CNN Architectures(AlexNet,VGG,GoogleNet,ResNet,DenseNet)
AlexNet (2012)

The network had a very similar architecture as LeNet by Yann LeCun et al but was deeper, with more filters per layer, and with stacked convolutional layers. It consisted 11x11, 5x5,3x3, convolutions, max pooling, dropout, data augmentation, ReLU activations, SGD with momentum. It attached ReLU activations after every convolutional and fully-connected layer
VGGNet (2014)
Similar to AlexNet, only 3x3 convolutions, but lots of filters

- Convolution using 64 filters
- Convolution using 64 filters + Max pooling
- Convolution using 128 filters
- Convolution using 128 filters + Max pooling
- Convolution using 256 filters
- Convolution using 256 filters
- Convolution using 256 filters + Max pooling
- Convolution using 512 filters
- Convolution using 512 filters
- Convolution using 512 filters + Max pooling
- Convolution using 512 filters
- Convolution using 512 filters
- Convolution using 512 filters + Max pooling
- Fully connected with 4096 nodes
- Fully connected with 4096 nodes
- Output layer with Softmax activation with 1000 nodes
- Convolutions layers (used only 3*3 size )
- Max pooling layers (used only 2*2 size)
- Fully connected layers at end
- Total 16 layers
实际上,一个5x5可以用两个3x3来近似代替,一个7x7可以用三个3x3的卷积核来代替,不仅提升了判别函数的识别能力,而且还减少了参数;如3个3x3的卷积核,通道数为C,则参数为3x(3x3xCxC)=27C2C2,而一个7x7的卷积核,通道数也为C,则参数为(7x7xCxC)=49C2C2。
GoogLeNet(2014)
GoogLeNet采用了22层网络,为了避免上述提到的梯度消失问题,GoogLeNet巧妙的在不同深度处增加了两个loss来保证梯度回传消失的现象
Inception的网络,将1x1,3x3,5x5的conv和3x3的pooling,stack在一起,一方面增加了网络的width,另一方面增加了网络对尺度的适应性,但是如果简单的将这些应用到feature map上的话,concat起来的feature map厚度将会很大,所以为了避免这一现象提出的inception具有如下结构,在3x3前,5x5前,max pooling后分别加上了1x1的卷积核起到了降低feature map厚度的作用,这也使得虽然googlenet有22层但是参数个数要少于alexnet和vgg。inception的具体结构如图2所示。
作者:时浊
链接:https://www.jianshu.com/p/1da6cc24137a
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
1、GoogLeNet Inception V1

采用1x1卷积核来进行降维。
例如:上一层的输出为100x100x128,经过具有256个输出的5x5卷积层之后(stride=1,pad=2),输出数据为100x100x256。其中,卷积层的参数为128x5x5x256。假如上一层输出先经过具有32个输出的1x1卷积层,再经过具有256个输出的5x5卷积层,那么最终的输出数据仍为为100x100x256,但卷积参数量已经减少为128x1x1x32 + 32x5x5x256,大约减少了4倍。
对上图做以下说明:
1 . 采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
2 . 之所以卷积核大小采用1、3和5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定pad=0、1、2,那么卷积之后便可以得到相同维度的特征,然后这些特征就可以直接拼接在一起了;
3 . 文章说很多地方都表明pooling挺有效,所以Inception里面也嵌入了。
4 . 网络越到后面,特征越抽象,而且每个特征所涉及的感受野也更大了,因此随着层数的增加,3x3和5x5卷积的比例也要增加。

对上图做如下说明:
1 . 显然GoogLeNet采用了模块化的结构,方便增添和修改;
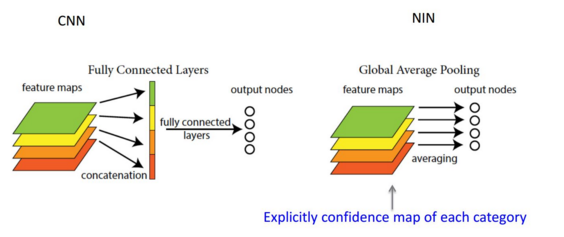
2 . 网络最后采用了average pooling来代替全连接层,想法来自NIN,事实证明可以将TOP1 accuracy提高0.6%。但是,实际在最后还是加了一个全连接层,主要是为了方便以后大家finetune;
3 . 虽然移除了全连接,但是网络中依然使用了Dropout ;
4 . 为了避免梯度消失,网络额外增加了2个辅助的softmax用于向前传导梯度。文章中说这两个辅助的分类器的loss应该加一个衰减系数,但看caffe中的model也没有加任何衰减。此外,实际测试的时候,这两个额外的softmax会被去掉。
global average pooling:假如,最后的一层的数据是10个6*6的特征图,global average pooling是将每一张特征图计算所有像素点的均值,输出一个数据值,
这样10 个特征图就会输出10个数据点,将这些数据点组成一个1*10的向量的话,就成为一个特征向量,就可以送入到softmax的分类中计算了
2、GoogLeNet Inception V2
从上面来看,大卷积核完全可以由一系列的3x3卷积核来替代,那能不能分解的更小一点呢。文章考虑了 nx1 卷积核。
如下图所示的取代3x3卷积:
于是,任意nxn的卷积都可以通过1xn卷积后接nx1卷积来替代。实际上,作者发现在网络的前期使用这种分解效果并不好,还有在中度大小的feature map上使用效果才会更好。(对于mxm大小的feature map,建议m在12到20之间)。
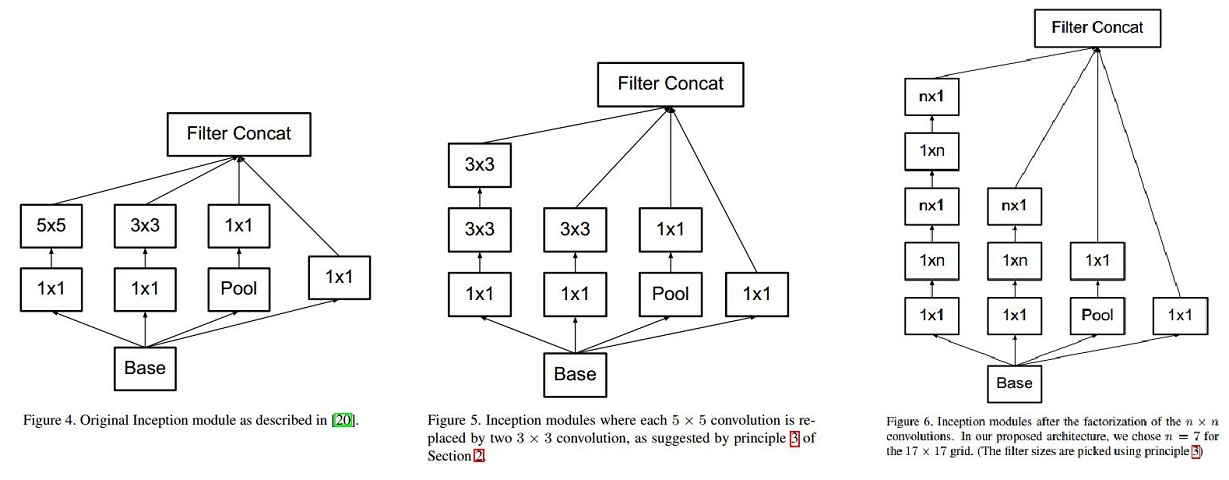
(1) 图4是GoogLeNet V1中使用的Inception结构;
(2) 图5是用3x3卷积序列来代替大卷积核;
(3) 图6是用nx1卷积来代替大卷积核,这里设定n=7来应对17x17大小的feature map。该结构被正式用在GoogLeNet V2中。
RestNet
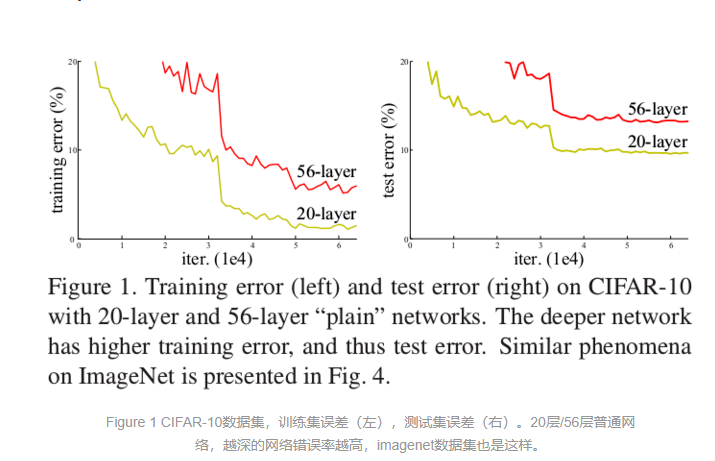

加入了shortcut connections,实线是在input 和output维度一致时候,虚线是在input和output维度不一致的时候,可以采用2种option: a) 对于多出来的dimention用0 padding b)利用1 X 1的卷积核降维
DenseNet
见后面的博客:https://www.cnblogs.com/wuxiangli/p/8257764.html
CNN Architectures(AlexNet,VGG,GoogleNet,ResNet,DenseNet)的更多相关文章
- AlexNet,VGG,GoogleNet,ResNet
AlexNet: VGGNet: 用3x3的小的卷积核代替大的卷积核,让网络只关注相邻的像素 3x3的感受野与7x7的感受野相同,但是需要更深的网络 这样使得参数更少 大多数内存占用在靠前的卷积层,大 ...
- LeNet, AlexNet, VGGNet, GoogleNet, ResNet的网络结构
1. LeNet 2. AlexNet 3. 参考文献: 1. 经典卷积神经网络结构——LeNet-5.AlexNet.VGG-16 2. 初探Alexnet网络结构 3.
- #Deep Learning回顾#之LeNet、AlexNet、GoogLeNet、VGG、ResNet
CNN的发展史 上一篇回顾讲的是2006年Hinton他们的Science Paper,当时提到,2006年虽然Deep Learning的概念被提出来了,但是学术界的大家还是表示不服.当时有流传的段 ...
- (转)ResNet, AlexNet, VGG, Inception: Understanding various architectures of Convolutional Networks
ResNet, AlexNet, VGG, Inception: Understanding various architectures of Convolutional Networks by KO ...
- Deep Learning 经典网路回顾#之LeNet、AlexNet、GoogLeNet、VGG、ResNet
#Deep Learning回顾#之LeNet.AlexNet.GoogLeNet.VGG.ResNet 深入浅出——网络模型中Inception的作用与结构全解析 图像识别中的深度残差学习(Deep ...
- 总结近期CNN模型的发展(一)---- ResNet [1, 2] Wide ResNet [3] ResNeXt [4] DenseNet [5] DPNet [9] NASNet [10] SENet [11] Capsules [12]
总结近期CNN模型的发展(一) from:https://zhuanlan.zhihu.com/p/30746099 余俊 计算机视觉及深度学习 1.前言 好久没有更新专栏了,最近因为项目的原因接 ...
- 【TensorFlow-windows】(六) CNN之Alex-net的测试
主要内容: 1.CNN之Alex-net的测试 2.该实现中的函数总结 平台: 1.windows 10 64位 2.Anaconda3-4.2.0-Windows-x86_64.exe (当时TF还 ...
- 经典深度学习CNN总结 - LeNet、AlexNet、GoogLeNet、VGG、ResNet
参考了: https://www.cnblogs.com/52machinelearning/p/5821591.html https://blog.csdn.net/qq_24695385/arti ...
- 深度学习方法(五):卷积神经网络CNN经典模型整理Lenet,Alexnet,Googlenet,VGG,Deep Residual Learning
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术感兴趣的同学加入. 关于卷积神经网络CNN,网络和文献中 ...
随机推荐
- Linux内核分析实验五
一.给MenuOS增加time和time-asm命令 1. 克隆并自动编译MenuOS rm menu -rf 强制删除原menu文件 git clone http: cd menumake root ...
- 20135239 益西拉姆 linux内核分析 进程的切换和系统的一般执行过程
week 8 进程的切换和系统的一般执行过程 [ 20135239 原文请转载请注明出处 <Linux内核分析>MOOC课程http://mooc.study.163.com/course ...
- 解题:AHOI2017/HNOI2017 礼物
题面 先不管旋转操作,只考虑增加亮度这个操作.显然这个玩意的影响是相对于$x,y$固定的,所以可以枚举增加的亮度然后O(1)算出来.为了方便我们把这个操作换种方法表示,只让一个手环改变$[-m,m]$ ...
- Access to a protected network share using Win32 C++
WNetAddConnection2 DWORD WNetAddConnection2A( LPNETRESOURCEA lpNetResource, LPCSTR lpPassword, LPCST ...
- spring 和 spring boot 的区别
最近越来越多的开发者都开始选择 spring-boot,与传统的 spring 相比,spring-boot又有哪些优势呢? 1.追求开箱即用的效果,只需要很少的配置就可以直接开始运行项目. 例如各种 ...
- ASP.NET IOC之 AutoFac的认识和结合MVC的使用
这几天研究了解发现AutoFac是个牛X的IOC容器,是.NET领域比较流行的IOC框架之一,传说是速度最快的,~ 据相关资料,相关学习,和认知,遂做了一些整理 优点: 它是C#语言联系很紧密,也就是 ...
- NYOJ 数独 DFS
数独 时间限制:1000 ms | 内存限制:65535 KB 难度:4 描述 数独是一种运用纸.笔进行演算的逻辑游戏.玩家需要根据9×9盘面上的已知数字,推理出所有剩余空格的数字,并满足每一 ...
- React - 环境准备
1. 下载 node.js,在 https://nodejs.org/en/download/ 选择合适的版本. 2. 检查 node.js 是否安装成功. hueyMB:~ zhisenzheng$ ...
- 在传统的ADO.NET中使用事务
using (SqlConnection conn = new SqlConnection()) { SqlCommand cmd = conn.CreateCommand(); //启动事务 Sql ...
- javascript 高度相关
//scrollTop; var scrollTop = Math.max(document.documentElement.scrollTop, document.body.scrollTop); ...