python学习(十八)爬虫中加入cookie
转载自:原文链接
前几篇文章介绍了urllib库基本使用和爬虫的简单应用,本文介绍如何通过post信息给网站,保存登陆后cookie,并用于请求有
权限的操作。保存cookie需要用到cookiejar类,可以输出cookie信息查看下
1 |
import http.cookiejar |
1 通过http.cookiejar.CookieJar()创建一个cookiejar对象,用来保存上网留下的cookie。
2 为了处理cookie,需要创建cookie处理器,通过urllib.request.HTTPCookieProcessor(cookie)根据cookie
创建cookie处理器。
3 接下来根据cookie处理器,建立opener, urllib.request.build_opener(handler)创建opener
4 通过openr访问cookie中的数据
可以保存cookie,用于以后访问有权限的网页。下面将cookie写入文件
1 |
#定义文件名 |
1 传入文件名,调用http.cookiejar.MozillaCookieJar创建cookie,
cookie和文件名绑定了。
2 根据cookie创建处理器, request.HTTPCookieProcessor创建handler
3 根据Cookie处理器创建opener
4 用opener访问网站,生成cookie
5 cookie.save保存到filename文件中,ignore_discard表示忽略是否过期,
及时被丢弃也保存。ignore_expires表示文件存在则覆盖写入。
对于保存好的cookie文件,可以提取并访问其他网页。
1 |
filename = 'cookie.txt' |
1 用MozillaCookieJar创建cookie
2 调用cookie.load加载文件内容到cookie中
3 根据cookie创建HTTPCookieProcessor
4 根据handler创建opener
5 利用opener打开网页,返回response
下面综合应用上面的知识,用爬虫模拟登陆,然后获取有权限的网页和信息。
通过浏览器审查元素的方式可以查看访问网站的request和response,用fiddler更方便一些,用fidder监控浏览器
数据,然后模拟浏览器发送登录请求。
随便找一个需要登陆的网站
http://www.lesmao.cc/forum.php
找到登陆按钮,点击登陆,查看fiddler监控的数据。
可以在fiddler中看到这个request请求post数据给网站。
通过webform这一选项看到我们投递的消息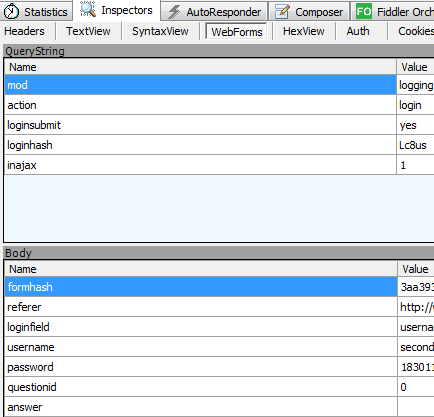
有些网页是需要登陆才能访问的,如
http://www.lesmao.cc/home.php?mod=space&do=notice&view=system
下面先模拟登陆,获取cookie,然后利用cookie访问个人信息网页。
1 |
if __name__ == '__main__': |
打印出的html信息和登陆后点击的信息是一致的,所以用cookie登陆并访问其它权限网页成功了。
源码下载地址:
源码下载
我的公众号:
python学习(十八)爬虫中加入cookie的更多相关文章
- python学习第八讲,python中的数据类型,列表,元祖,字典,之字典使用与介绍
目录 python学习第八讲,python中的数据类型,列表,元祖,字典,之字典使用与介绍.md 一丶字典 1.字典的定义 2.字典的使用. 3.字典的常用方法. python学习第八讲,python ...
- 漫谈程序员(十八)windows中的命令subst
漫谈程序员(十八)windows中的命令subst 用法格式 一.subst [盘符] [路径] 将指定的路径替代盘符,该路径将作为驱动器使用 二.subst /d 解除替代 三.不加任何参数键入 ...
- (转)SpringMVC学习(十二)——SpringMVC中的拦截器
http://blog.csdn.net/yerenyuan_pku/article/details/72567761 SpringMVC的处理器拦截器类似于Servlet开发中的过滤器Filter, ...
- (私人收藏)python学习(游戏、爬虫、排序、练习题、错误总结)
python学习(游戏.爬虫.排序.练习题.错误总结) https://pan.baidu.com/s/1dPzSoZdULHElKvb57kuKSgl7bz python100经典练习题python ...
- [Python学习] 简单网络爬虫抓取博客文章及思想介绍
前面一直强调Python运用到网络爬虫方面很有效,这篇文章也是结合学习的Python视频知识及我研究生数据挖掘方向的知识.从而简介下Python是怎样爬去网络数据的,文章知识很easy ...
- Python学习教程:Pandas中第二好用的函数
从网上看到一篇好的文章是关于如何学习python数据分析的迫不及待想要分享给大家,大家也可以点链接看原博客.希望对大家的学习有帮助. 本次的Python学习教程是关于Python数据分析实战基础相关内 ...
- [持续更新] Python学习、使用过程中遇见的非代码层面知识(想不到更好的标题了 T_T)
写在前面: 这篇博文记录的不是python代码.数据结构.算法相关的内容,而是在学习.使用过程中遇见的一些没有技术含量,但有时很令人抓耳挠腮的小东西.比如:python内置库怎么看.python搜索模 ...
- python学习笔记八——字典的方法
4.3.3 字典的方法 字典的常用方法可以极大地提高编程效率.keys()和values()分别返回字典的key列表和value列表.例: dict={"a":"appl ...
- Python脚本控制的WebDriver 常用操作 <二十八> 超时设置和cookie操作
超时设置 测试用例场景 webdriver中可以设置很多的超时时间 implicit_wait.识别对象时的超时时间.过了这个时间如果对象还没找到的话就会抛出异常 Python脚本 ff = webd ...
随机推荐
- TFS任务预览
不太熟悉TFS任务项的建立. 初步建立及按老师要求分配到个人的任务设置与时间安排如下: (长时间任务可由多人合作完成,具体根据情况迅速调整任务分配) 加上每人需要进行阅读前一小组的代码需要时间2*8= ...
- Daily Scrum (2015/10/21)
今天可以说是项目正式开始的第一天,由于大家缺乏做团队项目的经验,对TFS的使用都还不太熟悉,所以今天大家的主要工作是熟悉TFS的使用和对代码进行初步的理解.我们预计需要2-3天时间来理解透彻源代码.以 ...
- 20162328蔡文琛 大二week07
20162328 2017-2018-1 <程序设计与数据结构>第7周学习总结 教材学习内容总结 树是非线性结构,其元素组织为一个层次结构. 树的度表示树种任意节点的最大子节点数. 有m个 ...
- Chapter 8 面向对象设计
设计也是一个建模的活动,在设计阶段将集中研究系统的软件实现问题包括体系结构设计.详细设计.用户界面设计和数据库设计等.通常设计活动分为系统设计和详细设计两个主要阶段.软件设计要遵循模块化.耦合度和内聚 ...
- Restful风格wcf调用
文章:Restful风格wcf调用 作者相当于把wcf服务改造成rest风格. Restful风格wcf调用2——增删改查 这篇文章在第一篇的基础上,进行了优化. Restful风格wcf调用3——S ...
- 树莓派与Arduino Leonardo使用NRF24L01无线模块通信之基于RF24库 (三) 全双工通信
设计思路 Arduino Leonardo初始化为发送模式,发送完成后,立即切换为接收模式,不停的监听,收到数据后立即切换为发送模式,若超过一定时间还为接收到数据,则切换为发送模式. 树莓派初始化为接 ...
- java8之重新认识HashMap(转自美团技术团队)
java8之重新认识HashMap 摘要 HashMap是Java程序员使用频率最高的用于映射(键值对)处理的数据类型.随着JDK(JavaDevelopmet Kit)版本的更新,JDK1.8对Ha ...
- angularJS1笔记-(18)-$http及用angular实现JSONP跨域访问过程
官网上的解释为: The $http service is a core AngularJS service that facilitates communication with the remot ...
- 『编程题全队』Alpha 阶段冲刺博客集合
『编程题全队』Alpha 阶段冲刺博客集合 »Day1 2018年4月19日 博客连接:『编程题全队』Alpha 阶段冲刺博客Day1 »Day2 2018年4月20日 博客连接:『编程题全队』Alp ...
- OneZero第二周第一次站立会议(2016.3.28)
会议时间:2016年3月28日 会议成员:冉华,张敏,王巍,夏一鸣. 会议目的:分配第二周任务. 会议内容:由于老师要求4月1日进行Alpha发布,我们决定最优先完成消息录入功能.工作具体分配如下 1 ...