关于使用Tomcat搭建的Web项目,出现 URL 中文乱码的问题解析
URL编码问题
问题描述
使用 Tomcat 开发一个 Java Web 项目的时候,相信大多数人都遇到过url出现中文乱码的情况,绝大多数人为了避免出现这种问题,所以设计 url 一般都会尽量设计成都是英文字符。但总避免一种情况就是当你的系统中拥有搜索功能时,你无法预料到用户输入的是中文还是其他符号,此时还是会存在中文乱码的问题,那么为什么会产生中文乱码问题,下面给大家详细解析。
什么是 URL
URL 叫统一资源定位符,也可以说成我们平时在地址栏输入的路径。通过这个url(路径)我们可以发送请求给服务器,服务器寻找具体的服务器组件然后再向用户提供服务。
什么是 URL 编码
url 编码简单来说就是对 url 的字符 按照一定的编码规则进行转换。
为什么需要 URL 编码
人类的语言太多,不可能用一个通用的格式去表示这么多的字符,所以则需要编码,按照不同的规则来表示不同的字符。
那么现在进入正题
GET 请求 和 POST请求是如何进行url编码的
对于 GET 请求,我们都知道请求参数是直接跟在url后面,当 url 组装好之后浏览器会对其进行 encode 操作。此过程主要是对 url 中一些特殊字符进行编码以转换成 可以用 多个 ASCII 码字符表示。具体会以什么样的编码格式是由浏览器决定的(具体的规则可以参见 http://www.ruanyifeng.com/blog/2010/02/url_encoding.html )
进行URL encode之后,浏览器就会以iso-8859-1的编码方式转换为二进制随着请求头一起发送出去。
当请求发送到服务器之后,Tomcat 接收到这个请求,会对请求进行解析。具体的解析过程就不在这里详解,可以去参看一下 Tomcat 的源码,但在使用请求参数有中文时,我相信肯定很多人都会出现 404 的情况
下面将分别以Tomcat7、Tomcat8两种版本来说明这其中出现404的原因
关于URL含有中文导致404
第一种情况:URL 含有中文,出现404
当前测试的 Servlet
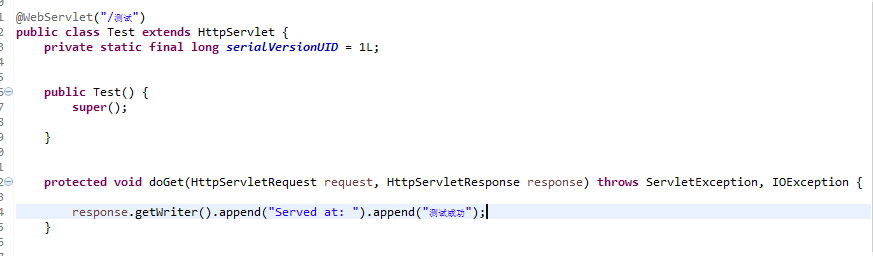
直接访问的结果
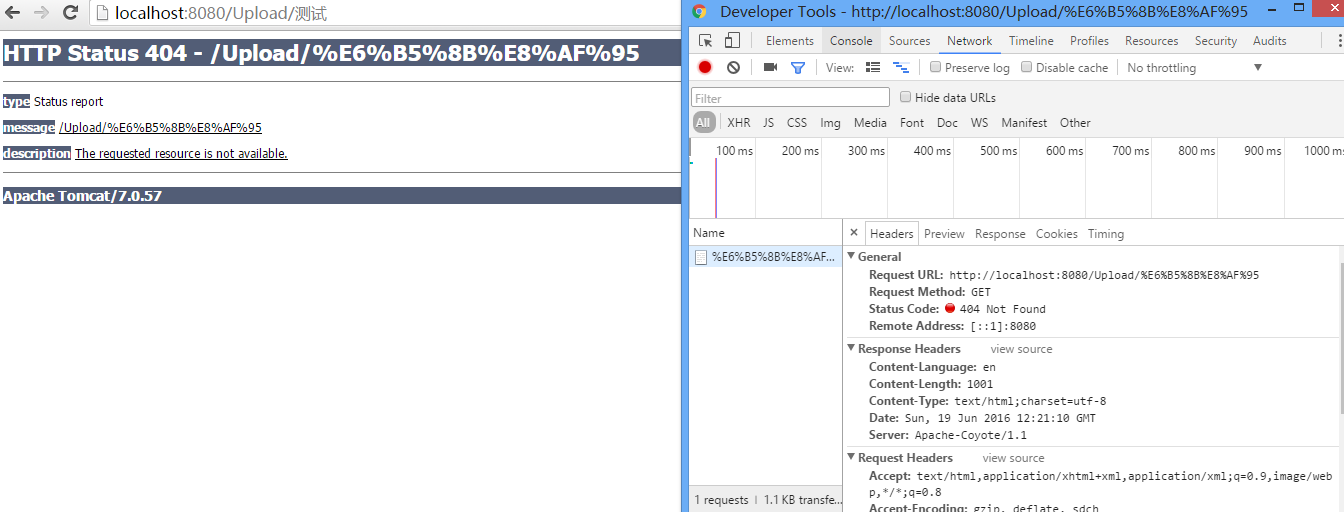
从测试图可以看出当 URL 含有中文时,直接在浏览器访问会出现 404,浏览器已经正确的发出了 HTTP 请求,所以这可以排除是浏览器的问题,那么问题应该是出现在服务器端,那么这个问题就应该从 Tomcat 如何解析请求着手查起。
Tomcat 解析请求时通过调用 AbstractInputBuffer.parseRequestLine 方法,这是一个抽象类,一般都将会委托org.apache.coyote.http11.InternalInputBuffer 子类来执行,那么我现在来看看 parseRequestLine 方法是如何执行的
public boolean parseRequestLine(boolean useAvailableDataOnly) throws IOException {
//前面省略,主要都是通过流的读取字节的操作解析请求的内容
//
// Reading the URI,这段代码主要是从流中读取 URL 的字节到buf中,再将buf的字节set进请求中
//
boolean eol = false;
while (!space) {
// Read new bytes if needed
if (pos >= lastValid) {
if (!fill())
throw new EOFException(sm.getString("iib.eof.error"));
}
// Spec says single SP but it also says be tolerant of HT
if (buf[pos] == Constants.SP || buf[pos] == Constants.HT) {
space = true;
end = pos;
} else if ((buf[pos] == Constants.CR)
|| (buf[pos] == Constants.LF)) {
// HTTP/0.9 style request
eol = true;
space = true;
end = pos;
} else if ((buf[pos] == Constants.QUESTION)
&& (questionPos == -1)) {
questionPos = pos;
}
pos++;
}
request.unparsedURI().setBytes(buf, start, end - start);
if (questionPos >= 0) {
request.queryString().setBytes(buf, questionPos + 1,
end - questionPos - 1);
request.requestURI().setBytes(buf, start, questionPos - start);
} else {
request.requestURI().setBytes(buf, start, end - start);
}
//后面一样省略,都是对请求流中的内容读取字节出来,set到请求对应的内容块
return true;
}
因为请求有很多内容,这个方法只是按照内容块将对应的字节 set 进请求,接下来 Tomcat 会基于请求来进一步解析,下一步是调用 AbstractProcessor.prepareRequest 方法,该方法主要是检查请求的内容是否合法,若都合法,则会将 request、response委托给 adapter 去调用service方法
public void service(org.apache.coyote.Request req,
org.apache.coyote.Response res)
throws Exception {
//省略代码
//service会调用该方法去解析请求,并对url进行解码
boolean postParseSuccess = postParseRequest(req, request, res, response);
//后面省略
}
protected boolean postParseRequest(org.apache.coyote.Request req,
Request request,
org.apache.coyote.Response res,
Response response)
throws Exception {
//省略
// Copy the raw URI to the decodedURI,解码从这里开始
// 这一步只是将未解码的 URL 字节复制给 decodedURL
MessageBytes decodedURI = req.decodedURI();
decodedURI.duplicate(req.requestURI());
// Parse the path parameters. This will:
// - strip out the path parameters
// - convert the decodedURI to bytes
parsePathParameters(req, request);
// 这一步是将 URL 中含有%的16进制数据合并
// URI decoding
// %xx decoding of the URL
try {
req.getURLDecoder().convert(decodedURI, false);
} catch (IOException ioe) {
res.setStatus(400);
res.setMessage("Invalid URI: " + ioe.getMessage());
connector.getService().getContainer().logAccess(
request, response, 0, true);
return false;
}
// 真正对 URL 解码操作在这一步
convertURI(decodedURI, request);
protected void convertURI(MessageBytes uri, Request request)
throws Exception {
ByteChunk bc = uri.getByteChunk();
int length = bc.getLength();
CharChunk cc = uri.getCharChunk();
cc.allocate(length, -1);
// 这一步是获取解码使用编码格式,从这里可以看出编码格式与 connector 有关
// 在默认情况下,如果没有配置Encoding,则为 null
String enc = connector.getURIEncoding();
if (enc != null) {
//根据编码格式来对 URL 进行解码
}
// 所以当我们没有配置时,会直接跳下去执行,以 ISO-8859-1的编码格式来解码 URL
// Default encoding: fast conversion for ISO-8859-1
byte[] bbuf = bc.getBuffer();
char[] cbuf = cc.getBuffer();
int start = bc.getStart();
for (int i = 0; i < length; i++) {
cbuf[i] = (char) (bbuf[i + start] & 0xff);
}
uri.setChars(cbuf, 0, length);
}
在Tomcat 7 里面,没有配置 connector 的编码,它会默认使用 ISO-8859-1 的编码格式来解码,所以该 URL 最后解码的结果是

可以看出解码后的 URL 出现了中文乱码,所以最后因为没有匹配到对应的 Servlet ,所以出现404
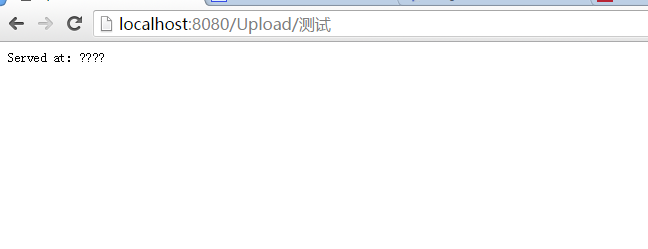
那么当我们在 Tomcat 的配置文件配置编码格式之后,再使用同样的 URL 去访问,这时就能成功访问了

URL 解码结果
测试结果
问题来了
当我们使用 Tomcat 8的时候,不管我们是否有设置 connector 的编码,当我们使用含有中文 URL 去访问资源,均会出现404的情况
注:Tomcat 8的默认编码是 UTF-8,而Tomcat 7 的默认编码是ISO-8859-1
那么既然Tomcat 8是以 UTF-8 进行解码的,所以 URL 能够正确解码成功,不会出现 URL 乱码,那么问题是出现在哪里呢?
我们知道请求最终会委托给一个请求包装对象,如果找不到,那么就会访问失败,所以现在从这里请求映射开始着手找原因。
Tomcat 匹配请求的 Mapper 有多种策略,一般是使用全名匹配
- 全名匹配:根据请求的全路径来设置对应 wrappers 对象
匹配方法如下
private final void internalMapExactWrapper
(Wrapper[] wrappers, CharChunk path, MappingData mappingData) {
Wrapper wrapper = exactFind(wrappers, path);
if (wrapper != null) {
mappingData.requestPath.setString(wrapper.name);
mappingData.wrapper = wrapper.object;
if (path.equals("/")) {
// Special handling for Context Root mapped servlet
mappingData.pathInfo.setString("/");
mappingData.wrapperPath.setString("");
// This seems wrong but it is what the spec says...
mappingData.contextPath.setString("");
} else {
mappingData.wrapperPath.setString(wrapper.name);
}
}
}
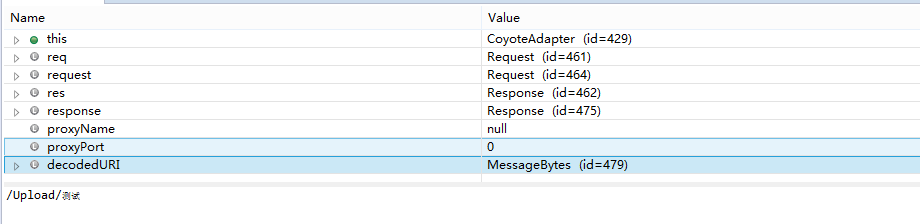
在 Tomcat 7 下 wrappers 对象集的内存快照

可以看到 wrappers 对象存在我们要访问的资源,所以使用Tomcat 7 我们可以最终访问到目标资源
在 Tomcat 8 下,wrapper 对象的内存快照
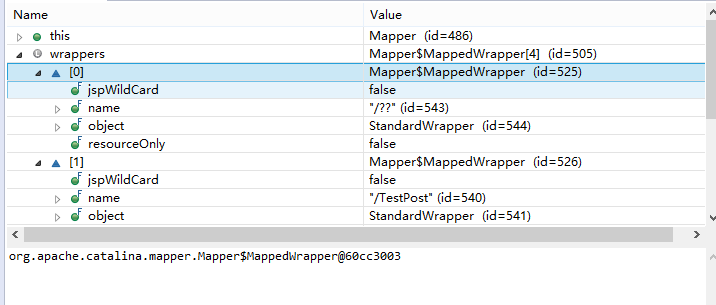
可以看到Mapper 对象的 name 出现乱码
所以之所以会造成这种原因是因为不同版本的 Tomcat 在生成 Servlet 对应的 Mapper对象时,解析路径使用的编码格式不同,具体编码可以去查看 Tomcat 如何解析 Servlet。
最后总结:
开发 Java Web 项目的时候,尽量避免设计含有中文字符的 URL,并且统一开发环境,比如Tomcat 版本。因为可能有些bug或问题出现原因是源于版本的不同,与自己的源程序逻辑无关,一旦出现这种问题,要找出问题的原因是需要花费很多时间的。
关于请求参数有中文乱码问题
在 Web 开发中,我们通常会有许多带有请求参数的请求,一般来说我们需要调用 request.setCharacterEncoding(“utf-8”); 方法来设置解析参数的编码,但是一般情况下,该方法只对于 Post请求有用,而对于 Get 请求获取参数仍然会出现乱码。
测试的 Servelt
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
request.setCharacterEncoding("utf-8");
response.setCharacterEncoding("utf-8");
String name = request.getParameter("name");
System.out.println(name);
request.getRequestDispatcher("Test.jsp").forward(request, response);
}
测试结果
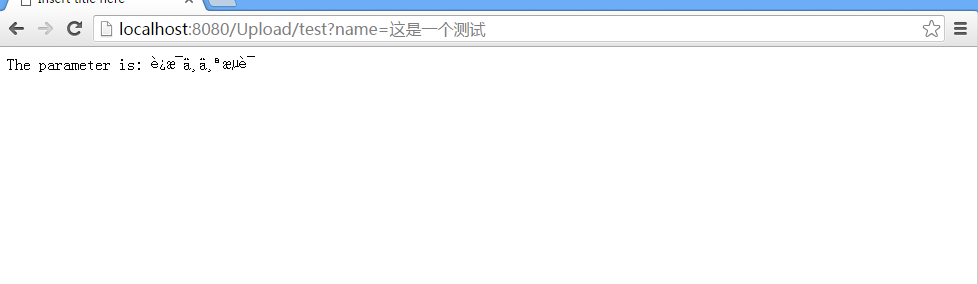
可以看到即使设置了编码,但是请求参数仍然是乱码。
那么 Tomcat 是如何解析请求参数的呢?
Tomcat 源码如下
protected void parseParameters(){
//以上代码省略
//获取我们设置的编码
String enc = getCharacterEncoding();
boolean useBodyEncodingForURI = connector.getUseBodyEncodingForURI();
if (enc != null) {
parameters.setEncoding(enc);
if (useBodyEncodingForURI) {
parameters.setQueryStringEncoding(enc);
}
} else {
parameters.setEncoding(org.apache.coyote.Constants.DEFAULT_CHARACTER_ENCODING);
if (useBodyEncodingForURI) {
parameters.setQueryStringEncoding
(org.apache.coyote.Constants.DEFAULT_CHARACTER_ENCODING);
}
}
parameters.handleQueryParameters();
}
public void handleQueryParameters() {
if( didQueryParameters ) {
return;
}
didQueryParameters=true;
if( queryMB==null || queryMB.isNull() ) {
return;
}
if(log.isDebugEnabled()) {
log.debug("Decoding query " + decodedQuery + " " +
queryStringEncoding);
}
try {
decodedQuery.duplicate( queryMB );
} catch (IOException e) {
// Can't happen, as decodedQuery can't overflow
e.printStackTrace();
}
// 解析 get 请求的参数是通过 parameter里面的 queryStringEncoding 来解码的
processParameters( decodedQuery, queryStringEncoding );
}
从源码可以看出 Tomcat 通过 String enc = getCharacterEncoding(); 来获取我们设置的编码,当前设置为 utf-8,但是当useBodyEncodingForURI 为 false 时,它只会讲 enc 的值赋值给 encoding 而不会赋值给 queryStringEncoding。
在解析参数时,对于 Post 请求,Tomcat 使用 encoding 来解码;对于 get 请求,Tomcat 使用 queryStringEncoding 来解析参数,因为此时 useBodyEncodingForURI 为 false 时,Tomcat 使用默认编码来解析,Tomcat 7的默认编码是 ISO-8859-1,所以解析之后参数出现乱码;Tomcat 8 默认编码是 UTF-8,因此解析不会出现乱码。
对于使用 Tomcat 7 出现请求参数乱码的解决方法:
- 在 Tomcat 的 server,xml 的配置文件中,对于 connector 的配置中,加上如下的配置,那么对于 get 请求,也能够通过request.setCharacterEncoding(“utf-8”); 来设定编码格式
<Connector connectionTimeout="20000" port="8080" protocol="HTTP/1.1" redirectPort="8443"
URIEncoding="UTF-8" useBodyEncodingForURI="true"/>
- 创建一个请求包装对象,重写请求的获取参数方法,并通过过滤器将请求委托给包装对象,具体代码如下:
public class EncodingRequest extends HttpServletRequestWrapper {
private HttpServletRequest request;
private boolean hasEncode = false;
public EncodingRequest(HttpServletRequest request) {
super(request);
this.request = request;
}
@Override
public String getParameter(String name) {
String[] values = getParameterValues(name);
if (values == null) {
return null;
}
return values[0];
}
@Override
public String[] getParameterValues(String name) {
Map<String, String[]> parameterMap = getParameterMap();
String[] values = parameterMap.get(name);
return values;
}
@Override
public Map getParameterMap() {
Map<String, String[]> parameterMap = request.getParameterMap();
String method = request.getMethod();
if (method.equalsIgnoreCase("post")) {
return parameterMap;
}
if (!hasEncode) {
Set<String> keys = parameterMap.keySet();
for (String key : keys) {
String[] values = parameterMap.get(key);
if (values == null) {
continue;
}
for (int i = 0; i < values.length; i++) {
String value = values[i];
try {
value = new String(value.getBytes("ISO-8859-1"),
"utf-8");
values[i] = value;
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}
hasEncode = true;
}
}
return parameterMap;
}
}
本文只是个人的测试的结果,如有错误,请提出,互相交流。
关于使用Tomcat搭建的Web项目,出现 URL 中文乱码的问题解析的更多相关文章
- Java Web项目中解决中文乱码方法总结
一.了解常识: 1.UTF-8国际编码,GBK中文编码.GBK包含GB2312,即如果通过GB2312编码后可以通过GBK解码,反之可能不成立; 2.web tomcat:默认是ISO8859-1,不 ...
- Tomcat启动web项目静态页面中文乱码问题解决
1 首先查看静态页面在编辑器中是否正常, 如果是eclipse ,需要设置一下项目编码格式为utf-8, 如果是idea , 一般会自动识别, 也可以自己手动检查一下, 检查html上面是否有 ...
- 【Web】关于URL中文乱码问题
关于URL编码 一.问题的由来 URL就是网址,只要上网,就一定会用到. ...
- 带领技术小白入门——基于java的微信公众号开发(包括服务器配置、java web项目搭建、tomcat手动发布web项目、微信开发所需的url和token验证)
微信公众号对于每个人来说都不陌生,但是许多人都不清楚是怎么开发的.身为技术小白的我,在闲暇之余研究了一下基于java的微信公众号开发.下面就是我的实现步骤,写的略显粗糙,希望大家多多提议! 一.申请服 ...
- Eclipse 搭建 Maven Web项目
第一步:安装JDK: 第二步:安装Eclipse: 第三步:安装tomcat7: 第四步:安装maven插件: 4.1 下载maven:http://maven.apache.org/download ...
- 使用MyEclipse搭建java Web项目开发
转自:http://blog.csdn.net/jiuqiyuliang/article/details/36875217 首先,在开始搭建MyEclipse的开发环境之前,还有三步工具的安装需要完成 ...
- 在Tomcat中部署web项目的三种方式
搬瓦工搭建SS教程 SSR免费节点:http://www.xiaokeli.me 在这里介绍在Tomcat中部署web项目的三种方式: 1.部署解包的webapp目录 2.打包的war文件 3.Man ...
- 在Eclipse中使用Struts和Hibernate框架搭建Maven Web项目
前言 学习使用Java还是2012年的事情,刚开始学习的Java的时候,使用的是MyEclipse工具和SSH框架.初学者适合使用MyEclipse,因为他将struts.Spring和Hiberna ...
- 搭建maven web项目并配置quartz定时任务【业务:对比数据变化内容】 历程
搭建maven web项目并配置quartz定时任务[业务:对比数据变化内容] 历程2018年03月03日 10:51:10 守望dfdfdf 阅读数:100更多个人分类: 工作 问题编辑版权声明:本 ...
随机推荐
- Eclipse4.6安装Tomcat插件时报错:Unable to read repository at http://tomcatplugin.sf.net/update/content.xml. Received fatal alert: handshake_failure
错误如下: Unable to read repository at http://tomcatplugin.sf.net/update/content.xml.Received fatal aler ...
- 退出全屏监听ESC事件
fullscreenchange事件 fullscreenchange:当窗口大小改变时触发 isFullscreen:全局变量 window.addEventListener("fulls ...
- Oracle特殊恢复原理与实战(DSI系列)
1.深入浅出Oracle(DSI系列Ⅰ) 2.Oracle特殊恢复原理与实战(DSI系列Ⅱ) 3.Oracle SQL Tuning(DSI系列Ⅲ)即将开设 4.Oracle DB Performan ...
- 关于第一场HBCTF的Web题小分享,当作自身的笔记
昨天晚上6点开始的HBCTF,虽然是针对小白的,但有些题目确实不简单. 昨天女朋友又让我帮她装DOTA2(女票是一个不怎么用电脑的),然后又有一个小白问我题目,我也很热情的告诉她了,哎,真耗不起. 言 ...
- SIM900A模块HTTP相关调试笔记
SIM900A模块使用笔记 更新2018-12-8 正常工作状态: 接线方法: 首先将 AT 写入字符串输入框,然后点击 发送.因为模块波特率默认是 9600,所以两条指令的显示都是没有问题的:如果将 ...
- 对于开发WEB方面项目需要的工具和技术了解
1.IDE:Webstorm,JavaScript 开发工具. 2.版本管理系统:Git,独一无二. 3.单元测试:jsamine,前后端共用.Jasmine是我们梦寐以求的Javascript测试框 ...
- super深究
super的入门使用: 在类的继承中,如果定义某个方法,该方法会覆盖父类的同名方法,但有时候我们希望能同时实现父类的功能,这时,我们就需要调用父类的方法了,可以通过使用super来实现.比如: cla ...
- Centos7使用yum安装Mysql5.7.19的详细步骤(可用)
Centos7的yum源中默认是没有mysql,因为现在已经用mariaDB代替mysql了. 首先我们下载mysql的repo源,我们可以去mysql官网找最新的repo源地址 地址: https: ...
- BZOJ1076:[SCOI2008]奖励关(状压DP,期望)
Description 你正在玩你最喜欢的电子游戏,并且刚刚进入一个奖励关.在这个奖励关里,系统将依次随机抛出k次宝物, 每次你都可以选择吃或者不吃(必须在抛出下一个宝物之前做出选择,且现在决定不吃的 ...
- 全局唯一Id:雪花算法
雪花算法-snowflake 分布式系统中,有一些需要使用全局唯一ID的场景,这种时候为了防止ID冲突可以使用36位的UUID,但是UUID有一些缺点,首先他相对比较长,另外UUID一般是无序的. 有 ...