有为其指明所属组,则就为其定义一个私有的用户组,起名称与用户名同名.
注:私有组可以变成普通用户组,当把其他用户加入到该组中,则其就变成了普通组
组是权限的容器:如普通用户 a,b,c 所属组grp,则它们会继承组grp的权限
与组有关的文件:/etc/group,/etc/gshadow
/etc/group文件: 其格式:group_name:passwoerd:GID:user_list
group_name:组名
passwoerd:组密码
GID:组的ID号
user_list:以group_name为附加组的用户列表
修改用户及用户组的命令:useradd,usermod, groupdd,userdel
a.增加用户 :useradd [options] username
options:
1.-u :UID
2.-g :GID
3.-d :指定用户家目录,默认是/home/username
4.-s :指定用户所在的shell环境
5.-G:指定用户的附加组
例如:增加一用户wendy UID为1888 家目录/home/oracle,shell为/bin/sh
#useradd –u 1888 –d /home/oracle –s /bin/sh wendy
b.修改用户:usermod [options] username
options:
1.-u :UID
2.-g :GID
3.-d :指定用户家目录,默认是/home/username
-m 与-b 一起用表示把用户家目录的内容也移走
4.-s :指定用户所在的shell环境
5.-G:指定用户的附加组
例如:修改用户wendy UID为1000 家目录/oracle,shell为/bin/bash
#usermod –u 1000 –d /oracle –s /bin/bash -m wendy
c.增加用户组:groupadd [options] groupname
options
1.-g :GID
例如:增加用户组grp UID为1001
#groupadd –g 1001 grp
d.删除用户:userdel [options]username
options
1.-r :连同家目录一起删除
例如:删除用户wendy及家目录
#userdel –r wendy
文件各类时间戳
[root@Gin gin]# ll
total 8
drwxr-xr-x 2 root root 4096 Jan 28 12:25 scripts
drwxr-xr-x 5 root root 4096 Jan 25 18:01 tools
## 上面的时间格式是默认的时间格式,表示最近一次的修改时间 [root@Gin gin]#
[root@Gin gin]# ll --time-style=long-iso
total 8
drwxr-xr-x 2 root root 4096 2017-01-28 12:25 scripts
drwxr-xr-x 5 root root 4096 2017-01-25 18:01 tools [root@Gin gin]# ll --time-style=iso
total 8
drwxr-xr-x 2 root root 4096 01-28 12:25 scripts
drwxr-xr-x 5 root root 4096 01-25 18:01 tools [root@Gin gin]# ll --time-style=full-iso
total 8
drwxr-xr-x 2 root root 4096 2017-01-28 12:25:53.109249645 +0800 scripts
drwxr-xr-x 5 root root 4096 2017-01-25 18:01:22.824747428 +0800 tools
Linux文件权限
linux普通文件的读,写,执行权限说明:
可读r:表示具有读取/阅读文件内容的权限
可写w:表示具有新增,修改文件内容的权限
(如果没有r,那vi无法编辑,强制编辑的话会覆盖数据,echo可以追加)
(特别提示:删除文件,包括修改文件名等,的权限受父目录的权限控制,和文件本身权限的控制)
可执行x:表示具有可执行文件的权限
(1:文件本身要能够执行 2:普通用户同时还需要具备r的权限才能 3:root都可执行)
Linux文件删除原理:
Linux是通过link的数量来控制文件删除的,只有当一个文件不存在任何link的时候,这个文件才会被删除。一般来说,每个文件都有2个link计数器:i_count 和 i_link。
i_count的意义是当前文件使用者(或被调用)的数量,i_link 的意义是介质连接的数量(硬链接的数量);可以理解为i_count是内存引用计数器,i_link是磁盘的引用计数器。
当一个文件被某一个进程引用时,对应i_count数就会增加;当创建文件的硬链接的时候,对应i_link数就会增加。
对于删除命令rm而言,实际就是减少磁盘引用计数i_link。这里就会有一个问题,如果一个文件正在被某个进程调用,而用户却执行rm操作把文件删除了,那么会出现什么结果呢?当用户执行rm操作删除文件后,再执行ls或者其他文件管理命令,无法再找到这个文件了,但是调用这个删除的文件的进程却在继续正常执行,依然能够从文件中正确的读取及写入内容。这又是为什么呢?
这是因为rm操作只是将文件的i_link减少了,如果没其它的链接i_link就为0了;但由于该文件依然被进程引用,因此,此时文件对应的i_count并不为0,所以即使执行rm操作,但系统并没有真正删除这个文件,当只有i_link及i_count都为0的时候,这个文件才会真正被删除。也就是说,还需要解除该进程的对该文件的调用才行。
以上讲的i_link及i_count是文件删除的真实条件,但是当文件没有被调用时,执行了rm操作删除文件后是否还可以找回被删的文件呢?
前面说了,rm操作只是将文件的i_link减少了,或者说置0了,实际就是将文件名到inode的链接删除了,此时,并没有删除文件的实体即(block数据块),此时,如果及时停止机器工作,数据是可以找回的,如果此时继续写入数据,那么当新数据就可能会被分配到被删除的数据的block数据块,此时,文件就会被真正的回收了,那时就是神仙也没有办法了。

Linux读文件的流程图:
修改权限
1:chmode command
Format : chmod [数字组合] 文件名
对应的数值(八进制)→ r : 4 , w : 2, x : 1 , - 0
/以下面的test.sh文件为例:
[root@gin tmp]# ll
total 4
-rw-r--r-- 1 gin incahome 16 Oct 7 08:41 test.sh
[root@gin tmp]# chmod 531 test.sh
[root@gin tmp]# ll
total 4
-r-x-wx--x 1 gin incahome 16 Oct 7 08:49 test.sh
chmod [用户类型] [+| - | =] [权限字符] 文件名
|
chmod |
用户类型 |
操作字符 |
权限字符 |
文件或目录 |
|
u (user) |
+ (加入权限) |
r |
||
|
g (group) |
- |
|||
|
o (others) |
- (减去权限) |
w |
||
|
a (all) |
= (设置) |
x |
[root@gin tmp]# chmod u+x,g=x test.sh
chmod有个很重要的参数 -R ,表示递归修改权限(文件夹及文件夹下所有文件都修改权限)
[root@gin tmp]# chmod -R 777 poe
[root@gin tmp]# ll poe/
total 0
-rwxrwxrwx 1 root root 0 Oct 7 09:17 1.txt
-rwxrwxrwx 1 root root 0 Oct 7 09:17 2.txt
-rwxrwxrwx 1 root root 0 Oct 7 09:17 3.txt
生产案例:为防止木马入侵,文件和目录给什么权限,安全临界点(文件夹及文件只读)
目录设为755 root root;文件设为644 root root
默认权限分配umask
文件权限计算小结论:
创建文件默认最大权限为666 (-rw-rw-rw-),默认创建的文件没有可执行权限x位。
对于文件来说,umask的设置是在假定文件拥有八进制666的权限上进行的,文件的权限就是666减去umask(umask的各个位数字也不能大于6,如,077就不符合条件)的掩码数值;重点在接下来的内容,如果umask的部分位或全部位为奇数,那么,在对应为奇数的文件权限位计算结果分别再加1就是最终文件权限值。
创建目录默认最大权限777(-rwx-rwx-rwx),默认创建的目录属主是有x权限,允许用户进入。对于目录来说,umask的设置是在假定文件拥有八进制777权限上进行,目录八进制权限777减去umask的掩码数值。
文件权限的一般计算方法:
默认文件权限计算方法
1)假设umask值为:022(所有位为偶数)
6 6 6 ==>文件的起始权限值
0 2 2 - ==>umask的值
---------
6 4 4
2)假设umask值为:045(其他用户组位为奇数)
6 6 6 ==>文件的起始权限值
0 4 5 - ==>umask的值
---------
6 2 1 ==>计算出来的权限。由于umask的最后一位数字是5,所以,在其他用户组位再加1。
0 0 1 +
---------
622 ==>真实文件权限
默认目录权限计算方法
7 7 7 ==>目录的起始权限值
0 2 2 - ==>umask的值
---------
7 5 5
规范成图表如下:
|
默认最大权限 |
umask值 |
用户创建的权限 |
|
|
创建文件(umask所有位为偶数)时: |
666 |
022 (全为偶数) |
644 |
|
-rw-rw-rw- |
-----w--w- |
-rw-r--r-- |
|
|
偶数加减法:(默认最大权限) - (umask权限) = (用户创建的权限) |
|||
|
创建文件(umask部分或全部位为奇数)时: |
666 |
123(部分位为奇数) --x--w--wx |
644(因为umask的值123中有2个位都是奇数,因此在计算结果543的基础上再加101,即奇数位对应的文件数字权限分别加1即可) |
|
-rw-rw-rw- |
-rw-r--r-- |
||
|
说明:(默认最大权限)-(umask权限)+(umask奇数对应权限位加1)=(用户创建的权限) |
|||
|
创建目录时: |
777 |
022 |
755 |
|
-rwxrwxrwx |
-----w--w- |
-rwxr-xr-x |
|
|
说明:(默认最大权限)-(umask权限)=(用户创建的权限) |
|||
umask的作用就是控制目录及文件的权限默认值!
控制文件:
[root@gin tmp]# sed -n '65,69p' /etc/bashrc
if [ $UID -gt 199 ] && [ "`id -gn`" = "`id -un`" ]; then
umask 002
else
umask 022
fi
企业面试:什么是umask,作用是什么,怎么计算文件和目录的默认权限
setuid 与 setgid 位
[gin@gin ~]$ ll `which passwd`
-rwsr-xr-x. 1 root root 25980 Feb 22 2012 /usr/bin/passwd
//这里的s就是setuid,s位如果原来有x权限,那么这位就是s,如果后来没有x权限,那这位就是S
如果普通用户本来没有删除文件的权限,但给rm 命令的权限加上s位后,即使普通用户的权限再低,也可以删除作任何文件
查找系统有s位权限的文件:
[root@gin test]# find / -type f -perm 4755|xargs ls -l
-rwsr-xr-x. 1 root root 77452 Oct 15 2014 /bin/mount
-rwsr-xr-x. 1 root root 36892 Sep 26 2013 /bin/ping
.............
suid知识小结:针对命令和二进制程序的
1)用户或属主对应的前三位权限的x位上如果有s就表示suid权限,当x位上没有小写x执行权限的时候,suid的权限显示的就是大写的S
2)suid作用就是让普通用户可以以root(或其他)的用户角色运行只有root(或其他)账号才能运行的程序或命令,或程序命令对应本来没有权限操作的文件等!(注意和 su 及 sudo的区别),suid为某一个命令设置特殊权限(使用者为所有人)!通过对rm命令设置suid加深对suid的理解
3)问题:希望poe(普通用户)能够删除本来没有权限删除的文件
a:sudo给poe授权rm b:给rm命令设置suid c:设置上级目录权限
4)suid修改的是执行的命令passwd,而不是处理目标文件/etc/passwd
5)仅对二进制命令程序有效,不能用在shell等类似脚本文件上
6)二进制命令程序需要有可执行权限x配置
7)suid权限仅在程序命令执行过程中有效
8)执行suid命令的任意系统用户都可以获得该命令在执行期间对应的文件所有者权限
9)suid是把又刃剑,是一个比较危险的功能,对系统安全有一定的威胁。系统suid的无用功能取消suid权限(安全优化)
实例一:umask所有位全为偶数时,多数读者对这个例子无疑问
[root@oldboy oldboy]# umask
0022 #→umask当前数值
[root@oldboy oldboy]# umask 044 #→更改为044
[root@oldboy oldboy]# umask
0044
[root@oldboy oldboy]# mkdir umask_test #→建目录测试
[root@oldboy oldboy]# ls -ld umask_test
drwx-wx-wx 2 root root 4096 Nov 12 19:21 umask_test #→对应数字权限为733,是不是符合上面的计算方法?
[root@oldboy oldboy]# touch umask_test.txt
[root@oldboy oldboy]# ls -l umask_test.txt
-rw--w--w- 1 root root 0 Nov 12 19:21 umask_test.txt #→对应数字权限为622,是不是符合上面的计算方法?
实例二:umask值的部分或全部位为奇数时,这个是读者疑问最大的
当umask值的其他属组位为奇数时:
[root@oldboy oldboy]# umask 0023
[root@oldboy oldboy]# mkdir dir
[root@oldboy oldboy]# touch file
[root@oldboy oldboy]# ls -l
总计 4
drwxr-xr-- 2 root root 4096 11-15 01:04 dir #→对应数字权限为754
-rw-r--r-- 1 root root 0 11-15 01:04 file #→对应数字权限为644
提示:根据前面的计算方法,当umask为0023时,dir的权限应该是754,而file的权限应该为643,但是由于umask的其他组位为奇数,因此最终权限为其他组位加1,即643加001(对应实践结果644)。注意:umask为偶数的位不要加1。
实例三:umask值的所有位为奇数时
[root@oldboy oldboy]# umask 0551
[root@oldboy oldboy]# umask
0551
umask 为0551 根据掩码方法计算:目录权限为226,文件权限115,而实际文件权限为226(umask的三个权限位都是奇数,所以,每个位分别加1就是正确的权限)
[root@oldboy oldboy]# mkdir dir5
[root@oldboy oldboy]# touch file5
[root@oldboy oldboy]# ls -l
总计 4
d-w--w-rw- 2 root root 4096 11-15 01:27 dir5 #→目录对应数字权限为226
--w--w-rw- 1 root root 0 11-15 01:27 file5 #→目录对应数字权限为226
再来一例验证下:
[root@oldboy oldboy]# umask 0333
[root@oldboy oldboy]# umask
0333
umask 为0333 根据掩码方法计算:目录权限为444,文件权限333,而实际文件权限为444(umask的三个位都是奇数,所以,每个位分别加1就是正确的权限)
[root@oldboy oldboy]# mkdir dir3
[root@oldboy oldboy]# touch file3
[root@oldboy oldboy]# ls -l|grep 3
dr--r--r-- 2 root root 4096 11-15 01:30 dir3 #→目录对应数字权限为444
-r--r--r-- 1 root root 0 11-15 01:30 file3 #→目录对应数字权限为444
粘滞位 sticky bit (sbit)及设置方法
粘滞位的理解,我们先看一个例子:
[root@gin test]# ll -d /tmp/
drwxrwxrwt. 4 root root 4096 Oct 7 10:07 /tmp/
我们看到/tmp权限位最后的一个字母是t。这就是粘滞位。
粘滞位的设置,用八进制的1000位来表示。粘滞位的用途一般是把一个文件夹的权限都打开,然后来共享文件,让多个用户都具有写权限,像/tmp目录一样,每个用户只能删自己创建的文件。方便带来安全隐患,生产环境我们一般不这样使用!
特殊权限对应的数字小结:
suid 4000权限字符 s or S,用户位上的x位上设置。授权方法:chmod 4755 poe.txt
sgid 2000 权限字符s or S,用户组位的x位上设置。授权方法:chmod 2755 poe.txt
粘滞位1000 权限字符t or T,其他用户位的x位上设置。授权方法:chmod 1755 poe.txt
如果对应位有x权限,字符权限表现为小写,否则表现为大写!
设置方法:
chmod g+s test
chmod u+s test
chmod o+t test
chmod 7755 test
2:修改用户组
[root@gin test]# chgrp poe /tmp/3.txt
[root@gin test]# chgrp -R poe /tmp/3.txt
此命令一般用的比较少,可使用chown命令替代此命令:
[root@gin tmp]# chown poe 2.txt
[root@gin tmp]# chown root.root 2.txt //这里的点也可以使用 : 代替
[root@gin tmp]# chown :incahome 2.txt //只修改组
[root@gin tmp]# chown -R poe.poe poe //递归修改目录的用户和组
特别提示:要修改用户和用户组必须是系统中已经存在的!
当把一个文件的属主与属组删除时,ll命令查看时会以uid and gid 显示:
[root@gin tmp]# ll
total 8
-rw-r--r-- 1 poe poe 0 Oct 7 09:17 2.txt
-rw-r--r-- 1 root poe 0 Oct 7 09:17 3.txt
-rw-r--r-- 1 804 805 0 Oct 7 14:53 gin.txt
drwxrwxrwx 2 poe poe 4096 Oct 7 09:17 poe
-rwx--xr-x 1 804 805 16 Oct 7 08:49 test.sh
可使用useradd命令指定uid and gid创建用户,再次查看时就会显示名称:
[root@gin tmp]# groupadd -g 805 incahome
[root@gin tmp]# useradd -u 804 -g incahome gin
[root@gin tmp]# ll
total 8
-rw-r--r-- 1 poe poe 0 Oct 7 09:17 2.txt
-rw-r--r-- 1 root poe 0 Oct 7 09:17 3.txt
-rw-r--r-- 1 gin incahome 0 Oct 7 14:53 gin.txt
drwxrwxrwx 2 poe poe 4096 Oct 7 09:17 poe
-rwx--xr-x 1 gin incahome 16 Oct 7 08:49 test.sh
chattr与lsattr命令详解
有时候你发现用root权限都不能修改某个文件,大部分原因是曾经用chattr命令锁定该文件了。chattr命令的作用很大,其中一些功能是由Linux内核版本来支持的,不过现在生产绝大部分跑的linux系统都是2.6以上内核了。通过chattr命令修改属性能够提高系统的安全性,但是它并不适合所有的目录。chattr命令不能保护/、/dev、/tmp、/var目录。lsattr命令是显示chattr命令设置的文件属性。
这两个命令是用来查看和改变文件、目录属性的,与chmod这个命令相比,chmod只是改变文件的读写、执行权限,更底层的属性控制是由chattr来改变的。
chattr命令的用法:chattr [ -RVf ] [ -v version ] [ mode ] files…
最关键的是在[mode]部分,[mode]部分是由+-=和[ASacDdIijsTtu]这些字符组合的,这部分是用来控制文件的属性。
+ :在原有参数设定基础上,追加参数。
- :在原有参数设定基础上,移除参数。
= :更新为指定参数设定。
A:文件或目录的 atime (access time)不可被修改(modified), 可以有效预防例如手提电脑磁盘I/O错误的发生。
S:硬盘I/O同步选项,功能类似sync。
a:即append,设定该参数后,只能向文件中添加数据,而不能删除,多用于服务器日志文件安全,只有root才能设定这个属性。
c:即compresse,设定文件是否经压缩后再存储。读取时需要经过自动解压操作。
d:即no dump,设定文件不能成为dump程序的备份目标。
i:设定文件不能被删除、改名、设定链接关系,同时不能写入或新增内容。i参数对于文件 系统的安全设置有很大帮助。
j:即journal,设定此参数使得当通过mount参数:data=ordered 或者 data=writeback 挂 载的文件系统,文件在写入时会先被记录(在journal中)。如果filesystem被设定参数为 data=journal,则该参数自动失效。
s:保密性地删除文件或目录,即硬盘空间被全部收回。
u:与s相反,当设定为u时,数据内容其实还存在磁盘中,可以用于undeletion。
各参数选项中常用到的是a和i。a选项强制只可添加不可删除,多用于日志系统的安全设定。而i是更为严格的安全设定,只有superuser (root) 或具有CAP_LINUX_IMMUTABLE处理能力(标识)的进程能够施加该选项。
应用举例:
1、用chattr命令防止系统中某个关键文件被修改:
# chattr +i /etc/resolv.conf
然后用mv /etc/resolv.conf等命令操作于该文件,都是得到Operation not permitted 的结果。vim编辑该文件时会提示W10: Warning: Changing a readonly file错误。要想修改此文件就要把i属性去掉: chattr -i /etc/resolv.conf
# lsattr /etc/resolv.conf
会显示如下属性
----i-------- /etc/resolv.conf
2、让某个文件只能往里面追加数据,但不能删除,适用于各种日志文件:
# chattr +a /var/log/messages
企业案例:
如果向磁盘写入数据提示如下错误:No space left on device,通过df -h查看磁盘空间,发现没满,请问可能原因是什么?
解答:可能是inode数量被消耗尽了!可使用df -i查看inode是否被消耗尽了!
企业工作中邮件临时队列/var/spool/clientmquene这里很容易被大量小文件占满导致No space left on device的错误。clientmquene目录只有安装了sendmial服务才会有。
CentOS5.8默认就会安装sendmial服务,因此邮件临时存放地点的路径为/var/spool/clientmquene;
CentOS6.6默认没有sendmial,而是改装了Postfix服务,因此邮件存放地点的路径为/var/spool/postfix/maildrop!
以上两个目录很容易被垃圾文件填满导致系统的inode数量不够用,从而导致无法存储新文件。
手动清理的方法:
[root@Gin day7]# find /var/spool/clientmquene/ -type f|xargs rm -f ## CentOS5.xx
[root@Gin day7]# find /var/spool/postfix/maildrop/ -type f|xargs rm -f ## CentOS6.x
定时清理的方法为:将上述命令写成脚本,然后做定时任务,每天晚上0点执行一次清理任务!
本节word文件地址:http://wenku.baidu.com/view/f1aee7f57d1cfad6195f312b3169a4517723e51b
Linux运维四:文件属性及文件权限的更多相关文章
- LINUX运维实战案例之文件已删除但空间不释放问题的分析与解决办法
1.错误现象 运维的监控系统发来通知,报告一台服务器空间满了,登陆服务器查看,根分区确实没有空间了,如下图所示: 这里首先说明一下服务器的一些删除策略,由于Linux没有回收站功能,我们的线上服务器所 ...
- Linux运维实战——如何利用文件节点删除乱码文件
引言 linux系统中删除文件可以用rm [filename] 命令,然而有些系统或程序自动生成的文件或者文件夹名称却是乱码. 虽然部分文件/文件夹可以通过复制粘贴名字的方式来删除,但是仍然有些文件无 ...
- Linux运维人员共用root帐户权限审计
Linux运维人员共用root帐户权限审计 2016-11-02 运维部落 一.应用场景 在中小型企业,公司不同运维人员基本都是以root 账户进行服务器的登陆管理,缺少了账户权限审计制度.不出问题还 ...
- Linux 运维工程师学习成长路线上要经历哪四个阶段?
之前曾看到一篇新闻,Linux之父建议大家找一份基于Linux和开源环境的工作.今天就来聊一聊我的想法,本人8年Linux运维一线经验,呆过很多互联网公司,从一线运维做到运维架构师一职,也见证了中国运 ...
- Linux运维入门到高级全套常用要点
Linux运维入门到高级全套常用要点 目 录 1. Linux 入门篇................................................................. ...
- linux运维中的命令梳理(二)
回想起来,从事linux运维工作已近5年之久了,日常工作中会用到很多常规命令,之前简单罗列了一些命令:http://www.cnblogs.com/kevingrace/p/5985486.html今 ...
- Linux运维笔记-日常操作命令总结(2)
回想起来,从事linux运维工作已近5年之久了,日常工作中会用到很多常规命令,之前简单罗列了一些命令:http://www.cnblogs.com/kevingrace/p/5985486.html今 ...
- 第一阶段·Linux运维基础-第1章·Linux基础及入门介绍
01-课程介绍-学习流程 02-服务器硬件-详解 03-服务器核心硬件-服务器型号-电源-CPU 01-课程介绍-学习流程 1.1. 光看不练,等于白干: 1.2 不看光练,思想怠慢: 1.3 即看又 ...
- Linux运维笔记--第三部
第三部 3. Linux系统文件重要知识初步讲解 # ls -lhi (i: inode,每个文件前的数字代表文件身份ID:h: human 人类可读) 显示:25091 -rw-r--r-- ...
随机推荐
- "prefs:root" or "App-Prefs:root"
iOS 苹果审核也是看心情的吗?已经上线几个版本了,新版本提交审核居然被查出来了! Guideline 2.5.1 - Performance - Software Requirements Your ...
- Xcode中的Target
Xcode中的Target,主要包含下面几点知识: Target依赖 Build Phase Build Rule Target依赖 Target的依赖关系表示一个Target要构建成功,必先依赖于其 ...
- 敏捷开发与XP实践
北京电子科技学院(BESTI) 实 验 报 告 课程: Java 班级:1352 姓名:黄伟业 学号:20135215 成绩: ...
- Jsp----注册登陆
一.需求分析 目前99%的网站都会有用户的登陆注册界面(用户就是一切嘛).其需求可想而知. 二.设计过程及所查寻资料 通过寻找上课老师所给予的课件,搜寻相关内容:目前以获取相关有java web关于w ...
- Task2 四则运算2
1.任务要求:对之前的自动出题系统提出了新的要求:(1).题目避免重复:(2).可定制(数量/打印方式):(3)可以控制下列参数:是否有乘除法.数值范围.加减有无负数.除法有无余数.是否支持分数... ...
- servlet的方法解析
一般来说servlet继承了HttpServlet,我们可以覆盖某些方法来实现自己的功能. Init()和Init(ServletConfig config),我们一般只需覆盖后者,因为这个可以从se ...
- C#窗体随机四则运算 (第四次作业)
---恢复内容开始--- 增量内容:1)处理用户的错误输入,比如输入字母或符号等,处理除法运算中分母为0的情况,处理结果为负数的情况,保证是小学水平不出现负数,比如不能出现5-8=-3这种情况:2)用 ...
- 增加ubuntu的内存——设置Swap增加内存
1.查看一下当前Swap分区的状态: $cat /proc/meminfo SwapTotal: 0 kB SwapFree: 0 kB 如果上面二项目都为0,说明没有Swap分区:如果不为0,则说明 ...
- JMeter性能测试基础 (1) - 安装及简单使用
Apache JMeter是一款开源性能测试工具,全部功能使用Java编写,可用于进行性能测试.JMeter最初被设计用于Web应用测试,之后被扩展至多个测试领域. Apache jmeter 可以用 ...
- [转帖]amzon最新的产品outposts
2018年12月3日,全球领先的企业软件创新者VMware(NYSE: VMW)发布两款运行于AWS Outposts的全新解决方案预览:VMware Cloud on AWS Outposts与VM ...